- The paper identifies Muon’s isotropic spectral whitening as a key deficit in handling low-rank and noisy gradients in VLA and RLVR applications.
- It introduces Pion, a high-pass variant that strategically promotes dominant singular values while suppressing spectral noise to enhance learning stability.
- Empirical evaluations show Pion’s superior convergence speed, robustness, and task performance across simulated and real-world benchmarks.
Rethinking Muon Beyond Pretraining: Spectral Failures and High-Pass Remedies for VLA and RLVR
Introduction and Motivation
The paper "Rethinking Muon Beyond Pretraining: Spectral Failures and High-Pass Remedies for VLA and RLVR" (2605.19282) addresses fundamental limitations of matrix-aware optimizers, focusing on Muon—a spectral optimizer leveraging Newton–Schulz (NS) iterations for momentum matrix orthogonalization. While Muon’s spectral whitening (driving all singular values to 1) is effective in large-scale LLM pretraining, the authors expose its critical shortcomings in two emerging deep learning domains: vision-language-action (VLA) multimodal training and reinforcement learning with verifiable rewards (RLVR). The paper analyzes the spectral origin of these failures and proposes Pion, a high-pass variant of Muon designed to preserve informative singular components and suppress spectral noise.
Spectral Analysis of Muon’s Limitations
Muon’s update mechanism distills to Θt=Θt−1−ηmsign(Mt), where msign maps all singular values of the momentum matrix Mt to one. This isotropic spectral exploration enables strong generalization in LLM pretraining, but the paper thoroughly demonstrates its non-adaptiveness across rank and noise in two key regimes:
1. VLA (Vision-Language-Action):
VLA models are composed of vision, language, and action modules, each characterized by distinct spectral gradient profiles. Empirical analysis reveals that the action module gradients are consistently low-rank; Muon's isotropic whitening amplifies the spectral tail—dominated by noise—leading to suboptimal convergence and poor final task performance.
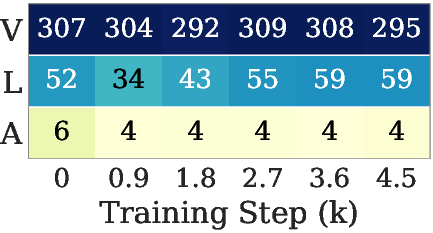
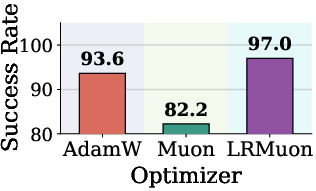
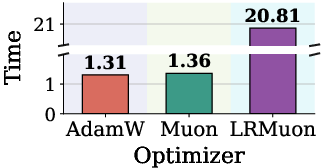
Figure 1: Limitations of Muon in VLA training—gradient effective rank distinguishes vision, language, and action modules, showing action’s persistent low rank.
2. RLVR (Reinforcement Learning with Verifiable Rewards):
RLVR post-training produces low-SNR policy gradients, with informative signal concentrated in a handful of dominant spectral directions. Muon’s uniform whitening, again, elevates noisy components that destabilize fine-tuning and cause rapid model collapse—unlike stable convergence observed with AdamW.
These observations are corroborated by SNR and per-module erank measurements and downstream task success rates, explicitly quantifying Muon’s failure to adapt to non-uniform spectral statistics.
High-Pass NS Remedy: Pion
Motivated by the spectral mismatch, the authors introduce Pion (Spectral High-pass Optimization on Momentum). Pion replaces Muon’s default NS iteration with a two-stage polynomial: Promotion and Suppression. The Promotion stage amplifies leading singular values, anchoring them at one, while Suppression contracts the spectral tail toward zero, implementing a sharp high-pass filter. The coefficients for both stages are derived analytically to enforce fixed points and monotonicity.
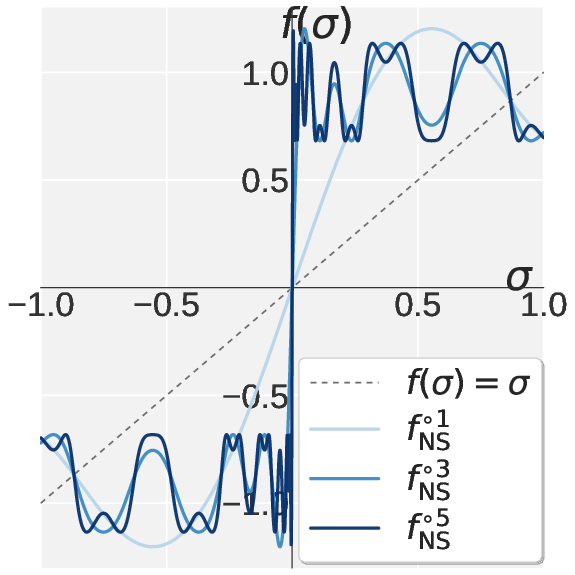
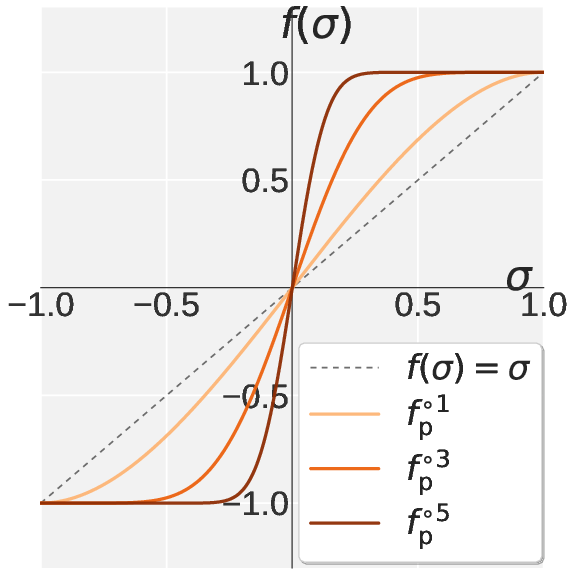
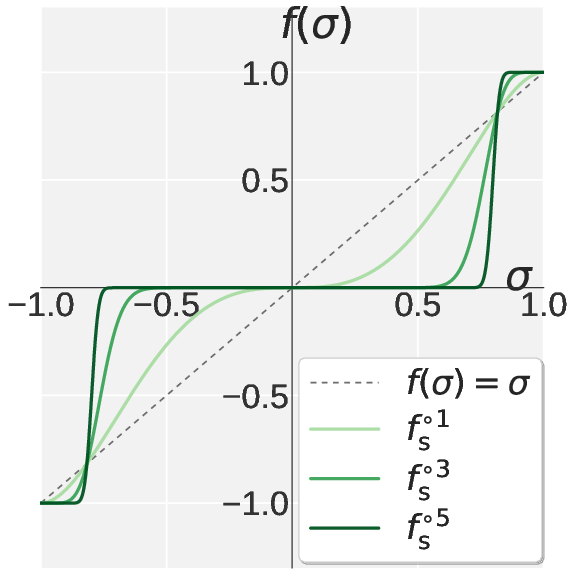
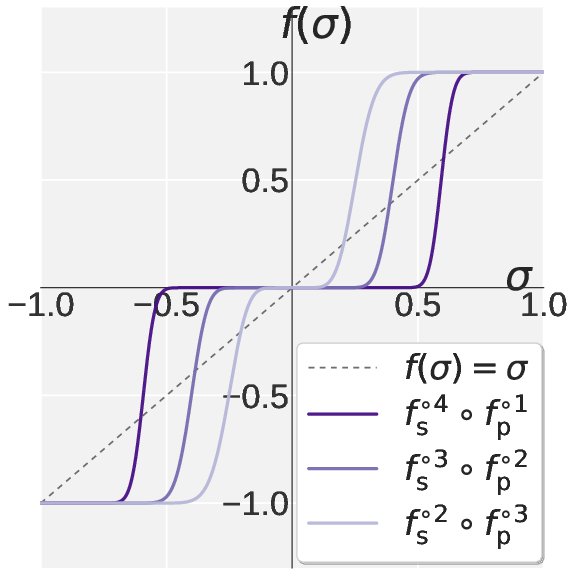
Figure 2: Visualization of the scalar NS polynomial mapping under Muon, Promotion, Suppression, and their composition in Pion, illustrating sharply differentiated spectral filtering.
Pion also supports a per-head mode for transformers: updates are applied independently along attention heads, preserving pretrained heterogeneity critical in RLVR post-training for maintaining headwise specialization.

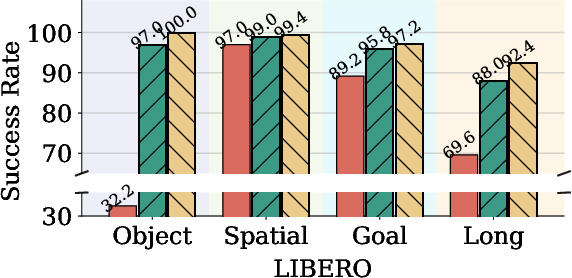
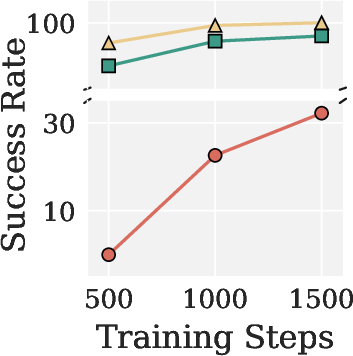
Figure 3: Success rates comparison of AdamW, Muon, and Pion for VLA-Adapter on LIBERO, showing Pion’s pronounced gains and faster convergence across diverse task suites.
Empirical Evaluation and Strong Numerical Claims
Experiments encompass both simulated and real-world robotic VLA settings (LIBERO, LIBERO-Plus, Franka Research 3 robot), and RLVR post-training with GRPO/GMPO on Qwen3-1.7B/4B (MATH, GSM8K benchmarks). Key empirical findings include:
- In VLA-Adapter training, Pion achieves up to 100% success rate in LIBERO Object after 1,500 steps vs. 97.0% for Muon and 32.2% for AdamW, demonstrating both superior convergence speed and final accuracy.
- On challenging perturbations in LIBERO-Plus, Pion shows increased robustness under distribution shifts, outperforming Muon and AdamW in language, noise, and robot variants.
- Real robot evaluation: Pion achieved an 85.6% average success rate in grasp-and-place tasks, compared to 31.1% for AdamW and 38.9% for Muon.
- In RLVR post-training, Muon collapses (zero accuracy), while Pion matches or exceeds AdamW, yielding faster convergence and higher gradient SNR.
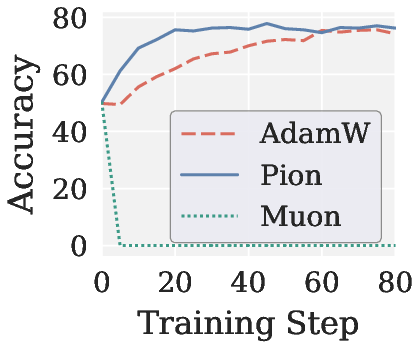
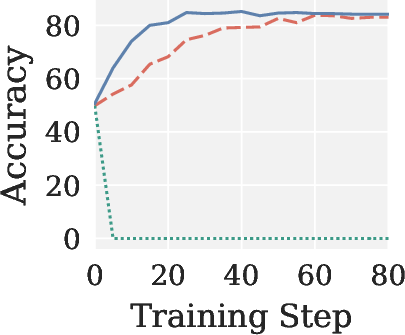
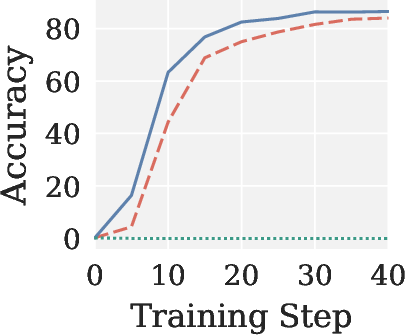
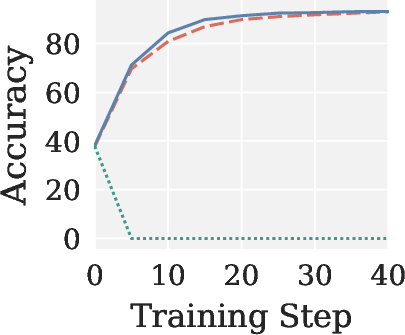
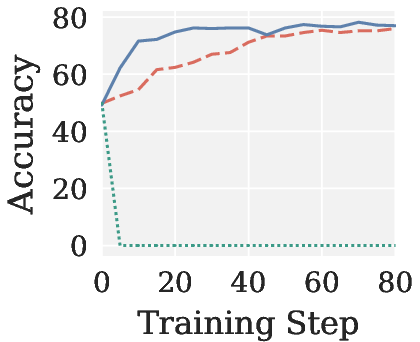
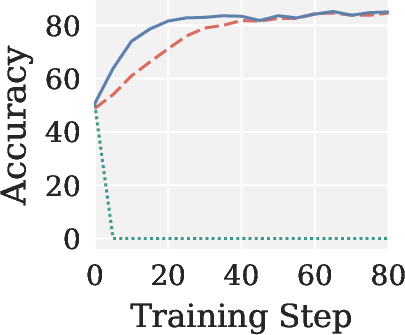
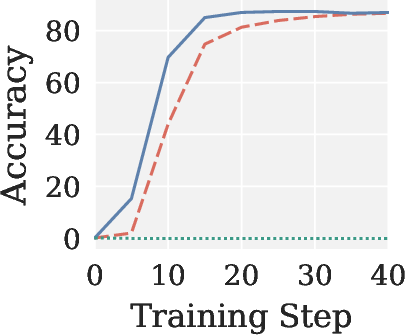
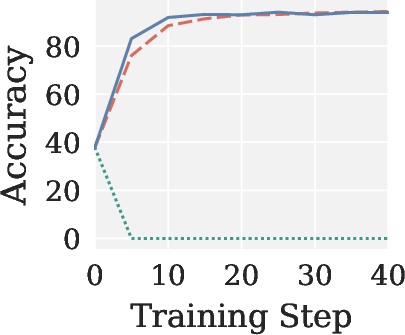
Figure 4: Validation accuracy across RLVR settings, showing Pion’s stability and AdamW-level performance; Muon yields near-zero accuracy in all cases.
Reverse ablation with a low-pass Muon variant confirms that only high-pass spectral shaping enables stable learning in these regimes.
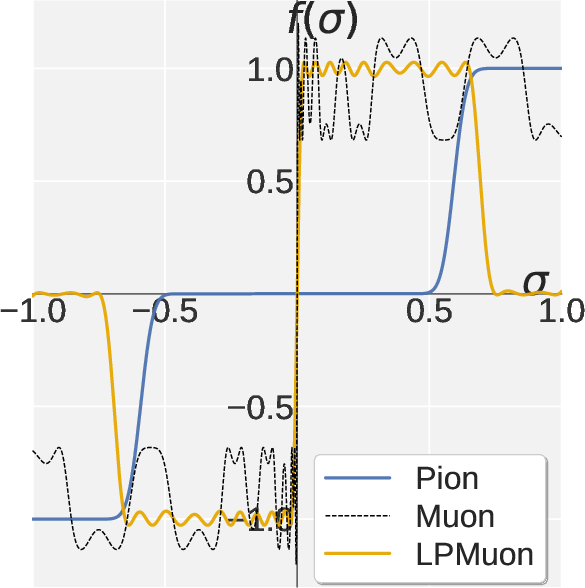
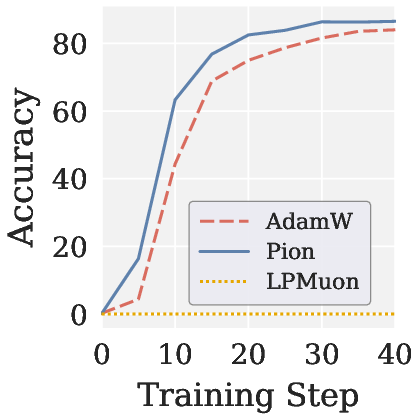
Figure 5: Scalar map of LPMuon (low-pass Muon) and accuracy trends—strong evidence that spectral high-pass (Pion) is necessary for RLVR.
Theoretical and Practical Implications
The study reframes spectral momentum orthogonalization as a flexible polynomial design, directly linking optimizer efficacy to spectral filtering profiles. Practically, Pion delivers adaptive robustness across heterogeneous model modules and noise-prone post-training, without overhead beyond Muon's NS iterations. The per-head mode provides an effective mechanism for respecting pretrained attention head structure, crucial for transformer architectures. These insights portend broader applicability of matrix-aware optimizers in multimodal, reinforcement-driven, and embodied agent contexts.
Conclusion
The paper rigorously details Muon’s spectral failures in VLA and RLVR, attributing them to a universal limitation: indiscriminate spectral whitening that corrupts informative updates in low-rank and low-SNR regimes. Pion’s high-pass NS, analytically derived and efficiently implemented, consistently outperforms both Muon and AdamW across tasks, architectures, and hardware. The findings underpin future advances in adaptive spectral optimization, suggesting further exploration around dynamic cutoff mechanisms, heterogeneity-aware updates, and cross-domain applications of matrix-aware optimizers.