SEGA: Spectral-Energy Guided Attention for Resolution Extrapolation in Diffusion Transformers
Abstract: Diffusion transformers (DiTs) have emerged as a dominant architecture for text-to-image generation, yet their performance drops when generating at resolutions beyond their training range. Existing training-free approaches mitigate this by modifying inference-time attention behavior, often through Rotary Position Embeddings (RoPE) extrapolation combined with attention scaling. However, these strategies apply a uniform and content-agnostic scaling across RoPE components with distinct frequency characteristics, inducing a trade-off between preserving global structure and recovering fine detail. We introduce SEGA, a training-free method that dynamically scales attention across RoPE components according to the latent's spatial-frequency structure at each denoising step. This adaptive scaling improves both structural coherence and fine-detail fidelity. Experiments show that SEGA consistently improves high-resolution synthesis across multiple target resolutions, outperforming state-of-the-art training-free baselines.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-Language Summary of “SEGA: Spectral-Energy Guided Attention for Resolution Extrapolation in Diffusion Transformers”
1) What is this paper about?
This paper shows a simple way to make text-to-image AI models create very large, sharp pictures (like 4K and beyond) without retraining them. The method is called SEGA. It tweaks how the model pays attention to different parts of an image while it’s being generated, so big shapes stay correct and tiny details stay crisp—even at sizes bigger than the model was trained on.
2) What questions are the researchers asking?
- Why do image models that work great at normal sizes start to blur, repeat patterns, or break shapes when asked to make much bigger images?
- Can we fix this without retraining the model (which is slow, costly, and needs lots of high-resolution data)?
- Can a one-step add-on, used only during image generation, improve both large structures (like layout and object placement) and fine details (like textures and edges)?
3) How does their method work (in simple terms)?
First, a quick idea of how these models work:
- Modern text-to-image models (Diffusion Transformers) create images step by step from noise, using “attention” to decide which parts of the picture relate to which words and pixels.
- They use a trick called Rotary Position Embeddings (RoPE) to remember where each image patch is. Think of RoPE as a way to label “where” things are so attention can line up features correctly.
The problem at high resolution:
- When you ask for a bigger image, there are many more patches (like having a much bigger puzzle). The model sees positional patterns it never saw during training. Its attention spreads too thin, causing blur, repeated textures, or broken structure.
- Past fixes turn one “global knob” to sharpen attention the same amount everywhere. But images aren’t uniform: big shapes (low frequencies) and tiny textures (high frequencies) need different treatment at different times.
What SEGA does:
- Imagine a music equalizer. If the “bass” is too quiet, you boost it; if the “treble” is too loud, you turn it down. SEGA does this for images.
- At every step of generation, it quickly checks the current in-progress image to see which “frequencies” have more or less energy:
- Low frequencies = big, smooth shapes and layouts.
- High frequencies = fine details and textures (like hair or leaf veins).
- SEGA then gives more attention boost to frequencies that look underemphasized and less boost to frequencies that already dominate. This keeps both structure and detail in balance.
- It also uses a simple “how peaky is the spectrum?” score (spectral flatness) to decide how strongly to apply these boosts. Early on, when everything is mostly noise, it does very little. Later, as the picture takes shape, it adjusts more.
In practical steps (lightweight and training-free):
- The model takes the current hidden image state and runs a fast “frequency check” (like splitting music into bass/mid/treble).
- It maps these frequency bands to the model’s RoPE components (which naturally align with different spatial frequencies).
- It scales each RoPE component differently: more for weak bands, less for strong bands, plus a small global baseline factor depending on how much larger the requested resolution is.
4) What did they find, and why does it matter?
Main results:
- SEGA produces bigger, higher-quality images that hold together well globally (correct layout, fewer broken shapes) and look detailed up close (crisper textures).
- It beats strong training-free baselines on several models (like Flux and Qwen) and at many sizes (including 4096×4096 and other 4K variants).
- It works consistently—even for very large images with more than 36 million pixels.
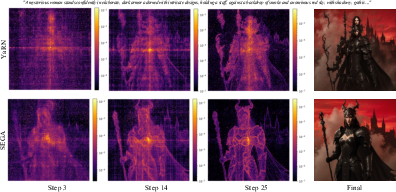
- Visualizations show SEGA keeps attention focused and stable earlier in the process, avoiding the “attention dilution” problem.
- Ablation tests (turning parts on/off) show both the per-frequency adjustments and the global strength control matter. Together they perform best.
Why it matters:
- You can unlock high-resolution image generation from existing models without collecting new data or retraining.
- You get sharper posters, wallpapers, and print-ready images with fewer artifacts.
- It’s simple to plug in and adds almost no complexity.
5) What’s the bigger impact?
SEGA suggests a new, practical way to handle “resolution jumps” in AI image generation: don’t treat every detail the same—adjust attention like an equalizer based on what the image currently needs. This idea could:
- Save time and computing costs by avoiding retraining for each new target resolution.
- Generalize to other areas, like video, where keeping structure and detail at high resolution is also hard.
- Inspire more “content-aware” attention methods that look at the picture in progress and adapt on the fly.
In short: SEGA is a smart, plug-and-play “attention equalizer” that helps AI make large, beautiful images without the usual high-res headaches.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to guide future research:
- Validation of the RoPE–spatial-frequency coupling: the paper assumes a direct, stable mapping from RoPE angular frequencies () to spatial wavelengths in the token grid, but does not empirically verify this coupling across layers, heads, patch sizes, and different DiT architectures.
- Layer- and head-specific behavior: SEGA appears to apply the same per-dimension scaling across layers and heads; the potential benefits of per-layer or per-head spectral modulation (given known specialization across layers/heads) remain unexplored.
- Robustness to different RoPE extrapolation schemes: SEGA is evaluated primarily with NTK-aware RoPE (with limited ablations for YaRN/DyPE); it remains unclear how sensitive the method is to the specific RoPE variant and how to best compute when RoPE parameters are modified.
- Generality beyond RoPE: the approach is tailored to RoPE; it is unknown whether analogous spectral-energy-guided mechanisms can be devised for other positional encodings (e.g., learned absolute embeddings, ALiBi), or for hybrid/relative schemes used in some DiTs.
- Where to tap the latent: the paper does not specify at which layer(s) the 2D latent map is extracted for FFT analysis; assessing the impact of tapping earlier vs. later feature maps (and whether multi-level fusion helps) is left open.
- Channel averaging heuristic: averaging channels to form may discard informative structure; whether learned or adaptive channel weighting (or multi-channel spectral statistics) would yield superior scaling remains unknown.
- Discretization and binning choices: the effects of FFT resolution, axis/radial bin sizes, band assignment for frequency bins, and smoothing on stability and quality are not systematically studied.
- Spectral statistic choice: spectral flatness (Wiener entropy) is used to gate the scaling, but alternative statistics (e.g., spectral slope, entropy of band energies, kurtosis, anisotropy measures) are not compared; the best criterion for different image/content regimes is unclear.
- Hyperparameter sensitivity: the exponents (in ) and (in the flatness gate), as well as normalization and nonlinearity choices (e.g., ), are set empirically without a principled selection procedure or sensitivity analysis.
- Theoretical understanding: there is no formal analysis linking dimension-wise scaling to changes in the attention kernel, effective receptive fields, and stability of denoising dynamics under resolution extrapolation.
- Early-step behavior under heavy noise: while the flatness gate is intended to suppress scaling when the spectrum is near-flat, how robust this is across different noise schedules, samplers, and rectified-flow vs. DDIM/DDPM settings is not quantified.
- Interaction with classifier-free guidance (CFG) and other guidance strategies: the paper does not analyze how SEGA interacts with different CFG strengths, negative prompts, or auxiliary guidance (e.g., aesthetic, edge, face guidance).
- Integration with multi-stage methods: although compared against multi-stage guidance baselines, it remains unexplored whether SEGA is complementary to them (e.g., as a plug-in within I-Max/HiFlow pipelines).
- Failure modes and safety valves: the potential for over-amplifying spurious high-frequency features, ringing-like artifacts, or over-sharpening in low-texture scenes is not analyzed; no mechanism to detect/mitigate such cases is described.
- Extreme resolutions and aspect ratios: despite claims of “exceeding 36M pixels,” systematic evaluation beyond 4096² and across extreme aspect ratios is limited; memory/latency trade-offs and stability at these scales are unreported.
- Compute and memory overhead: the cost of per-timestep 2D FFTs and spectral operations (vs. plain YaRN/NTK) is not quantified; scalability of SEGA’s overhead with resolution and number of steps is an open question.
- Applicability to U-Net diffusion models: the method is demonstrated on DiTs; whether analogous spectral-energy-guided attention helps U-Net backbones (with or without RoPE) remains untested.
- Cross-dataset generalization: evaluations focus on Aesthetic-4K and a zero-shot prompt set; robustness across diverse distributions (e.g., photorealistic vs. stylized, medical, satellite, highly repetitive textures) is not established.
- Text rendering and fine-structure benchmarks: the impact on small text legibility, faces, and precise line art at ultra-high resolutions is not specifically measured; targeted benchmarks are needed.
- Statistical robustness: improvements are reported without variance across seeds or statistical significance testing; reproducibility and confidence intervals for metrics are not provided.
- Choice of evaluation metrics: FID at ultra-high resolutions and FID-p variants may be unreliable; a broader set of human-consistent metrics or user studies could better assess perceived quality and structural fidelity.
- Temporal/modal extension: the authors speculate about benefits for video or other modalities, but SEGA’s behavior under temporal consistency constraints, multi-view coherence, or 3D-aware diffusion remains untested.
- Interaction with patch size/tokenization: how the mapping from token-grid frequencies to pixel-space frequencies depends on patch size, latent downsampling, or tokenization schemes is not examined.
- Uniform vs. adaptive : depends only on resolution ratio; exploring content- or step-adaptive reference scaling (or learning from data) is an open direction.
- Perceptual trade-offs across prompts: while qualitative diversity is shown, a systematic analysis of when SEGA helps most (e.g., highly textured vs. smooth scenes) and when it might hurt is missing.
- Compatibility with training-time strategies: whether SEGA remains beneficial for models trained with randomized positional encodings, multiscale curricula, or explicit spectral regularization is unexplored.
- Online stability and convergence: no diagnostics (e.g., attention entropy, spectral evolution curves, token-level consistency) are provided to characterize convergence or detect unstable runs at very high resolutions.
Practical Applications
Immediate Applications
The following applications can be deployed now with minimal engineering effort by integrating SEGA’s training-free, RoPE-compatible attention scaling into existing inference pipelines.
- High-resolution creative asset generation for design and advertising
- Sectors: media/entertainment, marketing, printing
- Tools/products/workflows: plug-in for Hugging Face Diffusers, ComfyUI/Forge/Automatic1111 “SEGA node,” in-house inference microservice that wraps Flux/Qwen with SEGA for 4K–8K output; prepress pipelines that directly render posters/billboards without separate super-resolution
- Value: improved structural coherence and fine detail at 4K+ without retraining; fewer stitching or multi-stage passes
- Assumptions/dependencies: access to RoPE-based DiTs (e.g., Flux, Qwen); GPU VRAM for 4K–8K; small FFT overhead per denoising step; model license compliance
- E-commerce imagery at production resolution
- Sectors: retail, marketplaces
- Tools/workflows: automated hero-image generation and variant creation (colors, backdrops) at native storefront resolutions; batch job in asset factory with SEGA-enabled sampler
- Value: eliminates reliance on separate upscalers; reduces artifacts on fine textures (fabrics, metals)
- Assumptions/dependencies: brand/content safety filters; prompt governance; memory budget for high-res inference
- Film/VFX concept art, matte painting, and high-res plates
- Sectors: film/TV, game cinematics
- Tools/workflows: internal art tools where artists iterate at scene resolution (e.g., 6–12K panoramas); SEGA as an attention modifier in studio render farm jobs
- Value: fewer repetitive patterns and structural breakdowns at extreme aspect ratios; faster iteration versus multi-stage guidance pipelines
- Assumptions/dependencies: pipeline access to DiT internals; stability across custom schedulers; artist controls (knobs for κ, γ)
- Game asset creation (skyboxes, environment textures, decals)
- Sectors: gaming, real-time graphics
- Tools/workflows: texture-authoring pipeline with SEGA-enhanced high-res diffusion; automated variant generation for LODs
- Value: sharper microdetails and fewer tiling/repetition artifacts; reduced need for manual cleanup
- Assumptions/dependencies: UV/layout workflows still needed; legal review for asset provenance
- Architecture and real estate marketing visuals
- Sectors: AEC, real estate
- Tools/workflows: SEGA-enabled text-to-image renderings for large-format boards, competition panels, wayfinding mockups
- Value: legible fine lines and facade details at poster/B1/B0 sizes
- Assumptions/dependencies: not a CAD/physics renderer; suitable for look-dev and marketing, not technical drawings
- Education and publishing posters/diagrams
- Sectors: education, publishing
- Tools/workflows: courseware poster generators; SEGA integrated into editorial asset tools for high-res figures
- Value: print-ready clarity without upscaling steps
- Assumptions/dependencies: factual accuracy still requires human curation; typography remains a T2I limitation
- Product personalization features (wallpapers, themes)
- Sectors: consumer software, mobile OEMs
- Tools/workflows: in-app “generate 4K wallpaper” using SEGA-enabled backend
- Value: high-res outputs on-device or via cloud with fewer artifacts
- Assumptions/dependencies: on-device compute likely insufficient for 4K diffusion; cloud inference required
- Cost/energy reduction versus retraining/fine-tuning
- Sectors: software/AI platforms
- Tools/workflows: replace fine-tuning or two-stage guidance with SEGA at inference; autoscaler profiles optimized for slightly longer step cost (FFT) but fewer passes
- Value: lowers compute and operational complexity; greener alternative to retraining for higher resolution
- Assumptions/dependencies: modest per-step overhead from spectral profiling; still quadratic attention scaling with token count
- Benchmarking and research baselines for resolution extrapolation
- Sectors: academia, industrial research labs
- Tools/workflows: release SEGA as a reproducible baseline for high-res DiT evaluation; ablation scaffolds for frequency-aware attention studies
- Value: standardized evaluation at 4K+ across Flux/Qwen; comparative studies vs. NTK/YaRN/DyPE
- Assumptions/dependencies: open-source implementation and scripts; access to Aesthetic-4K or internal prompt suites
- Production printing pipelines
- Sectors: print/on-demand, packaging
- Tools/workflows: SEGA-inference node before RIP/halftoning; direct render to CMYK-safe previews at 300+ DPI targets
- Value: better microtexture fidelity; reduces SR-induced halos or ringing
- Assumptions/dependencies: color management and ICC profiles handled downstream; T2I text rendering caveats
- Government and institutional communications assets
- Sectors: public sector, NGOs
- Tools/workflows: in-house high-res poster/banner generation with SEGA-enabled models
- Value: low-cost production of high-res public materials; faster iteration
- Assumptions/dependencies: content safety and legal review; data governance for prompts and outputs
- Integration into content platforms and AIGC SDKs
- Sectors: software platforms, SaaS
- Tools/workflows: “SEGA Attention Scaling” option in SDKs/APIs; feature flag to toggle per-resolution scaling strategy
- Value: smoother rollout path; A/B testing against uniform scaling baselines
- Assumptions/dependencies: needs access to model internals or cooperative vendor APIs
Long-Term Applications
These applications require additional research, scaling, or productization (e.g., modality extension, performance engineering, or validation).
- High-resolution video generation with frequency-aware attention
- Sectors: media, streaming, advertising
- Tools/products/workflows: extend SEGA to spatiotemporal DiTs; combine axis-wise with temporal spectral profiles to stabilize 4K–8K video
- Dependencies: mapping RoPE dimensions to temporal frequencies; maintaining temporal coherence; increased memory/compute; evaluation metrics for temporal fidelity
- 3D/asset pipelines (textures, materials, 3D diffusion)
- Sectors: VFX, gaming, digital twins
- Tools/workflows: apply spectral-guided scaling to 3D diffusion or texture-space diffusion; SEGA-like controllers in SDS/score distillation loops
- Dependencies: RoPE or analogous positional encodings for 3D/UV spaces; validation on mesh/UV artifacts
- Remote sensing and simulation data synthesis
- Sectors: geospatial, defense, environmental modeling
- Tools/workflows: high-res satellite-style synthetic data for pretraining/augmentation
- Dependencies: domain calibration and bias checks; strict labeling of synthetic data; potential dual-use concerns and policy oversight
- Domain-specific synthetic data engines (e.g., retail catalogs, fashion fabrics)
- Sectors: retail, manufacturing
- Tools/workflows: high-res synthetic training sets with preserved microtexture for downstream recognition or defect detection models
- Dependencies: rigorous domain gap studies; dataset documentation; IP and style-rights governance
- Medical and scientific illustration at ultra-high resolution
- Sectors: healthcare communications, publishing
- Tools/workflows: SEGA-enabled generators for educational/illustrative content (not diagnosis)
- Dependencies: clear disclaimer and non-diagnostic use; clinical validation if considered for any analytic task; institutional review where needed
- Adaptive attention controllers for compute allocation
- Sectors: AI infrastructure
- Tools/workflows: runtime policies that use spectral statistics to gate attention heads, adjust step counts, or tile adaptively at extreme resolutions
- Dependencies: scheduler co-design; reliability under varied prompts; hardware-aware kernels for FFT and attention
- Hardware/software co-design for spectral guidance
- Sectors: semiconductors, AI systems
- Tools/workflows: fused FFT-attention kernels; tensor core–friendly implementations; graph optimizations in Triton/CUDA
- Dependencies: kernel engineering; mixed-precision stability; benchmarking across GPUs/TPUs
- Standardized benchmarks and metrics for 4K–8K structural coherence
- Sectors: academia, standards bodies
- Tools/workflows: open datasets and metrics focusing on large-format structure/detail trade-offs; challenge leaderboards
- Dependencies: community buy-in; reference image availability at true high-res; perceptual study validation
- Policy frameworks for low-carbon scaling of generative models
- Sectors: public policy, sustainability
- Tools/workflows: procurement guidance and sustainability standards that prioritize training-free upgrades like SEGA over extensive retraining
- Dependencies: lifecycle carbon accounting; vendor transparency; independent audits
- Document/layout and typography-aware generation
- Sectors: publishing, signage
- Tools/workflows: integrate frequency-aware scaling with layout-constrained T2I/Doc-T2I to preserve small text and line art at poster scale
- Dependencies: advances in text rendering within T2I; hybrid pipelines with vector layers; evaluation for legibility
- Watermarking and provenance at high resolution
- Sectors: trust/safety, platforms
- Tools/workflows: combine SEGA with robust watermarking that survives 4K–8K rendering and print workflows
- Dependencies: watermark strength vs. quality trade-offs; open standards (e.g., C2PA) integration
Notes on feasibility and dependencies (cross-cutting):
- Model compatibility: SEGA assumes RoPE-based DiTs and access to query/key rotation hooks; U-Net or non-RoPE models need adaptations.
- Compute/memory: 2D FFT per denoising step introduces modest overhead; high resolutions still incur quadratic attention cost.
- Content safety and IP: high-fidelity outputs increase brand and legal scrutiny; integrate filters, prompt governance, and provenance tracking.
- Parameterization: κ and γ defaults work broadly but may need per-model tuning; expose as safe user controls with guardrails.
- Data and metrics: benefits measured on Aesthetic-4K and curated prompts; domain-specific validation may be required before deployment in specialized sectors.
Glossary
- Aesthetic-4K: A dataset of prompts and reference images used to evaluate high-resolution image synthesis quality. "We used prompts and reference images from the Aesthetic-4K~\cite{zhang2025diffusion} dataset."
- Attention dilution: A failure mode where attention becomes overly spread out, reducing positional discrimination. "YaRN~\cite{peng2024yarn}, which uses fixed, uniform scaling, suffers from attention dilution, where the model loses the ability to discriminate between positional offsets."
- Attention scaling: Multiplicative scaling of attention logits (or equivalently Q/K magnitudes) to adjust attention concentration during inference. "Another key component of YaRN is attention scaling, applied to the logits before the softmax."
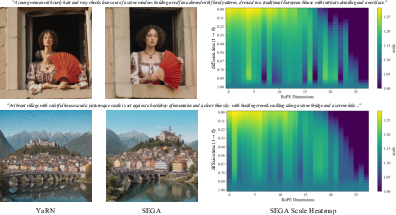
- Axis-wise profiles: One-dimensional spectral energy summaries along height and width derived by marginalizing the 2D power spectrum over the orthogonal axis. "Axis-wise profiles. For each axis with length , we marginalize the 2D power spectrum"
- Cascaded sampling: A multi-stage generation strategy where results at one scale guide sampling at higher resolutions. "through patch stitching, multi-scale fusion, or cascaded sampling"
- CLIP-IQA (CQA): A reference-free image quality assessment metric based on CLIP for evaluating generated images. "and CLIP-IQA (CQA)~\cite{wang2023exploring}."
- CLIP Score (CS): A metric measuring semantic alignment between text and image using CLIP embeddings. "Semantic alignment is measured by CLIP Score (CS)~\cite{clipscore,hessel2021clipscore}"
- Denoising step: An iteration in the diffusion sampling process where noise is progressively removed from the latent. "at each denoising step"
- Diffusion transformers (DiTs): Transformer-based diffusion architectures for image generation. "Diffusion transformers (DiTs) have emerged as a dominant architecture for text-to-image generation"
- Entropy-guided attention concentration: A technique that modulates attention focus using entropy to reduce artifacts like repetition. "employing entropy-guided attention concentration."
- Extrapolation ratio: The ratio between target and training sequence lengths/resolutions used to scale positional encodings for longer contexts. "given an extrapolation ratio $s = (L_{\text{target} / L_{\text{train})$, where ."
- Fast Fourier Transform (FFT): An efficient algorithm to compute discrete Fourier transforms; used here to analyze latent spatial frequencies. "a single 2D Fast Fourier Transform $\mathcal{F}_{2\mathrm{D}$"
- FID: Fréchet Inception Distance; a standard metric for evaluating generative image quality. "We evaluate image quality using FID~\cite{fid}"
- FID_p: A reported variant of FID used in the paper’s tables (exact definition not provided in the text). "FID\downarrow$"</li> <li><strong>HPSv2</strong>: Human Preference Score v2; a learned metric reflecting human judgments of image quality. "and HPSv2~\cite{wu2023human}"</li> <li><strong>ImageReward (IR)</strong>: A learned reward model estimating human preference for images conditioned on prompts. "ImageReward (IR)~\cite{xu2023imagereward}"</li> <li><strong>Latent</strong>: The intermediate hidden representation (feature map) being denoised and analyzed during generation. "the latent's spectral structure"</li> <li><strong>Length extrapolation</strong>: Techniques for extending models to longer sequences (or higher resolutions) than seen in training. "RoPE-based Length Extrapolation"</li> <li><strong>Logit scaling</strong>: Scaling the pre-softmax attention logits to control attention sharpness. "a constant logit scaling factor $\tau(s)$"</li> <li><strong>Multi-stage guidance</strong>: Approaches that generate a base-resolution image first and then guide a second, high-resolution sampling stage. "multi-stage guidance-based approaches"</li> <li><strong>MUSIQ (MSQ)</strong>: A no-reference image quality metric leveraging multi-scale features. "MUSIQ (MSQ)~\cite{ke2021musiq}"</li> <li><strong>NTK-aware</strong>: An RoPE extrapolation method that adjusts the base rotary frequency using Neural Tangent Kernel considerations. "NTK-aware~\cite{bloc97_ntk} instead adjusts $bb' = b \cdot s^{D/(D-2)}$"</li> <li><strong>NTK-by-parts</strong>: A YaRN scheme that partitions rotary dimensions and interpolates/extrapolates frequencies piecewise. "a.k.a.\ NTK-by-parts~\cite{peng2024yarn}"</li> <li><strong>Position Interpolation (PI)</strong>: An RoPE method that linearly compresses position indices to keep extrapolated positions within the training range. "Position Interpolation (PI)~\cite{chen2023extending} linearly compresses position indices"</li> <li><strong>Power spectrum</strong>: The squared magnitude of the Fourier transform indicating energy distribution across spatial frequencies. "2D power spectrum $\left|\mathcal{F}_{2\mathrm{D}[\tilde{\mathbf{M}]\right|^2$"</li> <li><strong>Radial profile</strong>: A rotation-invariant spectral summary obtained by averaging the 2D power spectrum over concentric rings. "Radial profile. We obtain $\mathcal{E}_{\text{iso}$"
- Relative positional offsets: Differences in positions that RoPE encodes and attention uses to bias interactions. "the relative positional offsets in Rotary Position Embeddings (RoPE) deviate significantly"
- Resolution extrapolation: Generating images at higher pixel resolutions than those seen during training by adapting positional encoding/attention. "particularly for resolution extrapolation"
- Rotary Position Embedding (RoPE): A positional encoding that rotates paired embedding dimensions at different angular frequencies to encode relative positions. "Rotary Position Embedding (RoPE)"
- Softmax: The normalization function that converts attention logits into probabilities. "applied to the logits before the softmax."
- Spectral flatness (Wiener entropy): A measure of how noise-like a spectrum is, defined as the ratio of geometric to arithmetic mean of spectral power. "the spectral flatness, also known as the Wiener entropy, defined as the ratio of the geometric mean to the arithmetic mean of a power spectrum."
- Spectral-Energy Guided Attention (SEGA): The proposed method that dynamically scales RoPE components based on the latent’s spectral energy distribution. "We introduce SEGA (Spectral-Energy Guided Attention), a training-free, content-aware method that dynamically adapts attention scaling"
- Token grid: The spatial grid of tokens over which attention operates in vision transformers. "across the expanded token grid."
- U-Net: A convolutional encoder–decoder architecture commonly used in diffusion models for image synthesis. "In U-Net architectures, methods such as DemoFusion~\cite{du2024demofusion}, FreeScale~\cite{qiu2025freescale}, and FreCaS~\cite{zhang2024frecas}"
- YaRN: An RoPE length-extrapolation method using band-specific frequency interpolation and uniform attention scaling. "YaRN proposes a constant logit scaling factor "
- Zero-Shot: An evaluation setting using prompts without task-specific tuning or examples. "We also curated a ``Zero-Shot'' benchmark"
Collections
Sign up for free to add this paper to one or more collections.