- The paper presents the matching principle, a geometric framework that regularizes the encoder's Jacobian along nuisance directions to suppress deployment drift.
- It establishes necessary and sufficient conditions showing that matching the nuisance range is critical, with misallocation leading to significant robustness failures.
- Empirical validations across modalities confirm that matched estimators consistently outperform isotropic and misaligned methods in drift suppression and robustness.
Geometric Unification of Robustness via the Matching Principle
Introduction and Motivation
The paper "The Matching Principle: A Geometric Theory of Loss Functions for Nuisance-Robust Representation Learning" (2605.22800) presents a comprehensive theoretical framework for understanding and designing loss functions that confer robustness to deployment-time nuisances in representation learning systems. Rather than treat adversarial robustness, domain adaptation, photometric/occlusion invariance, compositional generalisation, temporal robustness, and various alignment strategies as unrelated phenomena, the author develops a geometric theory that unifies these as aspects of a single estimation problem: identifying and regularising the covariance structure of label-preserving but potentially arbitrary input variation at deployment.
The core technical object is the population covariance Σ=CovQn(n), where Qn is a distribution of label-preserving deployment-time nuisances. The principal claim is that—across vision, language, and multimodal tasks—empirical strategies such as CORAL, adversarial training (PGD), IRM, data augmentation, metric learning, and various Jacobian penalties are best interpreted as different estimators of this core population object, each with strengths and explicit failure modes. This geometric perspective yields rigorous necessary and sufficient conditions for robustness, which are made precise in a series of theorems and falsifiable experimental predictions.
Theoretical Framework
The Matching Principle
The matching principle prescribes that, to mitigate the effects of deployment-time drift along label-invariant directions, the encoder's Jacobian should be regularised specifically within the subspace defined by the range of Σ. This is operationalised by constructing a loss:
LΣ′(θ)=Ltask(θ)+λEx[Tr(Jϕ(x)⊤Jϕ(x)Σ′)]
where Σ′ should be chosen so that its range covers range(Σ). The loss can capture all methods in the family, differing only in their choice of Σ′ as an (explicit or implicit) estimator of Σ.
Optimality and Necessity Results
Sufficiency (Theorem A)
If Σ′ is such that range(Σ′)⊇range(Σ), then in the limit of strong regularisation (Qn0), the linearised deployment drift vanishes (Qn1) for all task-relevant directions. Allocation of penalty strength within Qn2 can be optimised (cube-root water-filling), but even non-optimal allocation within the correct range is asymptotically sufficient for drift suppression [(Figure 1)].
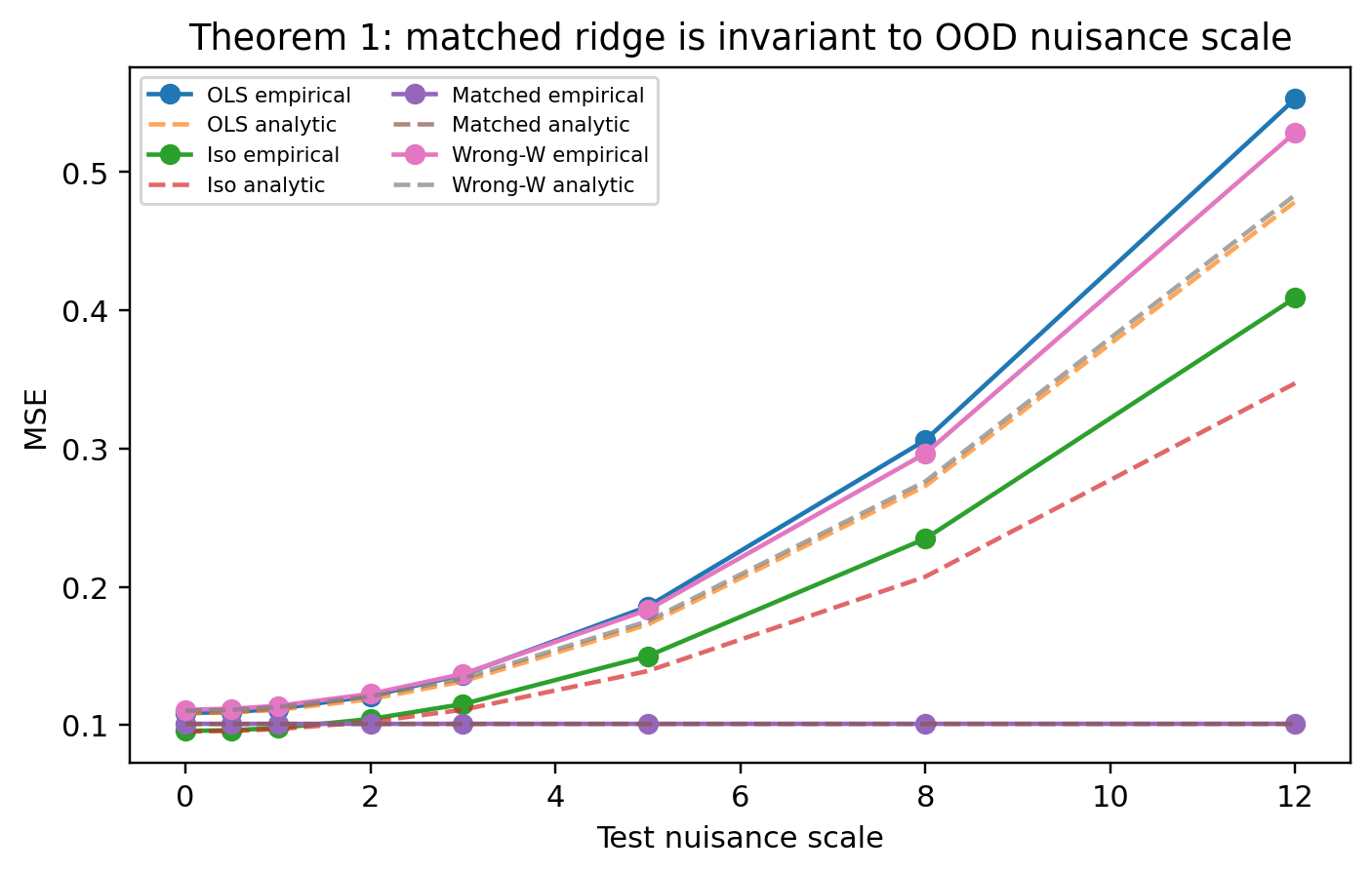
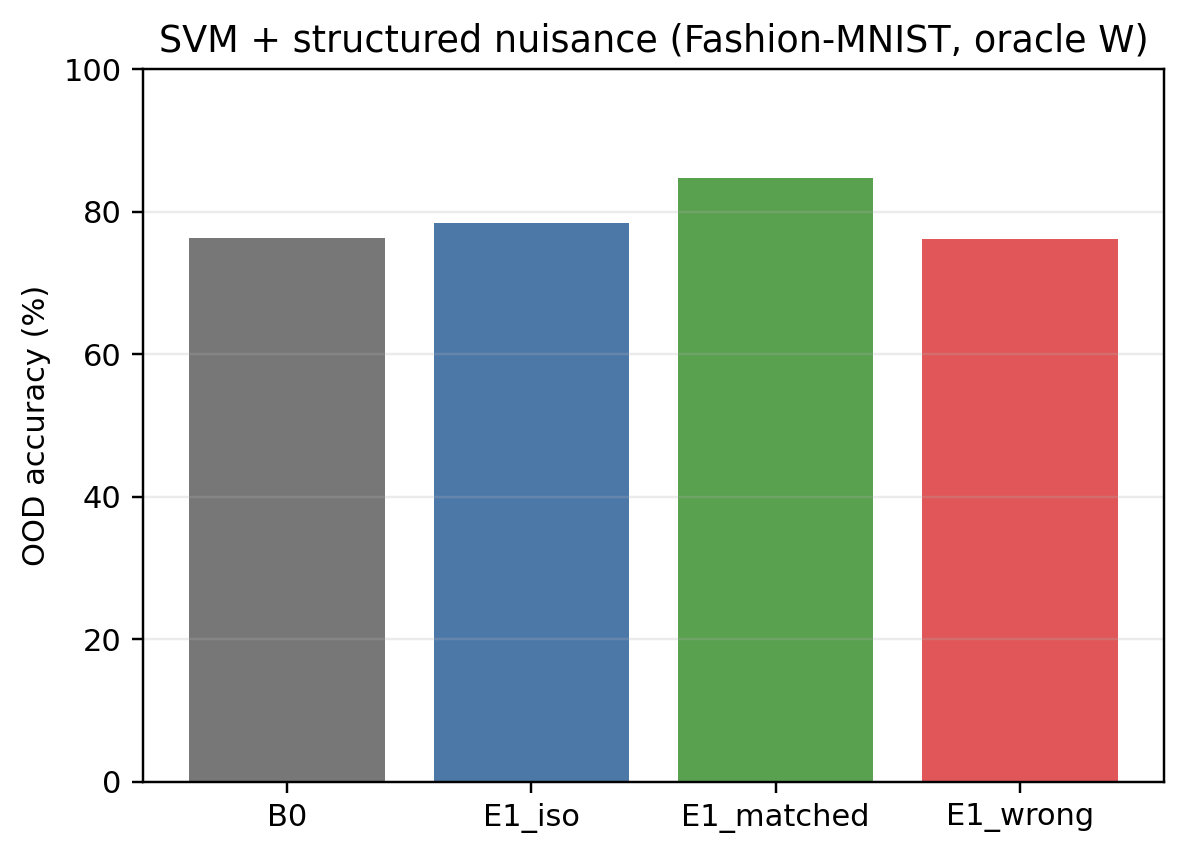
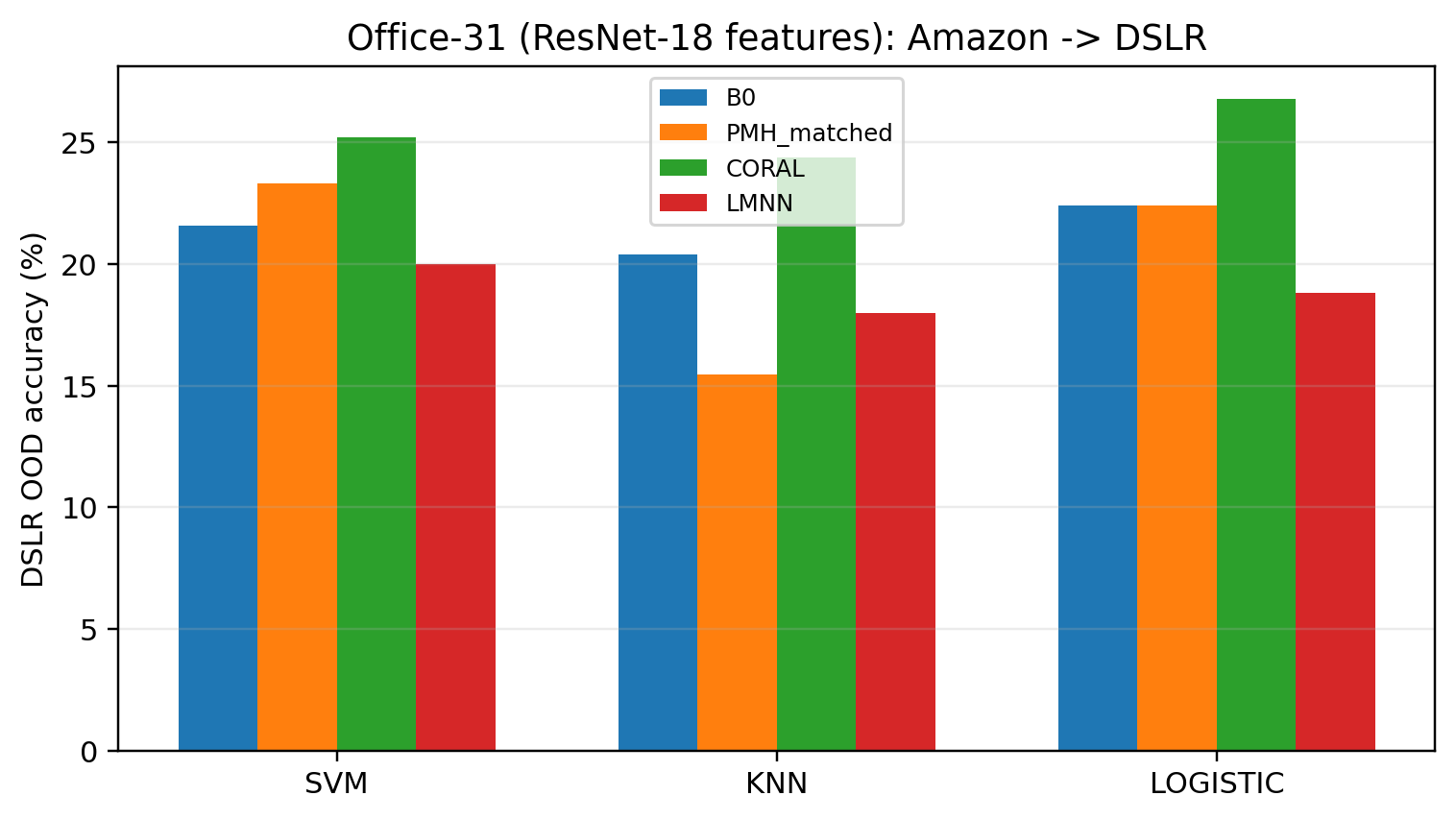
Figure 2: Closed-form demonstration of Theorem A's sufficiency: matched arms eliminate drift (MSE remains flat) as regularisation increases.
Necessity (Theorem G)
No quadratic Jacobian regulariser (i.e., no choice of Qn3 not covering the entire range of Qn4) can suppress deployment drift along all nuisance directions. If a direction is omitted, drift remains bounded away from zero regardless of Qn5.
Range vs. Allocation (Theorem B)
Matching the nuisance range is critical; misallocation of penalty mass within this subspace is a lower-order effect. Mismatching range leads to an Qn6 drift floor, while allocation mismatch within a matched range only incurs a vanishing excess as Qn7.
Deep Encoders (Theorem AQn8)
These geometric results hold (under mild assumptions) for nonlinear, deep encoders at global minimum. The paper constructs parameter settings for major architectures (MLPs, CNNs, ResNets, ViTs, GNNs, LLMs) achieving zero PMH penalty within the matched subspace.
Unification of Existing Methods
A critical contribution is the systematic algebraic identification of the Qn9 implicit in a wide array of methods:
- CORAL: cross-domain feature Gram matrix, estimating domain-shift covariance.
- PGD Adversarial Training: Gram matrix over adversarial directions, estimating local adversarial tangent.
- Data Augmentation: empirical mixture covariance over augmentation deltas.
- Isotropic Regularisation: unique when deployment noise has no preferred directions.
Each method's efficacy is determined by whether its estimator supplies a sufficiently accurate, well-conditioned approximation of Σ0 (as quantified by eigengap conditions and spectrum analysis). The theory predicts explicit failure modes—e.g., when the underlying nuisance subspace is high-rank or ill-conditioned, or when the estimator is mismatched to the nuisance family.
Trajectory Deviation Index (TDI)
The author introduces the Trajectory Deviation Index (TDI), a label-free probe of representation drift under isotropic (typically Gaussian) input perturbation. TDI tracks geometric sensitivity and is used throughout the empirical blocks to measure whether the encoder suppresses drift along label-preserving directions even in the absence of a downstream task loss.
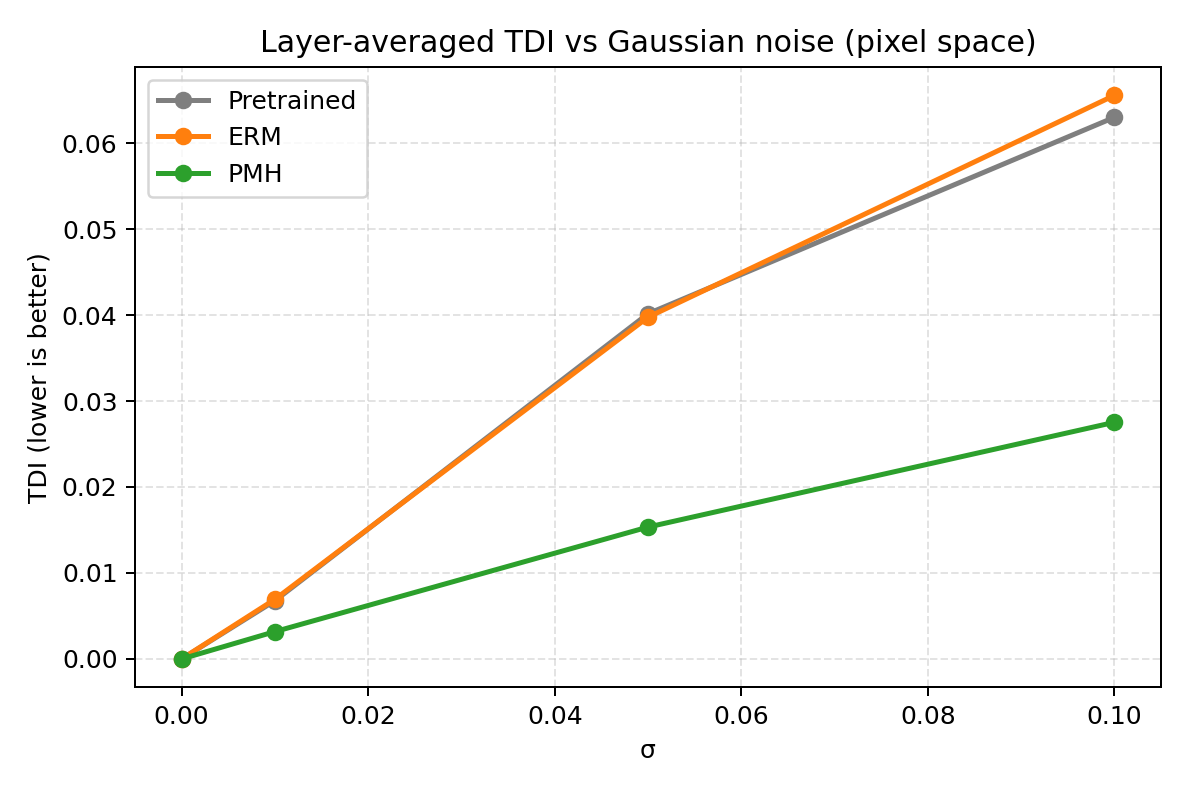
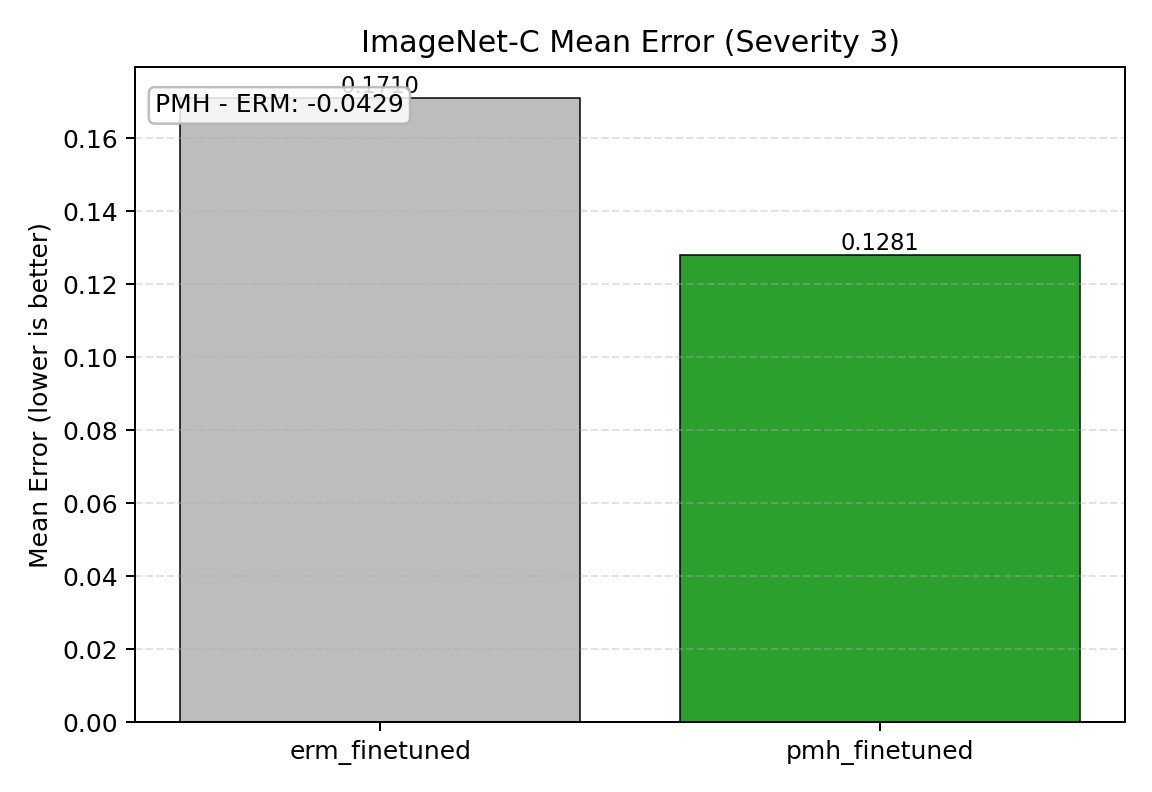
Figure 4: TDI vs. input noise strength: matched PMH suppresses drift across stress levels compared to Gaussian and other controls.
Directional Drift and Falsification Controls
Two essential falsification tests are formalised:
- Random-Σ1 Control (Lemma C): random rank-Σ2 penalties reduce to isotropic regularisation and should not outperform isotropic baselines.
- Signal-Σ3 Control (Corollaries E/EΣ4): penalising along the signal axis (i.e., directions aligned with class-relevant variation) provably hurts task metrics, sometimes below baseline.
Empirical Programme
Thirteen experimental blocks, spanning modalities (vision, language, speech, code, molecules) and model scales (ridge regression to 7B-parameter LLMs), systematically test the predictions of the theory. In twelve of thirteen cases, matched penalties constructed as prescribed outperform isotropic, random, and signal-aligned arms on headline drift or robustness metrics; the sole exception (Office-31) corresponds to a marginal eigengap predicted in advance.
Notably, the theory correctly predicts:
- Matched arms suppress TDI and directional drift along estimated nuisance directions.
- Random and isotropic baselines are indistinguishable under stress when the nuisance is not low-rank.
- Penalising along signal directions is unambiguously detrimental.
- Adversarial training (PGD-AT) trades clean accuracy for robustness, but does not suppress geometric drift as efficiently as matched PMH regularisation.
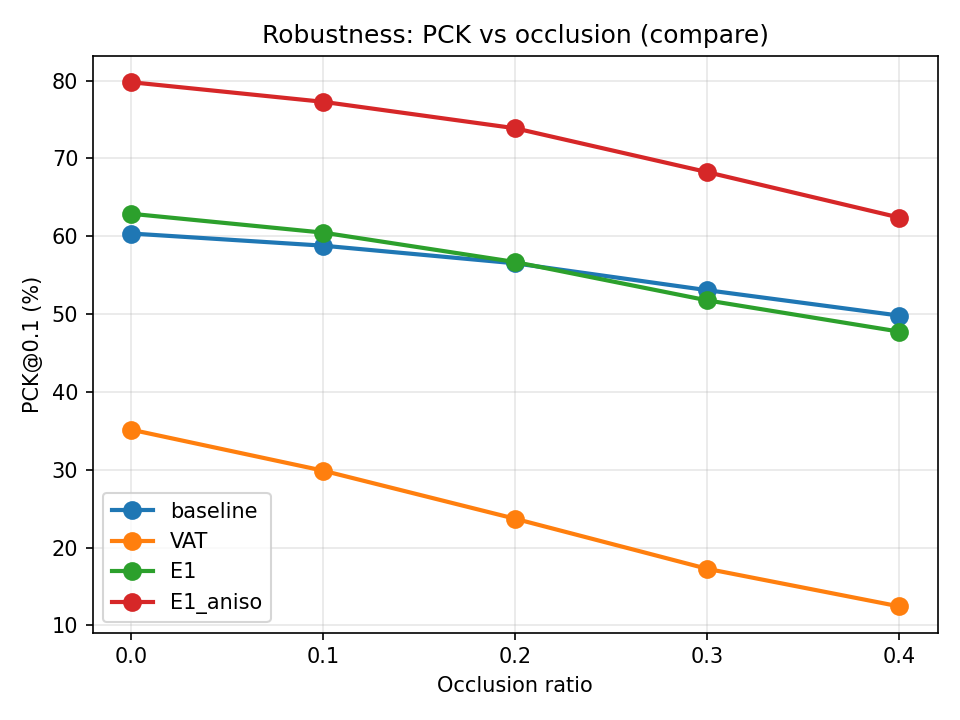
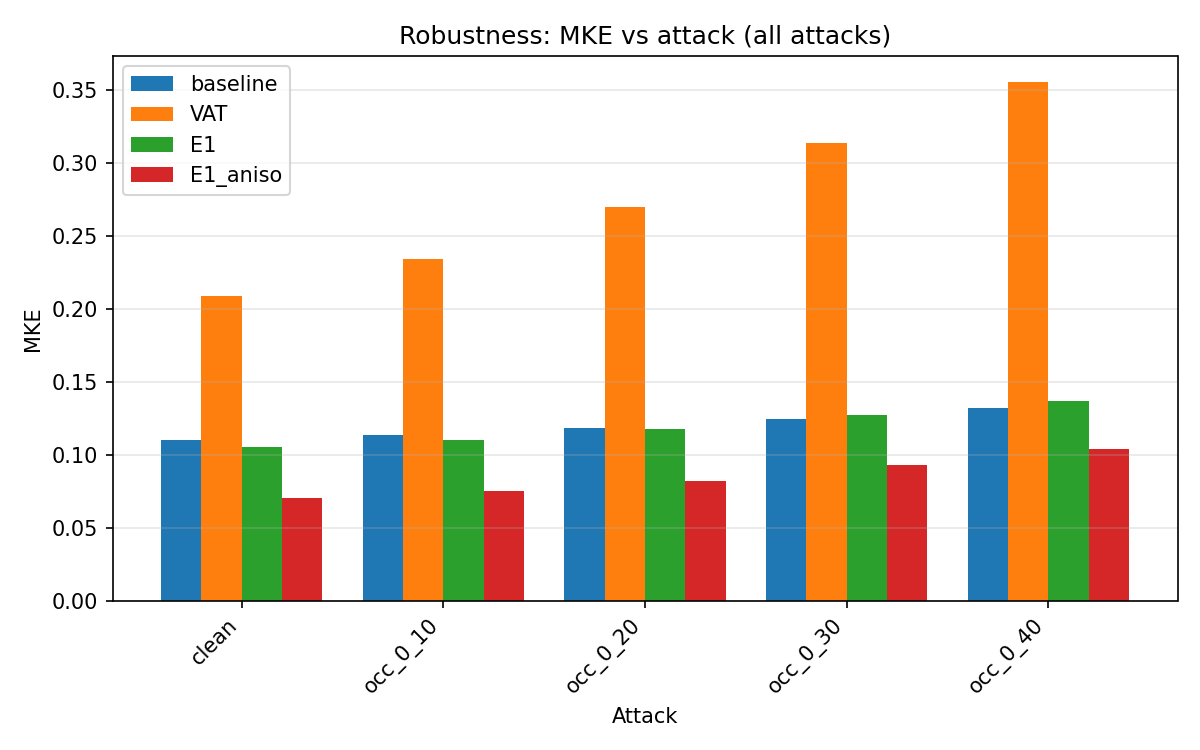
Figure 6: [email protected] (pose estimation) under increasing occlusion: matched anisotropic penalty (E1-aniso) sustains notably higher accuracy under severe occlusion relative to all other controls.
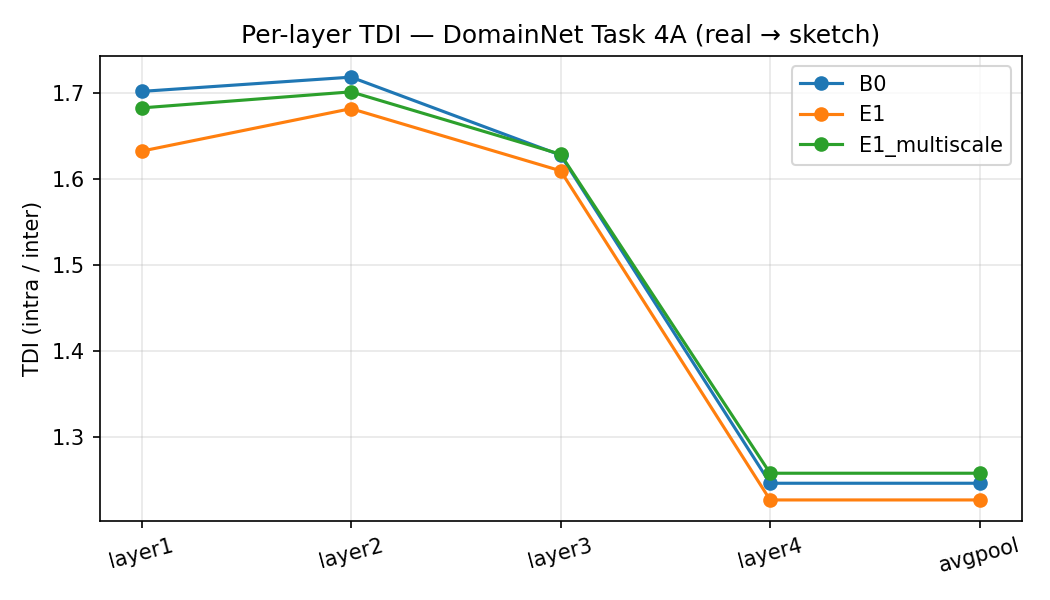
Figure 8: Per-layer TDI panel on domain shift: multiscale Gram matching achieves highest accuracy via final-layer class separation without minimal TDI at lowest layer.

Figure 10: Rare-class recovery in semantic segmentation: multiscale matched penalty recovers classes (e.g., motorcycle/rider) systematically missed by ERM and isotropic pixel penalties.
Implications and Future Research Directions
This work positions the design of robust loss functions as a search for accurate, well-conditioned estimators of deployment nuisance covariance. By making loss function design a first-class parameter (through PSD matrices), and by providing diagnostic/falsification tools, the framework has several implications:
- Architectural Neutrality: The matching principle is agnostic to architecture, as long as the expressivity conditions are met; loss design, not model class, controls robustness.
- Unified View of Robustness/Adaptation: Prevailing empirical practices—adversarial robustness, domain adaptation, augmentation, IRM—are not independent; they are different points in estimator space, and their comparative behaviour is determined by geometric fidelity, not the specifics of their implementation.
- Explicit Failure Modes: Practitioners can anticipate when robustness will fail, either due to estimator ill-conditioning (e.g., eigengap collapse) or theoretical inapplicability (non-label-preserving nuisance, causality requirements, or nonlinearisable perturbations).
- Testability and Falsifiability: Any claim of robustness improvement via regularisation must pass both the random-Σ5 and signal-Σ6 ablations; otherwise, neither geometry nor loss selection targets the true nuisance.
- Separation of Robustness and Accuracy: Geometry (drift suppression) and task accuracy can, and often do, decouple. This is structurally predicted by the theory and should be reflected in evaluation and reporting standards.
Open directions include optimizing estimator selection in mixed-nuisance regimes, developing nonlinearisable or higher-order extensions, and scaling the approach to full-scale RLHF for LLMs. The global reachability of the matched minimum in nonconvex deep models remains an open formal problem; empirically, the method is robust but theoretically this is not yet established universally.
Conclusion
This paper offers a rigorous, falsifiable, and constructively implementable geometric theory of loss function design for nuisance-robust representation learning. By reducing robustness and domain adaptation to the estimation of a core population nuisance covariance and making explicit the necessary and sufficient geometric criteria for drift suppression, the work subsumes a broad swath of empirical machine learning methods under a single unifying principle. The combination of strong theory, systematic ablations, numerical verification across scales, and explicit specification of failure cases marks a significant advance in the principled design of robust machine learning systems.

