One LR Doesn't Fit All: Heavy-Tail Guided Layerwise Learning Rates for LLMs
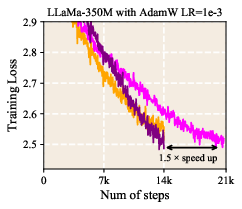
Abstract: Learning rate configuration is a fundamental aspect of modern deep learning. The prevailing practice of applying a uniform learning rate across all layers overlooks the structural heterogeneity of Transformers, potentially limiting their effectiveness as the backbone of LLMs. In this paper, we introduce Layerwise Learning Rate (LLR), an adaptive scheme that assigns distinct learning rates to individual Transformer layers. Our method is grounded in Heavy-Tailed Self-Regularization (HT-SR) theory, which characterizes the empirical spectral density (ESD) of weight correlation matrices to quantify heavy-tailedness. Layers with weaker heavy-tailedness are assigned larger learning rates to accelerate their training, while layers with stronger heavy-tailedness receive smaller learning rates. By tailoring learning rates in this manner, LLR promotes balanced training across layers, leading to faster convergence and improved generalization. Extensive experiments across architectures (from LLaMA to GPT-nano), optimizers (AdamW and Muon), and parameter scales (60M-1B) demonstrate that LLR achieves up to 1.5x training speedup and outperforms baselines, notably raising average zero-shot accuracy from 47.09% to 49.02%. A key advantage of LLR is its low tuning overhead: it transfers nearly optimal LR settings directly from the uniform baseline. Code is available at https://github.com/hed-ucas/Layer-wise-Learning-Rate.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a simple idea with a big effect: when training LLMs like LLaMA or GPT, not every layer of the model should learn at the same speed. The authors propose a method called Layerwise Learning Rate (LLR) that gives each layer its own learning rate (its own “speed”). They decide these speeds by measuring how “well-trained” each layer already looks, using a math signal called heavy-tailedness. Layers that look less trained get a bigger learning rate (learn faster), and layers that look more trained get a smaller one (learn more carefully).
What questions did the researchers ask?
They focused on three simple questions:
- Is using the same learning rate for every layer in a Transformer actually holding back training?
- Can we find a principled way to give different layers different learning rates that works reliably, not just with lucky settings?
- Will this make training faster and improve how well the model generalizes to new tasks?
How did they do it?
Think of a Transformer as a tall building with many floors (layers). The usual practice is to tell all floors to “renovate” at the same speed (same learning rate). But different floors have different needs. Some are already in good shape; others need more work. The authors’ method, LLR, checks each floor and adjusts its pace.
Here’s the approach in everyday terms:
- Measuring how “trained” a layer is:
- The authors use a signal from a layer’s weights called heavy-tailedness. In everyday terms, a “heavy-tailed” pattern means you see lots of small values and a few very large ones—like incomes in a country or city sizes: many small, a few huge.
- They compute a summary score (called alpha, α) by looking at how the layer’s weight values are spread out. A smaller α usually means “heavier tail” and suggests the layer has stronger, more complex structure—often a sign it’s already well-learned. A larger α suggests the layer is less developed and could benefit from more aggressive learning.
- Assigning learning rates per layer:
- Layers with weaker heavy-tailedness (larger α, likely less trained) get larger learning rates to catch up.
- Layers with stronger heavy-tailedness (smaller α, likely more trained) get smaller learning rates to avoid overdoing it.
- There’s a cap so learning rates don’t get too big or too small.
- Making it smooth and efficient:
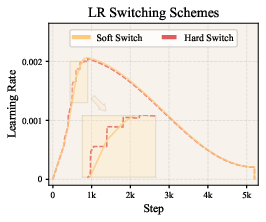
- Soft switch: Instead of suddenly changing a layer’s learning rate (which can cause unstable “spikes”), they smoothly transition to the new value over a short window.
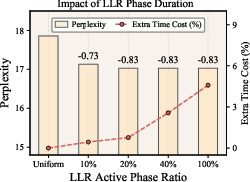
- Early focus: They apply these layer-by-layer updates mostly in the first ~20% of training, because that’s when the layers’ “heavy-tailedness” changes the most. After that, things stabilize, so extra computation isn’t needed.
- Special handling for embeddings: The “word lookup” layers (embeddings) are often under-updated in practice. The method ensures they get a sufficiently high learning rate so they don’t fall behind.
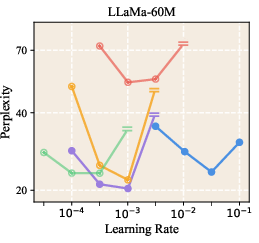
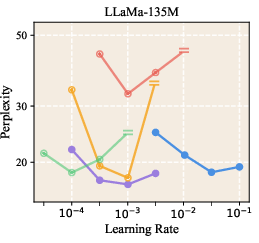
They tested LLR on several model sizes (about 60 million to 1 billion parameters), different architectures (LLaMA, GPT-nano), and different optimizers (AdamW and Muon).
What did they find?
To make the findings easy to digest, here are the main takeaways:
- Faster training without breaking things:
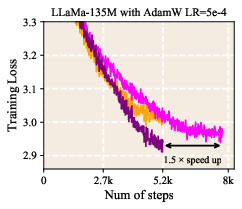
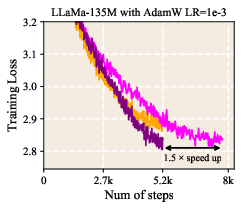
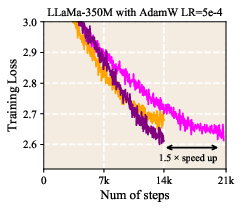
- LLR reached the same (or better) training loss with fewer training tokens, corresponding to about 1.5× speedup in some settings. In simple terms, the model learned more in less time.
- Better generalization to new tasks:
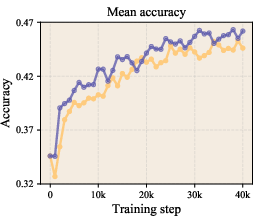
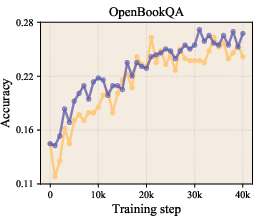
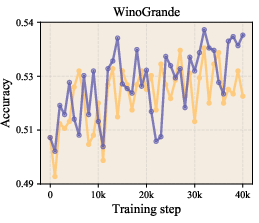
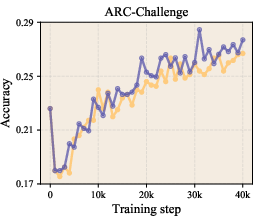
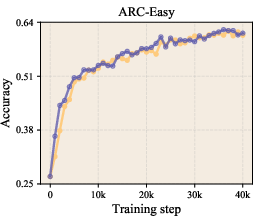
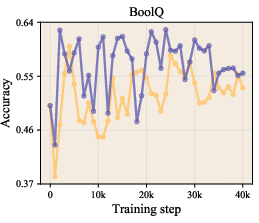
- On zero-shot benchmarks (where the model answers questions it wasn’t trained on directly), the LLaMA-1B model’s average accuracy improved from about 47.1% to 49.0% using LLR.
- On a larger LLaMA-3B run, average zero-shot accuracy also improved.
- Works across different setups:
- LLR beat or matched other layerwise methods (like LARS, LAMB, and “Sharpness”-based schedules) and worked with different optimizers (AdamW and Muon).
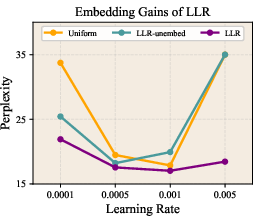
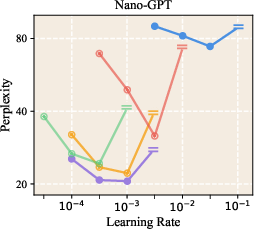
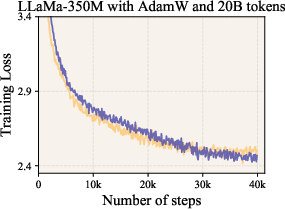
- It improved perplexity (a measure of how “surprised” the model is by the data; lower is better) across multiple model sizes. For example, on LLaMA-1B, validation perplexity improved from 9.77 to 9.59.
- Low tuning effort:
- One big practical win: you can start from the same overall learning rate you’d use for the uniform baseline. LLR then redistributes it across layers, so you don’t have to run loads of experiments to find good settings.
Why is this important?
- Smarter training for Transformers: Transformers are not uniform inside—attention parts and feed-forward parts behave differently. Treating every layer the same is convenient but suboptimal. LLR respects those differences.
- Save time and compute: If a method can train faster and generalize better without extra tuning, it can save money, energy, and researcher time.
- Plays well with existing tools: LLR is compatible with common optimizers and schedules, and it doesn’t require changing the model architecture.
- A step toward more adaptive training: The idea of using signals from the model’s own weights (like heavy-tailedness) to guide training is powerful. It hints at a future where models automatically adjust how they learn, layer by layer.
Key concepts explained simply
- Learning rate: The “step size” the model takes when it updates its weights. Bigger steps learn faster but can overshoot; smaller steps are safer but slower.
- Layerwise learning rate: Giving each layer its own step size instead of using the same one everywhere.
- Heavy-tailedness: A pattern where many values are small but a few are very large—like a long, stretched tail in a histogram. In this context, heavier tails usually indicate a layer has developed strong internal structure from learning.
- Perplexity: A score of how confused a LLM is when predicting text. Lower perplexity means the model is better at predicting the next word.
- Zero-shot accuracy: How well the model performs on tasks it wasn’t directly trained on, using only general knowledge learned during pretraining.
Final thoughts
This paper shows that “one learning rate doesn’t fit all” for LLMs. By watching how each layer’s weights evolve (through the heavy-tailedness signal) and adjusting learning rates accordingly, the model learns faster and ends up performing better on new tasks. Because it’s simple to plug into existing training setups and needs little extra tuning, LLR could become a practical default for training future LLMs more efficiently.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper makes a compelling case for layerwise learning rates guided by heavy-tailed spectral statistics, but several aspects remain underspecified or unexplored. The following points identify concrete gaps and questions for future work:
Scalability and external validity
- Limited model scale and training budgets: results are reported primarily for LLaMA variants up to 1B parameters (with a single 3B-parameter case at 30B tokens) and up to 100B tokens; it is unclear whether the approach holds for production-scale LLMs (e.g., 7B–70B+) and multi-hundred-billion or trillion-token regimes.
- Dataset diversity: pretraining is conducted on FineWeb only; the method’s robustness under different domains (e.g., code, multilingual corpora, scientific text), data quality distributions, and contamination levels remains untested.
- Architectural breadth: apart from LLaMA and GPT-nano, the method is not evaluated on encoder-decoder Transformers, MoE models, vision-LLMs, diffusion models, or retrieval-augmented architectures; whether the
α-guided schedule generalizes to these settings is unknown. - Task coverage: downstream evaluations focus on zero-shot commonsense and a RoBERTa fine-tuning suite; effects on instruction tuning, RLHF, multi-task SFT, long-context tasks, and calibration remain unexplored.
Methodological and algorithmic choices
- Spectral estimation at scale: the paper computes ESDs of
WᵀWand fits a power law using the Hill estimator withk = n/2, but does not specify tractable approximations for very large layers (e.g., partial SVD, Lanczos, randomized methods), nor quantify approximation error, memory/compute costs, or numerical stability as layer widths grow. - Sensitivity to PL-fitting design: the choice of estimator (Hill), tail cutoff (
k), and ESD window ([λ_min, λ_max]) can materially affectα; sensitivity analyses are only referenced in the appendix and not reported comprehensively. How robust are LR assignments to noisy or biasedαestimates? - Update interval and active phase:
αis computed every\tilde{t}(≈5.2M tokens) during the first 20% of training, then frozen. While Figure evidence suggests early stabilization for small models, the generality of this assumption for larger models, curriculum shifts, optimizer changes, or data distribution shifts is untested. - Mapping function design: the linear interpolation
f_T(i)bounded by[η, s·η]with a fixeds=5is heuristic. It is unclear whether non-linear mappings, adaptives, or normalization across layers (e.g., z-scoringα) would yield better stability or performance, or how sensitive gains are tosacross optimizers and scales. - Embedding/output-head special-casing: fixing embedding/output-head LR at the upper bound (
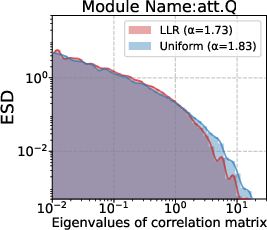
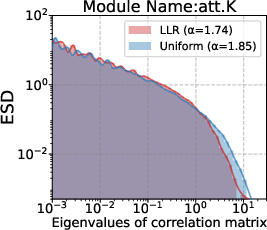
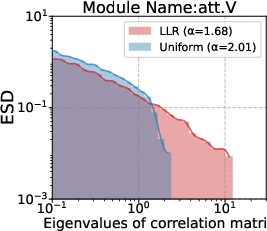
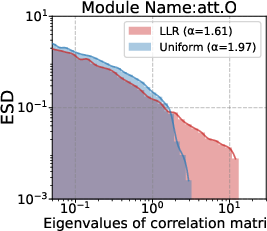
s·η) improves results here, but risks over-updating high-norm or high-variance layers. How this interacts with vocabulary size, tied embeddings, or different tokenizers is not systematically studied. - Parameter granularity: although the paper discusses module-level trends (e.g.,
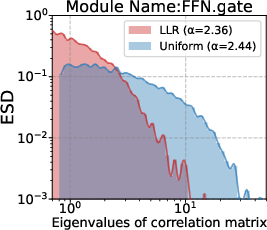
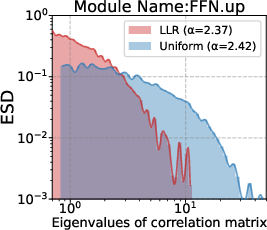
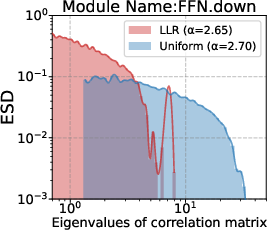
Att.q/k/v/o,FFN.up/down/gate), the algorithm is described as layerwise. It remains unclear whether finer granularity (per-module, per-head, per-submatrix) would be more effective, and how to avoid overfitting or instability at finer scales. - Interaction with schedules and hyperparameters: experiments primarily use cosine decay with warmup and gradient clipping. Effects under alternative schedulers (linear, step, polynomial), different warmup lengths, gradient clipping thresholds, and dropout settings are not examined.
- Optimizer breadth: beyond AdamW and Muon, there is no evaluation with popular alternatives (e.g., Adafactor, Lion, Sophia, Shampoo/K-FAC, D-Adaptation), leaving open whether the spectral-guided LR allocation interacts favorably or unfavorably with second-order or factored preconditioning.
Theoretical foundations
- Causal link between heavy-tailedness and optimal LR: the method assumes lower
αimplies “better trained” layers and thus should receive smaller LRs, while higherαimplies undertrained layers meriting larger LRs. This is motivated by HT-SR but lacks a formal derivation connectingαto optimal step sizes in non-convex transformer training; boundary conditions where the heuristic fails are not identified. - Dynamics across training phases: the paper posits early-phase stabilization of
αand shows reductions inαunder LLR correlated with better perplexity. However, a principled account of howαshould evolve across regimes (e.g., representation learning vs. memorization) and how LR should respond is not provided. - Interplay with normalization: Transformers employ RMSNorm/LayerNorm; the effect of normalization on weight spectra and on the interpretability of
αas a training-quality proxy is not analyzed. - Mixture spectra and spikes: how to handle layers with spiked spectra, mixed heavy-tail and bulk components, or persistent outliers is not discussed; the stability of PL-fitting under these conditions is unclear.
Practical and engineering considerations
- Compute and wall-clock efficiency: while LLR improves token-efficiency (perplexity vs. tokens) and claims low overhead by restricting updates to 20% of training, the wall-clock overhead of repeated ESD/PL computation (and its scaling with model size, sequence length, and parallelism) is not quantified beyond one small case.
- Distributed training compatibility: the approach may require gathering sharded weights to compute spectra per layer. Communication overheads, implementation complexity in tensor/sequence/pipeline parallelism, and impact on optimizer/kernel fusion are not analyzed.
- Stability under switching: the “soft switch” reduces LR spikes, but the sensitivity to
t_switch, failure modes (e.g., rapidαoscillations), and interactions with warmup and cosine min-LR are not fully characterized. - Robustness and variance: results are reported without confidence intervals or multiple seeds; the variance of benefits across runs, datasets, and hyperparameters remains unknown.
- Fairness of baselines and tuning: although the paper states that baselines are “carefully tuned,” details of search spaces and budgets per baseline (especially for sharpness-guided schedules) are limited. Whether LLR’s gains persist under more exhaustive baseline tuning is open.
Extensions and edge cases
- Later-phase adaptation: if
αdrifts due to data non-stationarity, curriculum, or optimizer restarts, freezing LR allocation after 20% could be suboptimal. Can one design a low-cost mechanism for late-phase updates or change-point detection? - Continual and domain-adaptive pretraining: how does LLR behave when new domains are introduced mid-training, or when models are continuously pretrained over evolving corpora?
- Adapter/LoRA and PEFT settings: applicability of LLR when training adapters or low-rank updates (where weight matrices and spectra are structurally different) is not explored.
- MoE gating and experts: per-expert and gate matrices may exhibit distinct spectra; whether
α-guided LRs should be expert-specific (and how to compute them efficiently) is an open question. - Regularization interactions: the method’s synergy/conflicts with weight decay schedules (including
α-dependent decays as in AlphaDecay), dropout, label smoothing, and data augmentation are not dissected.
These gaps suggest concrete follow-ups: scale LLR to 7B–70B models with efficient spectral approximations; benchmark across diverse corpora and optimizers (e.g., Adafactor, Shampoo); perform ablations on PL-fitting and mapping (s, non-linear transforms); quantify wall-clock overhead in distributed settings; test adaptive late-phase updates; and investigate theoretical connections between α, curvature/conditioning, and layerwise optimal step sizes.
Practical Applications
Overview
This paper introduces Layerwise Learning Rate (LLR), a training scheme that adjusts learning rates per Transformer layer using heavy‑tailed spectral statistics (the power‑law exponent α) computed from weight correlation matrices. Layers with weaker heavy‑tailedness receive larger LRs; layers with stronger heavy‑tailedness receive smaller LRs. Practical designs include a capped scaling factor, a tailored high LR for embeddings/output heads, a “soft switch” to prevent LR spikes, and limiting spectral updates to the early 20% of training. Results across LLaMA/GPT‑nano (60M–1B+ params), AdamW/Muon, and token budgets (up to 100B) show up to ~1.5× training speedup, reduced perplexity, and better zero‑shot accuracy with minimal tuning overhead. Code is publicly available.
Below are actionable, real‑world applications grouped by deployment horizon.
Immediate Applications
The items below are deployable now with modest integration effort, leveraging the released code and existing libraries.
- Plug‑in per‑layer LR scheduler for LLM pretraining and fine‑tuning
- Sector: software/AI, cloud computing, MLOps, open‑source
- What to do: Integrate LLR as a scheduler in PyTorch/Hugging Face training loops to reduce training tokens/time (~1.5× speedup reported) and improve generalization (e.g., +~2 pp average on zero‑shot benchmarks).
- Tools/workflows:
- “LLR Scheduler” module that:
- Computes per‑layer spectral α via empirical spectral density (ESD) every ~100 steps during the first ~20% of training.
- Applies bounded LR scaling (e.g., s≈5×) with a soft LR switch.
- Keeps embeddings/output head at the upper LR bound.
- Uses cosine decay and standard warmup.
- Monitoring: log per‑layer α and LR to TensorBoard/W&B for diagnostics.
- Assumptions/dependencies:
- Access to model weights for ESD; small overhead for eigen/singular value estimation.
- Mixed‑precision stability must be validated; α estimation uses Hill estimator.
- Best results shown with cosine LR schedules and tuned global LR inherited from uniform baseline.
- Demonstrated on 60M–3B parameter ranges; larger scales require validation.
- Compute and energy cost reduction for enterprise/model labs
- Sector: cloud providers, enterprise R&D, sustainability
- What to do: Adopt LLR in training pipelines to reduce GPU hours and energy consumption; integrate LLR metrics into carbon accounting and budget dashboards.
- Tools/workflows:
- MLOps dashboards showing training speedup, GPU‑hours saved, and per‑layer α over time.
- Policy‑friendly reports quantifying energy savings per run.
- Assumptions/dependencies:
- Savings depend on baseline LR tuning and model scale; realize benefits primarily in early training.
- Requires instrumentation/telemetry in training jobs.
- Faster domain‑specific LLMs with reduced hyperparameter search
- Sector: healthcare, finance, legal, education, customer service
- What to do: Use LLR for pretraining/fine‑tuning domain models (e.g., clinical, legal, tutoring assistants) to reduce LR grid search and stabilize training across heterogeneous layers.
- Tools/workflows:
- Combine LLR with parameter‑efficient fine‑tuning (e.g., LoRA).
- Adopt default LLR hyperparameters (e.g., s≈5, α updates in early 20% of training).
- Assumptions/dependencies:
- Validate on domain‑specific corpora and tasks; comply with data privacy/regulations.
- Embedding/output head must be handled as in the paper (upper LR bound) to avoid under‑training.
- Academic experimentation and reproducibility
- Sector: academia, open‑source research
- What to do: Use LLR to reduce experimental variance and tuning overhead in Transformer studies; analyze layer heterogeneity via α.
- Tools/workflows:
- Jupyter/TensorBoard widgets to visualize α per layer and its evolution.
- Reproducible training recipes on LLaMA‑style backbones at 60M–350M–1B.
- Assumptions/dependencies:
- Small additional compute for spectral statistics; early‑phase updates minimize overhead.
- Better fine‑tuning stability in smaller models and encoders
- Sector: NLP product teams, classical ML practitioners
- What to do: Apply LLR when fine‑tuning BERT/RoBERTa‑class models and GPT‑nano to improve downstream accuracy and convergence without extensive LR sweeps.
- Tools/workflows:
- Swap Uniform LR schedule with LLR (retain base LR and decay schedule); activate soft switch and embedding‑layer upper LR.
- Assumptions/dependencies:
- Confirm α computation with encoder architectures; use smaller k/eigenvalue subsets if needed for speed.
- Cross‑domain Transformer training efficiency (where applicable)
- Sector: vision (ViTs), speech (Transformers/Conformers), recommendation (Transformers)
- What to do: Pilot LLR in non‑LLM Transformers to see if per‑layer α‑guided LR improves speed/quality.
- Tools/workflows:
- Minimal changes: reuse LLR core and logging; adapt layer groupings (e.g., ViT blocks, MLPs, attention).
- Assumptions/dependencies:
- Heavy‑tailedness/α as a quality proxy must hold (validate via small‑scale trials).
- Spectral estimation cost manageable for target architecture.
- On‑device/private personalization via faster local adaptation
- Sector: mobile/edge, privacy‑preserving AI, consumer apps
- What to do: Use LLR for short local fine‑tuning phases (e.g., personalization) to decrease wall‑clock time and energy on device or private servers.
- Tools/workflows:
- Run α estimation briefly (few early steps) or amortize using server‑side profiling transferred to device.
- Assumptions/dependencies:
- On‑device compute constraints; may need approximations (e.g., randomized SVD, reduced layer sets).
- Most practical for small models or brief adaptation windows.
Long‑Term Applications
These items will likely require further research, scaling, and engineering (especially for frontier models and new training regimes).
- Spectral‑feedback controllers for frontier‑scale and distributed training
- Sector: large‑scale AI labs, cloud providers
- Vision: Extend LLR to 10B–100B+ models with pipeline/data/model parallelism; distributed α estimation with low comms overhead; integrate with DeepSpeed/ZeRO/FSDP.
- Potential tools/workflows:
- Randomized/sketching methods for scalable ESD/α estimation.
- Cluster‑wide LR controllers that coordinate per‑layer LRs across shards.
- Assumptions/dependencies:
- Numerical stability with mixed precision; efficient eigensolvers; robust scheduling under asynchrony.
- Validation at scale on realistic corpora and training durations.
- Integration with instruction tuning, RLHF, and continual learning
- Sector: AI product teams building aligned assistants
- Vision: Use α‑guided LR during SFT and RLHF to stabilize training and prevent over/under‑training of specific modules across phases; adapt in continual learning to counter catastrophic forgetting.
- Potential tools/workflows:
- RLHF controllers that modulate per‑layer LR with α and policy metrics (e.g., KL, reward variance).
- Assumptions/dependencies:
- Empirical link between α and alignment/robustness remains to be established; careful safety evaluation needed.
- Multi‑modal and diffusion models with heavy‑tail‑aware optimization
- Sector: vision‑language (VLMs), generative media, robotics perception
- Vision: Apply α‑guided LRs to vision encoders/decoders, cross‑modal fusion, and U‑Nets/transformers in diffusion to improve sample quality and training speed.
- Potential tools/workflows:
- Module‑wise LR maps (e.g., image encoder vs. text encoder vs. cross‑attention).
- Assumptions/dependencies:
- Confirm heavy‑tailedness patterns and α‑quality correlation in these modalities.
- Hardware‑aware and co‑designed optimizers
- Sector: semiconductor vendors, systems research
- Vision: On‑accelerator kernels that compute approximate spectral tails and apply layerwise LR updates with negligible overhead; SPMD microcode or firmware support.
- Potential tools/workflows:
- Library primitives for α estimation; fused ops in cuDNN/ROCm/XLA.
- Assumptions/dependencies:
- Vendor collaboration; standardized APIs for per‑layer LR schedules.
- AutoML/autotuning without manual LR sweeps
- Sector: platform providers, AutoML tools
- Vision: Combine spectral α with curvature/sharpness/noise‑scale signals into a unified controller that auto‑configures LR, weight decay, and schedule per layer.
- Potential tools/workflows:
- “Spectral Optimizer” suite: α‑guided LR + α‑guided weight decay (unified with Alphadecay).
- Assumptions/dependencies:
- Robust generalization across tasks, scales, and optimizers; benchmarking for fairness.
- Training governance and sustainability policy
- Sector: policy, ESG reporting, standards bodies
- Vision: Encourage/require energy‑efficient training practices (e.g., α‑guided LRs) in reporting frameworks; incorporate “optimization efficiency” metrics alongside FLOPs and emissions.
- Potential tools/workflows:
- MLCommons/ISO‑style benchmarks that include spectral‑aware optimization practices.
- Assumptions/dependencies:
- Broader evidence at frontier scales; consensus on metrics and verification.
- Reliability, safety, and “health” monitoring during training
- Sector: responsible AI, risk management
- Vision: Use α trajectories as signals for anomalous training (e.g., sudden layer overfitting or collapse), triggering LR adjustments, early stopping, or data curation interventions.
- Potential tools/workflows:
- “Alpha Monitor” that alerts when layers’ α deviates from healthy ranges; ties into MLOps incident response.
- Assumptions/dependencies:
- Establish thresholds and causal links between α patterns and downstream risks.
- Standardization in libraries and curricula
- Sector: open‑source ecosystems, education
- Vision: Add dynamic layerwise LR schedules as first‑class citizens in PyTorch/HF; integrate HT‑SR/α topics into ML courses and practitioner trainings.
- Potential tools/workflows:
- PRs adding LLR schedulers and α loggers; educational labs demonstrating heavy‑tailed ESDs and LR mapping.
- Assumptions/dependencies:
- Community acceptance and maintenance; clear API design.
Key cross‑cutting assumptions and dependencies
- Heavy‑tailedness and the power‑law exponent α are valid proxies for “training progress/quality” across layers; this held across tested LLMs but needs validation in other architectures and scales.
- Overheads from spectral estimation are manageable when constrained to early training and periodic updates; larger models may require approximate methods (randomized SVD/sketching) and distributed implementations.
- Reported gains rely on:
- Bounded LR scaling (typical s≈5).
- Soft LR switching to avoid spikes.
- Cosine decay schedules and standard warmup.
- Tailored high LR for embeddings/output heads.
- Results demonstrated up to ~3B parameters and token budgets up to 100B; extrapolation to frontier models (70B+) and other training regimes (RLHF, multi‑modal) requires further evidence.
- Mixed‑precision training and numerical stability must be verified when computing spectra; careful selection of eigenvalue subset (k) and precision is needed.
By adopting LLR now in training pipelines and advancing it for new regimes and scales, organizations can achieve faster convergence, better model quality, and tangible cost/energy savings with minimal additional tuning.
Glossary
- AdamW: An optimization algorithm that decouples weight decay from the gradient-based update in Adam. "Training loss curves of LLaMa-1B and LLaMa-3B under the AdamW optimizer"
- Adammini: An optimizer variant that introduces layer-wise learning-rate ideas to improve training efficiency. "Adammini, mup and CompleteP."
- Alphadecay: An HT-SR–based method that modulates weight decay across modules using spectral metrics. "Alphadecay and Tempbalance."
- Chinchilla scaling law: A compute-optimal guideline relating model size and training tokens for efficient pretraining. "under Chinchilla scaling law \cite{hoffmann2022training}"
- cosine learning rate schedule: A schedule that decays the learning rate following a cosine curve over training. "All models are trained with gradient clipping at 1.0 and a cosine learning rate schedule"
- Dirac delta function: A generalized function used to define distributions; here it formalizes the empirical spectral density. "where denotes the Dirac delta function"
- Empirical Spectral Density (ESD): The empirical distribution of eigenvalues (or singular values) of a matrix, used to characterize spectral properties of weights. "which characterizes the empirical spectral density (ESD) of weight correlation matrices"
- FFN (Feed-Forward Network): The position-wise multilayer perceptron submodule in Transformer blocks. "the FFN parameters (FFN.gate, FFN.up, FFN.down)"
- gradient clipping: A technique that caps the gradient norm to prevent exploding gradients. "All models are trained with gradient clipping at 1.0"
- Heavy-Tailed Self-Regularization (HT-SR) theory: A framework linking heavy-tailed weight spectra to training quality and generalization. "Our method is grounded in Heavy-Tailed Self-Regularization (HT-SR) theory"
- heavy-tailedness: The property of having power-law tails in a distribution; used to measure correlation strength in weight spectra. "to quantify heavy-tailedness."
- Hessian spectra: The distribution of eigenvalues of the loss Hessian, reflecting curvature and sharpness across layers. "the Hessian spectra differ substantially across layer types"
- Hill estimator: A statistical estimator of the tail index (power-law exponent) used for heavy-tail analysis. "The Hill estimator is given by:"
- LAMB: Layer-wise Adaptive Moments optimizer designed to scale learning rates using weight norms for stability. "LAMB \citep{you2019large}: A second-moment-based adaptive optimization algorithm"
- LARS: Layer-wise Adaptive Rate Scaling optimizer that scales learning rates by the ratio of weight to gradient norms. "LARS \citep{you2017large} and LAMB \citep{you2019large} scale LRs by the gradient-to-weight norm ratio"
- Layerwise Learning Rate (LLR): The paper’s method that assigns per-layer learning rates based on spectral heavy-tailedness to balance training. "Layerwise Learning Rate (LLR), an adaptive scheme that assigns distinct learning rates to individual Transformer layers."
- learning rate warmup: A strategy that gradually increases the learning rate at the start of training to improve stability. "with 10 of the training tokens used for learning rate warmup."
- LLaMA: A family of Transformer-based LLMs used as the paper’s main architecture. "pre-training various sizes of LLaMa models"
- Muon: A recently proposed optimizer used as a baseline/alternative to AdamW in experiments. "optimizers (AdamW and Muon)"
- Mup-AdamW: An AdamW variant paired with μ-parameterization (μP) scaling rules for stable width scaling. "Mup-AdamW \ \cite{yang2020feature}"
- Perplexity: A standard language modeling metric equal to the exponential of cross-entropy; lower is better. "Validation perplexity () is reported."
- PL exponent (): The power-law tail index estimated from the ESD, quantifying tail heaviness. "using the resulting PL exponent () as the measurement criterion."
- Power‑Law (PL) fitting: Fitting a power-law to the empirical spectrum to estimate the tail exponent. "performs PowerâLaw (PL) fitting"
- RLHF: Reinforcement Learning from Human Feedback, a post-training technique for aligning LLMs. "and RLHF \citep{ouyang2022training}"
- Sharpness: A measure of loss landscape curvature; disparities across modules can guide layer-wise LR choices. "identified sharpness disparities across Transformer modules"
- TempBalance: A method leveraging HT-SR to adjust layer-wise learning rates (notably in CNNs/fine-tuning scenarios). "The closest related work is TempBalance \citep{zhou2023temperature}"
- weight decay: An L2 regularization term applied during optimization to control model complexity. "applies HT-SR to modulate weight decay"
- Zero-shot evaluation: Testing model performance on unseen tasks without task-specific fine-tuning. "Zero-shot evaluation results ()"
Collections
Sign up for free to add this paper to one or more collections.

