Generative Recursive Reasoning
Abstract: How should future neural reasoning systems implement extended computation? Recursive Reasoning Models (RRMs) offer a promising alternative to autoregressive sequence extension by performing iterative latent-state refinement with shared transition functions. Yet existing RRMs are largely deterministic, following a single latent trajectory and converging to a single prediction. We introduce \emph{Generative Recursive reAsoning Models (GRAM)}, a framework that turns recursive latent reasoning into probabilistic multi-trajectory computation. GRAM models reasoning as a stochastic latent trajectory, enabling multiple hypotheses, alternative solution strategies, and inference-time scaling through both recursive depth and parallel trajectory sampling. This yields a latent-variable generative model supporting conditional reasoning via $p_θ(y \mid x)$ and, with fixed or absent inputs, unconditional generation via $p_θ(x)$. Trained with amortized variational inference, GRAM improves over deterministic recurrent and recursive baselines on structured reasoning and multi-solution constraint satisfaction tasks, while demonstrating an unconditional generation capability. \href{https://ahn-ml.github.io/gram-website/}{https://ahn-ml.github.io/gram-website}


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
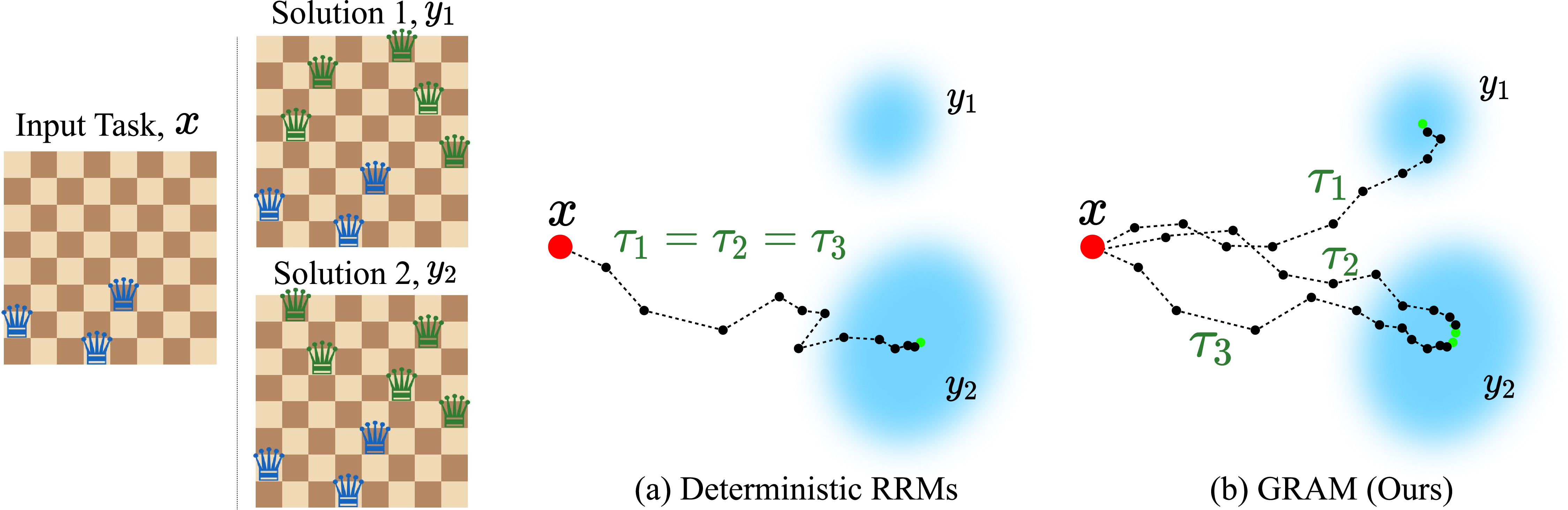
This paper introduces a new way for AI models to “think” through problems. Instead of following one fixed line of thought, the model (called GRAM: Generative Recursive reAsoning Model) explores many possible lines of thought in parallel and over multiple steps. This helps it handle problems with uncertainty or many correct answers (like puzzles with multiple solutions), and even create new things from scratch (like generating images or Sudoku boards).
What questions are the authors asking?
- How can we build AI systems that don’t just get bigger, but actually think better by using their computation more wisely?
- Can a model keep several “hypotheses” in mind at once, not just one?
- Can we scale up reasoning both by “thinking longer” (more steps) and by “thinking wider” (trying multiple ideas in parallel)?
- Can the same setup both solve problems when given an input (like completing a Sudoku) and generate things with no input (like inventing a new Sudoku board)?
How does their method work?
Think of the model as having an internal “scratchpad” where it refines its ideas step by step (this scratchpad is called a latent state). Traditional recursive models update this scratchpad in a fixed, predictable way, so they usually end up with one final answer. GRAM changes this by adding controlled randomness, so the model can explore multiple possible paths before choosing an answer.
Here are the main parts, in everyday terms:
Two loops: quick refinements inside slower big steps
- The latent state is like the model’s hidden workspace. GRAM splits it into:
- A high-level memory h (big-picture plan).
- A low-level memory l (fine details).
- Inside each big step, it quickly refines the low-level details several times while holding the big-picture plan steady.
- Then it updates the big-picture plan once, using both the refined details and a bit of guided randomness.
Analogy: Imagine solving a puzzle. Within each round, you tweak small details several times (move pieces around), then you make one larger strategic adjustment (change your overall approach).
Adding guided randomness to explore better
- At each big-picture update, GRAM first makes a best-guess update (a deterministic proposal).
- Then it adds a small, learned “random nudge” (noise) whose direction and size depend on the current situation.
- This lets the model explore different possible reasoning paths, instead of getting stuck in one.
Analogy: You’re navigating a maze. A GPS suggests the next turn (the proposal), but you also add a small, smart wiggle to explore nearby routes (the guided randomness), so you don’t miss a better path.
Training with a helper that can peek at the answer
- During training, the model uses two roles:
- A “prior” that guesses without seeing the answer (how it will work at test time).
- A “posterior” that’s allowed to peek at the correct answer while learning. It learns better ways to use the random nudges.
- The training goal balances two things:
- Solving the task correctly.
- Keeping the “peeking helper” close to what the “no-peeking” model can do on its own, so it won’t collapse when the helper is gone.
Analogy: A student practices with a tutor who can check the textbook (peek), then learns to do the same without help.
Scaling reasoning at test time: deeper and wider
- Depth (think longer): Let the model run more refinement steps to improve the result.
- Width (think wider): Run multiple “thought trajectories” in parallel and pick the best result.
- Choosing the best: Either use majority vote or a small judge network that scores which hidden state is most promising.
Analogy: You can spend more time thinking, or ask a group of friends to brainstorm in parallel and then pick the best idea.
Not just solving—also generating
- The same process can work with no input. GRAM can generate data from scratch (like digit images or Sudoku boards) by sampling and refining its own latent thoughts until an output appears.
What did they find?
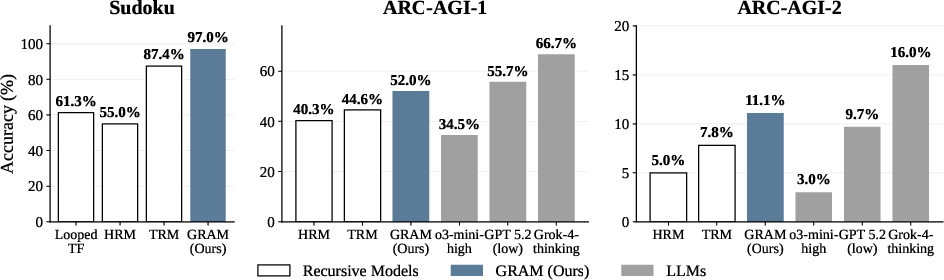
On several benchmarks, GRAM did better than similar models that only follow one deterministic path:
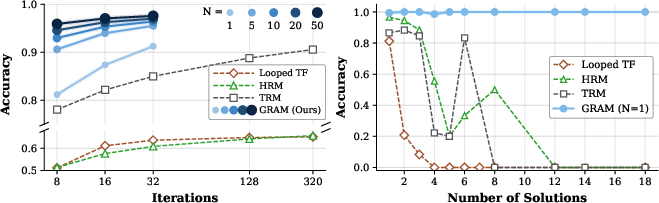
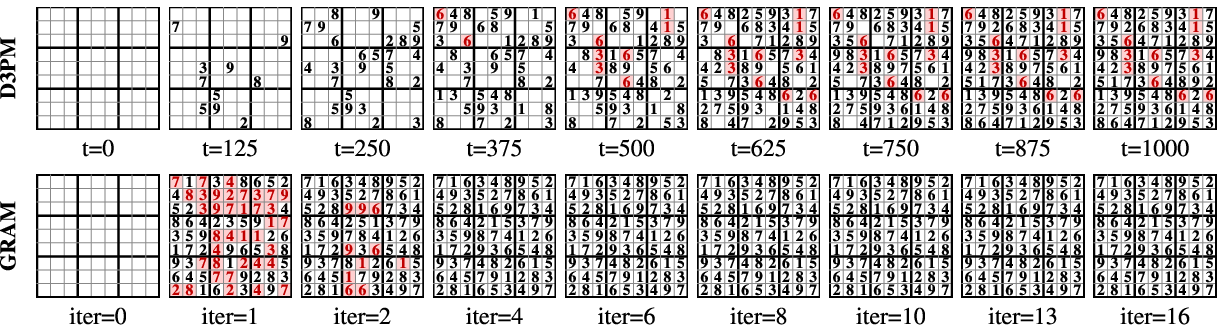
- Hard puzzles (Sudoku-Extreme, ARC-AGI): GRAM solved more problems correctly than deterministic recursive baselines (like Looped Transformers, HRM, TRM).
- Multi-solution tasks (N-Queens, Graph Coloring): GRAM found more valid different solutions and kept accuracy high even when many answers were possible. Deterministic models tended to “collapse” to one type of answer and miss others.
- Test-time scaling: Sampling multiple trajectories in parallel (wider) improved results as much as, or more than, just running longer (deeper), often with similar compute cost.
- Unconditional generation:
- Sudoku: GRAM generated valid full Sudoku boards at very high rates, using far fewer steps and parameters than a diffusion-style baseline.
- MNIST digits: GRAM generated clear digits with quality similar to a strong baseline, while deterministic recursion collapsed to poor-quality results.
Why this matters:
- Many real problems have uncertainty or multiple correct answers. Being able to explore and keep multiple hypotheses truly helps.
- Parallel exploration can improve quality without making you wait longer for one very deep chain of thought to finish.
- One architecture that both reasons (given inputs) and generates (from scratch) is flexible and powerful.
What is the impact of this research?
- Better problem-solving: GRAM shows that organizing computation as “guided, stochastic, recursive thinking” can beat just making models bigger or producing long text chains.
- Practical scaling: You can trade off between depth (latency) and width (parallelism) depending on your resources and needs.
- Generality: The same idea works for structured puzzles and for generating images or boards—suggesting broad usefulness.
- Design principle: Future reasoning models could adopt “probabilistic multi-trajectory recursion” as a core design, not an afterthought.
Caveats and care:
- Training is still sequential over many steps, which can be slower or harder to scale than standard Transformers.
- Because the model can generate very plausible outputs, users must still verify answers in high-stakes settings.
- Using many parallel samples can increase compute costs, so efficiency and good selection methods (like the judge network) are important.
In short
- Purpose: Let models explore several lines of thought, not just one.
- Method: Recursively refine a hidden workspace with small, learned random nudges, trained with a helper that can peek at answers.
- Results: Stronger puzzle solving, better handling of multiple solutions, effective parallel scaling, and solid generation from scratch.
- Impact: A practical step toward AI that thinks by exploring, not just by growing bigger.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps, uncertainties, and unexplored questions that emerge from the paper and could guide future work:
- Training objective bias and variance
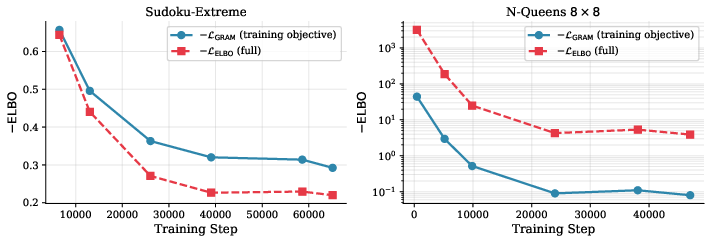
- The paper relies on a truncated, supervision-step surrogate objective (stopping gradients before the final transition of each step), which is a biased approximation to the full trajectory ELBO; the impact of this bias on consistency, convergence, and sample efficiency is not quantified.
- No comparison is provided against unbiased or lower-bias alternatives (e.g., full-trajectory reparameterization, DReG, VIMCO, control variates, or variational smoothing), nor is the variance of gradient estimators analyzed.
- The effect of KL scaling/annealing (e.g., β-ELBO or step-wise KL weights) on exploration, mode coverage, and over-regularization is not studied.
- Stochastic guidance design space
- Stochasticity is injected only into the high-level latent with a diagonal Gaussian; richer priors/posteriors (full-covariance, low-rank, learned flows, mixture or heavy-tailed distributions) and their effect on exploration and stability are not explored.
- The guidance mean/variance schedules and their adaptation over recursion depth are not studied; there is no analysis of annealing strategies or depth-dependent noise.
- An attempt to add noise to the low-level latent reportedly did not help, but alternative structured noise mechanisms (e.g., selective channel/attention-head noise, learned masks, correlated noise across steps, or state-dependent diffusion-like schedules) remain unexplored.
- It is unclear whether the model suffers posterior collapse or prior over-dispersion under different hyperparameters; diagnostics for effective stochasticity (e.g., per-step KL, mutual information between z and y) are not reported.
- Decoder and latent interface
- The decoder reads only the high-level latent; whether decoding from both levels, multi-read decoding, or iterative/auxiliary decoders improves accuracy, calibration, or diversity is not investigated.
- The trade-off between hierarchical depth K (low-level updates per transition) and exploration quality/efficiency is not characterized.
- Inference-time width scaling and selection
- Parallel sampling gains are shown, but the latency–throughput–quality trade-offs under realistic hardware constraints (e.g., GPU memory and batching limits) are not quantified.
- The Latent Process Reward Model (LPRM) is trained with a sparse, binary correctness signal; its calibration, robustness to distribution shift, and cross-task generalization are unstudied.
- There is no comparison with alternative candidate selection mechanisms (e.g., learned rerankers using input–output features, self-consistency with constraint checks, or test-time energy/score functions).
- Interacting or population-based trajectory search (e.g., resampling, beam search in latent space, particle MCMC, or cross-trajectory communication) is not explored; trajectories are sampled independently.
- Adaptive depth (ACT) behavior
- Although ACT is adopted, there is no analysis of learned halting distributions, depth–accuracy–latency trade-offs, or stability; optimal halting policies and their generalization remain open.
- Interactions between ACT and width scaling (e.g., variable halting depths across parallel samples) are not characterized.
- Comparisons and scope of evaluation
- The evaluation focuses on controlled puzzles and binarized MNIST; performance and practicality on large-scale or real-world tasks (natural language reasoning, code synthesis, math word problems, scientific planning, or multimodal reasoning) are left open.
- There is no systematic comparison with strong test-time sampling and reranking strategies in autoregressive LLMs (e.g., self-consistency, multi-sample CoT, ToT/GoT) under matched compute.
- The unconditional generative evaluation lacks likelihood or bound estimates (e.g., bits/dim, NLL via importance sampling); only IS/FID and Sudoku validity are reported.
- Compute and scalability constraints
- The authors note sequential deep supervision as a bottleneck but do not quantify wall-clock, memory, or energy compared to strong Transformer baselines at matched quality.
- Methods to mitigate sequential training (e.g., synthetic gradients, equilibrium models, reversible updates, parallel-in-time solvers, learned warm-starts) are not explored.
- Scaling laws (quality vs parameters/steps/samples) and diminishing returns for width vs depth are not studied.
- Theoretical properties and guarantees
- There are no theoretical guarantees on convergence, exploration sufficiency, or approximation quality of the surrogate objective relative to the true ELBO.
- The relationship to planning/search (e.g., stochastic local search, MCTS in latent space) and formal links to inference in probabilistic graphical models or SSMs are not analyzed.
- Constraint satisfaction and diversity trade-offs
- The balance between constraint satisfaction and solution diversity is not formally studied; how to control or tune this trade-off (via KL schedules, noise magnitude, or selection policies) remains unclear.
- Failure modes for multi-solution tasks (e.g., mode redundancy, duplicate solutions among samples) lack quantitative analysis beyond coverage percentages.
- Robustness, calibration, and reliability
- Uncertainty calibration (e.g., proper scoring rules, ECE) for both predictive distributions and LPRM scores is not evaluated.
- Robustness to distribution shift, adversarial perturbations, or corrupted inputs is unstudied.
- The reliability of GRAM when constraints cannot be fully satisfied (partial credit, soft constraints) is not examined.
- Architectural alternatives and ablations
- While hierarchical recursion is used, alternatives (e.g., continuous-time/ODE/SDE recursion, diffusion-style schedules, energy-based or score-based latent dynamics) are not compared.
- The role of auxiliary losses or intermediate decoders at multiple steps to stabilize training and improve exploration is not investigated.
- Sensitivity to key hyperparameters (number of transitions T, supervision steps N_sup, K, noise scale initialization, KL weights) is not systematically profiled.
- Integration with external tools and priors
- Combining GRAM with programmatic constraint checkers, differentiable solvers, external memory, or tool-augmented reasoning is not explored.
- Incorporating domain-specific priors (e.g., symmetries in Sudoku/graph rules, CSP factorization) into the transition or guidance distributions remains open.
- Generalization and transfer
- Cross-task transfer and few-shot generalization of the learned stochastic transitions are not evaluated (e.g., zero/few-shot adaptation to new puzzle variants or larger board sizes).
- The ability to reuse or compose learned latent skills/strategies across tasks is not studied.
- Safety and evaluation fidelity
- Although broader risks are acknowledged, there is no empirical assessment of hallucination/invalid-solution rates under constraint uncertainty or noisy reward models.
- For unconditional generation, the fidelity of evaluation on binarized MNIST (e.g., effect of binarization, FID computation protocol) and its relevance to broader generative modeling remains limited.
- Reproducibility and fairness
- Some baseline results are omitted due to cost (e.g., Looped TF on ARC-AGI), leaving potential questions about fairness and reproducibility under matched compute and tuning budgets.
- Details on hyperparameter searches for baselines vs GRAM, and sensitivity to random seeds, are not fully reported in the main text.
Practical Applications
Overview
Based on the paper “Generative Recursive Reasoning (GRAM),” the following applications translate its core findings—stochastic latent transitions in recursive reasoning, width- and depth-based inference-time scaling, and variational training—into practical, real-world use cases. Each item specifies sectors, potential tools/workflows, and feasibility assumptions or dependencies.
Immediate Applications
These can be prototyped or deployed now with task-specific data and moderate engineering effort, leveraging GRAM’s demonstrated strengths on constraint satisfaction and structured reasoning.
- Constraint-satisfaction plug-ins for operations and logistics (industry; software/OR)
- What: Use GRAM as a heuristic or solver for scheduling, timetabling, rostering, and resource allocation (e.g., staff rosters, machine/shift scheduling) where multiple valid solutions exist.
- How: Integrate a “GRAM-based CSP module” into existing OR stacks (e.g., OR-Tools, CP-SAT) to propose candidate assignments via width sampling and select with a Latent Process Reward Model (LPRM) or constraint validator.
- Dependencies: Formalization of problem-specific encoders/decoders; a fast constraint checker for selection; domain training data or synthetic generators; GPU/CPU capacity for parallel sampling.
- Candidate generation and ranking workflows (industry; software/UX/productivity)
- What: Generate multiple plausible variants and select the best via LPRM—e.g., layout planning, menu rotations, meeting/school timetables, seating charts.
- How: “Best-of-N” parallel trajectory sampling with majority vote or LPRM scoring, integrated into internal tools or user-facing interfaces.
- Dependencies: Simple quality signals or verifiers; moderate compute to run N parallel trajectories; calibration of LPRM targets.
- Hybrid solver–neural pipelines (industry/academia; software/AI engineering)
- What: Couple GRAM with search or SAT/SMT solvers—GRAM proposes candidate solutions or variable orderings; a classical solver verifies/refines.
- How: A “neuro-symbolic CSP pipeline” where GRAM’s stochastic guidance explores diverse solution paths; verification ensures correctness.
- Dependencies: Well-specified interfaces between GRAM outputs and solver inputs; interpretable constraint schemas; verifiers to mitigate false positives.
- Educational puzzle and content generation (education; edtech/content)
- What: Generate valid, diverse puzzles (e.g., Sudoku), grading rubrics, or multiple valid solution paths for assignments and exams.
- How: Unconditional GRAM generation for puzzles; conditional GRAM for problem-specific solutions; present top-k variants via LPRM or rule-based filters.
- Dependencies: Content safety checks; quality thresholds; lightweight compute for educators/platforms.
- Small-footprint, high-compute test-time reasoning (industry; on-device/edge)
- What: Deploy compact GRAM models that scale via shared weights and test-time recursion/parallel sampling for local constraint tasks (e.g., embedded scheduling, rule consistency checks).
- How: “On-device recursive reasoner” with adaptive halting (ACT) and width sampling tuned to device budget/latency.
- Dependencies: Efficient runtime kernels for repeated shared blocks; ACT tuning for latency; domain encoders/decoders.
- LLM scaffolding: latent “reasoner” module (industry/academia; software/AI tooling)
- What: Call GRAM as a subroutine from an LLM agent to explore multiple latent hypotheses for structured subproblems, returning the best candidate with a verifier.
- How: A “GRAM tool” in agent frameworks (e.g., LangChain) for CSP-like subtasks (e.g., resource allocation in multi-tool plans).
- Dependencies: API plumbing; prompt-to-structure conversion; verifiers or scoring heads; monitoring for failure modes.
- Risk/scenario generators under constraints (finance/operations; analytics)
- What: Sample diverse, valid scenarios under hard constraints (e.g., budget caps, exposure limits) for planning or stress-testing.
- How: Parallel hypothesized portfolios/plans, filtered by rule-checkers and ranked by LPRM or domain metrics.
- Dependencies: Accurate domain encoders; compliance constraints modeled explicitly; post-hoc validation; compute budget for width.
- Quality control and test case generation (software/MLOps)
- What: Propose multiple test inputs satisfying structural constraints (e.g., boundary cases) to improve coverage.
- How: Unconditional or conditional GRAM to produce structured test artifacts; select/curate via executable checks.
- Dependencies: Formalization of invariants; integration into CI/CD; small compute overhead.
- Hospital/clinic micro-scheduling pilots (healthcare; operations)
- What: Assist with appointment blocks, operating room schedules, or nurse shift rosters where multiple valid schedules exist.
- How: GRAM-generated candidate rosters via width sampling; verification against regulatory/union constraints; human-in-the-loop selection.
- Dependencies: Strong constraint modeling; auditable logs; local validation; privacy/security requirements.
- Inference-time efficiency tuning (cross-sector; AI/infra)
- What: Trade latency for quality by balancing recursion depth and width; use early halting with ACT and LPRM scoring to meet SLAs.
- How: “Depth/width controller” that tunes number of steps and samples per request based on observed difficulty or value thresholds.
- Dependencies: Telemetry and metrics; policy for compute budgets; fallback strategies.
Long-Term Applications
These require further research, scaling, validation, or sector-specific certification beyond the paper’s experiments.
- Clinical decision support with multi-hypothesis reasoning (healthcare)
- What: Maintain differential diagnoses or treatment plans as parallel latent trajectories; present vetted options with uncertainty estimates.
- How: GRAM integrated with EHR and guideline knowledge; width sampling to explore alternatives; verifiers for contraindications.
- Dependencies: Regulatory approval; robust clinical datasets; interpretable outputs; rigorous calibration and safety checks.
- Autonomy and robotics: multi-hypothesis task and motion planning (robotics)
- What: Explore parallel high-level plans under uncertainty (e.g., task sequencing, resource constraints) and feed into motion planners.
- How: GRAM at the symbolic planning layer; LPRM guided by task success proxies; integration with MCTS or trajectory optimizers.
- Dependencies: Tight coupling with low-level planners; real-time constraints; safe exploration policies.
- Supply-chain and grid-level optimization (energy/manufacturing/logistics)
- What: Generate diverse, constraint-compliant plans for production, inventory, or power scheduling with parallel hypothesis evaluation.
- How: GRAM proposes plans; simulators/optimizers verify and refine; width scaling accelerates exploration of the plan space.
- Dependencies: High-fidelity simulators; multi-objective metrics; robust verifiers; significant compute and data integration.
- Generative design and CAD under constraints (manufacturing/construction)
- What: Explore multiple design variants satisfying structural, budgetary, or manufacturability constraints; present ranked portfolios.
- How: GRAM-driven “design space explorer” pipeline, connected to CAD validators and physics/FEA checks.
- Dependencies: Accurate geometry/constraint encoding; slow verifier bottlenecks; human-in-the-loop reviews.
- Proof search and theorem exploration (academia; formal methods)
- What: Multi-trajectory latent exploration of proof strategies, merged with SAT/SMT/ATP systems.
- How: GRAM proposes proof sketches; theorem provers verify; LPRM predicts promise of partial proof states.
- Dependencies: Benchmarks and datasets; symbolic interfaces; interpretability of latent states.
- Portfolio construction and compliance-aware optimization (finance)
- What: Parallel exploration of feasible portfolios or hedging strategies under regulatory and risk constraints.
- How: GRAM plus rule-verification and scenario analysis; width scaling to surface high-quality alternatives.
- Dependencies: Regulatory compliance; accurate risk models; auditability; robust out-of-sample performance.
- Privacy-preserving, constraint-aware synthetic data (public policy/health/finance)
- What: Generate synthetic tabular records satisfying domain constraints and privacy budgets (e.g., DP).
- How: Unconditional GRAM with constraint and privacy-aware post-processing; validators for rule adherence.
- Dependencies: Strong privacy frameworks; coverage of minority modes; evaluation of utility vs. privacy.
- AI tutors with multiple solution strategies (education)
- What: Present alternative valid solution paths to math/logic problems; diagnose misconceptions by exploring likely student trajectories.
- How: GRAM-generated multi-path solutions ranked by pedagogical value; alignment with curriculum standards.
- Dependencies: Curriculum-aligned datasets; explainability; content moderation; fairness across student populations.
- Probabilistic programming and inference engines (software/AI research)
- What: Use GRAM’s recursive latent transitions as a generic inference/computation module within PPLs to navigate combinatorial state spaces.
- How: PPL backends call GRAM to refine latent proposals; LPRM scores partial states.
- Dependencies: APIs for program–model interfaces; stability and convergence analyses.
- Foundation reasoning models with depth–width scaling (AI at scale)
- What: Embed GRAM-like stochastic recursion inside larger models to replace verbose chain-of-thought with compact latent computation and parallel hypothesis exploration.
- How: Hybrid architectures that interleave token-level steps with latent recursive refinements; width-based sampling for robustness.
- Dependencies: Training efficiency (sequential supervision is a bottleneck per the paper); scalable variational objectives; alignment with safety policies.
Key Assumptions and Dependencies (Cross-Cutting)
- Problem formalization: Success hinges on high-quality encoders/decoders that map domain constraints and outputs to/from GRAM’s latent space.
- Verification and safety: For high-stakes domains, external verifiers (rule checkers, simulators, orcertified solvers) must filter candidates; LPRM alone is not a guarantee of correctness.
- Compute budgets: Width-based scaling trades parallel compute for quality; deployments require careful cost–latency management and ACT tuning.
- Data and supervision: Task-specific training data or reliable synthetic generators are needed; transfer to open-ended tasks remains unproven.
- Training efficiency: Current training uses deep supervision with truncated gradients; scaling to very large models will require algorithmic/engineering advances.
- Calibration and interpretability: Multi-hypothesis outputs must be accompanied by uncertainty estimates and human-understandable rationales for adoption in regulated settings.
- Generalization: Results are on controlled benchmarks (Sudoku, ARC-AGI, N-Queens, Graph Coloring, binarized MNIST); real-world performance requires validation on domain datasets.
These applications capitalize on GRAM’s two main innovations—stochastic latent trajectories and width-based inference-time scaling—enabling exploration of multiple hypotheses with compact models and improved constraint satisfaction.
Glossary
- Adaptive computation time (ACT): A mechanism that allows a recurrent model to decide dynamically how many computational steps to perform before halting. "in adopting adaptive computation time (ACT)"
- Amortized variational inference: A training paradigm that uses learned inference networks to approximate posteriors across many inputs, enabling efficient optimization of latent-variable models. "Trained with amortized variational inference, GRAM improves over deterministic recurrent and recursive baselines"
- Autoregressive: Refers to models that generate outputs sequentially, conditioning each step on previous ones. "Large autoregressive models typically scale reasoning by extending a sequence-generation process"
- Binarized MNIST: A version of the MNIST dataset where pixel values are thresholded to binary (0/1), often used for discrete generative modeling. "image generation on binarized MNIST~\citep{mnist}, where pixel values are thresholded to $0$ or $1$"
- Chain-of-Thought (CoT): An approach that has models produce explicit intermediate reasoning steps in natural language. "Latent reasoning aims to reduce the inefficiency and verbosity of explicit Chain-of-Thought (CoT)"
- Conditional distribution: A probability distribution of outputs given inputs, often denoted p(y|x) in supervised modeling. "GRAM models the conditional distribution by marginalizing over stochastic latent reasoning trajectories."
- Conditional Markov processes: Stochastic processes where the next state depends only on the current state (and possibly inputs), used to model latent trajectories. "Both the prior and the posterior are modeled as conditional Markov processes over latent states:"
- Constraint propagation: Iterative enforcement and transmission of constraints throughout a problem’s variables to reduce search space. "requiring extensive constraint propagation"
- Constraint satisfaction: Tasks where the goal is to assign values to variables subject to constraints, potentially with multiple valid solutions. "multi-solution constraint satisfaction tasks"
- Deep supervision: Applying training signals at multiple intermediate stages or steps of a model to stabilize and improve learning. "we train GRAM with deep supervision over $N_{\mathrm{sup}$ consecutive supervision steps"
- Deterministic proposal: A non-random, predicted update to the latent state before adding stochasticity. "the high-level update $f_{\mathrm{H}$ produces a deterministic proposal "
- Discrete diffusion model: A generative modeling framework that diffuses over discrete states and then denoises to sample data. "D3PM~\citep{d3pm}, a discrete diffusion model"
- Evidence lower bound (ELBO): A variational objective that lower-bounds the log-likelihood, optimized to train latent-variable models. "optimized by maximizing an evidence lower bound (ELBO)"
- Fréchet Inception Distance (FID): A metric for assessing the quality of generated images by comparing feature distributions between real and generated samples. "We report IS () and FID ()."
- Generative Recursive reAsoning Models (GRAM): The proposed framework that treats recursive reasoning as a probabilistic, multi-trajectory latent process for both conditional and unconditional generation. "we propose Generative Recursive reAsoning Models (GRAM), a framework that turns recursive latent reasoning into probabilistic multi-trajectory computation."
- Hierarchical instantiation: A design where the latent state is split into multiple levels (e.g., high- and low-level) updated at different time scales. "Hierarchical Instantiation. We instantiate the latent state with two interacting components, ."
- Hierarchical latent dynamics: Multi-level latent state updates that evolve at different granularities to support complex reasoning or representation learning. "reasoning-oriented recurrent designs such as hierarchical latent dynamics."
- HRM: A specific prior recursive reasoning model (Hierarchical Reasoning Model) used as a deterministic baseline in the paper. "Recent recursive reasoning models such as HRM~\citep{hrm} and TRM~\citep{trm} provide early evidence for the potential of this approach in structured reasoning."
- Inception Score (IS): A metric for evaluating generative models by measuring both sample quality and diversity via a pretrained classifier. "We report IS () and FID ()."
- Latent Process Reward Model (LPRM): A value head trained to predict the eventual quality of a trajectory from its latent state to guide selection among sampled trajectories. "best-of-N with a Latent Process Reward Model (LPRM)"
- Latent-variable generative model: A probabilistic model where observed data are generated by integrating over unobserved (latent) variables or trajectories. "This yields a latent-variable generative model supporting conditional reasoning via "
- Latent-variable probabilistic model: A modeling approach that posits hidden variables to explain observed data, optimized via variational objectives. "We model GRAM as a latent-variable probabilistic model "
- Learned prior: A parameterized prior distribution over latent variables conditioned on inputs, used for sampling at inference time. "trajectories are instead generated from the learned prior ."
- Marginalizing (over latent trajectories): Integrating over latent sequences to obtain the conditional likelihood of outputs. "by marginalizing over stochastic latent reasoning trajectories."
- Mode collapse: Failure mode of generative models where outputs lack diversity, collapsing to a few modes. "the deterministic baseline TRM exhibits mode collapse (FID 303.29)"
- Parallel trajectory sampling: Drawing multiple stochastic latent reasoning paths simultaneously at inference to explore diverse solutions. "inference-time scaling through both recursive depth and parallel trajectory sampling."
- Probabilistic multi-trajectory recursion: A design principle where recursive computation is stochastic, maintaining multiple plausible latent paths. "establish probabilistic multi-trajectory recursion as a design principle"
- Reparameterized Gaussian noise: Sampling noise via a differentiable transformation (reparameterization trick) to enable gradient-based training. "adding reparameterized Gaussian noise after a deterministic update "
- Recursive Reasoning Models (RRMs): Architectures that refine a persistent latent state through repeated computation rather than extending an output sequence. "Recursive Reasoning Models (RRMs) offer a promising alternative to autoregressive sequence extension by performing iterative latent-state refinement with shared transition functions."
- State-dependent Gaussian: A Gaussian noise distribution whose mean and/or variance depends on the current state or proposal, enabling learned stochasticity. "samples a conditional perturbation from a state-dependent Gaussian"
- Stochastic guidance: Learnable noise injected into latent updates to encourage exploration and multi-hypothesis reasoning. "We refer to as the learnable stochastic guidance."
- Stochastic latent transitions: Randomized updates of latent states that induce a distribution over reasoning trajectories. "stochastic latent transitions yield substantial gains within the recursive-reasoning paradigm."
- Surrogate objective: An approximate training objective used in place of the exact but expensive or intractable objective to reduce memory or computation. "This gives the following surrogate objective for each supervision step:"
- Truncated gradient propagation: Limiting backpropagation through long computational chains by cutting gradients beyond certain steps to save memory. "we apply truncated gradient propagation"
- Universal Transformers: Transformers with weight-sharing across depth that apply the same block recurrently to increase computational depth. "recurrent Transformer architectures such as Universal Transformers and Looped Transformers"
- Unconditional generation: Sampling outputs without conditioning inputs by modeling p(x), as opposed to conditional p(y|x). "unconditional generation via "
- Variational posterior: An approximate, learnable distribution over latent variables conditioned on observed data used to optimize the ELBO. "we therefore introduce a variational posterior "
- Width-based inference-time scaling: Improving performance by increasing the number of parallel sampled trajectories at inference, rather than only increasing depth. "we introduce width-based inference-time scaling"
- Looped Transformers: A recurrent transformer variant with shared blocks applied iteratively to deepen computation without increasing parameters. "Universal Transformers~\citep{universal} and Looped Transformers~\citep{looped_transformer}"
- Stochastic residual perturbation: A noise addition around a deterministic update that forms the stochastic transition in latent space. "a learned stochastic residual perturbation around a deterministic update"
- Latent reasoning trajectory: The sequence of latent states the model traverses during its internal reasoning process. "GRAM models reasoning as a stochastic latent trajectory"
Collections
Sign up for free to add this paper to one or more collections.

