- The paper presents a novel PF+BV framework that transforms natural language proofs into modular, verifiable components using block verification.
- It employs LLMs to independently check each proof segment, reducing context requirements and minimizing false positives.
- Empirical evaluations demonstrate that PF+BV achieves near 90% recall and superior error localization on both competition-level and research-level proofs.
Introduction and Motivation
The paper "Pseudo-Formalization for Automatic Proof Verification" (2605.20531) addresses the persistent challenge in AI-driven mathematics: automatic, reliable verification of mathematical proofs written in natural language, especially those by AI systems. While fully formal proofs in languages such as Lean or Isabelle admit mechanical verification due to their semantic precision and modular structure, the majority of proofs produced by humans or AI do not fit this mold, and translation into fully formal languages remains infeasible in many advanced mathematical contexts. The authors introduce Pseudo-Formalization (PF), a structured proof format retaining the modularity and precision necessary for verification, but with the flexibility of natural language. PF decomposes a proof into self-contained modules, each declaring its premises, conclusion, and proof. The Block Verification (BV) algorithm is applied, using LLMs to verify each module independently. This provides scalable oversight for mathematical argumentation and enables reliable proof verification beyond the domains accessible to current formal proof systems.
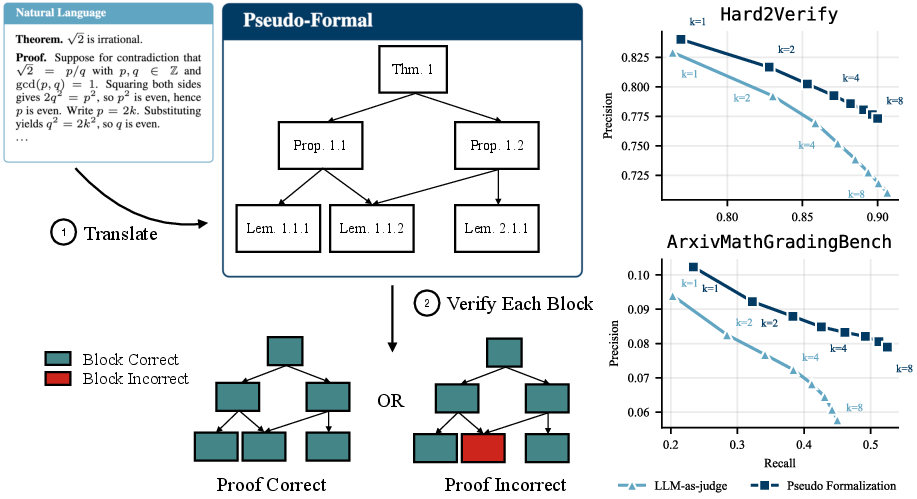
Figure 1: PF verification pipeline: translation from natural language proof to PF representation and block-wise verification, showing precision-recall deficit against LLM-as-judge baselines.
PF proofs are defined as sequences of modules (P,c,π), corresponding to premises, conclusion, and proof respectively, all in natural language. Proof structure is encoded via:
- A directed acyclic graph (DAG) G capturing invocation dependencies, i.e., which modules invoke others.
- A scope-inheritance forest T for hierarchical organization of premises and context.
This modular structure allows each block to be verified locally, leveraging minimal context and explicit premises. The theoretical analysis formalizes modularity benefits:
- The context required for block-wise verification of PF proofs is independent of proof length, i.e., O(L) where L bounds local block length, as opposed to O(n) context for whole-proof verification, where n is total proof length.
- The modularization enables verification in the short-context regime, mitigating context rot observed in LLMs when context exceeds their effective capacity.
The authors define "Good" PF proofs as those satisfying bounded scope depth and concise blocks; formally, depth(T)<D and ∣P∣,∣c∣,∣π∣<L for constants D,L independent of G0. The context-cost theorem demonstrates that a fixed-size transformer can simulate block-wise verification by aggregating G1 calls, each of size G2.
Figure 1: Diagram of PF block decomposition for proof verification.
PF+BV Pipeline and Verification Procedure
The pipeline for PF+BV proceeds in four stages:
- Translation: Natural language proofs are rewritten into PF format via LLMs, optionally employing a self-repair loop to patch discrepancies between the original proof and its pseudo-formalized version.
- Block Verification: Each module is independently checked for correctness by a verifier LLM, which accepts or flags errors, assuming children's correctness.
- Calibration: Error reports are aggregated by a calibrator LLM, parameterized by natural language strictness, to issue a final verdict—binary, numerical, or error-located.
- Parallel Aggregation: All prior steps are run in G3 parallel rollouts; pessimistic aggregation is employed for error recall maximization (proof passes only if all rollouts accept).
This modularity, together with pessimistic parallel scaling, allows performance tuning along the precision-recall axis, adapting to stricter or more permissive downstream requirements.
Experimental Evaluation
The authors conduct empirical evaluation on two benchmarks:
- Hard2Verify: Olympiad/Putnam-level proofs generated by frontier AIs, with step-level correctness labels.
- ArxivMathGradingBench: A new dataset of 35 research-level arXiv papers with known author-corrected errors, capturing realistic error localization scenarios.
Strong numerical results include:
- PF+BV achieves near-90% recall at step level on Hard2Verify, closely matching the baseline but demonstrating superior performance on longer, harder proofs in ArxivMathGradingBench.
- On ArxivMathGradingBench, PF+BV significantly outperforms the baseline on recall and error localization, raising fewer false alarms and covering a larger fraction of annotated errors per paper.
- PF+BV provides a Pareto-dominant precision-recall tradeoff relative to LLM-as-judge at all recall levels, and reduces mean number of false errors per proof by over 20% at G4.
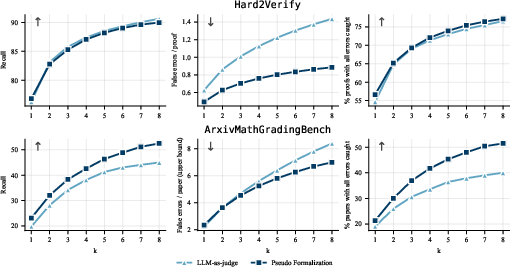
Figure 2: Left: Step-level recall as a function of number of parallel verification attempts (G5). PF+BV achieves higher recall and coverage, especially on longer proofs. Middle: Mean number of false errors per proof/paper. PF+BV flags fewer false errors. Right: Coverage of true errors per proof/paper.
The qualitative analysis demonstrates PF+BV's ability to localize errors. In the IMO 2024 P6 example, modularization isolates a logical misreading—strengthening "cannot contain both G6 and G7" to "all nonzero elements have same sign"—allowing the verifier to flag a non-trivial error missed by holistic approaches.
Related Works and Context
PF+BV advances several directions in automatic proof verification:
- Training legible outputs for verification via prover-verifier games, scalable oversight, and explicit modularization.
- Comparison with autoformalization pipelines, which translate natural-language proofs to fully formal languages for mechanized verification, but require complete formal libraries and incur high translation cost.
- Modular checking complements prior chunk-wise strategies (fixed-size chunk verification by LLMs) and tournament-style proof comparison.
The PF+BV framework is more broadly applicable in domains with modular argumentation beyond mathematics—for instance, empirical sciences or law—where arguments can be decomposed into explicit premises and conclusions.
Limitations and Future Work
Several limitations are acknowledged:
- Production of faithful PF rewrites is non-trivial; translation fidelity is empirically improved via self-repair, but does not guarantee correctness.
- Benchmark error labels are proxies for true error identification, potentially undercounting errors detected by PF+BV.
- PF+BV is currently restricted to mathematical proofs; extension to other domains requires adaptation of modularization and explicit premise-conclusion decomposition.
Future directions include training models to directly produce PF-format proofs, deeper integration with legibility-target architectures, and extension to additional scientific domains.
Conclusion
Pseudo-Formalization (PF) and Block Verification (BV) provide a rigorous, scalable framework for automatic verification of mathematical proofs in natural language, bridging the gap between formal and informal proof formats. The PF+BV pipeline enables modular, short-context verification that demonstrably outperforms strong baseline LLM-as-judge systems on both competition-level and research-level benchmarks, with reduced false positives and improved error localization. Its theoretical guarantees and empirical results establish PF+BV as a viable foundation for reliable proof verification in advanced mathematical reasoning, with practical implications for AI training, referee processes, and scalable evaluation of machine mathematics.

