- The paper introduces a verifier-guided evolutionary framework that adapts test-time skill artifacts using agent execution traces without retraining the model.
- The paper shows that integrating runtime dense feedback significantly increases pass rates and enhances skill quality, achieving a 33.6% pass rate on hard tasks.
- The paper highlights the creation of traceable artifacts and dense behavioral metrics that enable post hoc skill auditability and robust agent performance.
Trace2Skill: Verifier-Guided Skill Evolution for Long-Context EDA Agents
Motivation and Problem Statement
Electronic design automation (EDA) presents unique challenges for agentic LLMs, notably with Complex Verilog Design Problems (CVDP) that require repository navigation, intricate RTL editing, testbench orchestration, build dependency management, and recovery from hidden verification failures. Conventional approaches emphasize model fine-tuning or parallel solution sampling, but these methods falter on hard CVDP tasks with sparse learning signals and long-context, multi-turn requirements. Trace2Skill directly addresses this gap by using agent execution traces as a source of task-specific skill adaptation, eschewing RTL-specialized model updates and instead evolving skill artifacts injected at test time to a fixed agent.
Methodology
Trace2Skill operates as a training-free, skill-evolution pipeline. It ingests repeated agent rollouts on a target task, leverages runtime dense verifier feedback when available, and employs an oracle--mutator--selector evolutionary loop. The core adaptive unit is the skill text, guiding agent search, editing, validation, and recovery. Skills evolve across generations, where each candidate skill is evaluated via agent rollouts, scored using dense behavioral and semantic metrics, and selected based on a composite survivor signal (SelectQ) that combines sparse verifier success and repeat-robust agent progress.
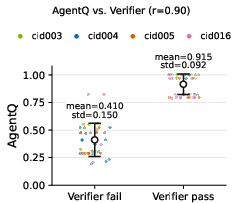
Figure 1: AgentQ proxy on 96 completed OSS seed-skill baseline rollouts, grouped by hidden verifier outcome and colored by CID.
Dense feedback is an optional mechanism that provides sanitized functional signals during rollouts, converting otherwise opaque verifier failures into actionable observations without exposing hidden harnesses or reference designs. Skill mutation and repair, under oracle guidance, ensure evolved skills retain critical task-specific rules and exclude unsafe or semantically regressive advice. All stages yield traceable artifacts, facilitating post hoc analysis and skill auditability.
Metrics
Sparse pass/fail outcomes, while definitive, are insufficient for dense optimization in hard CVDP tasks. Trace2Skill employs hierarchical metrics:
- PassRate: Hidden verifier pass fraction.
- SkillQ: Semantic skill content quality, assessing rule coverage, evidence grounding, actionability, validity, redundancy, and conservative mutation size.
- AgentProgressQ: Rollout behavioral quality, synthesizing partial verifier progress, execution phases, harness alignment, edit quality, turn efficiency, and path grounding.
- AgentVarianceQ: Behavioral repeat stability, indicating the stochasticity of rollouts under the same skill.
- SelectQ: Survivor-selection composite score, prioritizing pass rate but tie-breaking with robust agent progress and skill quality.
These metrics have strong empirical correlations with sparse outcomes; notably, AgentQ achieves r=0.90 and AUC=0.982 vis-à-vis final pass/fail labels on baseline rollouts, validating its utility as an optimization proxy.
Experimental Setup and Configurations
The study benchmarks Trace2Skill on 24 OSS-accessible CVDP tasks spanning specification-to-RTL, refinement, completion, and bug fixing categories. Frontier coding agents (Claude Code, Codex) are compared against the seed-skill CVDP agent. The eight hardest baseline failures—unsolved by all agents or only by the CVDP agent—form the core ablation suite for Trace2Skill analysis.
Four ablated configurations are evaluated using a consistent rollout budget and hidden verifier policies:
- C1: Baseline agent without skill evolution or dense feedback.
- C2: Baseline agent with runtime dense feedback.
- C3: Trace2Skill skill evolution under sparse reward.
- C4: Trace2Skill with dense reward/feedback.
Results and Analysis
Baseline performance on public OSS tasks shows CVDP agent pass rates inferior to frontier black-box baselines but highlights its traceability and skill adaptation advantages. On the eight hard tasks, C4 (Trace2Skill plus dense feedback) achieves 6/8 solved tasks and 33.6% pass rate, outperforming all non-evolution and non-feedback configurations (C1: 0/8, C2: 2/8, C3: 3/8), and raising AgentQ to 0.566.

Figure 2: C3 versus C4 quality dynamics on the 8 hard CVDP tasks. Points show generation-level means; error bars show SEM across valid candidate-skill measurements.
Quality metrics reveal that runtime dense feedback not only increases final pass rates but also improves the skill content (SkillQ) and execution stability (AgentProgressQ, AgentVarianceQ), fostering more repeatable rollout trajectories and actionable oracle lessons. The survivor-selection process ensures that skills evolve based on both behavioral evidence and semantic fitness, rather than single lucky rollouts.
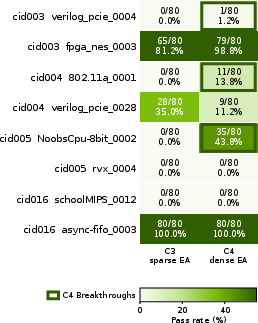
Figure 3: Task-level C3/C4 verifier outcomes on the 8 hard tasks. Cells show pass count and pass rate over five generations × four candidate skills × four repeats.
Task-level outcomes highlight C4-only breakthroughs, e.g., NoobsCpu-8bit_0002 with 35/80 passes (all leveraging dense verifier feedback), 802.11a_0001 with 11/80 passes, and verilog_pcie_0004 with 1/80 passes. Dense feedback transforms hidden functional failures into mid-rollout, actionable skill updates, which propagate through oracle summaries and mutator repairs. Agentic coadaptation between skill and behavioral trajectory emerges as a central mechanism.
Limitations
Trace2Skill is compute-intensive: long-horizon rollouts, multi-generation evolutionary adaptation, and dense verifier calls amplify resource requirements. The OSS task set is still heavily RTL-centric; broader EDA task integration remains an open challenge. Behavioral variance persists, suggesting skill content and feedback specificity could further regularize agent execution.
Implications and Future Directions
Practically, Trace2Skill delivers robust recovery on hard CVDP tasks where fine-tuned models and frontier agents fail, by leveraging only execution traces, inspectable skills, and verifier rewards. It sidesteps the need for extensive RTL-specialized model data or weight updates, offering a general test-time scaling strategy for verifiable EDA tasks. Theoretically, Trace2Skill advances dense behavioral credit assignment and post hoc skill auditability, promoting interpretable, trace-driven agent improvement in complex engineering domains.
Future development should focus on reducing compute overhead via adversarial feedback scheduling and procedural guidance enhancement, extending task-wise skill evolution to synthesis, formal verification, and full-flow scenarios, and integrating with collaborative multi-agent and benchmark frameworks.
Conclusion
Trace2Skill employs evolutionary adaptation of injected skills, guided by dense behavioral metrics and verifier feedback, to achieve recovery on long-context, multi-turn EDA tasks unsolved by both baseline agents and frontier LLMs. Its design embodies skill-agent coadaptation and dense trace mining, delivering interpretability, robustness, and extensibility without model retraining, and setting an effective blueprint for agentic scaling in verifiable code domains.