- The paper presents an agentic framework that integrates structured multimodal reasoning with dynamic tool invocation for enhanced open-vocabulary industrial anomaly detection.
- It employs a three-stage methodology combining supervised fine-tuning, external tool orchestration, and reinforcement learning with precision-driven rewards to mitigate false negatives.
- Performance evaluations show a balanced score of 83.4% across benchmarks and up to 17.4% recall improvement, demonstrating substantial gains over prior approaches.
Introduction and Motivation
Open-vocabulary industrial anomaly detection (IAD) faces critical challenges due to the unpredictable emergence of novel product types and defect morphologies in manufacturing environments. Existing paradigms—spanning reconstruction-based, embedding-based, and even vision-LLM approaches—are fundamentally limited by closed-set assumptions, scale-blindness, and lack of dynamic evidence acquisition. Recent progress in multimodal LLMs (MLLMs) enables zero-shot reasoning by bridging vision and language, but these models struggle with domain-misaligned reasoning and structural hallucinations. IndusAgent introduces an agentic, tool-augmented inspection paradigm for IAD, leveraging structured reasoning, external tool orchestration, and agentic reinforcement learning to address perceptual ambiguities and ensure robust, precise diagnostic inference.
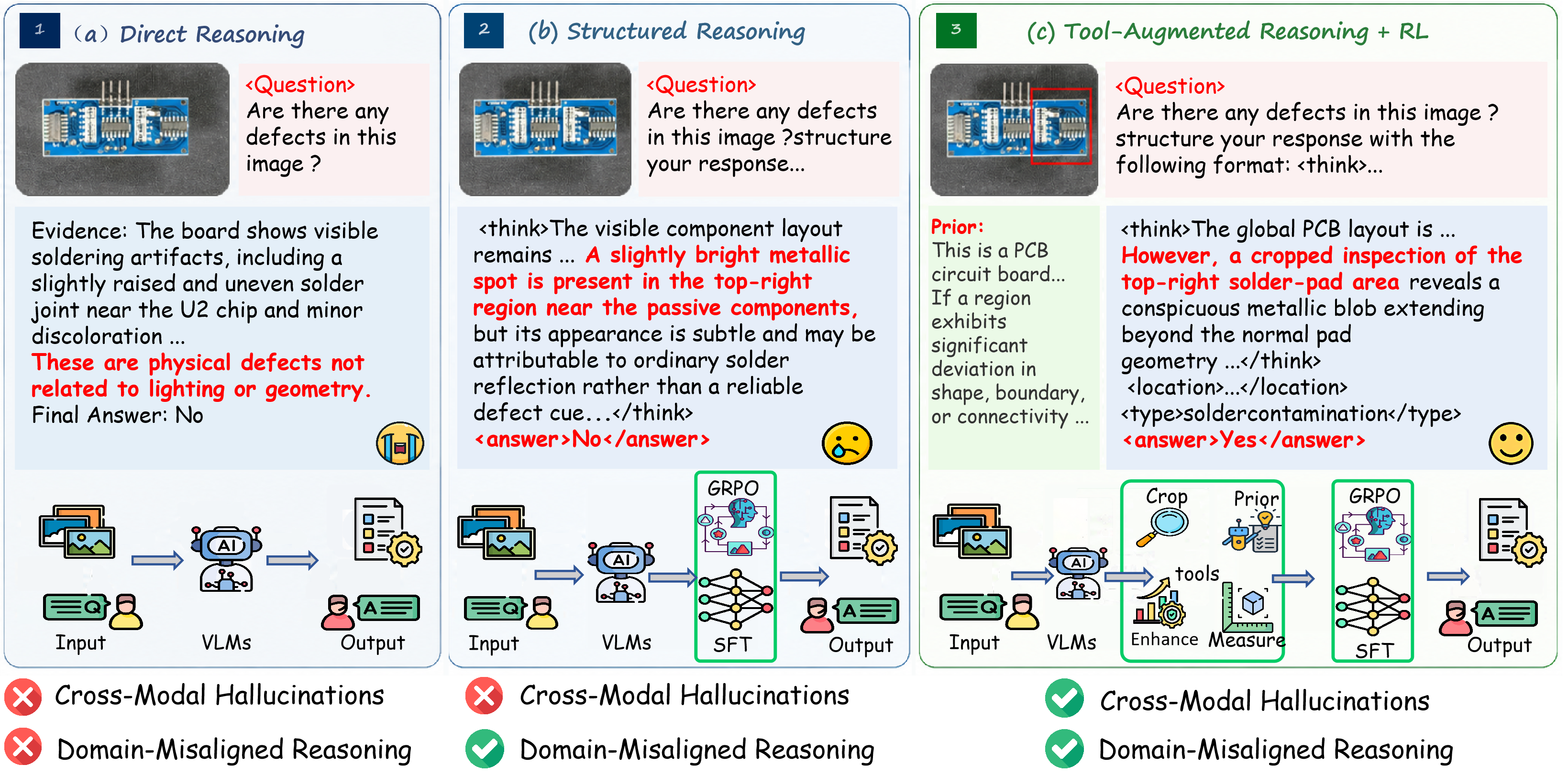
Figure 1: Comprehensive comparison of MLLM-based anomaly detection paradigms, illustrating the limitations of standard and ordinary CoT MLLMs and the improvements enabled by IndusAgent’s tool-based inspection.
Framework and Methodology
The IndusAgent pipeline consists of three sequential stages: a tool-integrated structured dataset (Indus-CoT) for reasoning supervision, agentic supervised fine-tuning (SFT) for protocol alignment, and tool-augmented reinforcement learning (RL) with a precision-driven reward mechanism. These stages tightly couple domain-knowledge acquisition, structured multimodal reasoning, and cost-aware tool invocation.
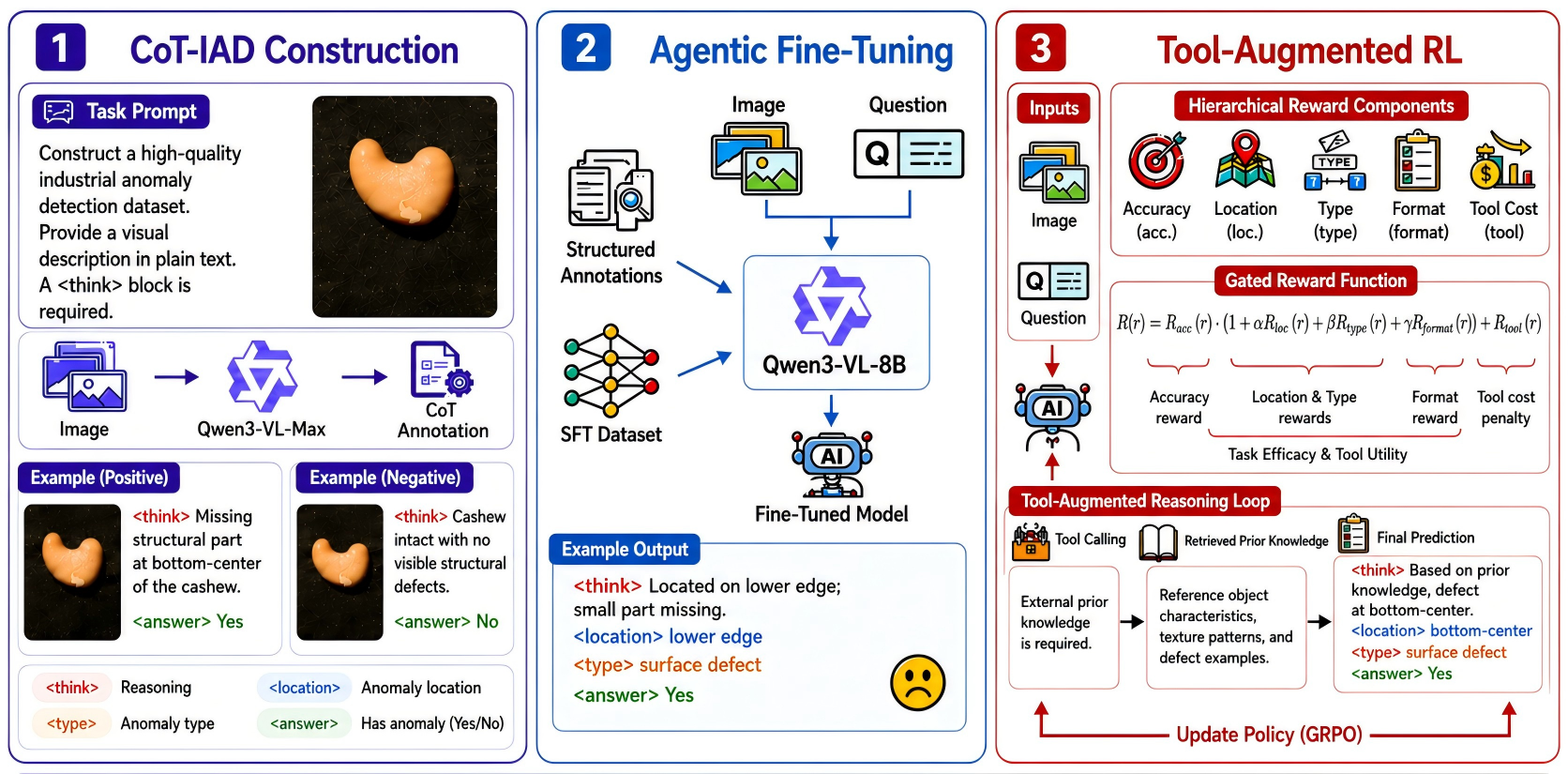
Figure 2: IndusAgent system architecture—depicting Indus-CoT data construction, agentic fine-tuning, and tool-augmented RL training phases.
IndusAgent instantiates the underlying visuolinguistic model (Qwen3-VL-8B) as an agentic policy that autoregressively decides on multi-step actions, including when to invoke external tools:
- Dynamic Region Cropping: Extracts high-resolution patches to capture fine-grained, localized defects undetectable in global views.
- Normalcy Prior Retrieval: Pulls expert-curated defect-free structural priors to anchor reasoning and avoid mistaking legitimate variations for anomalies.
- Low-Level Visual Enhancement: Applies lightweight computer vision operations (e.g., CLAHE, edge detection) for highlighting low-contrast and ambiguous textures.
- Geometric Measurement: Computes precise spatial relations, enabling verification of geometric anomalies such as misalignments and deformations.
The agentic policy fuses tool-derived feedback with global image context and instruction, integrating multimodal evidence before anomaly classification and detailed localization.
Indus-CoT Dataset and Structured Supervision
Indus-CoT provides reference-free, tool-integrated multimodal CoT trajectories, constructed using a strong teacher model, that synthetically generates inspection processes crossing global observation, tool execution, and final verification. The dataset is built to be strictly category-disjoint from evaluation domains, ensuring that learned behaviors transfer to unseen products and defects. Structured masking strategies during SFT guarantee the model internalizes diagnostic logic rather than spurious context memorization.
Agentic Fine-Tuning and Reinforcement Learning
Direct RL post-training for multimodal tasks is notoriously unstable. IndusAgent employs supervised fine-tuning with structured reasoning traces for cold-start initialization, followed by Group Relative Policy Optimization (GRPO) RL with a hierarchical, accuracy-gated reward function:
- Reward Gating: Only activates localization, categorization, and tool-utility rewards when the final (binary) diagnostic label is correct, strictly discouraging reward gaming and tool abuse.
- Cost-Aware Tool Utility: Rewards tool invocation only when it yields measurable diagnostic confidence improvement, penalizing redundant or unhelpful tool usage.
- Format Compliance: Penalizes malformed outputs to maintain structured trajectory generation.
Experimental Analysis
IndusAgent is evaluated on five industrial anomaly detection benchmarks: MVTec-AD, VisA, MPDD, DTD, and SDD, covering both structured workpiece and texture-centric domains. The evaluation is conducted under a strict zero-shot, reference-free, and category-disjoint protocol.
IndusAgent achieves state-of-the-art performance, yielding an average balanced score of 83.4% on all benchmarks with only 8B parameters, notably outperforming both proprietary commercial APIs and the largest available open-source models by substantial margins.
- On particularly challenging datasets (VisA, MPDD), IndusAgent delivers scores of 76.8% and 72.7%, respectively, decisively surpassing previous vision-LLM baselines.
- Recall analysis demonstrates that IndusAgent substantially mitigates the false-negative bottleneck endemic to IAD, exhibiting recall surges up to +17.4% compared to IAD-R1 on MPDD.
- Ablation studies confirm that removal of the agentic SFT or tool-augmented RL modules produces catastrophic performance degradation, while toolset ablations validate the necessity of each distinct tool, with cropping and enhancement being most critical on object- and texture-centric domains, respectively.

Figure 3: Case study comparing Qwen3-VL-8B baseline to IndusAgent; IndusAgent avoids hallucination and accurately grounds diagnostic reasoning via tool-augmented inspection.

Figure 4: Another case study illustrating successful fine-grained defect detection by IndusAgent in a visually ambiguous industrial scene.

Figure 5: Further case study comparison, highlighting IndusAgent’s ability to leverage geometric measurement for precise localization.
Analysis of tool invocation policies reveals highly selective, dataset-adaptive behavior: cropping dominates object-centric tasks (invoked >60% of time), whereas enhancement is preferred for high-frequency texture scenarios. The success rate of tool execution approaches 99%, evidencing robust integration.
Implications and Future Directions
IndusAgent establishes a new paradigm for category-disjoint, open-vocabulary industrial visual inspection, demonstrating that passive visuolinguistic reasoning is inadequate for micro-defect detection and that active, cost-aware evidence gathering is critical for robust decision-making. Practically, this framework lowers the annotation and supervision burden for industrial anomaly inspection, facilitating rapid adaptation to emergent products and defects. Theoretically, it raises the bar for structured reasoning in agentic MLLMs, underscoring the efficacy of tool-augmented RL with tightly-coupled reward gating for reducing hallucination and gaming.
Future research directions include extending the agentic inference paradigm to multimodal temporal streams (e.g., video inspection), exploring lightweight tool-integration for deployment in resource-constrained edge settings, and refining the reward framework to jointly optimize for human trustworthiness and process efficiency. The methodology also inspires broader adoption in other critical visual diagnosis domains (medical, scientific, security), where high-stakes precision and interpretability are paramount.
Conclusion
IndusAgent operationalizes a rigorous, tool-integrated, agentic inspection protocol for open-vocabulary industrial anomaly detection, combining structured multimodal reasoning with cost-aware, RL-driven exploration. The results decisively demonstrate that sophisticated orchestration of evidence acquisition and stringent reward gating are essential for reliable and generalizable industrial vision applications, setting a new standard for next-generation MLLM-based active inspection systems (2605.20682).

