- The paper demonstrates that unlearned LLMs exhibit low calibration error while increasingly relying on shortcut cues for decision making.
- The methodology leverages controlled benchmarks like TOFU and RELU MCQA to assess both probabilistic reliability with ECE, MCE, and Brier Score and shortcut detection via attribution analysis.
- Results highlight that calibration alone is insufficient to guarantee semantic decision quality, urging the adoption of dual-axis evaluation for machine unlearning.
Reliability Paradox in Machine Unlearning: Calibration versus Decision Rules in LLMs
Motivation and Problem Setting
The paper "Calibration vs Decision Making: Revisiting the Reliability Paradox in Unlearned LLMs" (2605.20915) rigorously examines the intersection of machine unlearning and model reliability in generative LLMs. Unlearning aims to remove the influence of specific training data while preserving model fidelity on retained information. Traditionally, calibration—where predicted confidence matches empirical accuracy—is employed as a reliability surrogate, but recent evidence exposes a critical flaw: well-calibrated models may still operate on non-semantic, shortcut cues, undermining reliability. The study extends the reliability paradox established in encoder-based models to decoder-only architectures under the unlearning regime, interrogating whether calibration remains a sufficient metric when model decision rules shift during targeted forgetting.
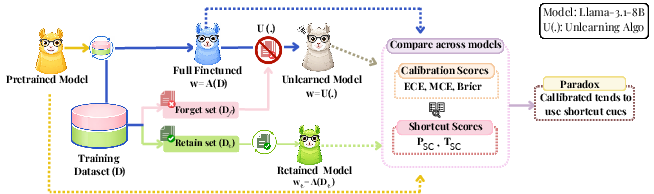
Figure 1: Reliability evaluation pipeline: dataset split, fine-tuning/unlearning, and evaluation using calibration and attribution-based shortcut detection.
Methodological Framework
The authors leverage the TOFU benchmark, a controlled dataset for structured forgetting and retention studies, coupled with RELU MCQA format, which facilitates probabilistic reliability measurement and fine-grained attribution analysis. Four model states are interrogated: pretrained, fully fine-tuned, retained (ideal unlearned via direct training on retained data), and unlearned (via approximate unlearning algorithms).
Reliability is dissected from two complementary perspectives:
- Probabilistic Reliability: Quantified with ECE, MCE, and Brier Score, using confidence bins over MCQA outputs.
- Decision Rule Reliability: Assessed via token-level Integrated Gradients and corpus-level Local Mutual Information (LMI), identifying tokens with both high model attribution and dataset-wide correlation as shortcut cues. Metrics PSC (proportion of shortcut-cued predictions) and TSC (tradeoff between task performance and shortcut reliance) formalize shortcut usage.
Four prominent unlearning algorithms are evaluated (Gradient Ascent, Gradient Difference, Negative Preference Optimization, Direct Preference Optimization) with LoRA for efficient, low-rank adaptation.
Results: Calibration and Shortcut Reliance
Empirical evaluation reveals several critical findings:
- Calibration Behavior: Fine-tuned and unlearned models consistently achieve low ECE (≈0.04–$0.08$ on retained splits), indicating high confidence–accuracy alignment post-unlearning. On forget splits, calibration error rises, as expected, but remains below thresholds in retained data.
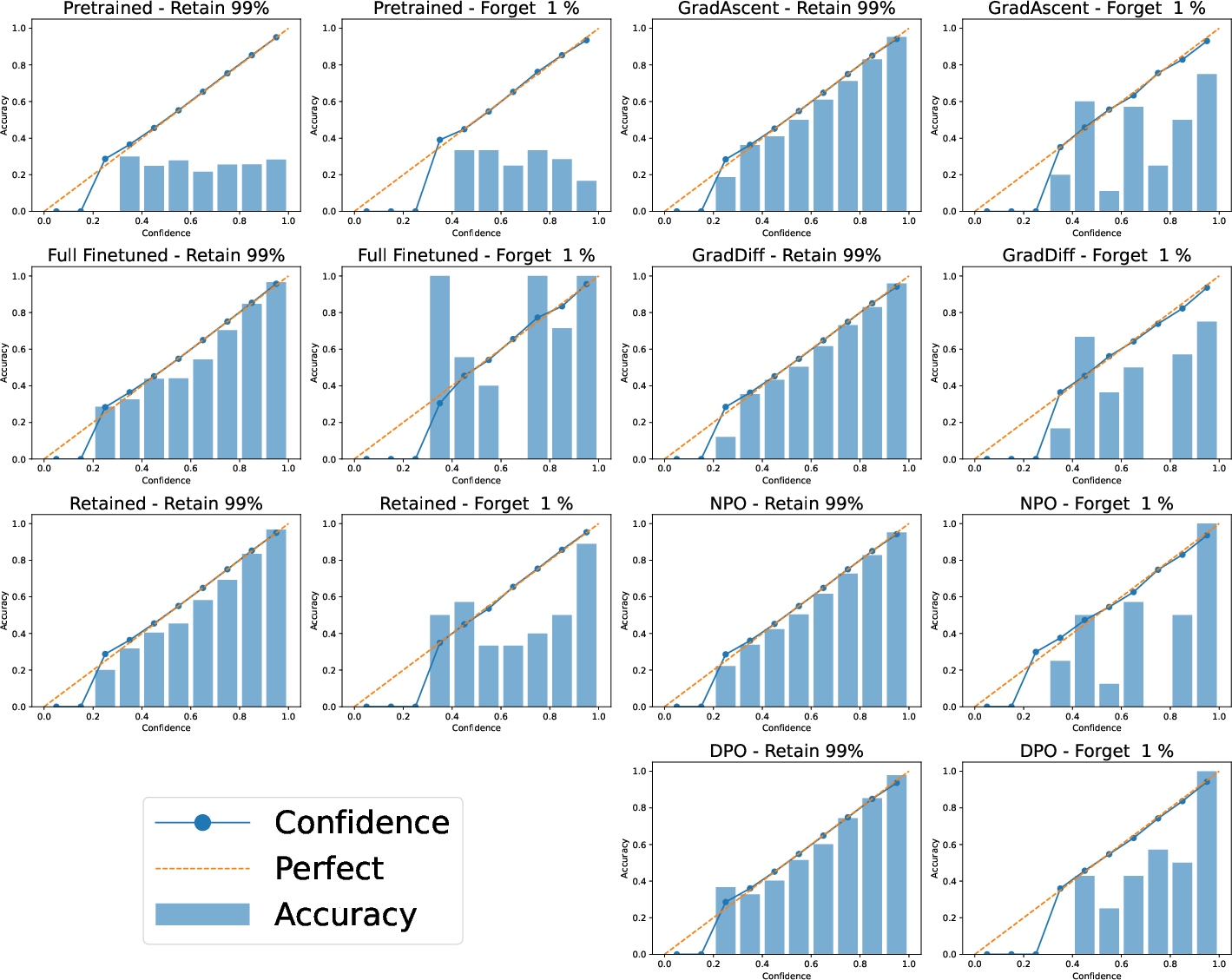
Figure 2: Calibration curves for 1% forget—fine-tuned and unlearned models are well calibrated, but display notable deviations in mid-confidence regions.
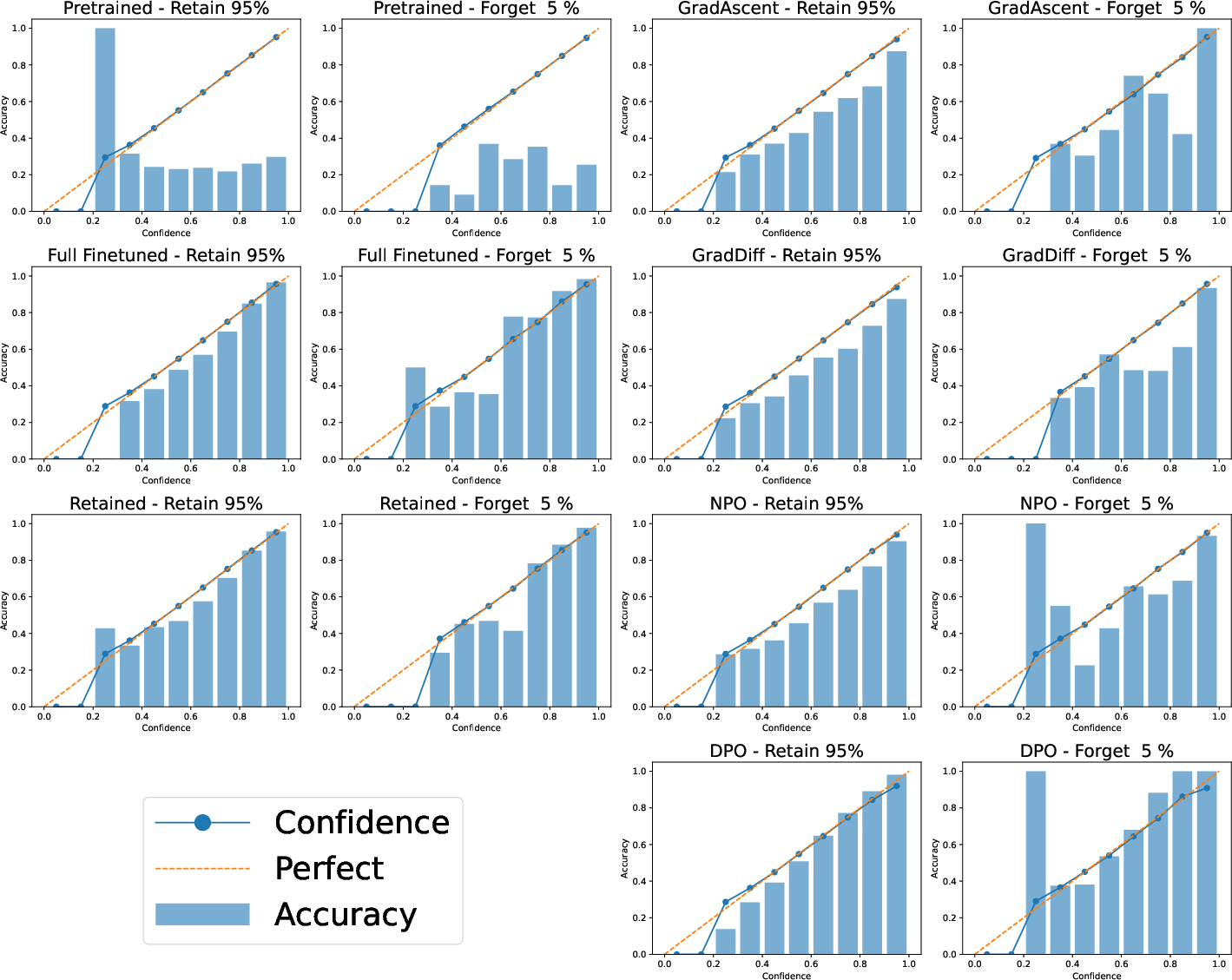
Figure 3: Calibration curves for 5% forget—calibration remains robust overall, but variability increases and miscalibration emerges in intermediate bins.
- Decision Rule Degradation: Attribution analysis uncovers an increased reliance on shortcut cues post-unlearning. PSC remains high (>85%) even in well-calibrated models, and in some cases, shortcut usage increases rather than decreases after unlearning, especially at higher forgetting ratios. TSC drops across unlearning variants, reflecting a compromised tradeoff between performance and legitimate decision features.
- Qualitative Patterns: Post-unlearning models often favor verbs, grammatical function words, and dataset-specific signals ("does", "about") rather than semantically relevant entities or context-dependent features derived from the question prompt (see Table~\ref{tab:shortcut_tokens_main}).
Theoretical and Practical Implications
These results strengthen the reliability paradox: calibration is insufficient in isolation for certifying decision quality in unlearned models. The divergence between confidence alignment and meaningful decision rules persists even under explicit targeted parameter modification. Practical implications are profound—deployed LLMs subjected to unlearning can pass calibration-based audits while still relying on non-generalizable, artifacts-based heuristics. This poses nontrivial risks for applications in medical assistance, legal NLP, and other high-stakes domains, where explainable and robust decision foundations are imperative.
Theoretically, this finding underscores the necessity for dual-axis evaluation of reliability in machine unlearning—both calibration and decision rule analysis—and signals the demand for unlearning algorithms regularized to mitigate shortcut adoption. The limit of MCQA-based calibration diagnostics in open-ended generative settings is also established.
Limitations and Future Directions
The paper’s scope is bounded by single architecture evaluation (Llama-3.1-8B), controlled dataset/benchmark protocols (TOFU, RELU MCQA), and MCQA-driven calibration metrics. Approximate shortcut detection is dependent on attribution and LMI methodology; generalization to diverse tokenizations and architectures requires further exploration. Robustness (OOD performance post-unlearning) is not addressed.
Future research is encouraged to develop shortcut-aware regularization for unlearning algorithms, integrate joint calibration/attribution diagnostics in evaluation pipelines, and expand reliability studies to larger, more diverse architectures and open-ended task formats.
Conclusion
This work establishes that decoder-only LLMs subjected to machine unlearning exhibit a marked reliability paradox: they sustain calibration quality while increasingly relying on dataset-specific shortcuts. Calibration metrics, therefore, are inadequate as sole indicators of reliability—models may appear statistically trustworthy while enacting unsound, non-semantic decision rules. Comprehensive reliability evaluation for unlearned LMs must concurrently interrogate probabilistic fidelity and the semantic legitimacy of decision features.
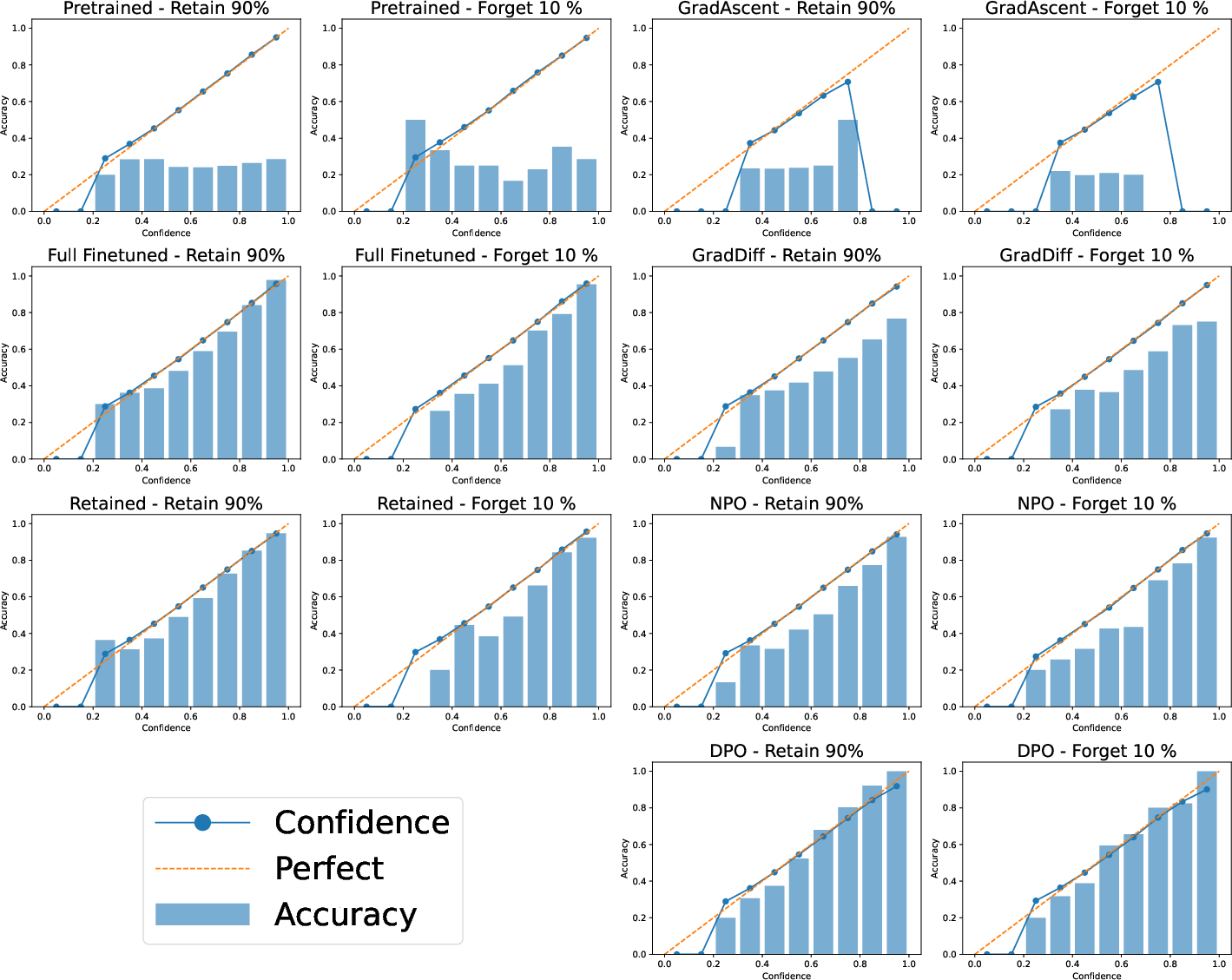
Figure 4: Reliability diagrams for 10% forget—deviations in lower/mid-confidence bins demonstrate that calibration does not safeguard against shortcut-driven decisions after unlearning.

