- The paper presents a two-pronged CoCoReviewBench framework that enhances reference completeness and correctness using a detailed 23-dimensional taxonomy.
- It employs category-level scoring, multi-party adjudication, and LLM-assisted annotation, achieving high reliability with 85.45% category assignment and robust error resolution.
- Empirical insights reveal that reasoning-enabled AI models outperform traditional methods in correctness and grounding, though challenges in coverage and hallucination persist.
CoCoReviewBench: Rigorous Completeness and Correctness Benchmarking for AI Reviewers
Motivation: Limitations of Human Peer Reviews as Evaluation References
The deployment of LLM-based AI reviewers for academic peer review introduces the need for rigorous, fine-grained evaluation protocols. However, existing approaches are fundamentally limited by their reliance on human-written reference reviews, which exhibit severe incompleteness and correctness issues. Single reviewers routinely address only a subset of evaluation criteria, and substantial inter-reviewer and reviewer-author conflicts remain unaddressed. Systematic analysis over 3,900 papers confirms that peer reviews as currently used cannot serve as effective gold references, as they both lack coverage across essential categories and contain a substantial fraction of erroneous judgments.
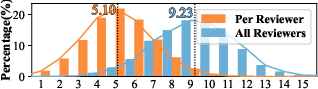
Figure 1: Distribution of subcategory coverage among human reviewers, confirming that most reviewer reports address only a sparse selection of evaluation dimensions.

Figure 2: Typical cases of inconsistency between reviewer judgments and between reviewers and authors, resolved only via subsequent meta-review.
The CoCoReviewBench Framework: Benchmark Construction and Validation
CoCoReviewBench directly addresses these deficits by introducing a two-pronged methodology: (1) maximizing reference completeness through explicit category-level construction and aggregation, and (2) enhancing correctness by filtering or adjudicating errors using multi-party discourse traces and meta-reviews.
The benchmark construction pipeline parses every review into atomic opinions, classifies each into a rigorous 23-dimensional taxonomy, and tracks discussion clusters across reviewers and authors. Disagreements are resolved using meta-review judgment to designate the reference, and redundant or incorrect opinions are excluded. This structured, overlap-aware annotation pipeline is partially accelerated by a distilled 8B LLM, ensuring scalability and reproducibility.
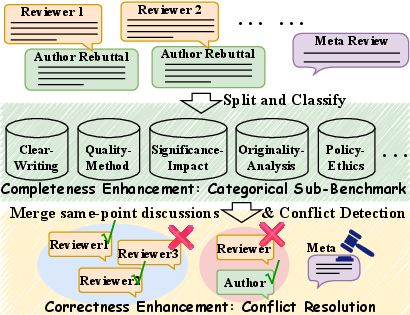
Figure 3: High-level overview of the CoCoReviewBench workflow, illustrating completeness-aware category subsetting and correctness adjudication via discussion and meta-review trace.
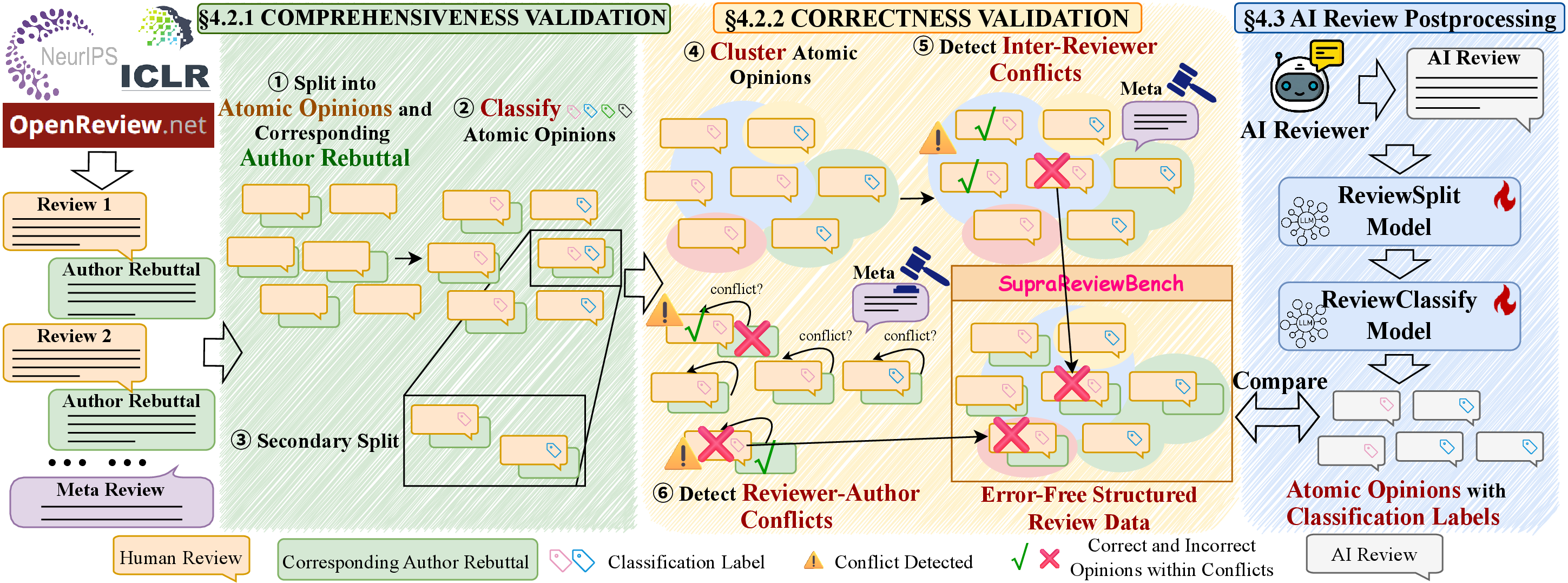
Figure 4: Detailed workflow for reference construction and classification, with multiple agentic steps implementing segmentation, labeling, conflict detection, and adjudication.
Robustness is demonstrated by step-level leave-one-out validation using six strong LLMs and further corroborated by human annotation: 85.45% category assignment, 93.41% opinion aggregation, and 81.4%/66.8% correctness scores for inter-reviewer and reviewer-author conflicts, respectively, indicating strong process reliability except for the most ambiguous rejected cases.
Evaluation Protocol: Category-Level Metrics for AI Reviewers
Unlike surface-level lexical overlap metrics (BLEU, ROUGE-L, BERTScore), CoCoReviewBench adopts direct category-level scoring. LLM-as-a-judge protocols explicitly evaluate atomic AI comments against curated references in each category using a 1–5 scale over dimensions such as correctness, thoroughness, grounding, verifiability, and clarity. Only evaluation for categories with reference comments is performed, neutralizing incompleteness bias. Paper-level completeness is computed as the fraction of categories addressed per model relative to union coverage by all human reviewers.
Empirical Insights and Numerical Findings
Experiments across general-purpose and specialized LLMs yield several core findings:
- Old metrics (BLEU/ROUGE/BERTScore) are misaligned with actual correctness: Non-reasoning models trained on human references outperform even GPT-5-family models, underscoring that these metrics reward semantic overlap rather than substantive review quality.
- AI reviewers currently underperform on correctness and thoroughness for most categories, with reasoning-enabled models (e.g., GPT-5.2, Qwen3-32B, DeepReviewer) providing stronger grounding and verifiability, consistently matching or exceeding humans in those axes.
- Completeness remains limited: The best AI reviews cover more categories than a single reviewer but do not reach the aggregate coverage of all reviewers for a paper; their within-category thoroughness does not match aggregated human references.
- Meta-review analysis confirms that, while not a perfect fine-grained oracle, meta-reviews are a reliable high-level adjudication signal in high-conflict scenarios.
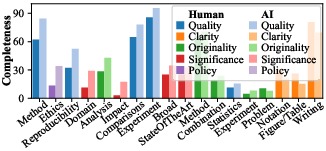

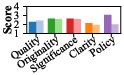
Figure 5: Category-wise breakdown showing AI reviewer coverage, correctness, and thoroughness, with AI reviewers more aggressive in coverage but lagging in Policy and Clarity.
Error Diagnostics and Hallucination Analysis
Despite broad coverage by the top models, the analysis reveals:
- Consistent deficits in non-Quality categories (e.g., Policy, Clarity).
- Hallucination risk in figure-related categories even when only text is provided, illustrating the tendency of LLM-based reviewers to produce unfounded comments beyond the input context.
- Instances where inclusion of erroneous human opinions in AI reviewer training can propagate hallucinations, as supported by a substantial closing of the correctness gap when treating incorrect opinions as reference.
Implications and Forward Directions
The strong empirical evidence presented in CoCoReviewBench demonstrates that direct use of human peer reviews as gold references is deeply flawed due to systematic incompleteness and frequent errors, even when aggregating multiple reviewers. The proposed category-level, adjudication-informed protocol presents a more robust standard for evaluating AI reviewers. These findings have both immediate and long-term consequences:
- For training, current supervised setups risk imprinting human incompleteness and inconsistency, weakening the reliability of LLM reviewers in new domains or task criteria.
- For evaluation, the CoCoReviewBench methodology should become standard in benchmarking, facilitating fairer and more actionable insights into the true capabilities and deficits of LLM-based reviewer models.
- Reasoning models should be prioritized for deployment in evaluator roles due to their empirical superiority in grounding and verifiability, though the fundamental issue of identifying major versus minor issues remains open.
- Further lines of work could extend multi-party meta-review adjudication and structured aggregation to additional peer evaluation workflows, explore active query augmentation for missing categories, and more deeply analyze the propagation of human biases and error patterns into AI review pipelines.
Conclusion
CoCoReviewBench establishes a new standard for completeness- and correctness-oriented benchmarking in the evaluation of AI reviewers (2605.07905). The methodology enables fine-grained, category-level diagnostics immune to human review sparsity, and leverages multi-party adjudication for reference correction. Major results identify reasoning-type models as currently strongest on most axes, with hallucination and coverage challenges still unsolved. The benchmark and framework present a path toward more informative evaluation and training of automated reviewing systems, as well as a template for principled benchmarking in other open-ended, multi-faceted language tasks.