- The paper demonstrates that state-of-the-art generative models misgeneralize physical quantities due to local model-induced trajectory errors.
- It introduces the data deviation kernel to predict and explain systematic drifts in physical quantity distributions across both synthetic and real-world systems.
- Kernel-informed data transformations effectively align generated outputs with intended physical constraints, guiding practical mitigation strategies.
Mechanisms of Misgeneralization in Physical Sequence Modeling
Introduction
"Mechanisms of Misgeneralization in Physical Sequence Modeling" (2605.20299) rigorously identifies, formalizes, and analyzes a significant failure mode—termed physical misgeneralization—in generative sequence modeling for physical domains. Despite the common engineering practice of curating demonstration datasets to shape the distribution of key physical quantities (e.g., travel distance, energy), the paper demonstrates that state-of-the-art marginal generative models, particularly diffusion-based sequence planners, frequently violate these distributional constraints post-training. This misalignment arises even when each individual generated trajectory appears physically plausible. The authors provide a mechanistic analysis, accompanied by synthetic and real-world empirical evidence, and propose mitigation strategies grounded in the developed theoretical framework.



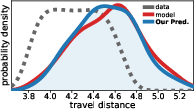

Figure 1: Illustration of the mechanism driving physical misgeneralization—local model-induced trajectory deviations propagate through physical measurement, causing drift in the induced physical quantity distribution.
Defining Physical Misgeneralization
The central phenomenon—physical misgeneralization—is situated within the context of generative sequence modeling in domains such as robotics, molecular dynamics, and motion planning. Here, model training is conducted using marginal objectives over trajectories, with dataset curation designed to shape the distribution over a specific physical variable r (e.g., travel distance or energy). The paper formally distinguishes (i) the latent distribution π(r) intended by the curated dataset, and (ii) the distribution πˉS(r) recovered by applying a measurement function m(r∣x) to generated trajectories.
Strikingly, trained models systematically drift from π(r): even if generation remains “on-distribution” for individual trajectories, the aggregate over samples fails to respect the intended physical constraint. This is quantified via total variation (TV) between πˉmodel(r) and π(r), and the paper introduces the notion of quantity drift as a formal measure.
Mechanistic Analysis: Data Deviation Kernel
The paper provides a predictive, architecture-informed account of physical misgeneralization. The core mechanism is that local model-induced errors—typical of the chosen model class (e.g., convolutional diffusion models)—are not evenly distributed with respect to the physical quantity of interest. These deviations, when propagated through the measurement function m(r∣x), induce a systematic redistribution of probability mass over r.
The authors operationalize this with the data deviation kernel Darchσ(δ∣x), describing how architectural biases disperse probability mass locally in trajectory space around each data point π(r)0. By explicitly modeling this perturbation structure (e.g., as Gaussian-weighted local recombination with data fragments), they predict the shifted distribution over π(r)1 post-generation—without reference to any specific trained model.
This approach is instantiated across several synthetic dynamical systems (sinusoidal, tent map, logistic map), as well as applied cases (double pendulum, Maze2D). Their analysis leverages the known sensitivity of each system (e.g., Lyapunov exponents for chaoticity) to trace how small, local deviations result in macroscopic drift in the induced measure over physical quantities.
Empirical Validation
Through comprehensive experiments, the agreement between predicted and observed drifts is systematically validated. In each synthetic system, the kernel-based prediction accurately forecasts which quantity values become over- or under-represented in model samples.
(Figure 2)
Figure 2: Comparison of intended, predicted, and actual induced distributions over the physical quantity for several benchmark systems; kernel-based predictions closely mirror empirical drift.
Key findings include:
- For near-linear or low-sensitivity systems (e.g., sinusoidal family), model-induced drift is negligible.
- In chaotic systems (tent/logistic maps), the drift is non-trivial, concentrated in modality-specific regions, and fully anticipated by kernel analysis.
- In physical simulation and navigation tasks (double pendulum energy, Maze2D path length), experimentally observed drifts (e.g., upwards shift in energy or path length) precisely match kernel-based predictions.
Statistical tests across multiple training seeds confirm the robustness and generality of the mechanistic interpretation.
Mitigation Strategies
The paper evaluates several families of interventions for combating physical misgeneralization:
- Dataset Reweighting: Stratified or importance reweighting of the training set according to the drifted quantity is largely ineffective. Model errors in trajectory space persist regardless of dataset balance due to the nature of the unsupervised marginal objective.
- Conditional Modeling / Guidance: Conditioning on the physical quantity at generation time (e.g., classifier-free guidance) is partially effective in controlled synthetic systems but fails to fully correct drift in settings with complex joint constraints (e.g., Maze2D with environment geometry).
- Kernel-Informed Data Representation: The strongest mitigation is derived from the mechanistic account—transforming the data representation so that local deviation neighborhoods align with desired quantity distributions. By encoding training data with codes such that local neighborhoods (as defined by the data deviation kernel) yield balanced distributions over π(r)2, the drift is substantially reduced without trading off sample quality or diversity.
(Figure 3)
Figure 3: Efficacy of various intervention strategies; kernel-informed data transformations (rightmost panel) yield the sharpest correction in induced quantity measures.
Theoretical and Practical Implications
This work has important implications for both the design and evaluation of generative models for physical systems:
- Theoretical: It establishes that misgeneralization along physical axes is an anticipated outcome of architectural biases and the geometry of physical measurement, not merely an empirical accident or an artifact of poor dataset curation. The data deviation kernel formalism unifies and mechanizes the analysis of such effects.
- Practical: Practitioners cannot assume that plausible, high-fidelity sample generation implies alignment with intended aggregate physical statistics. When safety, power usage, or fairness hinges on distributional guarantees, direct marginal modeling is insufficient. The kernel-based approach provides actionable tools for diagnosing and mitigating such failures.
Furthermore, the framework extends beyond physical systems. Preliminary results in text-to-speech demonstrate analogous prosody drift attributable to the same class of mechanisms, suggesting that aggregate under- or over-representation of salient attributes (e.g., protected or socially meaningful quantities) may be endemic to generative modeling more broadly.
Future Directions
The results motivate several open questions for the community:
- Defining data deviation kernels for other model classes (e.g., autoregressive transformers, VAEs) to enable predictive analysis and mitigation in these settings.
- Extending kernel analysis to composed pipelines (e.g., multi-stage TTS), where errors can accumulate across stages.
- Leveraging kernel-informed architectures or objective formulations to directly penalize anticipated drifts, possibly by integrating distributional constraints beyond trajectory-level supervision.
Conclusion
This work presents a systematic theory and empirical corroboration of physical misgeneralization in marginal sequence modeling. By articulating, validating, and operationalizing the mechanism via the data deviation kernel, it equips both theoreticians and practitioners with predictive and mitigative tools to ensure alignment of generative models with intended physical specifications. The implications resonate through safety-critical, scientifically-informed, and fairness-sensitive deployment scenarios in AI and robotics.