- The paper demonstrates that reweighted objectives yield provably tighter variational bounds by integrating optimal time-dependent ELBOs.
- Empirical results on ImageNet 64×64 show that simple and flow-matching weightings achieve lower FID scores and enhanced sample diversity.
- The work extends the reweighted loss framework to discrete masked diffusion models, bridging theory with robust performance gains.
Demystifying Diffusion Objectives: Reweighted Losses are Better Variational Bounds
Motivation and Theoretical Foundation
The paper "Demystifying Diffusion Objectives: Reweighted Losses are Better Variational Bounds" (2511.19664) provides a rigorous theoretical analysis of reweighted objectives commonly employed in diffusion model training for generative modeling, with a primary emphasis on both continuous Gaussian and discrete (masked) diffusions. The standard practice of optimizing reweighted ELBOs, rather than the ELBO itself, is shown to have a critical theoretical justification grounded in variational inference.
By constructing a cascade of time-dependent variational lower bounds on the data log-likelihood, the authors demonstrate that reweighted objectives yield provably tighter bounds—i.e., smaller data-model KL-divergences—relative to the conventional ELBO. This formalism establishes the reweighted loss as a sum over more "1" time-dependent ELBOs, each improving the variational bound at respective timesteps. Furthermore, nonzero weights at early timesteps ensure adequate exposure of the denoiser to all noise regimes, an essential prerequisite for successful ancestral sampling.
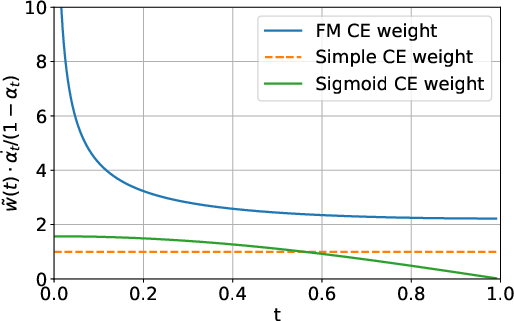
Figure 1: Total cross-entropy loss weight under cosine schedule αt=1−cos(2π(1−t)).
Extension to Masked Diffusion Models
Prior to this work, discrete diffusion and masked models (e.g., MaskGIT) utilized heuristic loss weightings. The paper generalizes the cascade-of-bounds interpretation to masked diffusion, formalizing the reweighted objective as an improved variational bound applicable to discrete domains. By matching weighting functions (e.g., flow-matching, sigmoid, simple) from continuous diffusion to the log-SNR parameterization of masked diffusion, the authors bridge theoretical justification across modalities and offer reweighted loss functions that correct for the lack of invariance in the time/parameter schedule.
Empirically, the "simple" weighting—summing denoising losses over mask inputs, normalized by the number of masks in a batch—emerges as a special case of the improved variational bound framework. This alignment accounts for the strong sample quality previously observed for such weightings in masked image modeling, now explained with formal probabilistic grounding.

Figure 2: Class-conditional samples from the masked diffusion model (324M, simple weighting) on ImageNet 64×64, showing intra-class diversity and excellent distribution coverage.
Empirical Evaluation
Extensive experiments are conducted on ImageNet 64×64 using class-conditional masked diffusion models. Switching from standard ELBO training to monotonic reweighted objectives (sigmoid, flow-matching, simple) produces marked improvements in sample quality, as quantified by FID and Inception Score. Models trained on simple and flow-matching weightings not only surpass masked autoencoder and autoregressive designs (e.g., MaskGIT, MAR, FractalMAR) but also approach the perceptual quality of current state-of-the-art continuous Gaussian diffusion models (ADM, EDM, VDM++).
A model with 324M parameters, trained with the simple weighting, achieves an FID of 1.92 while displaying substantial diversity per class—a strong numerical result for masked diffusion frameworks, as depicted below.




Figure 3: Monotonic weighting functions for masked diffusion (ELBO, Sigmoid, FM, Simple), each improving sample quality with corresponding FID scores annotated.
Notably, models trained on non-monotonic objectives (IDDPM, EDM) show degraded FID, confirming the necessity of monotonicity for their theoretical validity and empirical effectiveness.


Figure 4: Samples from masked diffusion models with non-monotonic weighting (IDDPM, EDM) exhibit poorer generative quality compared to monotonic counterparts.
Implications and Prospects
The formalism established in this paper unites practical heuristics and principled training of diffusion models under a universal variational bound framework. The recognition that improved bounds derive from the integration of optimal decoder transitions directly informs future exploration of adaptive or data-driven weighting schedules, potentially automating optimal objective construction for a wider array of data domains and modalities.
From a theoretical standpoint, the cascade-of-bounds interpretation strengthens the statistical rigor underpinning reweighted diffusion objectives, and highlights the trade-off between tightness of the bound and the tractability of sample generation. Practical implications concern the convergence of best practices for weighting schemes: monotonic functions anchored at boundary points of the schedule yield empirically superior sample quality.
This groundwork sets the stage for further research in multi-modal generative modeling, automated weighting strategies, and deeper integration of variational perspective in diffusion architectures.
Conclusion
This paper delivers an authoritative theoretical foundation for the prevalent use of reweighted losses in diffusion model training, reformulating them as improved variational bounds whose empirical efficacy is now decisively justified. By generalizing this result to masked diffusion models and providing strong empirical validation, the authors resolve a longstanding disconnect between theory and practice, serving as a catalyst for future methodological innovations in generative modeling.