DyPE: Dynamic Position Extrapolation for Ultra High Resolution Diffusion
Abstract: Diffusion Transformer models can generate images with remarkable fidelity and detail, yet training them at ultra-high resolutions remains extremely costly due to the self-attention mechanism's quadratic scaling with the number of image tokens. In this paper, we introduce Dynamic Position Extrapolation (DyPE), a novel, training-free method that enables pre-trained diffusion transformers to synthesize images at resolutions far beyond their training data, with no additional sampling cost. DyPE takes advantage of the spectral progression inherent to the diffusion process, where low-frequency structures converge early, while high-frequencies take more steps to resolve. Specifically, DyPE dynamically adjusts the model's positional encoding at each diffusion step, matching their frequency spectrum with the current stage of the generative process. This approach allows us to generate images at resolutions that exceed the training resolution dramatically, e.g., 16 million pixels using FLUX. On multiple benchmarks, DyPE consistently improves performance and achieves state-of-the-art fidelity in ultra-high-resolution image generation, with gains becoming even more pronounced at higher resolutions. Project page is available at https://noamissachar.github.io/DyPE/.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a simple idea called DyPE (Dynamic Position Extrapolation) that helps existing image-making AI models create very large, sharp pictures without retraining and without slowing down. It focuses on diffusion transformer models (a popular kind of AI for generating images from text), and shows how to adjust the way these models “understand” where each part of the image belongs as they draw the picture step by step.
What problem is the paper solving?
Modern image AI models can already make detailed pictures, but training them to handle ultra-high resolutions (like 4096×4096 pixels and above) is extremely expensive. That’s because transformers compare many parts of the image with each other, and this costs a lot more memory and time as the image gets bigger. The paper asks: How can we make already-trained models draw much larger images well, without retraining and without extra computation?
Key questions in simple terms
- When a diffusion model draws a picture, it starts from pure noise and slowly shapes it into a clear image. Do different kinds of image details (big shapes vs tiny textures) settle at different times during this process?
- Can we take advantage of this timing to tell the model which parts of the image’s “position information” to focus on at each step?
- If we do that, can the model make very large images with better structure and sharper details, using the same number of steps and the same speed?
How it works (methods explained simply)
Think of diffusion as painting in reverse: the model starts with a noisy canvas and gradually cleans it up until it looks like a real picture. Early steps settle big, smooth shapes (low-frequency parts), and later steps add fine details (high-frequency parts), like textures and sharp edges.
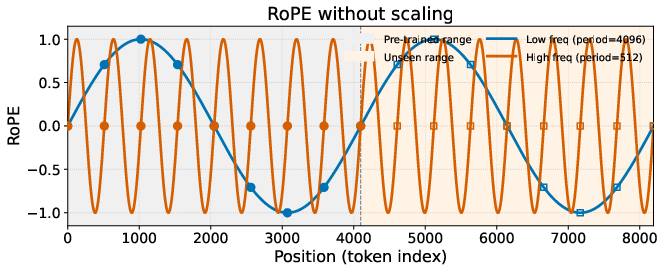
Transformers need “positional encoding” (PE) to know where each patch or token of an image is located, a bit like giving every tile in a mosaic its coordinates. A common method for this is RoPE (Rotary Positional Embeddings), which uses waves at different speeds (frequencies) to represent positions. Low-frequency waves capture big patterns; high-frequency waves capture tiny details.
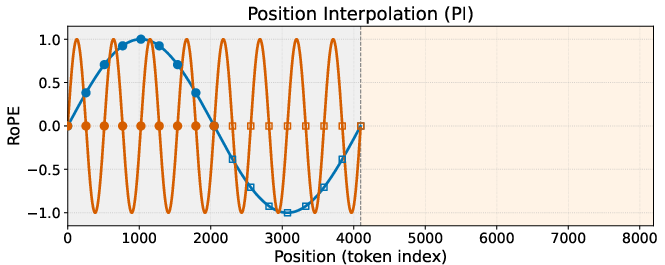
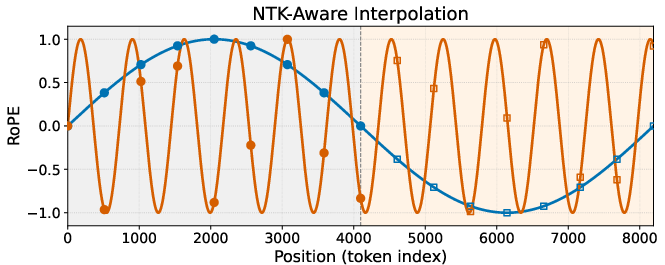
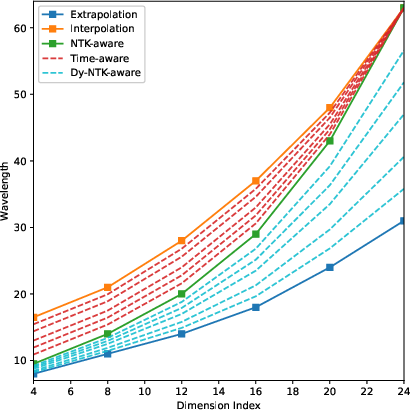
Past techniques for making models work on bigger images (PI, NTK-aware, and YaRN) adjust these waves in a fixed way during inference:
- PI: compresses positions uniformly; it preserves large shapes but tends to blur fine details.
- NTK-aware: rescales frequencies to keep low-frequency stable, often at the cost of high-frequency detail.
- YaRN: blends ideas from both and also tweaks attention; it’s better but still fixed over time.
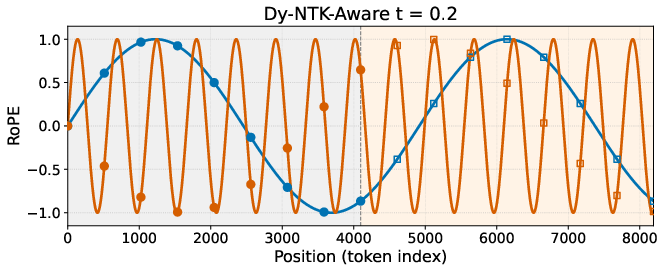
The paper’s key insight is that diffusion itself progresses from low-frequency (big shapes) early to high-frequency (small details) later. So the positional encoding should also change over time to match this natural progression.
Here’s the DyPE idea in plain words:
- Early steps: emphasize low-frequency position information so big shapes settle in properly at large resolutions (using extrapolation methods like YaRN or NTK-aware).
- Later steps: gradually turn down that scaling so the model returns to its original, trained positional settings, freeing up capacity to represent and refine high-frequency details sharply.
Technically, they use a simple time-based schedule (think of it as a dimmer switch) that starts strong and fades to “no scaling” by the end. They apply this schedule to create time-aware versions of existing methods:
- Dy-PI (dynamic PI)
- Dy-NTK (dynamic NTK-aware)
- Dy-YaRN (dynamic YaRN, which moves the frequency ramps over time)
This is all done at inference time. No retraining. No extra steps. Just smarter coordination between the diffusion timeline and positional encoding.
Main findings and why they matter
The authors test DyPE on several setups and report consistent improvements:
- On a popular text-to-image model (FLUX), DyPE helps generate ultra-high-resolution images (16 million+ pixels) with better alignment to prompts, more pleasing aesthetics, and sharper details. The gains become more noticeable as the resolution increases (e.g., at 4096×4096).
- Human preference tests show people picked DyPE-enhanced images around 87–90% of the time over regular methods, for text alignment, structure, and fine details.
- A scaling study shows baseline methods start to break down at high resolutions (FLUX degrades around 3072×3072, YaRN around 4096×4096), while Dy-YaRN stays strong up to 6144×6144 before dropping.
- On class-conditional generation (ImageNet) using another model (FiTv2), DyPE versions generally improved key metrics (FID, Inception Score), especially Dy-YaRN.
In short: DyPE makes large images that look more coherent and detailed, and it does this without extra cost or training.
What this means going forward
This research suggests a practical way to unlock high-resolution image generation in transformer-based models:
- You can take a strong, pre-trained model and push it to much higher resolutions by simply adjusting how it encodes positions over the diffusion steps.
- This saves time and money because you don’t need to retrain the model or add extra sampling steps.
- The idea of “time-aware positional encoding” could be extended to even bigger images, or to video (where timing matters even more), potentially improving both spatial detail and smooth motion.
Overall, DyPE shows that matching the model’s internal “sense of position” to the natural rhythm of the diffusion process—big shapes first, fine details later—helps the model generalize to ultra-large images with better quality, stability, and detail.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, formulated as concrete, actionable items for future research:
- Formal theory linking dynamic PE to denoising accuracy: The spectral analysis relies on the forward mixture in Fourier space and the empirical PSD progression; there is no formal derivation or proof that time-varying RoPE scaling reduces per-frequency reconstruction error in the learned reverse process. Establish a theoretical connection (e.g., error bounds or NTK analysis) between PE frequency allocation and denoiser performance across timesteps.
- Generalization across diffusion schedules and samplers: DyPE is described with a linear flow-matching schedule (αt=1−t, σt=t) and an abstract t∈[0,1]. It is unclear how to map DyPE to common VP schedules and widely used samplers (DDIM, DPM-Solver++, ancestral variants). Provide a schedule-agnostic mapping from noise level σ (or SNR) to κ(t), validate across samplers, and quantify sensitivity.
- Automatic, data-driven scheduler design: The choice of DyPE hyperparameters (λs, λt) and YaRN ramp thresholds (α, β) is manual. Develop adaptive strategies that estimate κ(t) from the current sample’s spectrum (or attention statistics), learn per-model/per-resolution schedules, or meta-learn λs, λt from small validation sets.
- Layer/head-specific dynamics: DyPE applies the same κ(t) across all layers and attention heads, although different layers/heads attend to different scales. Investigate per-layer or per-head schedules (e.g., deeper layers emphasizing higher frequencies later), and measure their impact on detail vs. global structure.
- Cross-attention and text token treatment: The paper only modifies axial RoPE on image tokens; the effect on cross-attention (image–text alignment) and on text-token positional encodings is not studied. Evaluate whether dynamic PE should also be applied to cross-attention blocks or text embeddings, and measure trade-offs in prompt fidelity vs. image detail.
- Attention entropy/scaling over time: YaRN’s attention logit scaling τ(s) is static with respect to time. Assess whether time-dependent attention scaling (τ(s, t)) improves stability, reduces attention entropy inflation at higher resolutions, or mitigates repetition/artifacts during late denoising steps.
- Transfer beyond RoPE: DyPE is tailored to RoPE. Explore applicability to other PEs (2D Fourier features, learned absolute/relative PEs, ALiBi variants, hybrid axial schemes) and whether time-dependent frequency allocation yields similar gains.
- Failure modes at very high resolutions: Resolution scaling analysis indicates degradation at 6144×6144, without diagnosing causes (e.g., attention collapse, aliasing, token budget constraints, training distribution shift). Provide failure analyses (attention patterns, PSD slope deviations, artifact taxonomy) and mitigation strategies.
- Coverage across models and domains: Evaluation is limited to FLUX and FiTv2 on ImageNet/DrawBench/Aesthetic-4K. Test DyPE on diverse DiTs (e.g., SD3-family, PixArt), modalities (line-art, typography), and domains (satellite, medical) to assess robustness to datasets with atypical spectra.
- Aspect-ratio biases and anisotropy: FLUX appears biased toward landscape; DyPE narrows but does not resolve this. Analyze anisotropic frequency behavior (horizontal vs. vertical bands) and propose axis-aware schedules or training-time remedies for portrait/aspect-ratio generalization.
- Metrics for high-frequency fidelity: Current metrics (CLIPScore, ImageReward, Aesthetic, FID) do not directly quantify preservation of high-frequency detail. Introduce Fourier-based metrics (PSD slope alignment, high-frequency energy ratios), edge sharpness/MTF, or spatial frequency LPIPS to validate DyPE’s intended effect.
- Human evaluation rigor: The user study (20 prompts, 50 raters) lacks statistical testing, inter-rater reliability, and demographic/reporting details. Provide significance tests, confidence intervals, rater consistency analysis, and larger, stratified prompt sets to reduce bias.
- Compute/memory profiling: The claim of “no additional sampling cost” refers to PE operations, but ultra-high-resolution DiT inference remains quadratic in tokens. Quantify actual memory/time overheads at 4K–16M pixels, hardware requirements, throughput, and practical limits; compare against patch-based/sparse attention baselines.
- Interaction with guidance and conditioning: Effects under different guidance scales, negative prompts, and complex conditioning (e.g., control signals, masks) are not evaluated. Measure whether dynamic PE alters guidance responsiveness or controllability.
- Combining with complementary methods: The synergy between DyPE and training-free high-res techniques (patch stitching, FreeScale, ElasticDiffusion, ScaleCrafter, CutDiffusion) is unexplored. Benchmark hybrid pipelines and identify interference or additive gains.
- Training-time integration: While noted as future work, there is no empirical evidence that time-dependent PE helps during training (e.g., randomized time-aware RoPE schedules). Study light fine-tuning regimens and whether DyPE-in-training improves out-of-distribution resolution generalization.
- Diversity–fidelity trade-offs: Improvements are reported primarily on fidelity/alignment metrics. Assess effects on sample diversity (precision–recall curves, coverage metrics, class-wise IS) to rule out unintended mode concentration.
- Robustness to prompts emphasizing high frequencies: Evaluate DyPE on prompts requiring crisp micro-textures (microtext, line-art, moiré-sensitive patterns), small fonts, and fine typography to stress-test high-frequency preservation.
- Implementation reproducibility: Key hyperparameters, sampler settings, and exact κ(t) configurations are relegated to the appendix/project page. Provide fully specified configs and ablations (including seeds and variance) to facilitate reproduction.
- Video and temporal coherence: Extending DyPE to video is proposed but untested. Investigate spatio-temporal PE schedules (coupled spatial–temporal κ(t)) and their effects on flicker, motion consistency, and long-range temporal dependencies.
Practical Applications
Immediate Applications
Below are actionable, deployment-ready uses of DyPE that can be implemented today, along with sector mappings, potential tools/workflows, and feasibility notes.
- Software/ML Infrastructure
- Description: Integrate DyPE (especially Dy-YaRN) into existing Diffusion Transformer (DiT) inference stacks to unlock 4K–8K generation without retraining or extra sampling steps.
- Sectors: Software, AI platforms
- Potential tools/workflows:
- Add a DyPE scheduler wrapping RoPE calls in FLUX, FiTv2, or similar DiT models.
- Implement
kappa(t) = t^{λ_t}for Dy-YaRN orkappa(t) = λ_s * t^{λ_t}for Dy-NTK/Dy-PI; exposeλ_tvia config. - Cache timestep-specific PE transforms to avoid runtime overhead.
- Validate with CLIPScore, ImageReward, Aesthetics; monitor behavior beyond 4096².
- Assumptions/dependencies: Model uses RoPE; access to the sampler’s timesteps; sufficient GPU memory (attention cost still scales with tokens); licensing of FLUX/FiTv2; quality assurance at 4096²–6144².
- Media, Advertising, and Creative Studios
- Description: Generate ultra-high-resolution, print-ready visuals (billboards, posters, packaging, large-format displays) with better fine detail and fewer extrapolation artifacts.
- Sectors: Media/Entertainment, Marketing, Printing
- Potential tools/workflows:
- “DyPE for FLUX” plug-in in creative pipelines (Photoshop/Blender bridge scripts; REST inference microservice).
- Batch workflows for 4K+ hero images; prompt libraries tuned for Dy-YaRN.
- Human-in-the-loop review with A/B comparisons against static YaRN.
- Assumptions/dependencies: Consistent color management; prompt safety filters; GPU memory for large images; internal acceptance criteria for aesthetics and brand guidelines.
- E‑commerce and Product Visualization
- Description: Produce high‑res product pages, zoomable hero shots, and texture‑rich close-ups without fine-tuning the base model.
- Sectors: Retail, Fashion, Consumer electronics
- Potential tools/workflows:
- DyPE-enabled “detail pass” for 4K images with better texture fidelity.
- Programmatic generation of product backdrops and lifestyle scenes at high aspect ratios.
- Assumptions/dependencies: Content moderation; domain prompts; GPU quotas; periodic human QA for material realism.
- Game Development and XR
- Description: Generate large textures, skyboxes, panoramic backgrounds, and environment plates with reduced blurring and repetitive artifacts typical at high resolutions.
- Sectors: Gaming, AR/VR
- Potential tools/workflows:
- Unity/Unreal asset pipelines incorporating Dy-YaRN for 4K–8K textures.
- Panorama generation (equirectangular skyboxes) using DyPE scheduling for aspect ratios.
- Assumptions/dependencies: Style consistency across assets; memory constraints; export formats (EXR, HDR).
- Architecture, Industrial Design, and Visualization
- Description: Create high‑resolution concept renders and mood boards with improved structure and fine detail (interiors, façade studies, product prototypes).
- Sectors: AEC, Industrial design
- Potential tools/workflows:
- Visualization farms employing DyPE wrappers over FLUX/FiTv2.
- CAD-to-prompt workflows; batch render at 4K–8K; A/B review for structure fidelity.
- Assumptions/dependencies: Accurate perspective and geometry prompt design; post-processing for photometric realism.
- Education and Learning Resources
- Description: Produce high‑res instructional visuals, course materials, and art/design references; teach frequency-aware generation in ML curricula.
- Sectors: Education
- Potential tools/workflows:
- Jupyter notebooks showing PSD progression and DyPE schedules.
- Classroom demos comparing static vs dynamic PE at 2K/4K.
- Assumptions/dependencies: Modest compute (4K fits on modern GPUs); public models with permissive licenses.
- Research and Open‑Source Ecosystem
- Description: Use DyPE to study denoising frequency dynamics and position encoding extrapolation; benchmark long‑context generalization in DiTs.
- Sectors: Academia, Open-source
- Potential tools/workflows:
- Diffusers extension: “Dy-YaRN for vision” (axis‑wise PE; scheduler hooks).
- Reproducible benchmarks (DrawBench, Aesthetic‑4K; 1024²–6144² scaling curves).
- Assumptions/dependencies: Access to evaluation datasets; standard metrics (CLIPScore, ImageReward, FID); institutional GPU resources.
- Content Moderation and Watermarking Pipelines
- Description: Ensure provenance systems and detectors work for ultra‑high‑res outputs; update downstream moderation tooling to handle 4K+ images.
- Sectors: Policy, Trust & Safety, Platform governance
- Potential tools/workflows:
- Adjust forensic tools to consider DyPE’s removal of periodic artifacts and high‑frequency gains.
- Embed/verify high‑res watermarks at generation time.
- Assumptions/dependencies: Alignment with platform policies; standardized watermarking APIs; risk assessments for high‑fidelity synthetic content.
- Consumer Use (Daily Life)
- Description: Generate high‑res wallpapers, posters, and photo‑art prints with sharper details on 4K/8K displays.
- Sectors: Consumer apps
- Potential tools/workflows:
- Mobile/desktop apps exposing “Ultra‑res (DyPE)” mode with auto‑selection of Dy‑YaRN.
- Presets for portrait vs landscape (paper sizes, aspect ratios).
- Assumptions/dependencies: Device limits; cloud inference quotas; content safety filters.
Long‑Term Applications
These opportunities require further research, scaling, or development before broad deployment.
- Video Generation with Time‑Aware Positional Extrapolation
- Description: Extend DyPE to spatiotemporal PE for coherent high‑resolution video; dynamically allocate frequency across space and time.
- Sectors: Media/Entertainment, Social platforms
- Potential tools/products: “DyPE‑T” for video DiTs; temporal ramp scheduling combining spatial and temporal RoPE.
- Assumptions/dependencies: New DiT architectures supporting time axes; significant memory/compute; robust temporal metrics.
- Training‑Time Co‑Design (Light Tuning with DyPE)
- Description: Incorporate dynamic PE schedules during fine‑tuning to push resolution limits beyond 6144² and stabilize extreme contexts.
- Sectors: Software/ML
- Potential tools/products: Training plugins that anneal PE ramps; curriculum schedules aligned to diffusion timesteps.
- Assumptions/dependencies: Additional compute; large high‑res datasets; careful hyperparameterization of λ_t/λ_s.
- Healthcare and Medical Simulation
- Description: High‑resolution synthetic medical imagery for training, pretext tasks, and augmentation (e.g., histopathology, dermoscopy) with better fine structures.
- Sectors: Healthcare
- Potential tools/products: Synthetic dataset generators with DyPE; validation suites for clinical realism.
- Assumptions/dependencies: Strict clinical validation; regulatory and ethical approvals; domain‑specific prompts and priors.
- Remote Sensing and Mapping
- Description: High‑res synthetic satellite/aerial images for data augmentation, sensor simulation, and training downstream detectors.
- Sectors: Geospatial, Defense, Agriculture
- Potential tools/products: “Geo‑DyPE” modules respecting geospatial constraints; integration with GIS tooling.
- Assumptions/dependencies: Spectral correctness (beyond RGB), geo‑registration fidelity, rigorous evaluation against real data.
- Robotics Simulation and Digital Twins
- Description: Photorealistic, ultra‑res environments and textures for sim‑to‑real training, improving perception under fine‑detail conditions.
- Sectors: Robotics, Manufacturing
- Potential tools/products: DyPE‑enabled texture packs; high‑res environment synthesis pipelines.
- Assumptions/dependencies: Domain gap management; physically‑based rendering consistency; compute budgets.
- Multi‑View/3D Asset Generation
- Description: Frequency‑aware PE for multi‑view consistency and ultra‑res texture generation for 3D assets and NeRF‑like pipelines.
- Sectors: Gaming, VFX, 3D content creation
- Potential tools/products: DyPE‑integrated multi‑view DiTs; view‑dependent ramp scheduling.
- Assumptions/dependencies: Geometry coherence constraints; cross‑view correspondence; extended model architectures.
- Energy/Compute‑Efficient Ultra‑Res Generation
- Description: Co‑design DyPE with attention sparsification or patchwise memory optimizations to control quadratic scaling, reducing energy costs of ultra‑res synthesis.
- Sectors: Energy, Cloud infrastructure
- Potential tools/products: Dynamic frequency‑aware attention gating; hybrid global‑local attention guided by DyPE schedules.
- Assumptions/dependencies: Hardware support; algorithmic innovations; sustained performance at quality parity.
- Security and Policy Frameworks for High‑Fidelity Generative Media
- Description: Standards for provenance, disclosure, and detection tailored to ultra‑high‑res generative outputs; guidelines for responsible use.
- Sectors: Policy/Governance
- Potential tools/products: High‑res watermark standards; audit pipelines that account for DyPE’s detail preservation.
- Assumptions/dependencies: Multi‑stakeholder coordination; legislative adoption; international standards alignment.
- Domain‑Specific High‑Res Evaluations and Metrics
- Description: New metrics capturing high‑frequency fidelity, structural coherence, and human preference at ultra resolutions.
- Sectors: Academia, Industry benchmarking
- Potential tools/products: Frequency‑sliced FID variants; PSD‑aware alignment scores; large-scale human eval protocols.
- Assumptions/dependencies: Benchmark creation at 4K–8K; cross‑domain validation.
- Consumer Hardware and Edge Deployments
- Description: Optimize DyPE-based generation for edge devices (high‑end phones/PCs) with specialized attention kernels or on‑device caching.
- Sectors: Consumer electronics
- Potential tools/products: Edge inference SDKs with DyPE; display‑adaptive generation modes.
- Assumptions/dependencies: Hardware acceleration (GPU/NPU); memory limits; quality vs latency tradeoffs.
Cross‑Cutting Assumptions and Dependencies
- Model compatibility: DyPE operates on RoPE‑based DiTs; U‑Net backbones require different adaptation.
- Schedules and hyperparameters: Performance depends on the diffusion schedule (e.g., Flow Matching vs VP) and well‑chosen
λ_t,λ_s. - Compute/memory: “No additional sampling cost” refers to step counts; attention still scales quadratically with tokens—large images demand substantial VRAM.
- Generalization limits: Empirically strong to 4096²–6144²; behavior beyond that may degrade without additional engineering or tuning.
- Ethics and safety: High‑fidelity outputs increase deepfake risks—necessitate watermarking, provenance, and moderation.
- Licenses/datasets: Respect model and dataset licenses (e.g., FLUX variants); ensure prompt safety and domain appropriateness.
Glossary
- Aesthetic-4K: A curated benchmark/dataset for evaluating ultra-high-resolution image generation quality. "DrawBench and Aesthetic-4K"
- Aesthetic-Score-Predictor: A model trained to predict human aesthetic judgments of images. "image aesthetics using Aesthetic-Score-Predictor~\citep{schuhmann2022laion}"
- Attention logits: The unnormalized scores in attention that are passed through softmax to produce attention weights. "attention logits are modified by a factor ."
- Attention scaling: An adjustment to attention logits to compensate for entropy changes when context length increases. "The second extension is the attention scaling, where attention logits are modified by a factor ."
- CLIP: A vision–LLM used to compute image–text similarity. "a similarity metric between image and text embeddings based on CLIP~\citep{radford2021learning}"
- CLIP-Score: A reference-free metric that measures alignment between generated images and text prompts using CLIP embeddings. "text-image alignment using CLIP-Score~\citep{hessel2022clipscorereferencefreeevaluationmetric}"
- Denoiser: The learned network that iteratively removes noise during the reverse diffusion process. "samples generated by a denoiser trained on ImageNet~\citep{russakovsky2015imagenet}"
- Diffusion Transformers (DiTs): Transformer-based diffusion models that combine diffusion training with transformer architectures for image generation. "Diffusion Transformers (DiTs)~\citep{dit} have recently emerged as a powerful class of generative models"
- DrawBench: A benchmark of 200 prompts assessing multiple aspects of text-to-image generation quality. "DrawBench~\citep{saharia2022photorealistictexttoimagediffusionmodels}, a set of 200 text prompts"
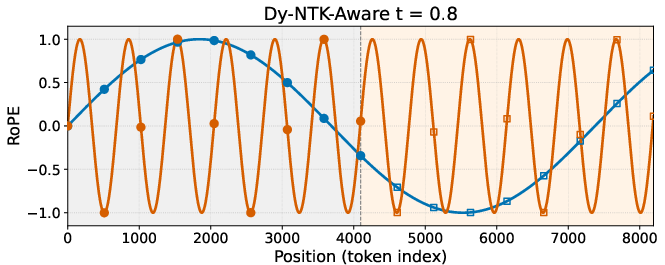
- Dy-NTK: The time-aware (dynamic) variant of NTK-aware RoPE scaling that reduces scaling over denoising steps. "NTK-aware vs.~Dy-NTK-aware"
- Dy-PI: The time-aware (dynamic) variant of Position Interpolation where the scaling factor attenuates over denoising steps. "Dy-PI."
- Dy-YaRN: The time-aware (dynamic) variant of YaRN where ramp thresholds are scheduled over diffusion timesteps. "Dy-YaRN"
- DyPE: Dynamic Position Extrapolation; a training-free method that schedules positional encoding extrapolation to match diffusion’s spectral progression. "we introduce Dynamic Position Extrapolation (DyPE), a novel, training-free method"
- FID: Frechet Inception Distance; a distributional metric comparing real and generated image features. "FID~\citep{heusel2017gans}"
- FiTv2: A flexible Vision Transformer diffusion model designed for multi-resolution generation. "We apply DyPE\ on FiTv2~\citep{wang2024fitv2scalableimprovedflexible}"
- FLUX: A large-scale diffusion transformer used as a base model for ultra-high-resolution synthesis. "on top of FLUX~\citep{flux1kreadev2025}"
- Flow Matching: A diffusion training formulation using linear noise/data schedules for trajectory matching. "Flow Matching~\citep{Lipman2022FlowMatching, liu2022flow}"
- Fourier space: The frequency-domain representation used to analyze spectral behavior during diffusion. "derive a complementary perspective in Fourier space"
- ImageReward: A learned reward model trained on human preferences to evaluate generated images. "human preference alignment using ImageReward~\citep{xu2023imagereward}"
- Inception Score (IS): A metric evaluating image quality and diversity using a pre-trained classifier’s predictive distribution. "Inception Score (IS)~\citep{salimans2016improved}"
- Neural Tangent Kernel (NTK)-aware interpolation: A RoPE frequency-scaling scheme that preserves low-frequency stability when extrapolating context length. "the Neural Tangent Kernel (NTK-aware) interpolation~\citep{peng2023ntk, peng2023yarnefficientcontextwindow}"
- NTK-by-parts interpolation: A piecewise NTK-based scaling in YaRN that splits frequencies into bands with different mappings. "the NTK-by-parts interpolation, which splits the spectrum to three bands"
- Position Interpolation (PI): A RoPE method that uniformly rescales positions to extend context length. "Position Interpolation (PI)~\citep{chen2023pi}"
- Positional Embedding (PE): Encodings that inject position information into transformer inputs/attention to model spatial dependencies. "Positional Embedding (PE)."
- Power Spectrum Density (PSD): A function describing how signal power is distributed over frequencies. "Power Spectrum Density (PSD)"
- Progression map: A function that quantifies how each frequency component evolves from noise to data over denoising time. "we consider a progression map relating each frequency component to a progress index, "
- Reverse diffusion trajectory: The denoising path from pure noise to a clean sample in diffusion sampling. "the reverse diffusion trajectory exhibits a clear spectral ordering"
- Rotary Positional Embeddings (RoPE): A positional encoding that encodes relative positions via rotations in query–key interactions. "Rotary Positional Embeddings (RoPE)~\citep{su2021rope}"
- sFID: Spatial Frechet Inception Distance; a variant of FID sensitive to spatial structure. "sFID~\citep{nash2021generating}"
- Self-attention: The transformer mechanism computing token-to-token interactions with quadratic complexity in sequence length. "the self-attention mechanism's quadratic scaling with the number of image tokens"
- Spectral progression: The phenomenon where low frequencies settle early and high frequencies resolve later during diffusion. "the spectral progression inherent to the diffusion process"
- YaRN: A RoPE extrapolation method that combines piecewise frequency scaling and attention scaling for longer contexts. "Yet another RoPE extensioN, or YaRN~\citep{peng2023yarnefficientcontextwindow}"
Collections
Sign up for free to add this paper to one or more collections.