- The paper demonstrates that fine-tuning MLLMs on the MMR-AD dataset dramatically improves anomaly detection and localization metrics.
- The methodology integrates Chain-of-Thought reasoning, automated text generation, and reinforcement learning to refine performance.
- The dataset, with 127,137 samples spanning 14 industrial sources, ensures diverse and precise evaluation of general anomaly detection.
MMR-AD: A Large-Scale Multimodal Dataset for Benchmarking General Anomaly Detection with Multimodal LLMs
Motivation and Problem Scope
General anomaly detection (GAD) seeks to identify anomalies across novel, previously unseen classes without model retraining or fine-tuning. This task is foundational in industrial anomaly detection (IAD), pushing the field beyond specialist, class- or task-specific detectors towards generalist architectures. Multimodal LLMs (MLLMs), such as Qwen2.5-VL, GPT-4V, and Gemini-2.5, have demonstrated considerable progress in cross-modal reasoning, yet their efficacy on fine-grained anomaly detection, especially when robust localization is required, remains under-characterized due to the lack of high-quality multimodal reasoning benchmarks adapted for anomaly detection.
The "MMR-AD: A Large-Scale Multimodal Dataset for Benchmarking General Anomaly Detection with Multimodal LLMs" (2604.10971) addresses the aforementioned gap by providing a comprehensive dataset for GAD evaluation and model development. It also provides a rigorous empirical assessment of both commercial and open-source MLLMs on this GAD task and introduces Anomaly-R1, a reasoning-centric AD baseline post-trained with Chain-of-Thought (CoT) reasoning and reinforced via RL.
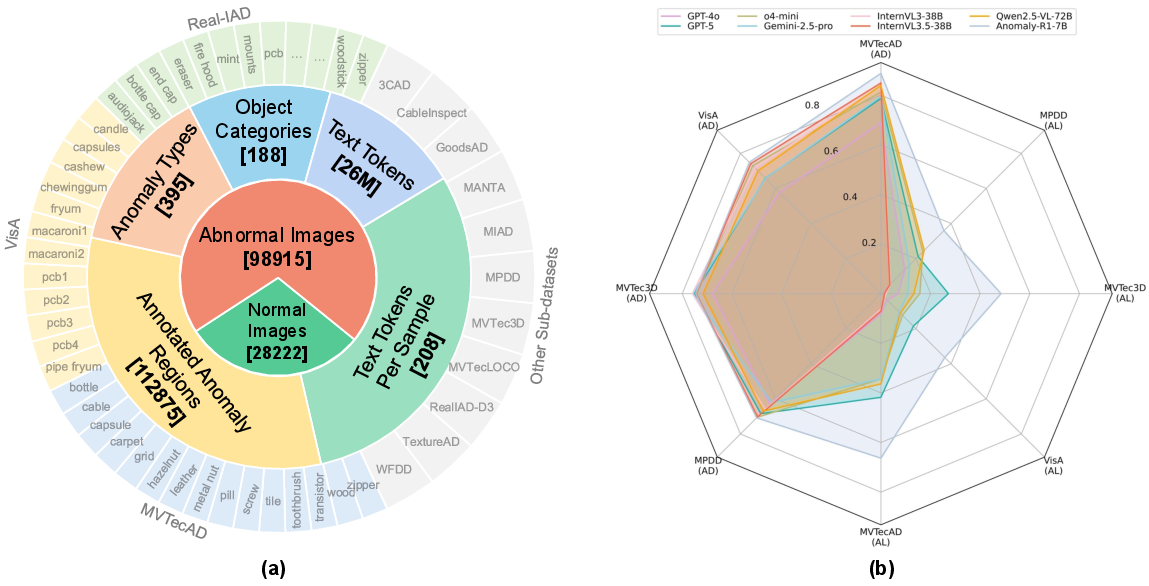
Figure 1: Overview and performance impact of MMR-AD, illustrating dataset composition and anomaly detection/localization improvement from domain-specific post-training.
Dataset Design and Construction
MMR-AD is curated from 14 public industrial AD datasets, spanning 188 product classes and encompassing 395 anomaly types, totaling 127,137 samples with 112,875 annotated anomalous regions. Key to its design is quality assurance: image-level and region-level noise (e.g., incorrect or ambiguous anomaly labels) from source datasets is manually filtered, and all anomalous regions are consistently re-annotated with bounding boxes and text labels—enabling precise evaluation of region-level localization rather than relying on mask-based or coarse location descriptors.
Text generation for training and evaluation is automated using a high-capacity MLLM (Qwen2.5-VL-72B), instructed to generate detailed, structured, reasoning-based descriptions of the anomaly detection process, given a pair of (reference, input) images. The reference sample is spatially aligned using a retrieval pipeline to mitigate intra-class spatial variance. Visual hints (red bounding boxes) and textual hints (explicit anomaly type and coordinates) are included during the generation phase to maximize accurate grounding of generated reasoning.
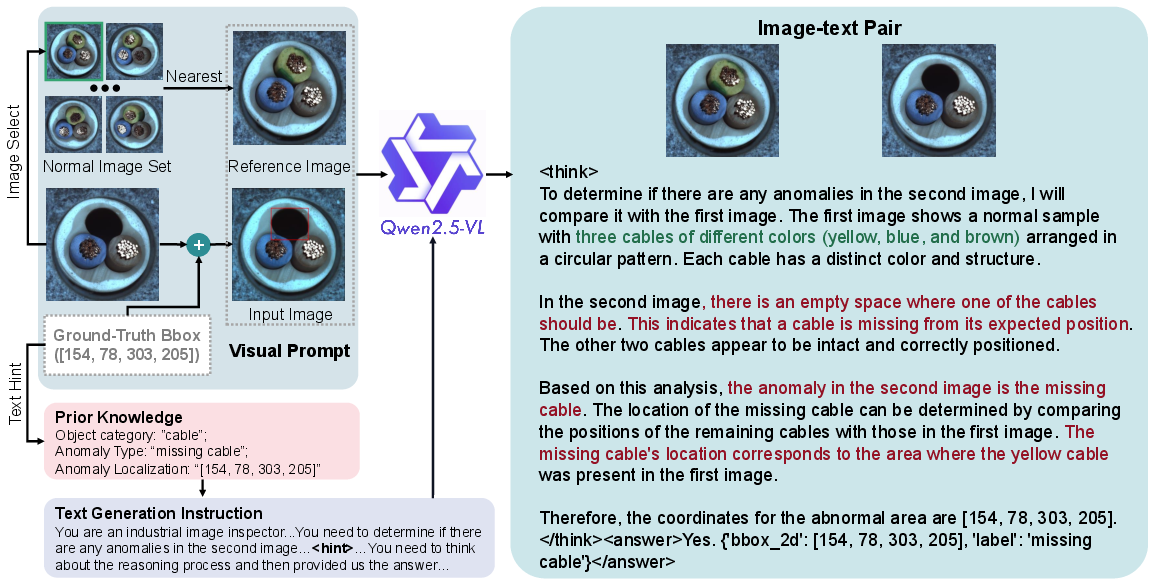
Figure 2: Automated text generation pipeline wherein Qwen2.5-VL-72B reasons about differences and localizes anomalies, assisted by visual and textual hints.
Each final annotation comprises a CoT "think" tag and an explicit answer, formatted for downstream models to learn step-by-step reasoning alongside final decision making. All outputs are quality-verified by comparing predicted anomaly regions and labels to ground-truth annotations, ensuring high consistency and semantic fidelity.

Figure 3: Comparison of MMR-AD with prior benchmarks; MMR-AD uniquely provides paired images, granular reasoning texts, and precise bounding boxes.
Compared to prior multimodal AD datasets (MMAD, Anomaly-Instruct-125K), MMR-AD is superior in diversity (more classes and anomaly types), scale (number of samples and regions), precision of annotation (fine-grained bounding boxes), and richness of textual data (CoT reasoning). The modularity of bounding box annotation allows improving or regenerating texts as stronger multimodal models emerge.
Baseline Model: Anomaly-R1
To establish a standardized strong baseline, Anomaly-R1 is proposed—initialized from Qwen2.5-VL-7B, refined with LoRA for parameter efficiency, and first cold-started using supervised fine-tuning with CoT-labeled MMR-AD data. Crucially, reinforcement learning, using the GRPO algorithm, further amplifies reasoning and anomaly localization performance. The RL stage leverages explicit reward functions considering both final decision accuracy and alignment of predicted and ground-truth bounding boxes, penalizing inconsistent localization (via IoU-based penalties).
Contrastive sampling is employed to maintain meaningful RL gradients: for each query, at least one positive and negative instance are guaranteed by manipulating hints and including gold-standard reasoning. Furthermore, domain knowledge is optionally injected as category-tailored lists of plausible anomaly types, strictly constraining the model's focus during reasoning.
Experimental Protocol and Results
The MMR-AD evaluation protocol holds out entire source datasets (e.g., MVTecAD, VisA, MVTec3D, MPDD) during training, forming non-overlapping train/test splits and thus rigorously benchmarking generalization. Metrics include sample-level accuracy, recall, and precision for both detection and localization (the latter with bounding box IoU ≥0.1).
Extensive benchmarking reveals:
- All evaluated commercial (GPT-5, Gemini-2.5-pro, OpenAI-o4-mini, Qwen-QVQ-Max) and open-source (Llama4-Maverick, Gemma3, InternVL3, Qwen2.5-VL-7B/72B) MLLMs underperform on industrial AD and localization, especially for region accuracy (often below 10%).
- Fine-tuning Qwen2.5-VL-7B on MMR-AD (Anomaly-R1) dramatically augments localization (from 8.9 to 66.3 on MVTecAD) and improves detection across all testbeds. Domain knowledge injection yields further gains.
- Compared to prior AD-specific models (PaDiM, PatchCore, HGAD, Dinomaly, INP-Former) that leverage full training data, MLLM-based baselines lag but demonstrate steady progress, validating the utility but also the challenge of domain generalization without exhaustive retraining.
(Figure 1, right panel)
Figure 1: Post-training on MMR-AD substantially increases both anomaly detection and anomaly localization, particularly for finely localized regions.
Ablations and Analysis
Ablation studies confirm:
- Explicit CoT reasoning is essential for generalization; omitting the "think" phase conspicuously degrades both detection and localization metrics.
- Reference images—serving as normal templates—significantly enhance the ability to discern anomalies versus direct, unpaired prediction.
- RL (post fine-tuning) is critical; applying RL on top of cold-started CoT reasoning maximizes localization fidelity and convergence.
- Domain knowledge, even when injected as static text, directly improves class-disambiguated anomaly recognition and reduces spurious detections.
- Contrastive sampling for RL training increases stability and convergence by preventing trivial or degenerate advantage estimation.

Figure 4: Qualitative comparison indicates that generalist MLLMs hallucinate or miss anomalies, while Anomaly-R1 demonstrates accurate reasoning and localization.
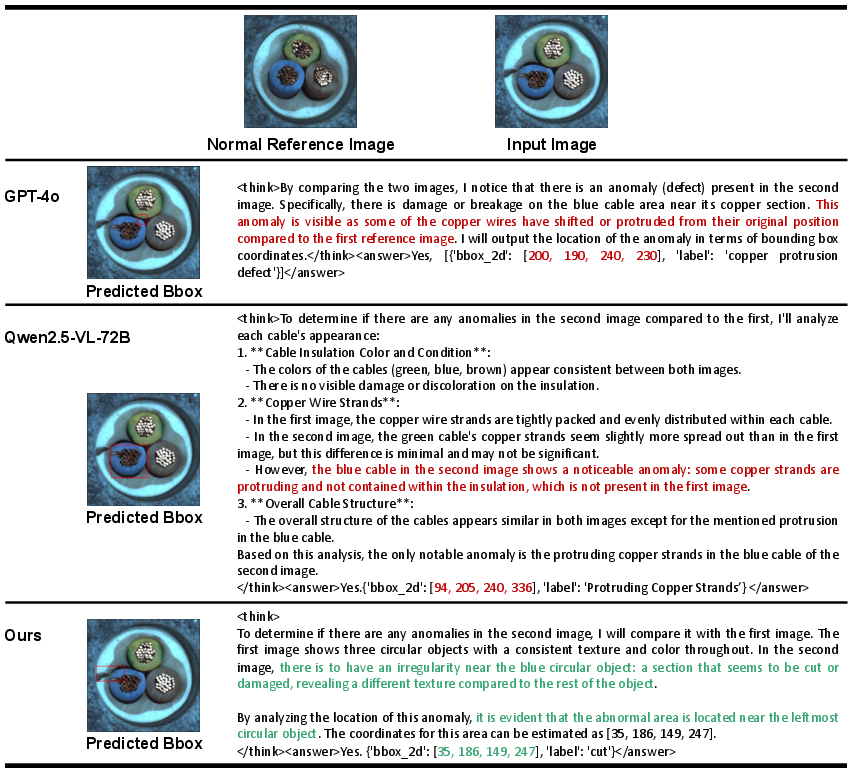
Figure 5: Failure case demonstrating limitations in reasoning where localized bounding box is inaccurate.
Implications and Future Work
MMR-AD establishes an open, extensible foundation for benchmarking and developing GAD models in industrial vision. The strong gap between commercial MLLMs and Anomaly-R1 after post-training emphasizes that even advanced generalist MLLMs require considerable domain adaptation for high-precision, localized anomaly detection. Methodologically, the combination of automated reasoning data generation, reward-engineered RL, and domain knowledge constraints creates a reproducible protocol for other specialized AD applications.
Practically, the clear performance gains observed from domain-specific post-training on reasoning-augmented benchmarks further motivate dataset curation and RL-facilitated post-training for future multimodal AI systems. This protocol can generalize to other industry settings (e.g., medical imaging, autonomous inspection), with appropriate dataset and annotation adaptations.
Conclusion
MMR-AD significantly advances the industrial anomaly detection landscape by delivering a scale- and diversity-rich multimodal benchmark, a validated data generation pipeline, and robust baseline modeling protocols. Empirical evidence from extensive comparison and ablation studies unmistakably demonstrates the necessity of tailored datasets and domain-specific post-training for achieving GAD with MLLMs. These findings will strongly shape future research on MLLM adaptation, data-driven RL post-training, and open benchmarking for anomaly detection tasks.