Towards a Data-Parameter Correspondence for LLMs: A Preliminary Discussion
Published 19 Apr 2026 in cs.LG | (2604.17384v1)
Abstract: LLM optimization has historically bifurcated into isolated data-centric and model-centric paradigms: the former manipulates involved samples through selection, augmentation, or poisoning, while the latter tunes model weights via masking, quantization, or low-rank adaptation. This paper establishes a unified \emph{data-parameter correspondence} revealing these seemingly disparate operations as dual manifestations of the same geometric structure on the statistical manifold $\mathcal{M}$. Grounded in the Fisher-Rao metric $g_{ij}(θ)$ and Legendre duality between natural ($θ$) and expectation ($η$) parameters, we identify three fundamental correspondences spanning the model lifecycle: 1. Geometric correspondence: data pruning and parameter sparsification equivalently reduce manifold volume via dual coordinate constraints; 2. Low-rank correspondence: in-context learning (ICL) and LoRA adaptation explore identical subspaces on the Grassmannian $\mathcal{G}(r,d)$, with $k$-shot samples geometrically equivalent to rank-$r$ updates; 3. Security-privacy correspondence: adversarial attacks exhibit cooperative amplification between data poisoning and parameter backdoors, whereas protective mechanisms follow cascading attenuation where data compression multiplicatively enhances parameter privacy. Extending from training through post-training compression to inference, this framework provides mathematical formalization for cross-community methodology transfer, demonstrating that cooperative optimization integrating data and parameter modalities may outperform isolated approaches across efficiency, robustness, and privacy dimensions.
The paper presents a unified geometric framework that maps data and parameter operations in LLMs using the Fisher–Rao metric and Legendre duality.
It translates techniques such as pruning, augmentation, low-rank adaptation, and in-context learning into dual geometric operations, enhancing model efficiency.
The study demonstrates cross-domain strategies for continual learning, model merging, and adversarial robustness, paving the way for cooperative optimization.
Towards a Data-Parameter Correspondence for LLMs: A Preliminary Discussion
Introduction
The study systematically establishes a geometric and operational correspondence between data-centric and parameter-centric methodologies for LLMs. Historically, the dichotomy between data-side and parameter-side optimization has limited cross-pollination of theory, practice, and efficiency. By leveraging information geometry—specifically, the Fisher–Rao metric and Legendre duality—the paper formulates a unified framework in which data and parameter operations are treated as dual coordinate systems on the statistical manifold M. This formalism enables translation, hybridization, and mutual enhancement between operations such as pruning, low-rank adaptation, data augmentation, adversarial manipulation, and compositional merging across the full LLM lifecycle: training, post-training compression, and inference.
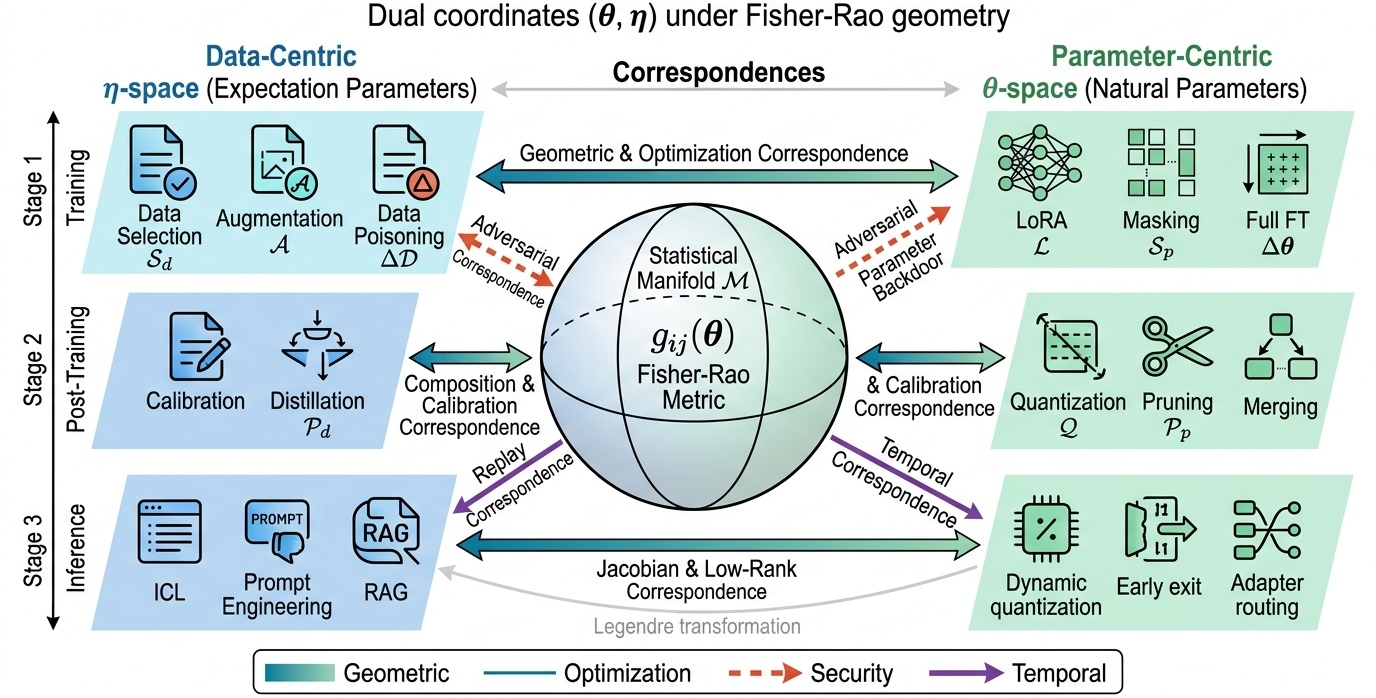
Figure 1: Unified view depicting data-centric (η-space) and parameter-centric (θ-space) operations as duals on the statistical manifold M under the Fisher–Rao metric. Dualities are instantiated across lifecycle stages with manifold volume reduction as a cardinal geometric motif.
Theoretical Foundation: Geometric Correspondence
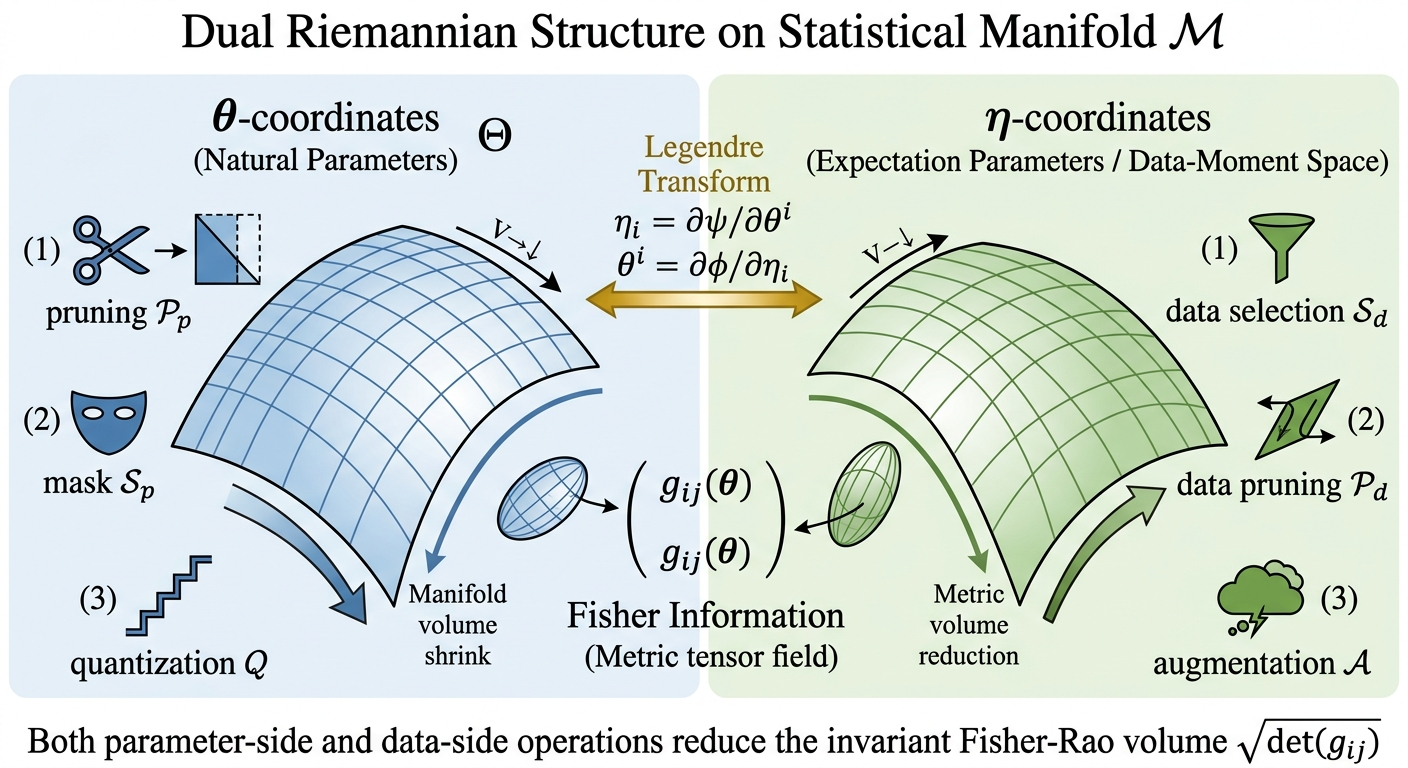
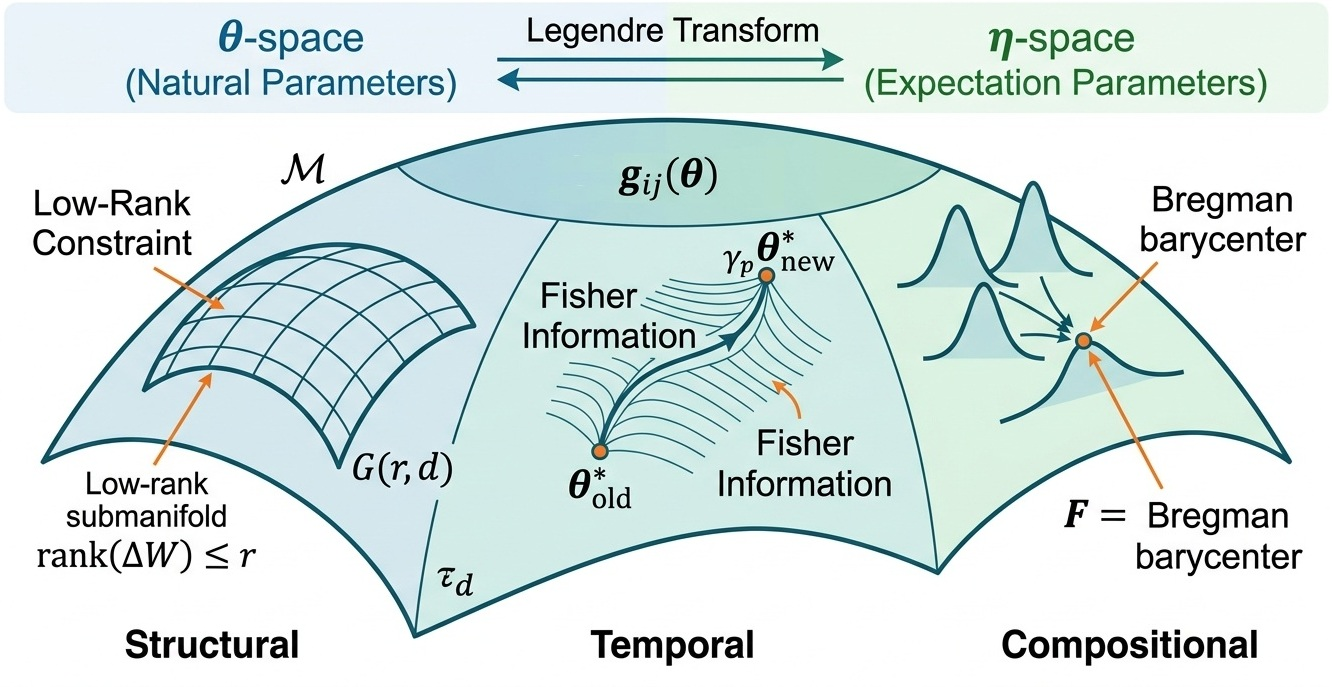
The core insight is the identification of dual geometric structures for data and parameter manipulations, instantiated on the information-geometric statistical manifold M. The Fisher-Rao metric gij(θ) encapsulates the Riemannian geometry, enabling duality between natural parameters θ (weights) and expectation parameters η (moments of data distribution). Pruning, quantization, and augmentation in both domains are characterized as volume-reduction procedures, limiting the degrees of freedom on M either by direct coordinate constraints or by effective support restriction.
Figure 2: Dual Riemannian structure—data operations perturb expectation parameters, parameter operations constrain natural parameters; both shrink the invariant volume form det(gij) under Legendre duality.
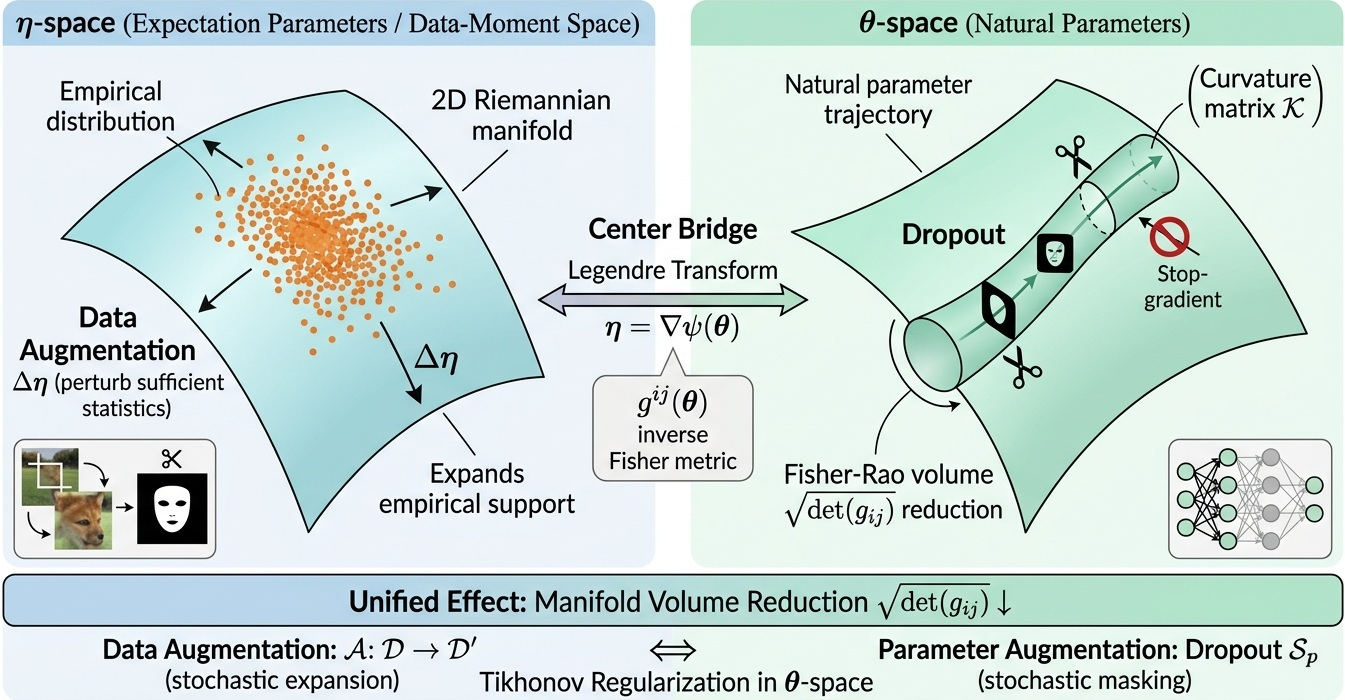
Continuous relaxations (e.g., Tikhonov regularization) and stochastic augmentations (e.g., dropout) correspond to geometric regularization and smoothing of the loss landscape, with their effect interpretable in both parameter and data moment spaces.
Figure 3: Data augmentation and parameter dropout viewed as dual Fisher-Rao volume reducing mechanisms—input support extension in η0-space versus stochastic masking in η1-space.
Structural Correspondence: Low-Rank Adaptation and In-Context Learning
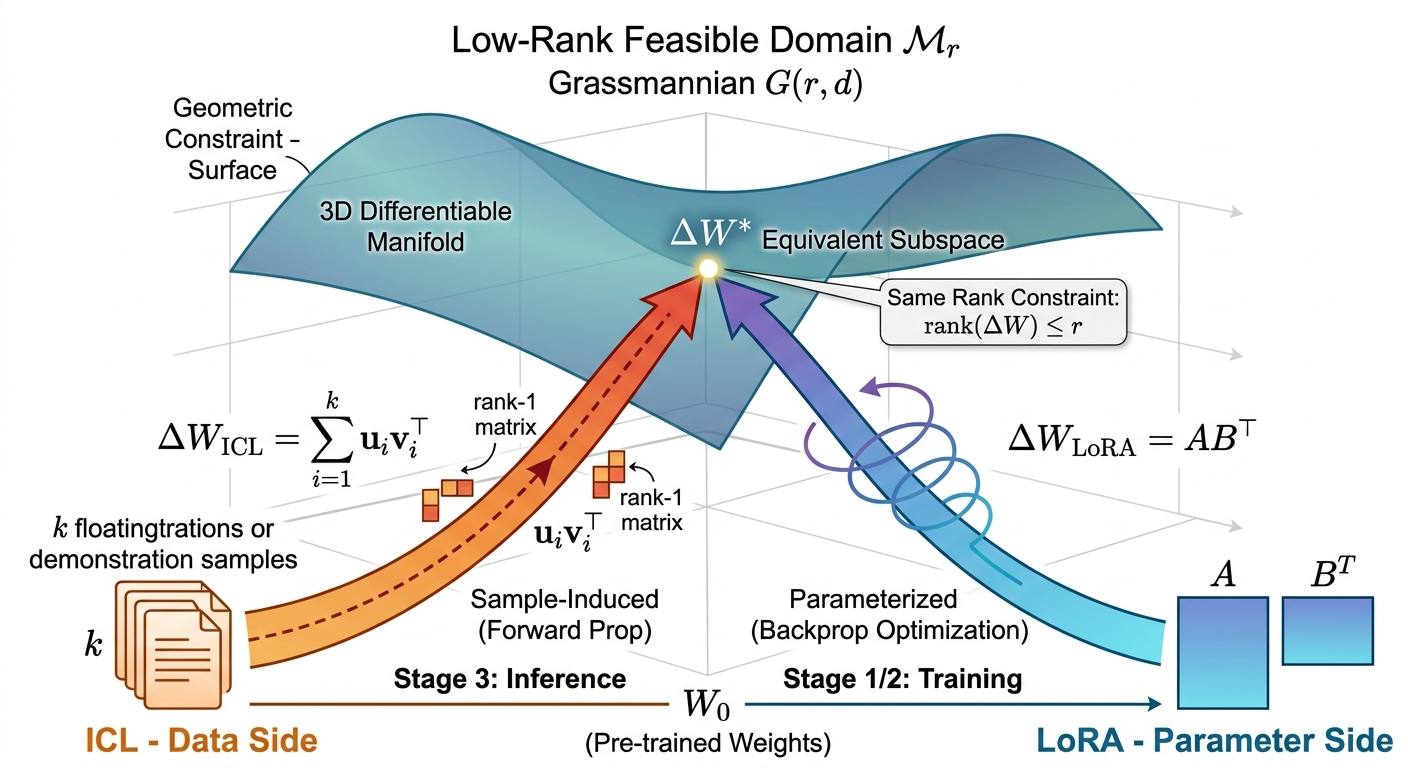
The framework formally unites in-context learning (ICL) and low-rank adaptation (LoRA) as dual mechanisms for subspace adaptation on the Grassmannian manifold η2. While ICL exploits data-induced, sample-composed low-rank updates in frozen-weight scenarios (inference), LoRA explicitly optimizes rank-constrained updates in the parameter space. The effective dimension of adaptation is governed by context length (ICL) or rank (LoRA), with a one-to-one mapping between number of demonstrations and rank of parameter adaptation.
Figure 4: ICL (left) generates low-rank updates through context manipulation; LoRA (right) parameterizes the same subspace geometrically, unified on η3.
This leads to algorithmic strategies where the subspace induced by ICL can be identified and then further refined using LoRA, obviating the need for full-parameter update steps and enabling coarse-to-fine optimization.
Temporal and Compositional Correspondences: Continual Learning and Model/Data Mixing
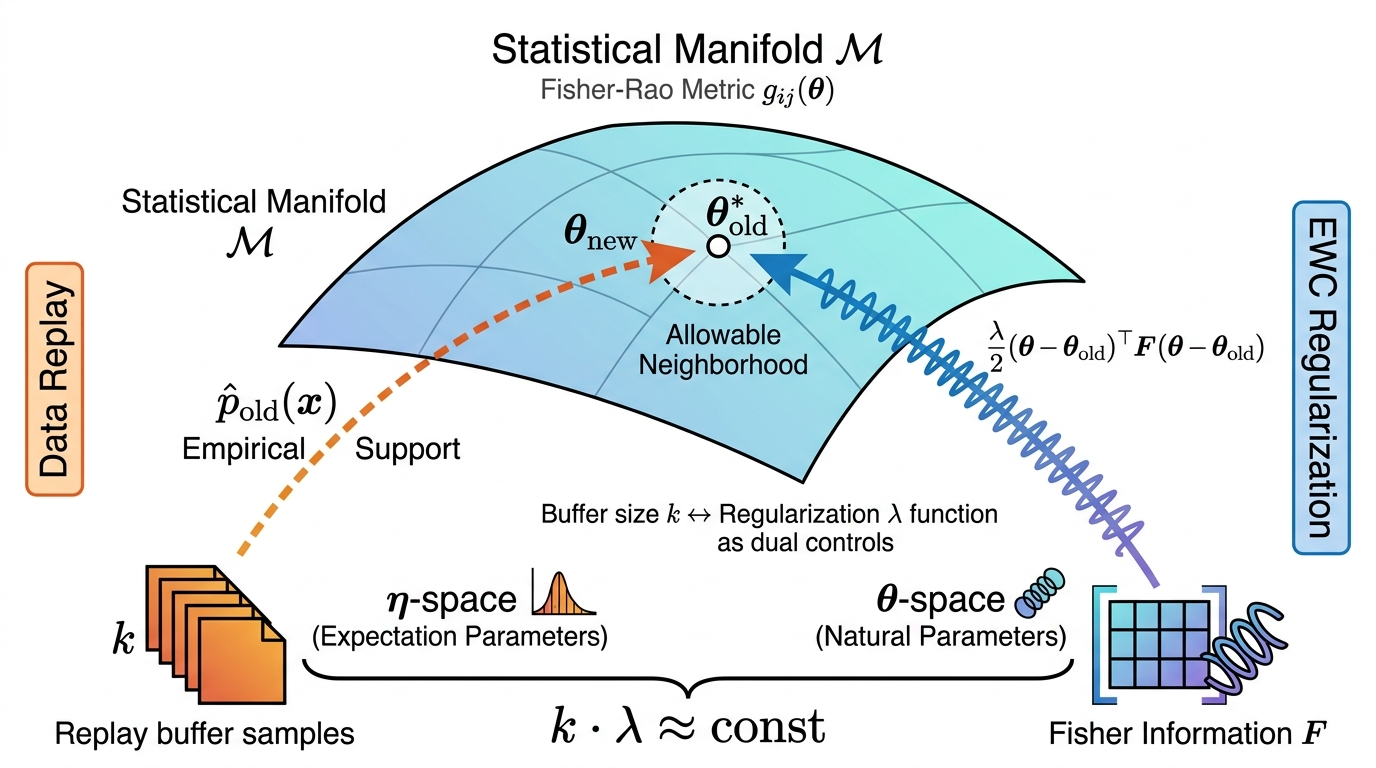
Continual learning is mapped to dual strategies: experience replay constrains empirical support in expectation parameter space, while Elastic Weight Consolidation (EWC) applies curvature penalties via Fisher information in the parameter manifold. A direct trade-off is established—given a fixed overall constraint on deviation in η4, increasing replay buffer size allows reduced EWC regularization and vice versa.
Figure 5: Data replay maintains η5-space support; EWC manages Fisher curvature in η6-space. Both delimit the parameter trajectory around prior optima on the manifold.
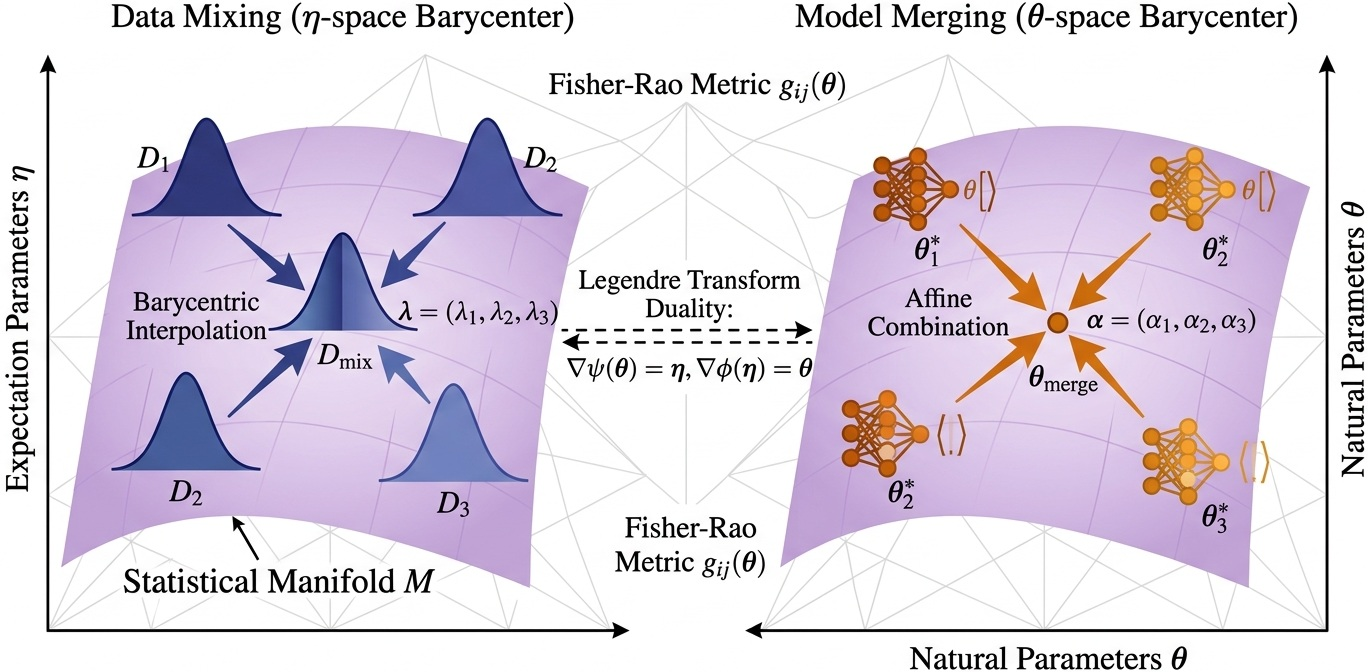
Model merging and data mixing are demonstrated as affine and barycentric operations in the dual spaces. Mixing distributions in η7-space (via optimal coefficients) is dual to model parameter averaging or merging in η8-space, with both interpretable as finding Bregman barycenters—a concrete instantiation enabled by the manifold structure.
Figure 6: Data distributions mixed barycentrically in η9-space are dual to parameter interpolations in θ0-space, linked via Legendre transforms.
Security and Privacy Dualities
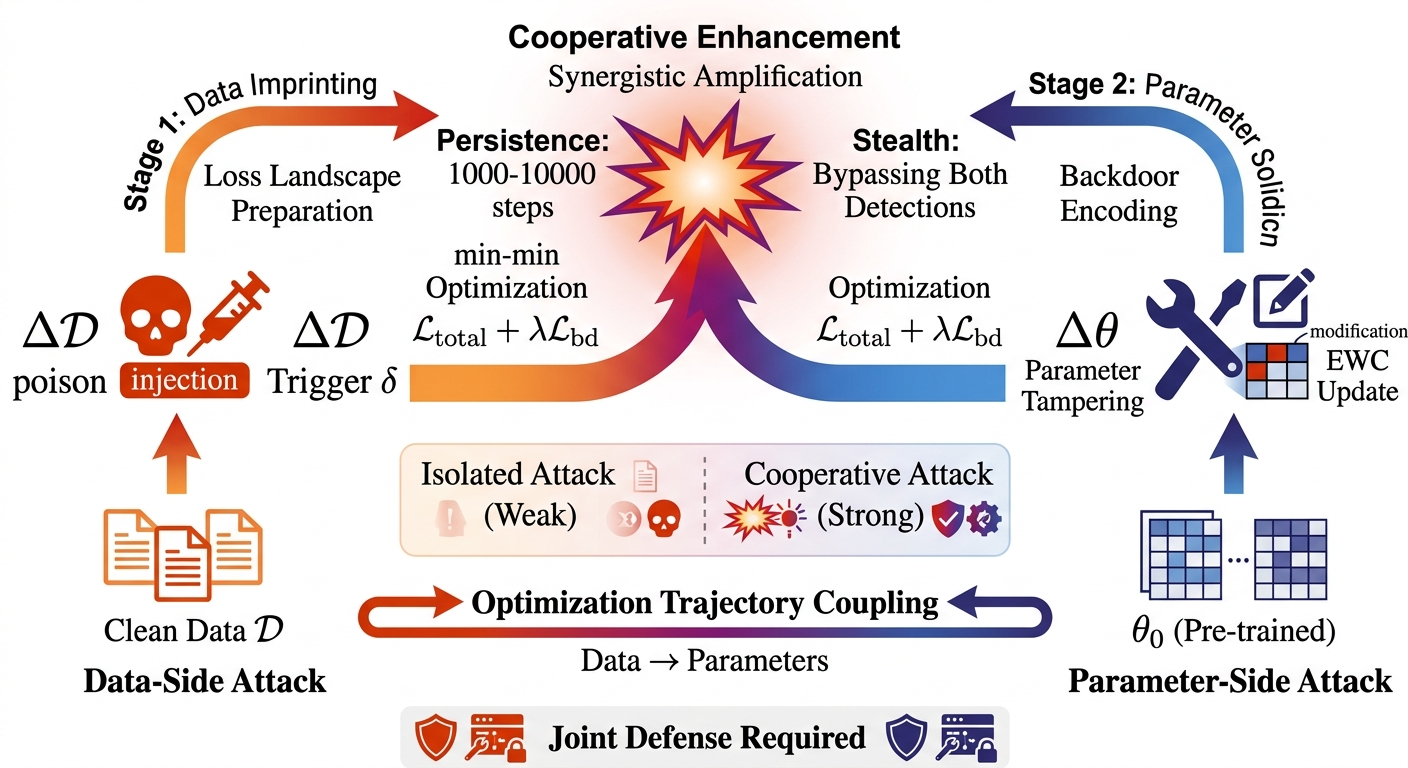
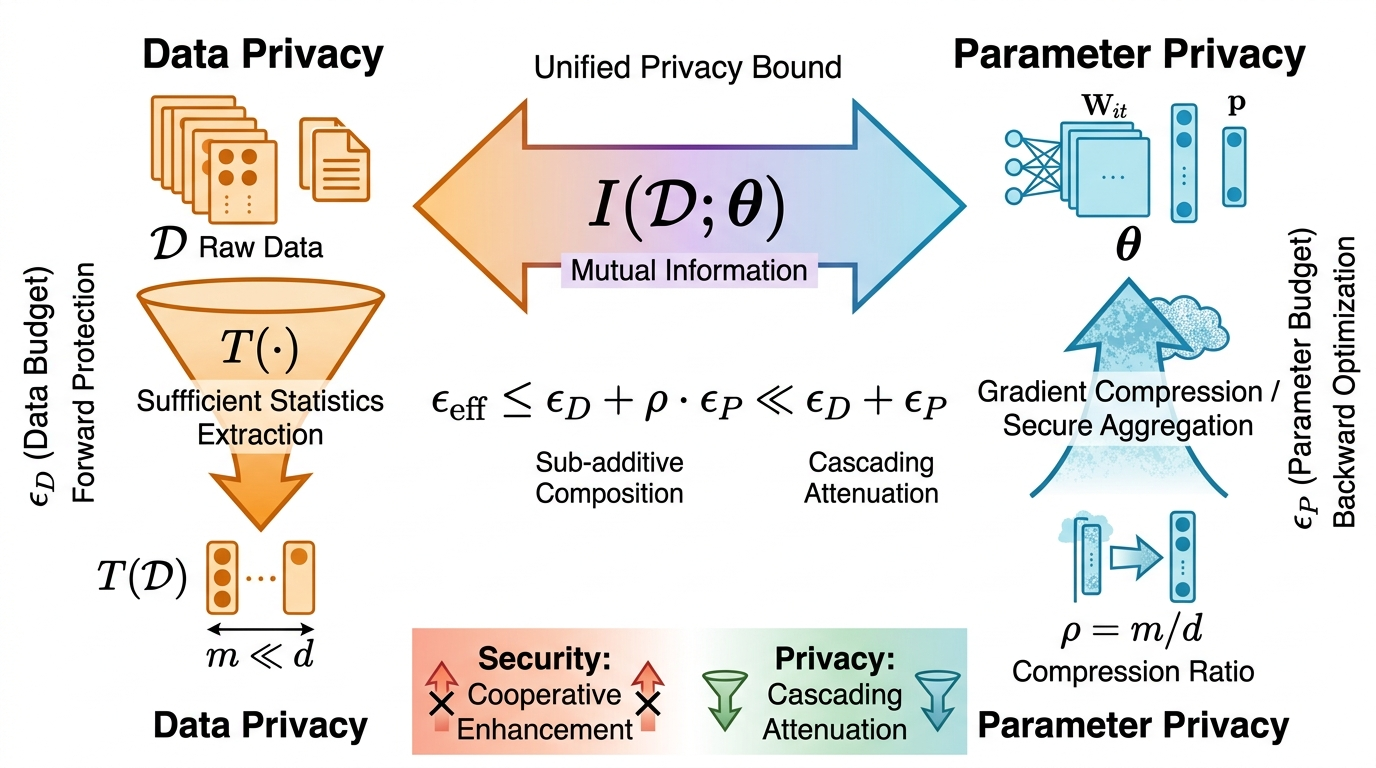
The framework reveals that adversarial manipulations (e.g., poisoning, backdoor implantation) demonstrate strong cooperative (synergistic) interaction between data and parameter interventions. The geometry of the loss landscape determines the detectability and persistence of backdoors, with min-min optimization jointly shaping basin width and curvature to ensure stealth and endurance of malicious triggers. Conversely, privacy-preserving mechanisms (compression, noise, dimensionality reduction) exhibit cascading attenuation properties: data compression reduces mutual information accessible to parameters, and parameter-side protection multiplicatively benefits from aggressive data-space budget reduction. The fundamental coupling is through the mutual information θ1, yielding sub-additive privacy bounds.
Figure 7: Cooperative attack geometry—data-side trigger design sets the loss landscape, parameter-side solidification ensures backdoor persistence, surpassing linear accumulation.
Figure 8: Privacy duality—information-theoretic bounds propagate across data and parameter spaces, with cascading composition providing enhanced privacy relative to isolated mechanisms.
Inference-Stage Duality: Jacobian Image Spaces and Testing-Time Constraints
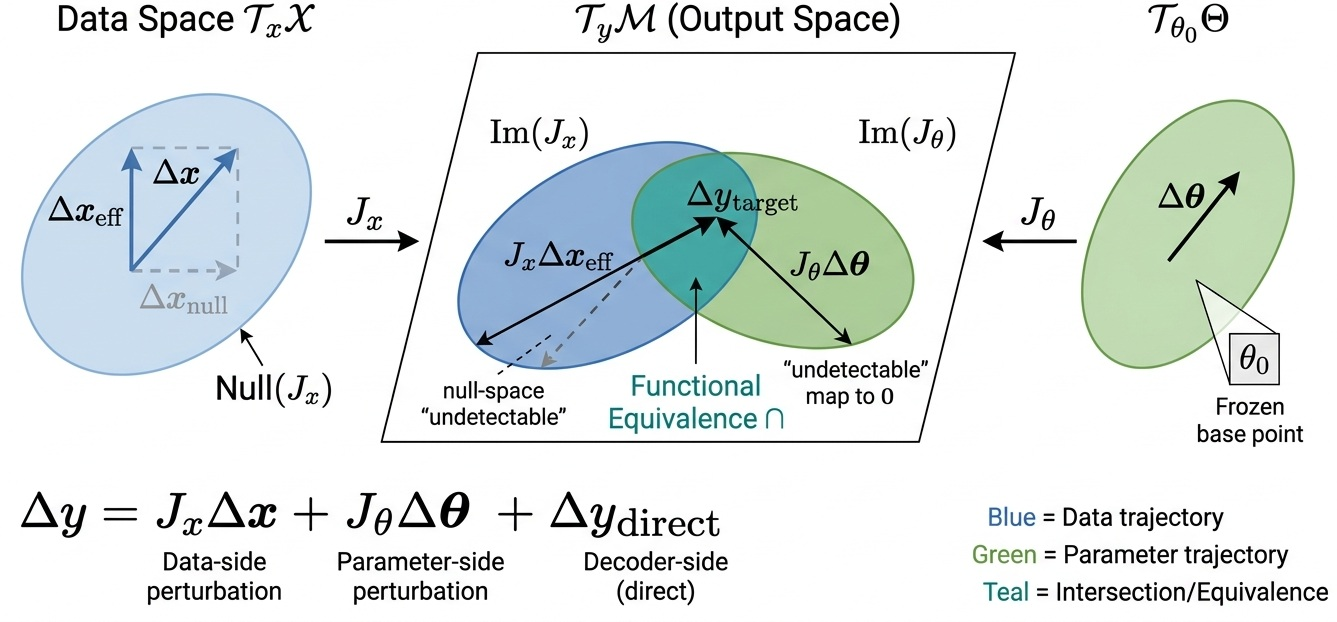
At inference, the local linear structure defined by Jacobian image spaces θ2 and θ3 enables functional equivalence: any target output perturbation in their intersection can be achieved by data-side (prompt/context) or parameter-side (adapter) manipulation. The null spaces of these Jacobians formalize limits on detectability and characterizability of adversarial attacks, quantifying the inherent vulnerability surface.
Figure 9: Jacobian image space duality—effective perturbation regions and undetectable null spaces underpin functional equivalence for data and parameter operations at inference.
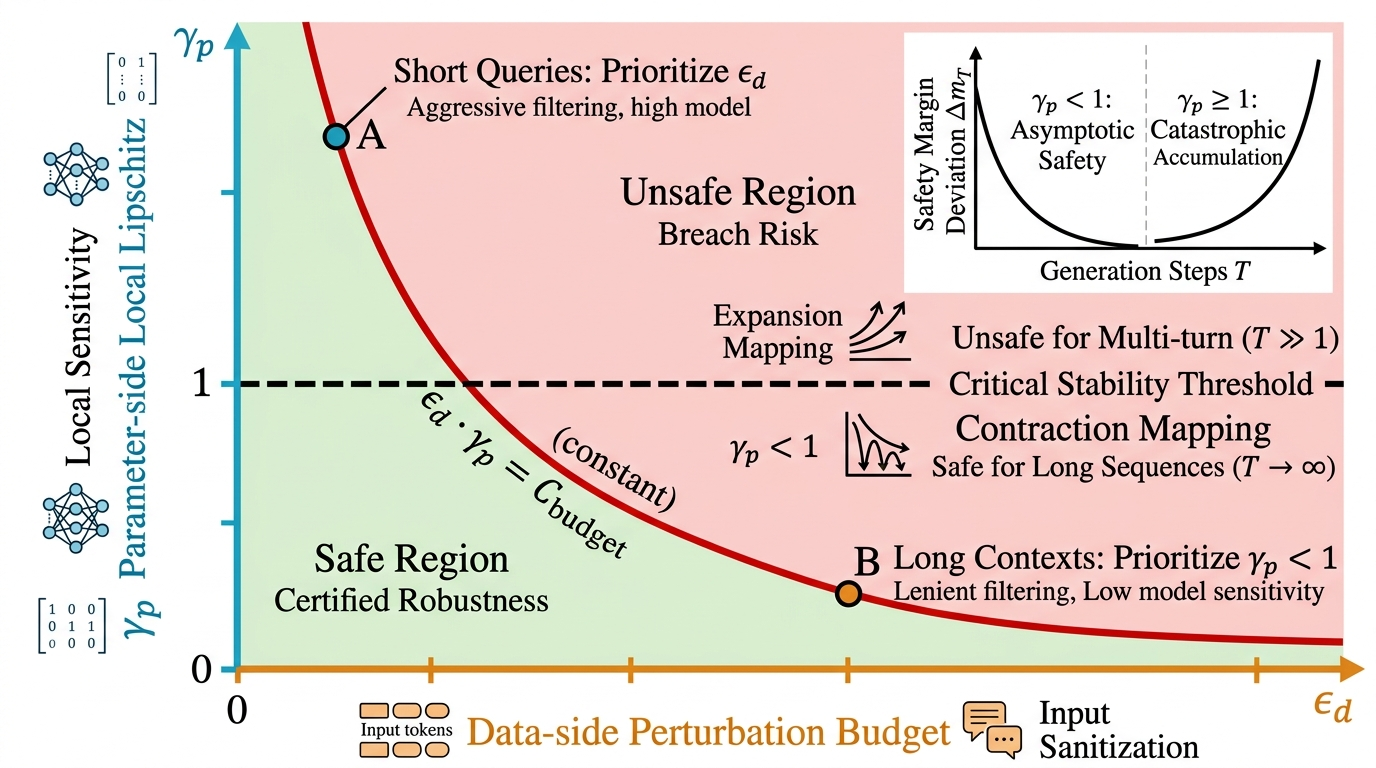
Inference security constraints manifest as a product bound: for defense, the maximum allowable product of data perturbation budget and parameter-space Lipschitz constant (θ4) must not exceed a fixed safety budget. Only when θ5 is asymptotic robustness achievable for long-form autoregressive generation, highlighting the criticality of Lipschitz-enforcing regularization in high-risk deployments.
Figure 10: Testing-time robustness is dictated by the product of input sanitization (data-side) and model sensitivity (parameter-side) budgets, with a phase transition at θ6.
Algorithmic Realization
All constructs—gradient interaction matrices, Fisher diagonal, Jacobian projections, and local Lipschitz constant estimation—admit streaming implementations via vectorized automatic differentiation (JVP/VJP), stochastic Hutchinson sketching, and power iteration. This ensures practical deployability, with sublinear memory scaling and tight control of computational overhead.
Implications and Future Directions
Theoretical Impact:
This data-parameter correspondence establishes a robust foundation for cross-community methodology transfer. Problems such as model compression, continual learning, multi-task fusion, and robustness certification can now be addressed through a common language. The identification of boundaries for these dualities (e.g., nonlocal divergence, non-differentiable operations, adversarial regime shifts) informs both technical limitations and research priorities.
Practical Impact:
Resource allocation across structural (rank, sample), temporal (replay, regularization), compositional (mixing entropy), privacy, and security budgets can be systematically aligned, enabling jointly optimal trade-offs.
Future Directions:
Promising avenues include extending from local to global geometry (energy-based dualities), addressing non-differentiable operation boundaries, and formalizing information-theoretic privacy and adversarial proofs under more realistic assumptions.
Conclusion
The results demonstrate that data and parameter operations in LLMs, across all lifecycle stages, are not merely analogous but are inherently dual, geometric manifestations on a shared manifold. This unification leads to superior, cooperative optimization paradigms for efficiency, robustness, and privacy, with strong prospects for future advances in LLM training, deployment, and security.
Figure 11: Synthesis: data-parameter correspondences viewed as multiple dual operations along structural, temporal, and compositional dimensions with security/privacy boundaries on θ7.
The framework challenges the prevailing orthodoxy of separation between data and parameter cognition in LLM research, presenting a compelling roadmap for the next generation of principled, geometry-aware, and cooperative machine learning algorithms.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.