- The paper introduces a novel framework that integrates multimodal sensors with a language-guided two-hop grounding mechanism for precise anomaly localization.
- It employs frozen encoders, lightweight adapters, and slot attention to fuse 2D/3D data and generate interpretable, region-specific diagnostic reports.
- The model leverages executable-rule reward optimization to enforce protocol-aligned reporting, achieving state-of-the-art detection and schema adherence.
ZSG-IAD: A Multimodal Framework for Zero-Shot Grounded Industrial Anomaly Detection
Introduction
Industrial anomaly detection (IAD) systems demand precise localization and transparent attribution of defects to ensure operational reliability and accountability. Conventional deep-learning IAD models provide limited interpretability, often outputting only image-wide scores or heatmaps, which are insufficient for tasks necessitating region-level reasoning and protocol-aligned reporting. The "ZSG-IAD: A Multimodal Framework for Zero-Shot Grounded Industrial Anomaly Detection" (2604.17949) presents a comprehensive framework to bridge these gaps, integrating robust multimodal feature extraction, protocol-compliant language-based reasoning, and physically coherent region grounding, all under zero-shot generalization constraints.
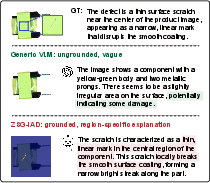
Figure 1: From vague anomaly descriptions (generic VLM, GPT-4o) to grounded, region-specific reports (ZSG-IAD) on a scratched industrial part.
Methodology and System Architecture
ZSG-IAD implements a scalable, modular architecture (Figure 2), utilizing frozen 2D/3D encoders (RGB, sensor, point cloud) augmented by lightweight adapters and dedicated multimodal fusion. Cross-modal feature interactions are enhanced via Channel-Spatial Swapping (CSS) and a bidirectional cross-attention (BCA) layer, enabling robust alignment between geometry, appearance, and sensor-derived features. The slot attention module distills evidence-like latent tokens critical for structured anomaly reporting.
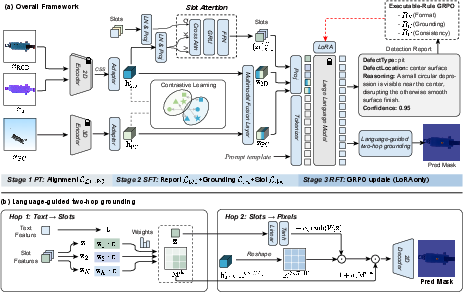
Figure 2: Overview of ZSG-IAD: frozen 2D/3D encoders with lightweight adapters, multimodal fusion, slot-based evidence tokens for structured reporting, and language-guided two-hop grounding with Executable-Rule GRPO.
A causal LLM, guided via LoRA adapters, executes structured report synthesis, drawing directly on fused vision-language evidence, and outputs standardized diagnostic fields (<DefectType>, <DefectLocation>, <Reasoning>, <Confidence>). The core technical innovation is the language-guided two-hop Text→Slots→Pixels grounding mechanism, which explicitly aligns textual claims to spatial evidence through a coarse-to-fine slot-based attention mechanism, yielding physically meaningful pixel-level masks.

Figure 3: Qualitative visualization of language-guided two-hop grounding—showing RGB input, top slot attention maps, aggregated coarse map, final prediction, and ground-truth mask.
Language-Guided Two-Hop Grounding
The two-hop grounding module operates by first mapping report-decoder text embeddings to relevant latent slot tokens (Hop-1), aggregating their spatial supports into a coarse evidence map. In Hop-2, the slot features and coarse map condition a lightweight segmentation decoder via channel-spatial gating, generating fine-grained region masks. This separation ensures that grounding is both interpretable—enabling traceability from decision rationale to local evidence—and actionable for industrial workflow integration.
Qualitative samples emphasize how ZSG-IAD’s pipeline not only links textual rationales to ROI but also corrects for confounding features or background clutter (Figure 4).

Figure 4: Qualitative examples of multimodal grounded reporting, from raw RGB/sensor/point cloud through predicted and ground-truth masks, highlighting report–mask consistency.
Protocol Alignment via Executable-Rule GRPO
Standard supervised fine-tuning often fails to enforce domain-specified report schema or ensure logical consistency between language rationales and visual localization. ZSG-IAD addresses this with Executable-Rule Group-Relative Policy Optimization (GRPO) under RL-with-Verifiable-Rewards (RLVR). The system is reinforced with rewards that are (i) schema-aware (all required fields parsable), (ii) spatially consistent (coarse map aligns with mask), and (iii) logically entailed (<Reasoning> supports <DefectType> via NLI). Only LoRA adapters are updated, ensuring stability and computational efficiency.
Experimental Evaluation
ZSG-IAD is evaluated across multiple tightly controlled industrial anomaly detection datasets, including standard zero-shot AD benchmarks and the custom-built MM-IAD-ReportBench. The framework unifies detection accuracy, localization fidelity, grounded reporting, and faithfulness metrics.
Quantitatively, ZSG-IAD (all modalities) achieves state-of-the-art on all primary metrics: accuracy (82.4%), F1-score (87.8%), pixel AUROC (97.6%), Dice (77.6%), structured schema adherence (99.6%), and logical consistency (NLI 93.8%). Significant ablation results confirm that slot tokens and the two-hop grounding head are indispensable for alignment and faithfulness, and each component of the executable reward regime (schema, grounding, consistency) contributes distinctly to overall system reliability.
Zero-shot transfer is robust: even with strict train-test separation (cross-dataset/category), ZSG-IAD maintains strong detection and schema-valid reporting, outperforming both generalist VLMs—which are vague, ungrounded, and not protocol-aligned—and classical anomaly baselines, which lack region-to-rationale traceability.
Implications and Future Directions
ZSG-IAD offers a paradigm shift for trustworthy industrial AI by coupling multi-sensor perception with report-level protocolization and spatial grounding, suitable for auditing, root-cause analysis, and closed-loop rework pipelines. Its explicit evidence tracing, high schema-validity rates, and logical self-consistency distinguish it from conventional "black box" IAD systems and from generic multimodal LLMs optimized solely for free-form generation.
On the theoretical front, this work demonstrates the synergistic benefits of combining slot-based scene decomposition, modular language-vision adapters, and reinforcement alignment via verifiable industrial protocols. Notably, reinforcement with automatic executable rewards obviates dependency on RLHF or human preference data, reducing annotation overhead and improving system reliability.
Future research avenues include extending ZSG-IAD’s two-hop grounding to full 3D localization, refining reward functions for more nuanced protocol enforcement (e.g., causal traceability, anomaly recurrence tracking), and integrating with real-world digital twin or Industry 4.0 platforms.
Conclusion
ZSG-IAD establishes a robust, extensible foundation for zero-shot grounded industrial anomaly detection, leveraging multimodal sensor fusion, slot-based evidence selection, structured reporting, and executable-rule reinforcement. It sets a high bar for transparency, protocol adherence, and actionability in industrial inspection AI, encouraging further work on interpretable, auditable, and reliable intelligent manufacturing systems.