ThoughtTrace: Understanding User Thoughts in Real-World LLM Interactions
Abstract: Conversational AI has now reached billions of users, yet existing datasets capture only what people say, not what they think. We introduce ThoughtTrace, the first large-scale dataset that pairs real-world multi-turn human--AI conversations with users' self-reported thoughts: their reasons for sending prompts and reactions to assistant responses. ThoughtTrace comprises 1,058 users, 2,155 conversations, 17,058 turns, and 10,174 thought annotations collected across 20 LLMs. Our analysis shows that ThoughtTrace captures long-horizon, topically diverse interactions, and that thoughts are semantically distinct from messages, difficult for frontier LLMs to infer from context, diverse in content, and tied to conversation stages. We further demonstrate the utility of thoughts for downstream modeling. First, thoughts improve user-behavior prediction as inference-time context. Second, thought-guided rewrites provide fine-grained alignment signals for training personalized assistants. Together, ThoughtTrace establishes user thoughts as a new data modality for studying the cognitive dynamics behind human--AI interaction and provides a foundation for building assistants that better understand and adapt to users' latent goals, preferences, and needs.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
ThoughtTrace: A simple explanation for teens
What this paper is about (brief overview)
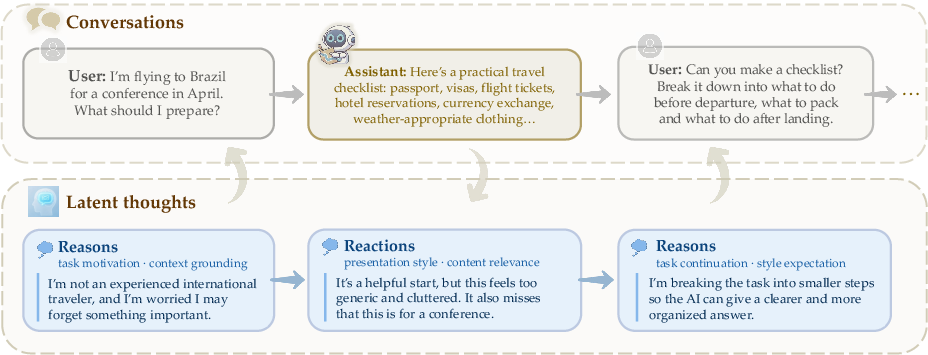
This paper introduces ThoughtTrace, a new dataset that doesn’t just record what people say to chatbots, but also what they’re thinking while they chat. Imagine speech bubbles from a comic: you see the words characters say, but you also see their “thought bubbles.” ThoughtTrace pairs real chat messages with those “thought bubbles” (private reasons and reactions) to help build AI assistants that better understand what people really want.
What the researchers wanted to find out (key questions)
The authors explore a few big questions:
- Can we collect people’s “thought bubbles” during real chats with AI at a large scale?
- Are these thoughts really different from the messages people type?
- Can today’s top AI models guess those thoughts just from the conversation?
- Do people’s thoughts change as a conversation moves from the first message to later ones?
- Do thoughts actually help: (a) predict what a user will say next and (b) train assistants to respond better?
How they did it (methods in everyday language)
The team built a chat website and asked over 1,000 volunteers to:
- Do two real tasks (like planning a trip or drafting an email) by chatting with an AI assistant for up to 10 minutes per task.
- After each AI reply, privately write how they felt about it (their reaction).
- Before each user message, privately write why they were sending it (their reason).
Important details:
- People chatted with one of 20 different AI models (they didn’t know which).
- The “thoughts” were never shown to the AI during the chat; they were private notes for research.
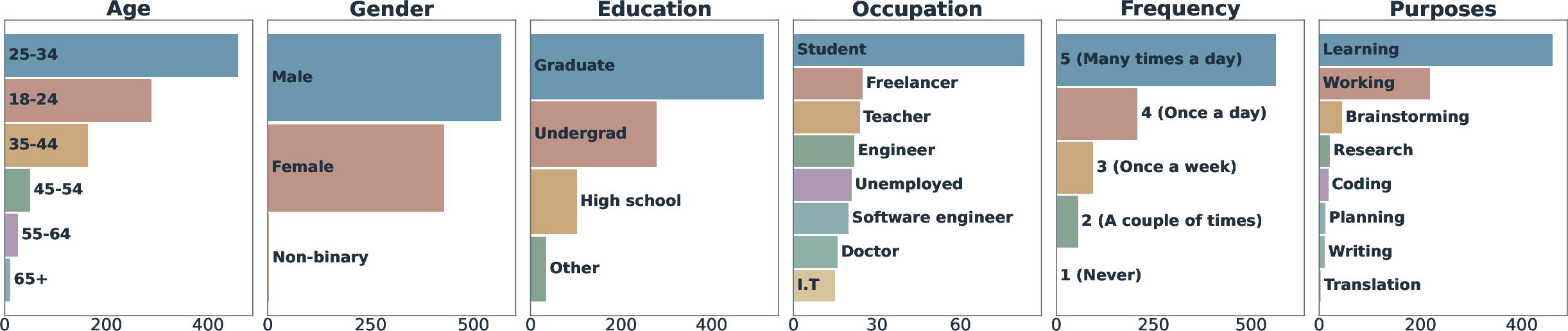
- The dataset includes 2,155 conversations, 17,058 back-and-forth turns, and 10,174 thought notes, plus basic demographics (age, education, occupation).
How they analyzed the data:
- “Semantic embeddings”: Think of placing every text (a message or a thought) as a point on a map where distance shows how similar the meanings are. If thoughts land far from the messages, they’re adding new information.
- “LLM-as-judge”: They asked strong AIs to act like referees, comparing two pieces of text (for example, a guessed thought vs. the real thought) and scoring how similar they are.
- Utility tests:
- Next-message prediction: Does giving a model the user’s private thoughts help it guess what the user will type next?
- Alignment training: They took AI answers that users didn’t like, used the users’ thoughts to rewrite those answers, and then taught a smaller model to prefer those improved answers. Later, they tested if people prefer the improved model’s outputs.
What they found (main results and why they matter)
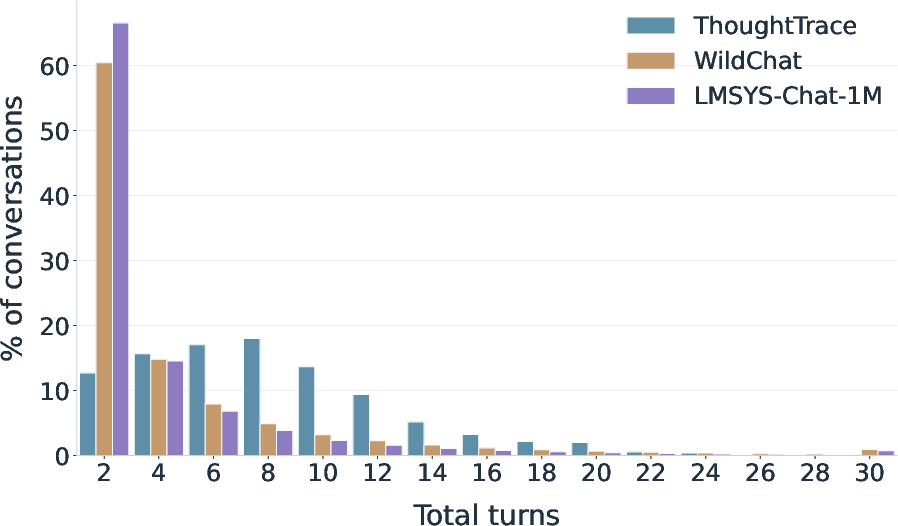
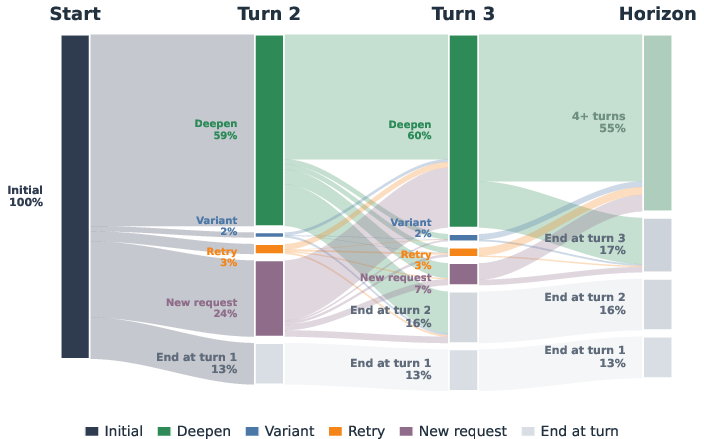
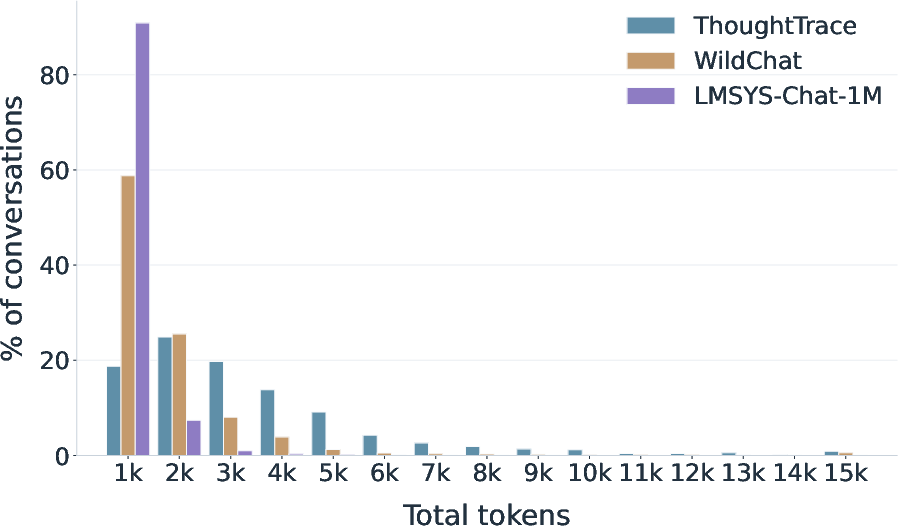
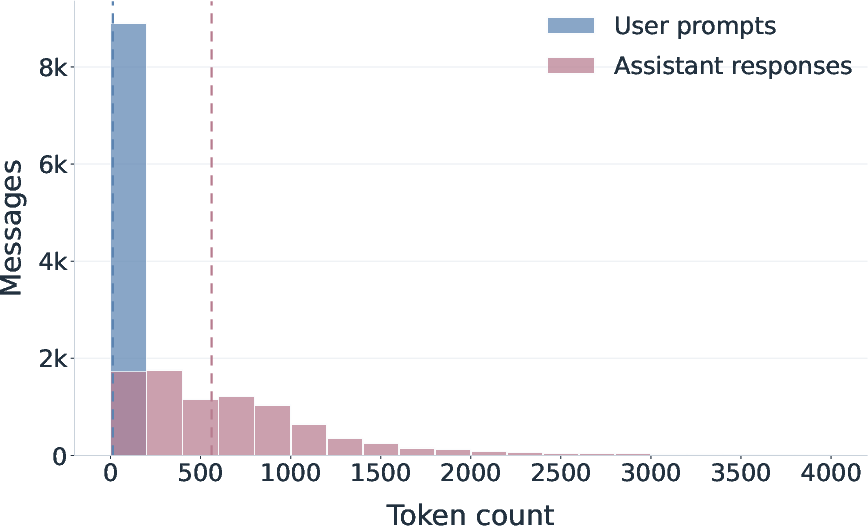
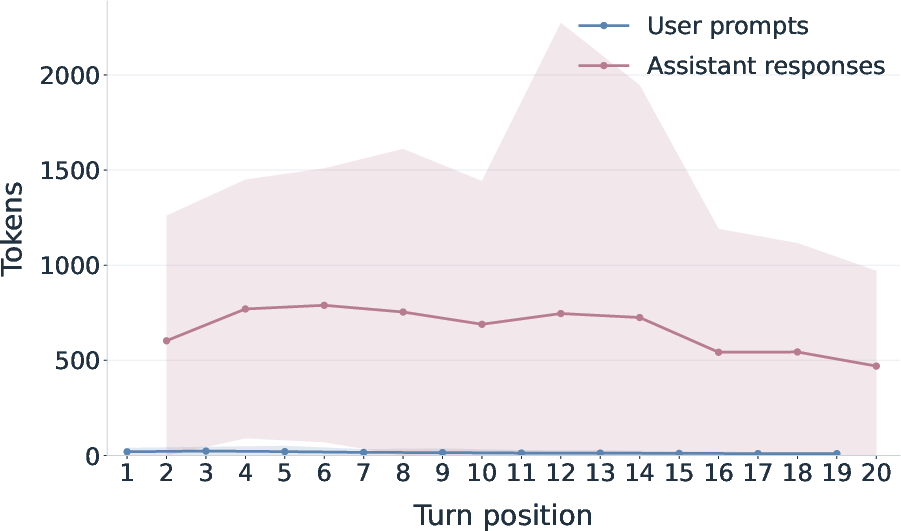
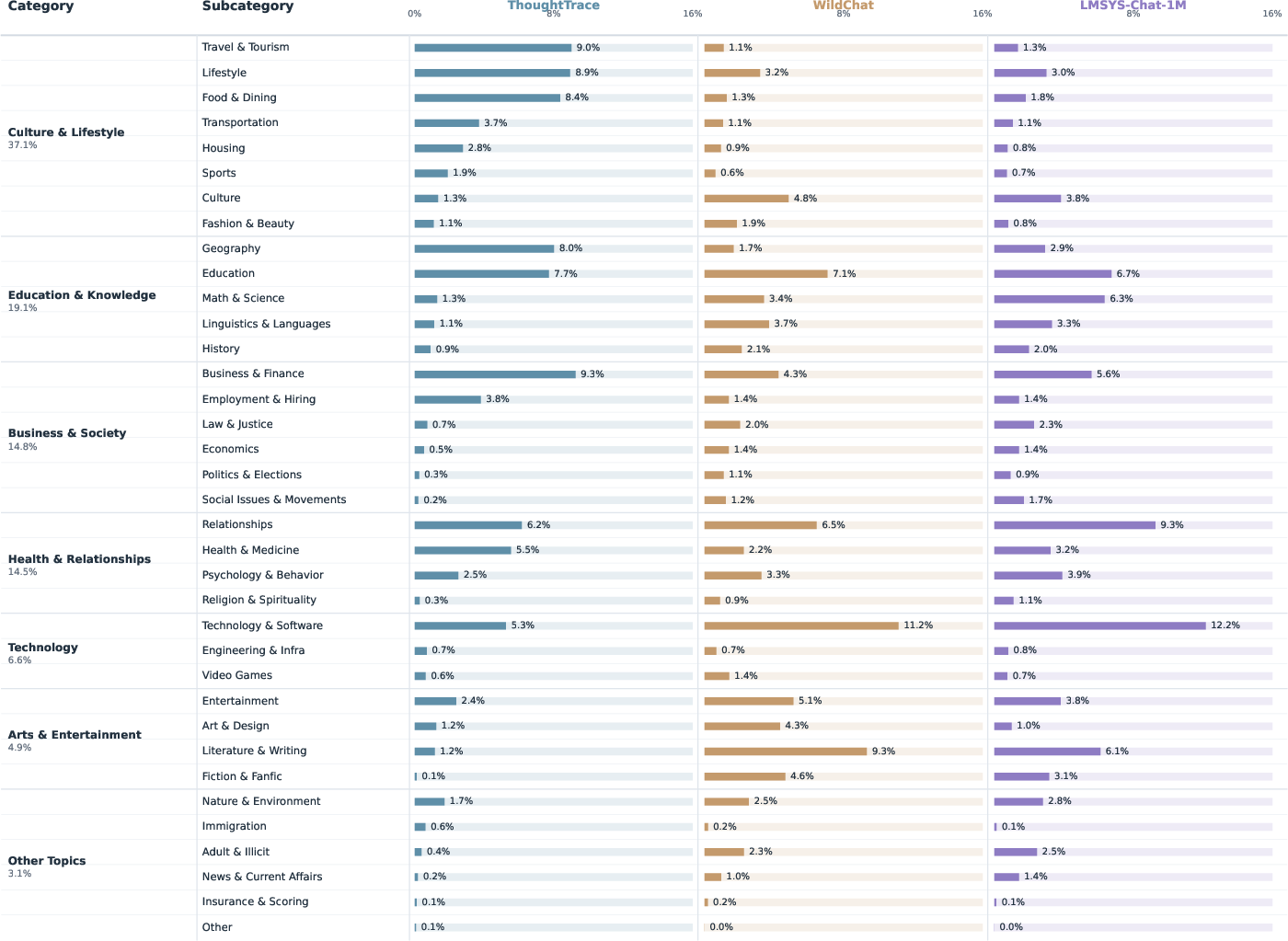
- The dataset captures realistic, longer chats about everyday topics.
- Conversations are usually multi-turn (lots of back-and-forth), not just one question and one answer.
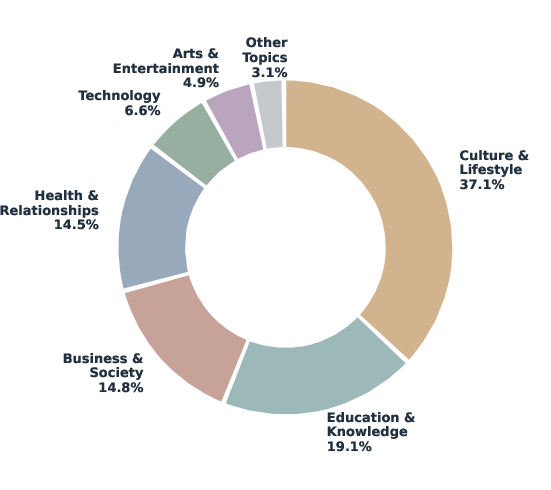
- Topics are broad: school, work, travel, health, tech, and more.
- Most user turns continue or build on the previous task rather than starting over, which reflects real use.
Why this matters: Real AI use is often a longer conversation where goals evolve. This dataset matches that.
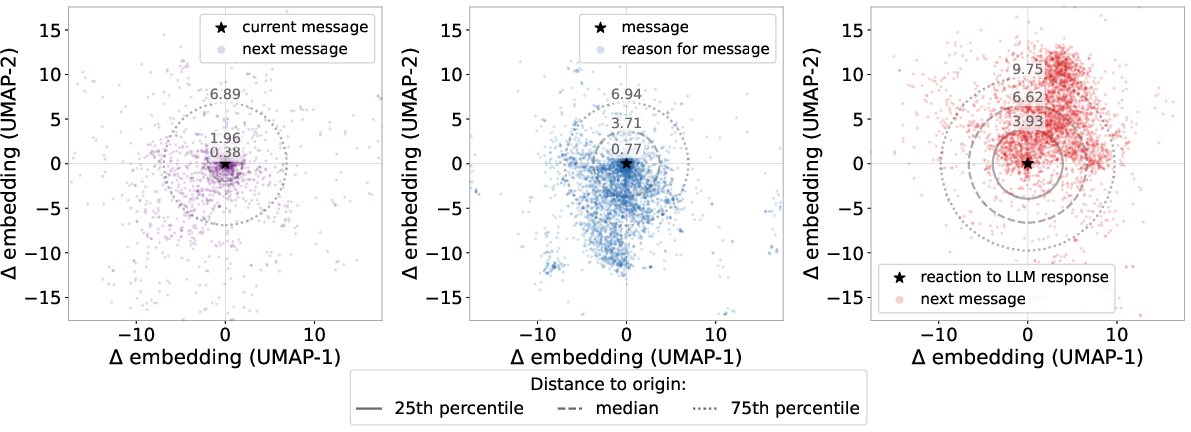
- Thoughts are not the same as messages.
- The “map of meaning” showed that thoughts are meaningfully different from what people type.
- When AIs tried to guess a user’s thoughts from the chat, they generally didn’t do very well.
Why this matters: There’s a lot of hidden context—users’ goals, constraints, preferences—that doesn’t appear in their typed messages.
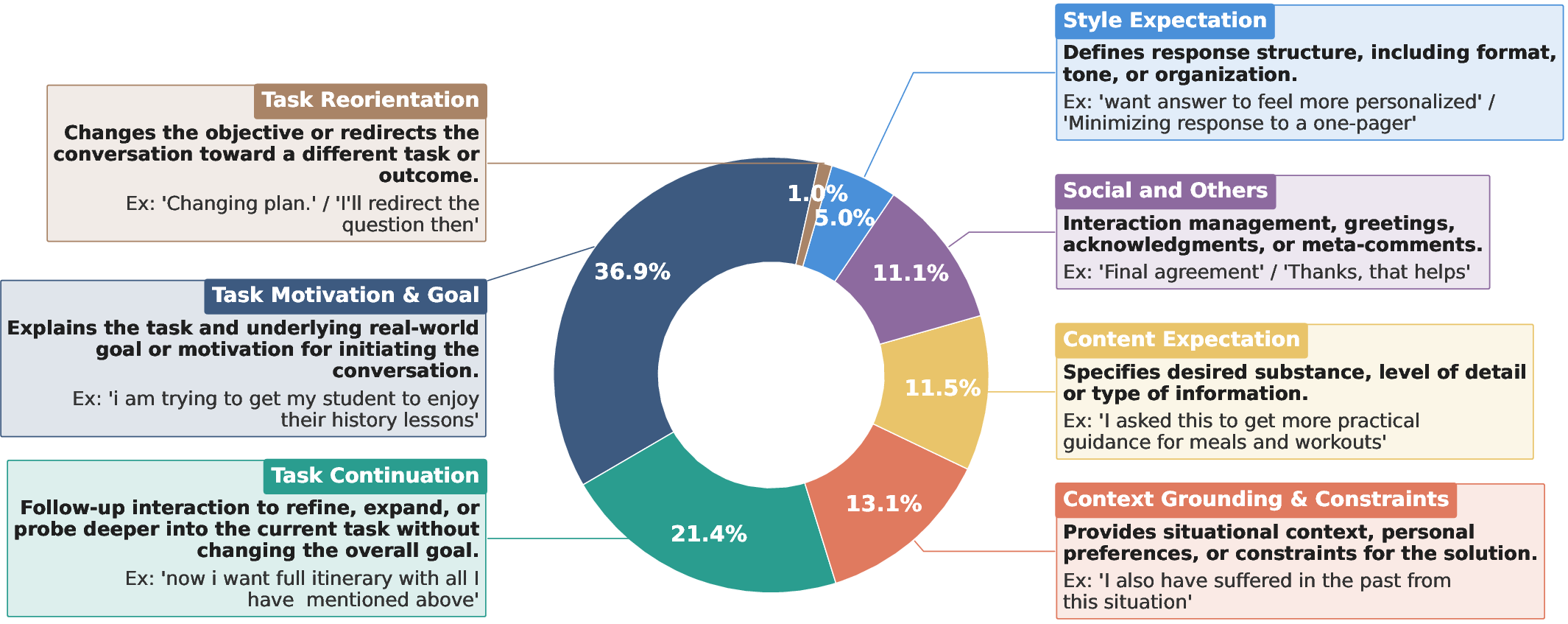
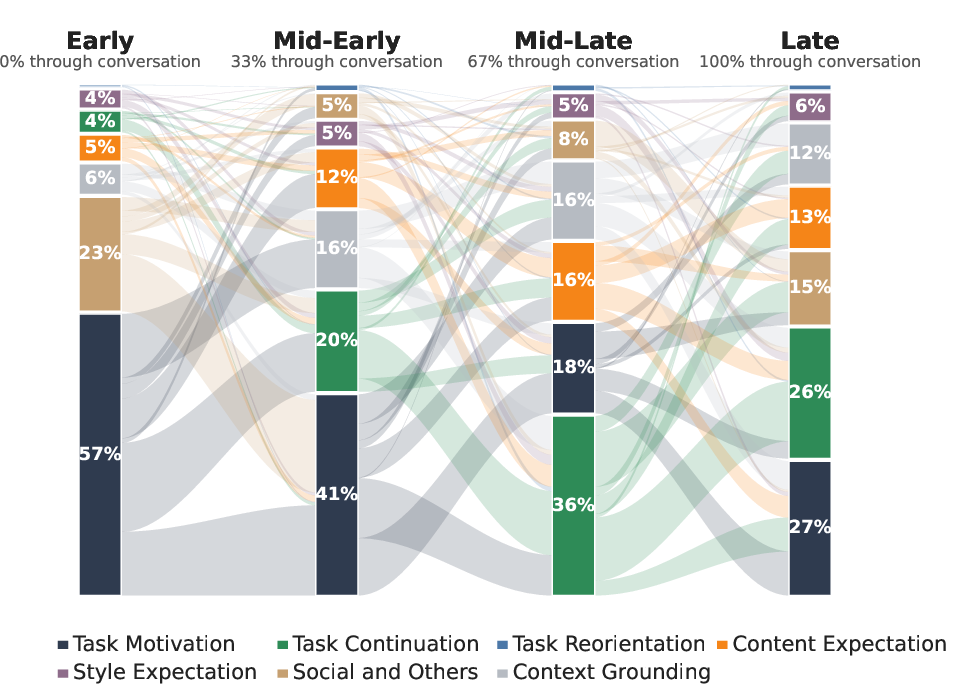
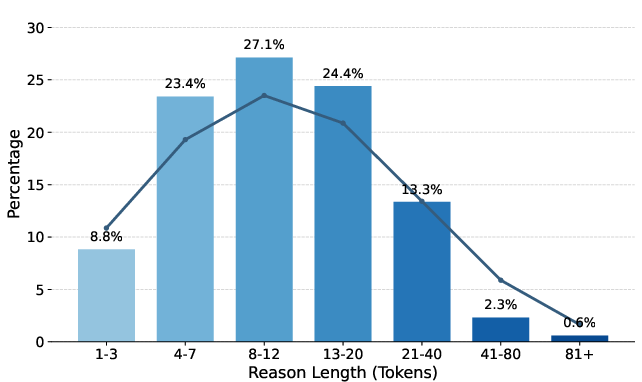
- Thoughts cover many types and change across the conversation.
- Reasons include things like task motivation (why they’re doing this), continuing the task, providing context/constraints, and style or content preferences.
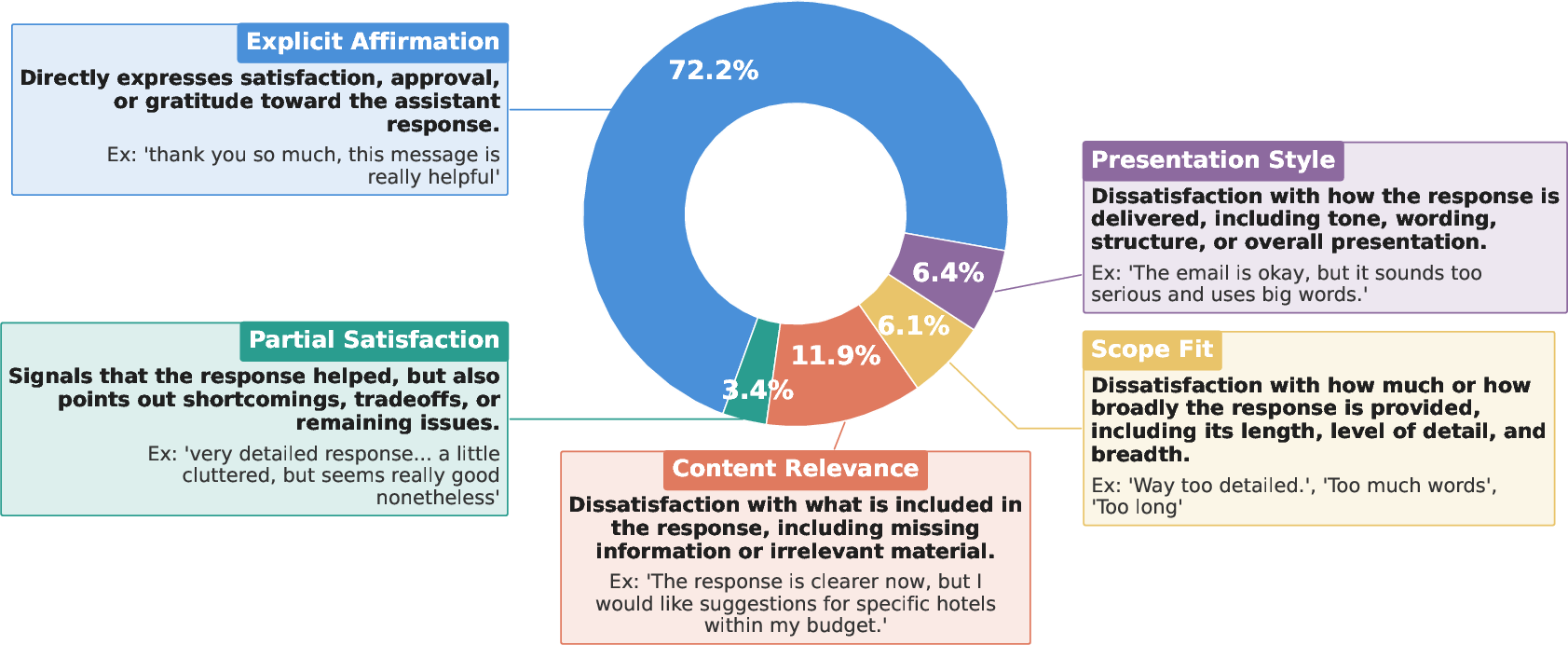
- Reactions include clear approval, partial satisfaction, and specific complaints (e.g., content wasn’t relevant, style wasn’t helpful, the scope was off).
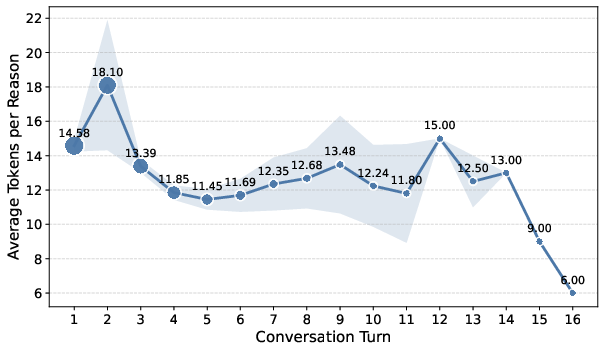
- Early in a chat, people’s reasons are more about their overall goal; later on, reasons focus on continuing and refining. Reactions trend more positive as the conversation progresses.
Why this matters: Knowing which stage the user is in helps an assistant respond more appropriately.
- Thoughts are useful for building better AI.
- Predicting what users will say next: When models could see the user’s thoughts, their predictions improved a lot (around a 40% relative gain in similarity to what the user actually typed).
- Training better responses: Using thought-guided rewrites (fixing weak AI answers using the user’s reactions) led to a model that people preferred more than:
- The original base model,
- A model trained on another big dataset of chats, and
- A version trained using only the messages (without the private thoughts).
Why this matters: Thoughts provide clearer, more detailed signals about what users want fixed, making it easier to improve AI responses.
Why this work could matter in the real world (implications)
- More helpful and personal assistants: If AI can learn from what people are really thinking—not just what they type—it can tailor answers to users’ goals, preferences, and feelings.
- Better evaluation and training: Thoughts can serve as a “training wheel” for AI—showing where an answer falls short and how to fix it—leading to faster, more precise improvements.
- Stronger user simulators: If we want to practice training AIs without involving people all the time, we can build simulated users that reflect real thoughts and behaviors.
- Deeper understanding of human–AI interaction: Researchers can study how intentions and reactions change turn by turn, which helps design more respectful and satisfying AI systems.
A quick note on limits:
- People only wrote thoughts they were aware of; subconscious reactions aren’t captured.
- Writing thoughts might slightly change how people chat.
- The study uses a specific group of online participants, which may not fully represent everyone.
- They tested two main applications here; there’s more to explore.
In short: ThoughtTrace adds the “why” and “how I feel” behind the “what I said.” That extra layer helps predict what users will do next and trains AI to respond in ways people actually prefer.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed as concrete opportunities for future research.
- Ecological validity and duration: Conversations were constrained to 10-minute tasks and a lab-like annotation setting; it remains unknown how thoughts evolve over longer, multi-day, multi-session workflows and in fully in-the-wild usage without annotation burden.
- Representativeness and language coverage: Participants were recruited via Prolific and skew younger and more educated; the dataset’s generalizability to other populations, cultures, and non-English users is untested. A multilingual version and cross-cultural validation are missing.
- Reactivity of thought elicitation: Asking users to annotate reasons and reactions may change behavior (e.g., deeper reflection, polarization). A/B studies comparing identical tasks with and without thought elicitation are needed to quantify reactivity effects.
- Conscious vs. subconscious cognition: The dataset captures only consciously accessible, self-reported thoughts; how much of user intent and satisfaction remains implicit, emotional, or non-verbal is unmeasured. Methods to triangulate (e.g., micro-ESM, think-aloud, physiological proxies) are unexplored.
- Annotation timing and latency: It is unclear whether “reasons” were written before or after sending the message and how quickly “reactions” were recorded; turn-level latency analyses (and their effect on content) are absent.
- Missingness and completeness: There are fewer thoughts than turns (10,174 vs. 17,058), but missingness patterns (by user, stage, or topic) are not analyzed; potential bias from selective annotation remains unknown.
- Taxonomy granularity: The seven “reason” and five “reaction” types may be too coarse. Absent are intensity/valence, confidence/uncertainty, emotional state, and stakes/priority signals that could better guide models.
- Label validity and reliability: Reason/reaction categories were assigned via an LLM-based annotation framework; human audits, inter-annotator agreement, and robustness checks across coders/taxonomies are not reported.
- Overreliance on LLM-as-judge: Key evaluations (thought–message semantic coverage, thought inference, and prediction quality) depend on LLM judges; human evaluations, cross-judge calibration, and robustness to judge choice are not provided.
- Thought inference evaluation scope: Difficulty-of-inference is shown for three frontier models and a single prompting setup; ablations (e.g., ToM prompts, chain-of-thought, “predict-then-rationalize”), broader model coverage, and robustness checks are not explored.
- Associational, not causal, analyses: The paper shows stage-dependent correlations between thought types and behaviors but does not establish causal effects. Interventional or quasi-experimental designs are needed to test how thoughts shape subsequent actions.
- Cross-model differences: Although 20 models were used, the paper does not analyze how model identity/quality affects users’ thoughts, dissatisfaction patterns, or extension behavior. Per-model and model-family comparisons are missing.
- Topic- and domain-specific patterns: The link between specific subtopics/domains and thought/reaction types (especially dissatisfaction drivers) remains underexplored beyond aggregate distributions.
- Realistic deployment pathway for “thought-augmented” prediction: Next-message prediction gains assume access to ground-truth thoughts at inference time; end-to-end pipelines that first predict thoughts and then use them (with compounding error) are untested.
- Alignment experiment confounds: Thought-guided rewrites used more dissatisfaction instances than message-guided (2.2×). Controlled ablations that match counts, source conversations, and selection criteria are needed to isolate the value of “thought content” per se.
- Generalizability of alignment gains: Alignment results are reported for Qwen3.5-4B on Arena-Hard; replication across base models of various sizes, multiple benchmarks (e.g., MT-Bench, HELM), and human A/B tests is needed.
- In-the-wild effectiveness of thought-guided training: Whether thought-guided alignment measurably improves user satisfaction and task success in live interactive settings has not been evaluated.
- Longitudinal personalization: With only two tasks per participant, stable preference/goal modeling and cross-task transfer of thoughts are not assessed. Longer-term, repeated-measures studies are needed.
- Multimodal and agentic settings: The dataset is text-only and tool-free; how thoughts manifest with voice, images, code execution, browsing, or agentic planning remains unexplored.
- Privacy and sensitive inferences: Thought data can encode intimate or sensitive information; the paper does not detail de-identification rigor, privacy-preserving release, misuse risks, or guardrails for models that infer private thoughts.
- Fairness and demographic effects: Group-wise differences in thought patterns, inference accuracy, or alignment outcomes are not analyzed; fairness audits and bias mitigation strategies for thought prediction/alignment are missing.
- Simulator validation: While thought-aware simulators are proposed, no simulator is built/evaluated to show that modeling thoughts improves training outcomes or better matches human behavior.
- Quality control and adversarial behavior: Beyond a tutorial/quiz, the paper does not report attention checks, adversarial data detection, or reliability metrics for user-entered thoughts.
- Convergent validity with explicit satisfaction: The dataset lacks standardized satisfaction ratings; correlations between reactions and rating scales (or task success) are not established.
- Benchmarking and metrics standardization: A public, standardized “thought prediction” benchmark with fixed splits, human-verified references, and clearly defined metrics/baselines is not presented.
- Handling multiple and conflicting thoughts: The paper allows multiple thoughts per turn but does not analyze how conflicts are resolved or how models should prioritize competing latent needs.
- Stage dynamics beyond counts: Effects of inter-turn delays, time pressure, and session restarts on thought types and satisfaction are not measured.
- Cross-lingual pragmatics and taxonomy transfer: Whether the thought taxonomy and inference models hold across languages and cultural pragmatics is untested.
- Interface-induced biases: The annotation UI and prompt wording may shape thought content; A/B studies of UI design (placement, optional vs. required, free-form vs. guided) are not conducted.
- Robustness of embedding-based conclusions: Semantic distance analyses rely on a single embedding model (details deferred to the appendix); sensitivity to alternative embedding spaces is not shown.
- Class imbalance in reactions: “Explicit Affirmation” dominates (72.2%); whether this reflects real satisfaction, taxonomy bias, or LLM labeling bias is unclear without human validation and rebalancing strategies.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that organizations and individuals can implement now, drawing on ThoughtTrace’s findings that user thoughts (reasons and reactions) are distinct from messages, difficult to infer reliably, and valuable for prediction and alignment.
- Personalized chat UI with “reason/reaction” capture
- Sectors: software, customer support, education, productivity apps
- What: Add low-friction UI elements (chips, dropdowns, short text fields) to capture user “Reason” (e.g., goal, constraints, style preference) when sending a message and “Reaction” (affirmation, dissatisfaction categories) after a reply.
- Tools/workflows:
- Reason/Reaction widgets; schema aligned to ThoughtTrace taxonomies (7 reason and 5 reaction types).
- Prompt templates that explicitly pass captured thoughts as context.
- Assumptions/dependencies: Users accept minimal extra input; clear consent/UX copy; data storage compliant with privacy regulations.
- Thought-augmented prompting in assistants
- Sectors: software, IDEs, enterprise productivity
- What: Incorporate captured thoughts as inference-time context to improve next-turn predictions and response quality (supported by +41.7% gain in next-message prediction with thought context).
- Tools/workflows:
- “Context headers” in system prompts: Goal, Constraints, Content/Style Expectations, Task Continuation signal.
- Server-side middleware that injects the thoughts into prompts and logs outcomes.
- Assumptions/dependencies: Prompt budget and latency overhead acceptable; reliable logging and redaction.
- Thought-guided preference learning to align models
- Sectors: model training, foundation model labs, applied ML teams
- What: Use reactions indicating dissatisfaction to generate thought-guided rewrites and train with DPO or similar preference learning, which outperforms message-guided rewrites (+4.5% over messages; +25.6% over base model on Arena-Hard).
- Tools/workflows:
- Data pipeline to extract (original response, thought-guided rewrite) pairs.
- Fine-tuning setups (e.g., LoRA/PEFT) and evaluation on robust preference benchmarks.
- Assumptions/dependencies: Sufficient GPU budget; access to safe training data; evaluation coverage beyond Arena-Hard for domain fit.
- Dissatisfaction detectors for real-time remediation
- Sectors: CX analytics, customer support, SaaS
- What: Lightweight classifiers (or rules) that detect reaction categories (content relevance, scope fit, presentation style) to trigger auto-rewrites, follow-up questions, or escalation.
- Tools/workflows:
- Rule-based prompts + small classifiers trained on reaction labels.
- Playbooks for “if reaction=X then do Y” (e.g., ask for constraints if “scope fit” issue).
- Assumptions/dependencies: Availability of labels; integration with chat orchestration and QA guardrails.
- Conversation analytics with thought taxonomies
- Sectors: product, CX, operations
- What: Instrument conversations to track how thought categories evolve by turn (e.g., rising affirmation in later stages) to identify friction points and prioritize UX/content fixes.
- Tools/workflows:
- Dashboards reporting thought distribution by stage, topic, and model.
- A/B tests measuring changes in affirmation/dissatisfaction rates.
- Assumptions/dependencies: Proper anonymization; statistically meaningful sample sizes.
- Basic user simulators conditioned on thoughts
- Sectors: applied ML, QA, model eval
- What: Train/drive simple user simulators that take conversation history + thoughts to produce the next user turn, enabling automated scenario testing and regression checks.
- Tools/workflows:
- Finetuning/evaluation scripts conditioned on ThoughtTrace format.
- Scenario libraries mapped to thought categories (e.g., novice vs. expert goals).
- Assumptions/dependencies: Simulated users not yet fully faithful; careful use for internal testing rather than deployment-critical decisions.
- Rapid prototyping for education and training tools
- Sectors: education, L&D
- What: Tutors/coaches prompt learners to state goals and constraints up front, then adapt explanations and style based on ongoing reactions (affirmation vs. dissatisfaction types).
- Tools/workflows:
- Tutor prompts with “explicit goal + style” capture.
- Stage-aware tutor strategies (more scaffolding early; summarization later).
- Assumptions/dependencies: Student willingness to provide inputs; alignment with institutional policies.
- Data schemas and logging practices for thought signals
- Sectors: software engineering, data engineering, governance
- What: Adopt a standard schema (conversation ID, message type, thought type/label) to support analytics, training, and auditability.
- Tools/workflows:
- Event logging with PII redaction; IAM/role-based access to “thought” fields.
- Retention policies and deletion workflows.
- Assumptions/dependencies: Data governance maturity; security reviews.
- Targeted prompt patterns for common reaction types
- Sectors: content generation, marketing, support
- What: Maintain prompt macros that respond to specific dissatisfaction types (e.g., “style mismatch” triggers tone/format restyling; “scope fit” triggers clarification).
- Tools/workflows:
- Prompt libraries indexed by reaction category.
- Quick-rewrite buttons in agent consoles.
- Assumptions/dependencies: Content moderation and brand consistency controls.
- Academic benchmarks and studies using ThoughtTrace
- Sectors: academia, HCI, NLP
- What: Immediate use of dataset to study multi-turn cognition, stage dynamics, and latent-intent prediction; create thought-prediction baselines and eval sets.
- Tools/workflows:
- Evaluation scripts for thought inference and message prediction.
- Cross-demographic analyses and ablation studies.
- Assumptions/dependencies: Dataset access; IRB-compliant usage; careful interpretation given self-reported thoughts.
Long-Term Applications
These applications require further research, scaling, policy frameworks, or infrastructure to be feasible and safe.
- Thought inference modules (machine Theory of Mind) integrated into assistants
- Sectors: software, agents, robotics (HRI)
- What: Models that reliably predict reasons/reactions from context to proactively tailor responses—while being transparent and corrigible.
- Tools/workflows:
- Multi-task training (predict thoughts + next message).
- Uncertainty estimation; user-verifiable summaries of inferred intent.
- Assumptions/dependencies: Advances in ToM generalization; strong calibration; safeguards against misattribution or manipulation.
- Persistent, privacy-preserving user state for personalization
- Sectors: OS-level assistants, enterprise productivity, consumer apps
- What: Long-lived user profiles capturing stable goals, preferences, and common constraints across sessions, updated with stage-aware signals.
- Tools/workflows:
- On-device memory stores, federated learning, differential privacy.
- Memory governance: consent renewal, inspection, and deletion.
- Assumptions/dependencies: Regulatory approval; robust privacy tech; user trust and clear control surfaces.
- Thought-guided reward modeling and online alignment
- Sectors: model training, RLHF/RL
- What: Build reward models that encode dissatisfaction categories and revise-instructions; extend to online settings (OPD) using thought signals for continual improvement.
- Tools/workflows:
- RMs trained on thought-annotated conversations, with red-teaming.
- Safe online learning loops and drift detection.
- Assumptions/dependencies: Scalable, safe on-policy training; rigorous evals to avoid reward hacking.
- High-fidelity user simulators for training and stress-testing
- Sectors: model evaluation, safety, policy testing
- What: Agents that simulate diverse users with latent thought trajectories for large-scale training, safety evaluation, and what-if policy assessments.
- Tools/workflows:
- Simulator benchmarks validated against real thought traces.
- Scenario orchestration across demographics and tasks.
- Assumptions/dependencies: External validation against real users; bias auditing; governance around use.
- Sector-specific thought-aware assistants
- Healthcare:
- What: Patient-facing triage and education assistants that capture goals, constraints (e.g., comorbidities), and reactions to improve clarity and adherence; careful use in mental health to detect anxiety/style needs.
- Dependencies: Clinical validation; FDA/EMA or local regulatory compliance; safety and disclaimers.
- Education:
- What: Longitudinal tutors that adapt by stage and learner reactions, personalize scaffolding and assessment.
- Dependencies: Curriculum alignment; fairness and accessibility audits.
- Finance:
- What: Advisors that clarify user goals/risk tolerance via thought capture and tailor explanations; transparent reasoning paths.
- Dependencies: Compliance (e.g., SEC/ESMA), clear suitability disclosures.
- Enterprise/Customer Support:
- What: Agents that detect and respond to latent dissatisfaction to reduce escalations and improve CSAT.
- Dependencies: Data sharing agreements; integration with CRM; bias controls.
- Robotics/HRI:
- What: Robots that adapt task plans based on operator intent/reactions captured through multimodal channels and chat.
- Dependencies: Robust multimodal ToM; safety certifications.
- Standards and regulations for “mental-state data”
- Sectors: policy, legal, compliance
- What: Governance frameworks defining consent, storage, use, and sharing of thought-level data (distinct from chat logs); labeling requirements for inferred vs. user-supplied thoughts.
- Tools/workflows:
- Model cards and data statements for thought usage.
- Auditable consent trails; opt-out mechanisms.
- Assumptions/dependencies: Multi-stakeholder consensus; alignment with GDPR/CCPA/AIA and sectoral rules.
- Cross-modal thought collection and fusion
- Sectors: wearables, accessibility, multimodal AI
- What: Enhance thought signals with prosody, keystroke dynamics, or physiological indicators (opt-in) to better infer reactions/needs for accessibility use cases.
- Tools/workflows:
- Multimodal encoders; privacy-aware signal processing.
- On-device inference to limit data exposure.
- Assumptions/dependencies: Strong privacy protections; IRB-level oversight; evidence of benefit vs. risk.
- Ecosystem of thought-augmented datasets and SDKs
- Sectors: developer tools, MLOps
- What: Shared schemas, SDKs, and benchmarks for collecting and using thoughts across applications, enabling reproducible training and evaluation.
- Tools/workflows:
- Open-source connectors for logging, redaction, and consent flows.
- Benchmark suites for thought prediction and satisfaction modeling.
- Assumptions/dependencies: Community adoption; funding and maintenance.
- Thought-centered evaluation standards
- Sectors: academia, standards bodies, model labs
- What: Benchmarks and metrics that measure latent-intent capture and user satisfaction beyond surface text (e.g., stage-specific affirmation rates).
- Tools/workflows:
- Public leaderboards with thought-aware tasks.
- Cross-lab reproducibility protocols.
- Assumptions/dependencies: Agreement on metrics; high-quality human oversight.
- Safety and ethics toolkits for thought-aware systems
- Sectors: safety, ethics, internal audit
- What: Auditing tools to detect over-personalization, undue influence, or manipulative use of inferred thoughts; bias and fairness checks across demographics.
- Tools/workflows:
- Counterfactual audits by toggling thought inputs.
- Impact assessments and red-team playbooks.
- Assumptions/dependencies: Organizational commitment; access to necessary logs under strict privacy controls.
Key Dependencies and Assumptions Across Applications
- User acceptance and trust: Clear consent, transparency about how thoughts are used, and obvious user controls are essential.
- Data governance: Strong anonymization, role-based access, retention limits, and secure storage of “mental-state data.”
- Representativeness: ThoughtTrace users were recruited via Prolific; additional, diverse data may be needed for broad generalization.
- Model limits: Current LLMs struggle to infer thoughts reliably; production systems should prefer explicit user inputs or confirm inferred states.
- Cost/latency: Injecting thought context increases token and compute budgets; engineering optimizations and caching are needed.
- Regulatory compliance: Anticipate evolving AI and data protection regulations; sector-specific approvals may be required (e.g., healthcare, finance).
These applications translate ThoughtTrace’s core insight—that self-reported user thoughts are a distinct, high-value modality—into practical product workflows, training pipelines, evaluation methods, and policy frameworks that can improve alignment, personalization, and user satisfaction in real-world AI systems.
Glossary
- Arena-Hard: A robust instruction-following benchmark used to evaluate model alignment via preference comparisons. "Models are evaluated on Arena-Hard"
- Direct Preference Optimization (DPO): A preference-based fine-tuning method that directly optimizes a policy from chosen vs. rejected responses without an explicit reward model. "paired with originals for DPO training"
- Explicit Affirmation: A reaction label indicating the user’s clear approval or satisfaction with a response. "Explicit Affirmation dominates (72.2%)"
- Frontier LLMs: The most capable state-of-the-art LLMs available at a given time. "three frontier LLMs"
- Inference-time context: Additional information provided to a model at inference to condition or improve its predictions. "as inference-time context."
- LLM-as-a-judge: Using an LLM to evaluate, score, or compare outputs for metrics like similarity or quality. "An LLM-as-a-judge scores each inference"
- Long-horizon conversations: Dialogues that span many turns, requiring sustained context and evolving goals across the interaction. "long-horizon conversations"
- Multi-turn conversations: Dialogues consisting of multiple alternating user and assistant messages within the same interaction. "multi-turn conversations"
- On-Policy Distillation (OPD): A training approach that distills on-policy (online) generated behaviors into a student model for iterative improvement. "On-Policy Distillation (OPD)"
- Preference learning: Training models from human or proxy preferences to better align outputs with desired behavior. "for preference learning"
- Reward modeling: Learning a function that assigns scalar rewards to outputs based on human or proxy feedback to guide training. "reward modeling"
- Semantic coverage: The extent to which one text captures the informational content of another. "LLM-based semantic coverage scoring"
- Semantic similarity: A measure of how similar two texts are in meaning, often judged on a numeric scale. "semantic similarity to the ground truth"
- Style-Controlled Win Rate (SC Win): A win-rate metric that controls for stylistic differences to isolate substantive quality. "style-controlled win rates (SC Win, %)"
- Theory of Mind (ToM): The capacity to infer others’ latent mental states (e.g., beliefs, goals, desires) from behavior. "Theory of Mind (ToM)"
- UMAP (Uniform Manifold Approximation and Projection): A dimensionality reduction technique for visualizing high-dimensional data (e.g., embeddings). "UMAP projections of embedding differences"
- User simulators: Models that mimic user behavior and messages to train or evaluate conversational assistants. "user simulators"
- Win rate: The percentage of pairwise comparisons in which a model’s response is preferred. "(+25.6% win rate)"
Collections
Sign up for free to add this paper to one or more collections.