- The paper presents TIDE, a novel I/O-aware expert offloading strategy that exploits temporal stability in MoE dLLMs to reduce redundant migrations.
- TIDE’s interval-based refresh mechanism balances migration cost and CPU delays, achieving up to 1.5x throughput gains over baseline systems.
- The approach enables efficient, lossless inference for 100B+ parameter models on limited hardware without compromising output quality.
TIDE: Efficient and Lossless Mixture-of-Experts dLLM Inference via I/O-Aware Expert Offloading
Introduction
Diffusion LLMs (dLLMs) are increasingly relevant due to their intrinsic parallelism and bidirectional context, which support high-throughput, block-level text generation. Scaling these models with Mixture-of-Experts (MoE) architectures enables parameter counts in the 100B+ range while maintaining computational efficiency. Yet, as the parameter count increases, efficient inference in memory- and bandwidth-constrained environments (e.g., a single GPU-CPU system) presents severe bottlenecks: excessive expert offloading triggers overwhelming interconnect I/O, while naive CPU rerouting induces pronounced compute stalls. The "TIDE: Efficient and Lossless MoE Diffusion LLM Inference with I/O-aware Expert Offload" paper (2605.20179) introduces a policy for lossless expert scheduling, specifically exploiting the temporal stability of expert activations in the denoising process to maximize throughput under tight resource constraints.
MoE dLLMs activate a large set of experts at every denoising step, owing to their block-level parallel decoding—contrasting with autoregressive (AR) models that incrementally compute token-by-token. In resource-bound settings where not all expert weights fit in GPU memory, two approaches arise: static rerouting of tokens to CPU (causing CPU-bound bottlenecks), or step-wise expert swapping between GPU and CPU (causing massive I/O volumes as the expert footprint per step is broad and fragmented).
Critically, the aggregate cost is governed by the GPU expert hit rate, the frequency and volume of offloads, as well as the execution/transfer imbalance between devices. Efficient scheduling thus demands joint minimization of migration-induced I/O overhead and CPU compute delays, subject to the constraint of lossless inference.
Key Observation: Temporal Locality in Expert Activations
Through granular empirical analysis, TIDE establishes that expert activation patterns in dLLM blocks are highly temporally correlated: at the block level, consecutive denoising steps activate largely overlapping sets of experts, with adjacent steps displaying mean cosine similarities of 0.985. Even steps separated by up to five denoising iterations sustain a similarity above 0.95, revealing strong temporal locality (Figure 1a).
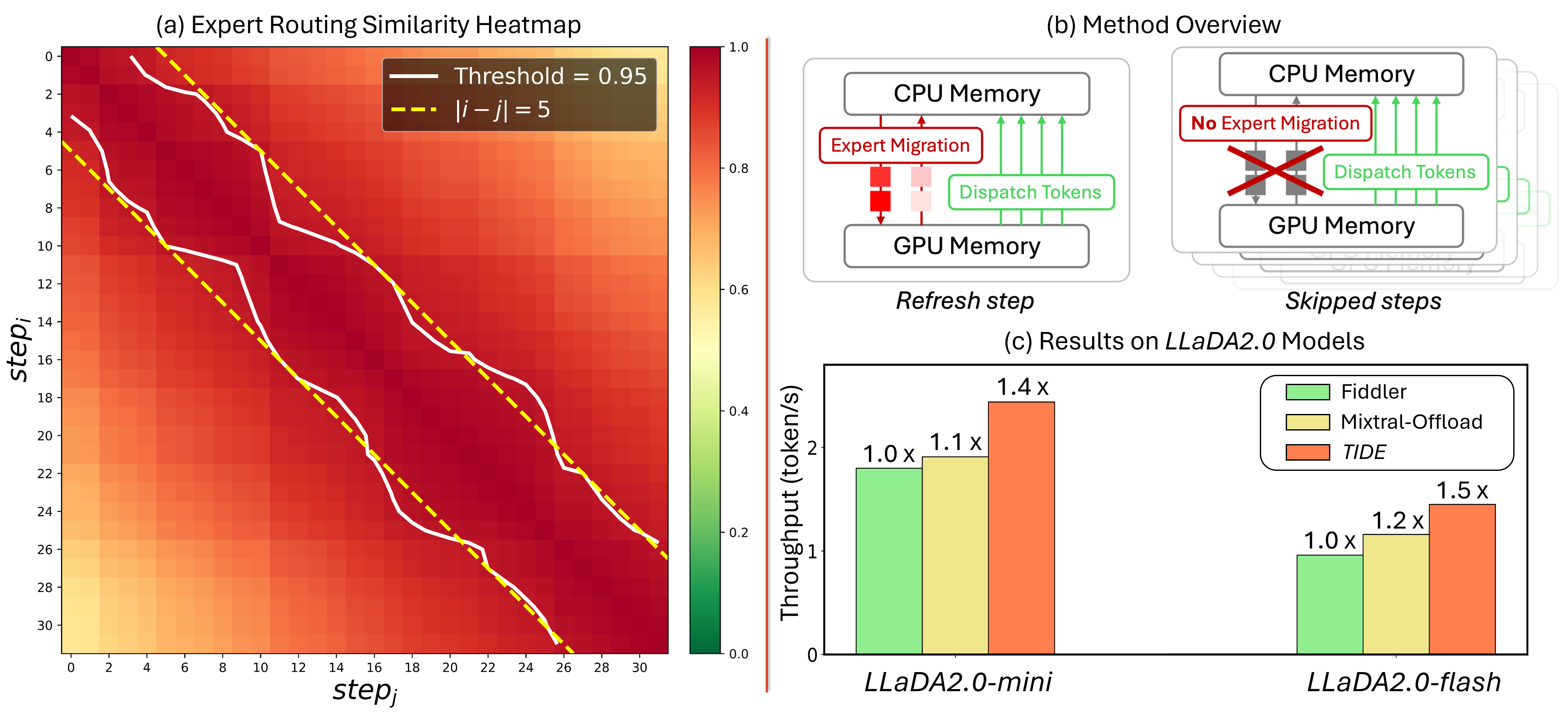
Figure 1: (a) Expert routing similarity across denoising steps; (b) system-level TIDE scheduling strategy; (c) throughput comparison to baseline MoE inference systems.
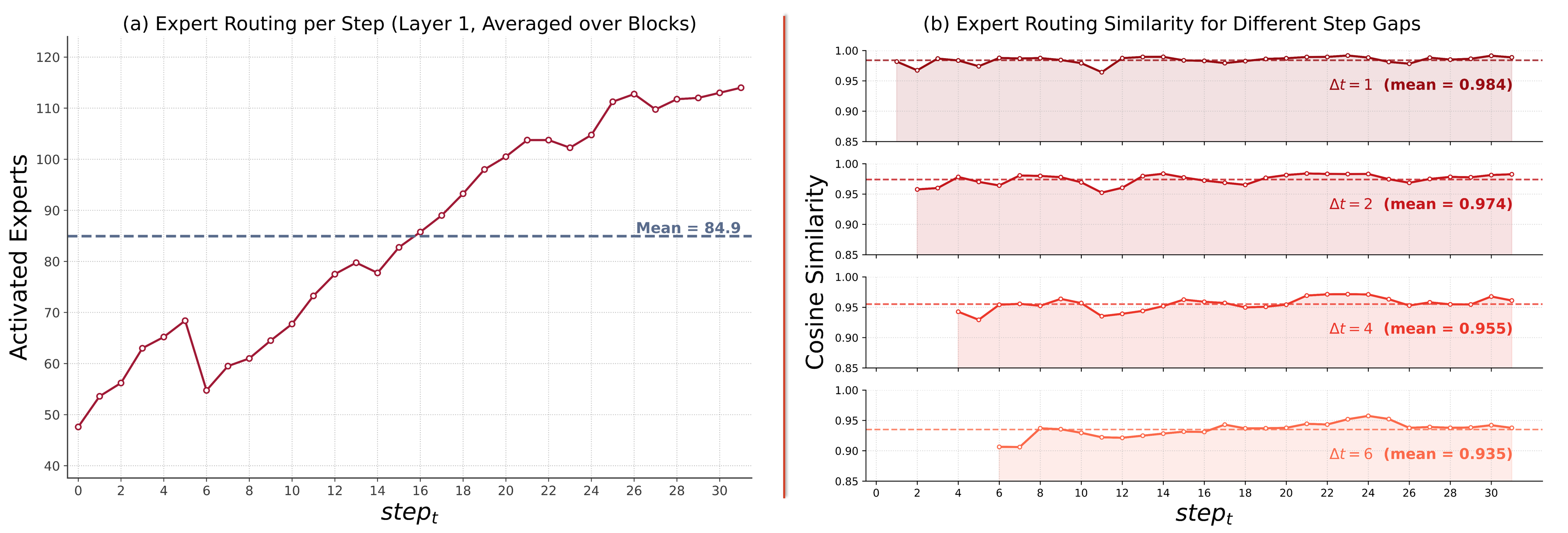
Figure 2: (a) Unique experts activated per denoising step, (b) similarity decay across intervals within a block.
These findings indicate that expert selection is quasi-static within short block intervals, enabling amortized migration and placement decisions. Concretely, scheduling may be batched across intervals rather than per-step, exploiting predictability in routing, thereby reducing redundant I/O and maximizing compute locality.
TIDE System: Interval-Based, I/O-Optimized Expert Scheduling
TIDE introduces an interval-oriented refresh strategy. Rather than migrating experts or routing tokens at every step, TIDE divides block-wise denoising into refresh steps (where expert placement is updated) and skipped steps (where the prior mapping is retained). At a refresh step, those experts with the highest cumulative token activations (“high demand”) are migrated to GPU, up to the memory budget. All remaining tokens are either executed on resident GPU experts or asynchronously offloaded to CPU without GPU stalling (Figure 3).
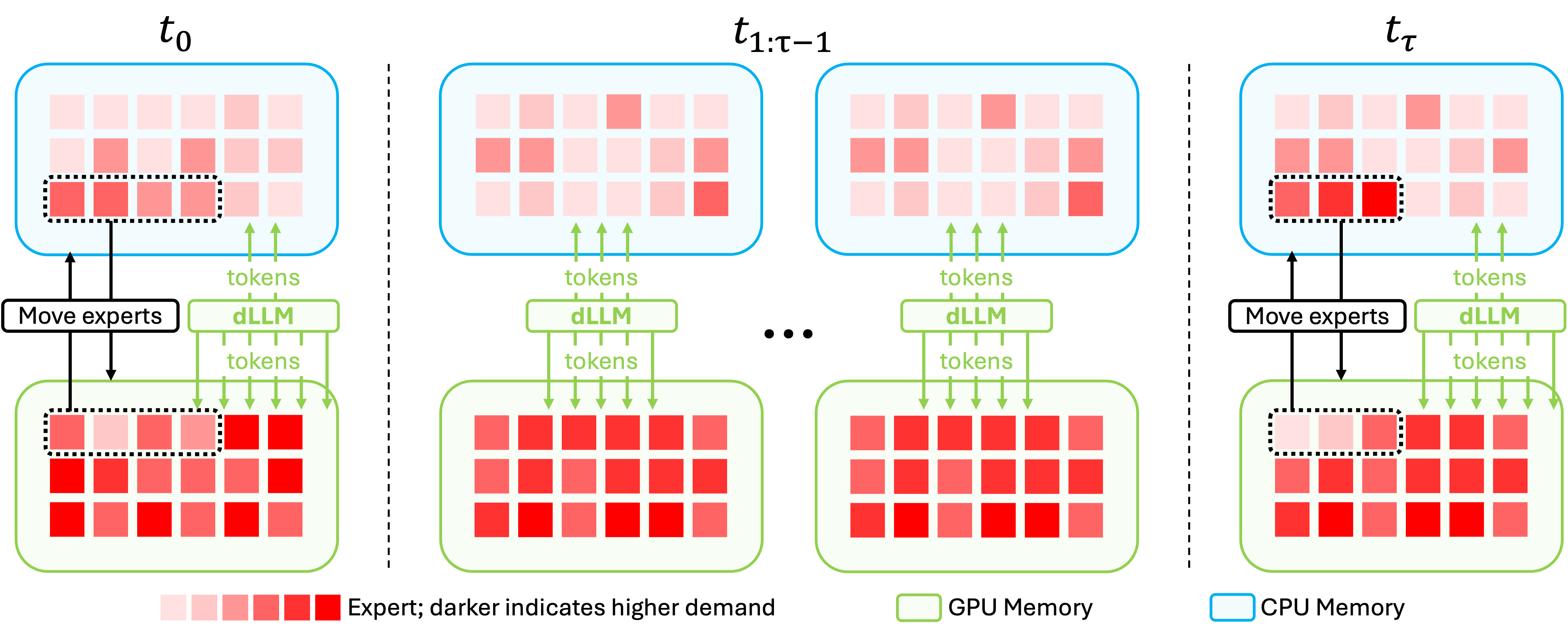
Figure 3: TIDE’s execution pipeline. Refresh steps update GPU experts, skipped steps reuse the previous mapping and avoid migrations.
The critical system parameter is the refresh interval τ—the number of denoising steps between expert set updates. TIDE analytically models the trade-off between the migration cost (which decreases with larger τ) and CPU compute cost due to missed GPU experts (which increases with larger τ). The optimal τ is found by minimizing the composite latency function combining both, leveraging offline profiling for hardware and execution parameterization.
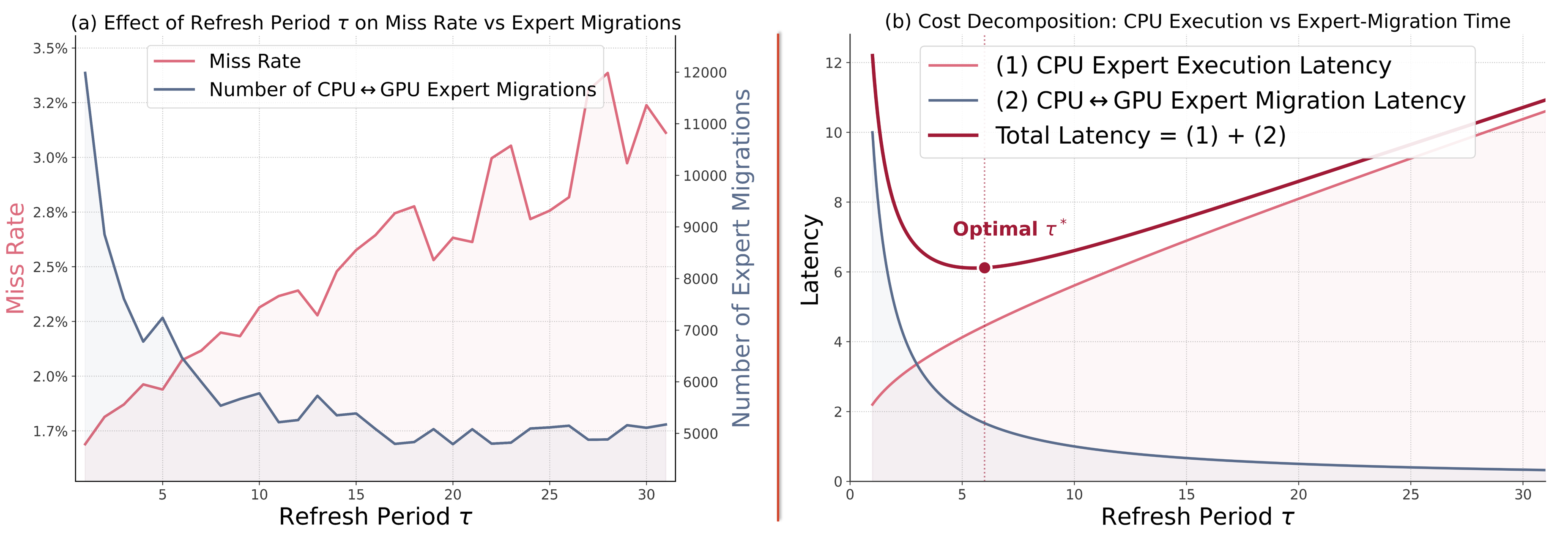
Figure 4: (a) GPU expert miss rate and migration count vs. refresh interval τ. (b) Migration/I/O and CPU latency trade-off as a function of τ.
Experimental Results
Evaluations on LLaDA2.0-mini (16BA1B) and LLaDA2.0-flash (100BA6B) models on single NVIDIA A100/H100 nodes exhibit the throughput benefits of TIDE. The method achieves up to 1.4× improvement over Mixtral-Offload [fastio] and 1.5× over Fiddler [fiddler], both of which are the state-of-the-art baselines in the MoE-AR and offloading spaces.
Numerically, TIDE consistently improves decoded tokens per second under various conditions: different block sizes, GPU memory budgets, and confidence thresholds (Figure 5). Particularly, TIDE’s gains are most pronounced under stringent GPU memory, precisely where naive strategies saturate I/O and degrade throughput.
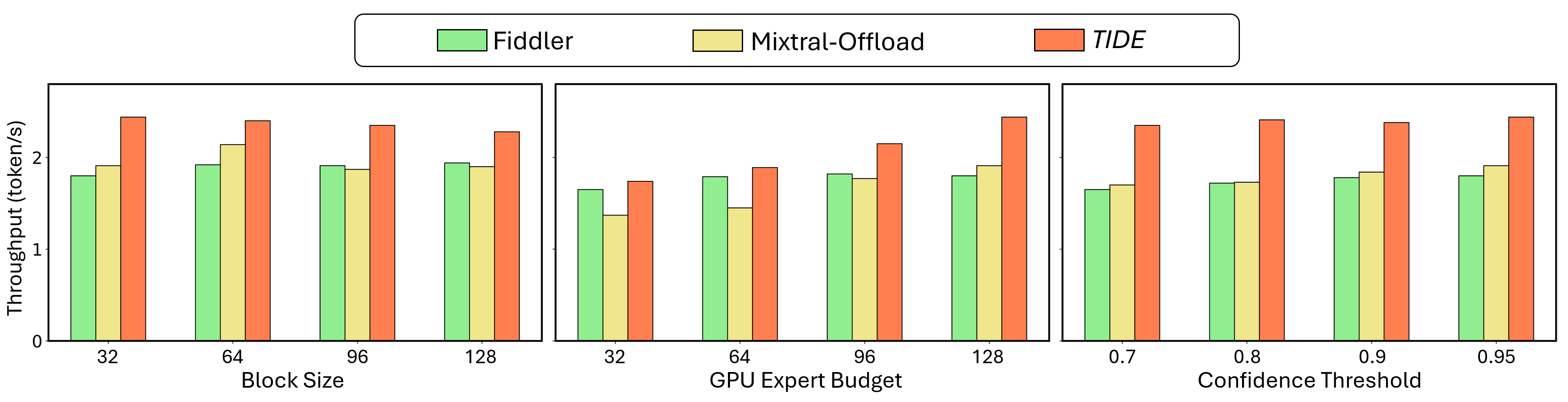
Figure 5: TIDE outperforms baseline approaches across block sizes, GPU expert budgets, and confidence thresholds on LLaDA2.0-mini.
These speedups are entirely lossless regarding model outputs, as TIDE does not alter routing policy, expert selection, or underlying model parameters—it is a purely systems-level, inference-time optimization.
Theoretical and Practical Implications
TIDE substantiates that in dLLM-MoE inference, expert activation regularities (temporal stability) present substantial untapped accelerative potential. The analytical modeling and interval optimization framework generalized here are applicable across diffusion-based MoE architectures adopting parallel, block-wise decoding.
Practically, the method supports efficient deployment of 100B+ parameter models on commodity and edge systems, offering substantial throughput improvement while respecting real-time and energy constraints. The approach is compatible with standard PyTorch and HuggingFace Transformer implementations and can be integrated into serving and scheduling frameworks such as SGLang and vLLM.
Theoretically, TIDE’s approach highlights that cross-step similarity in activation patterns—a property deeply rooted in the stochastic, iterative denoising regime of diffusion models—translates directly into systems optimization levers. Future extensions may further exploit inter-block similarity, address scheduling in distributed multi-GPU/multi-node contexts, and target broader hardware diversity beyond NVIDIA GPUs.
Conclusion
TIDE presents a rigorously engineered, lossless, and resource-optimized inference policy for MoE-based diffusion LLMs, leveraging the cross-step temporal locality of expert routing to minimize redundant expert migrations and maximize GPU utilization. Real-world benchmarks demonstrate up to 1.5× throughput gains under resource constraints, without any impact on model output. These insights provide a foundation for continued scaling of diffusion LLMs to production workloads, with broad implications for efficient and practical AI deployment on limited hardware.

