- The paper introduces ZO-MOPI, a novel algorithm that leverages partial spectral orthogonalization to reduce gradient noise in zeroth-order optimization.
- The method uses Streaming Power Iteration to track top-k singular directions, enhancing convergence rates and stability in large language model fine-tuning.
- Empirical results demonstrate that ZO-MOPI outperforms prior baselines, achieving faster convergence and memory efficiency on diverse LLM tasks.
Accelerating Zeroth-Order Spectral Optimization with Partial Orthogonalization from Power Iteration
Motivation and Problem Setting
Zeroth-order (ZO) optimization methods, which rely exclusively on forward function evaluations to estimate gradients, are increasingly important for fine-tuning LLMs in constrained environments. Traditional FO approaches, such as Adam, are memory-prohibitive for edge devices due to the requirement for dynamic storage of activations and gradients. ZO methods such as MeZO allow memory-efficient adaptation by circumventing backpropagation, but they suffer from high gradient estimation variance—especially prominent in the billion-parameter LLM regime.
Spectral optimizers like Muon exploit matrix structure by orthogonalizing gradients, yielding accelerated convergence in FO settings. However, direct application of full orthogonalization (via Newton–Schulz iterations) to ZO-estimated gradients amplifies noise-dominated directions, degrading performance. The spectral distribution of ZO- and FO-estimated gradients reveals this fundamental mismatch; FO gradients concentrate energy in dominant directions, while ZO gradients exhibit a heavier and flatter spectral tail, reflecting high noise (Figure 1).
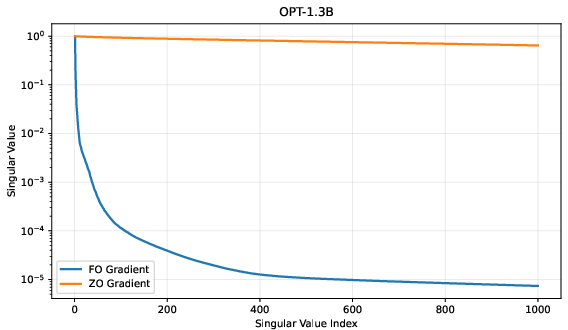
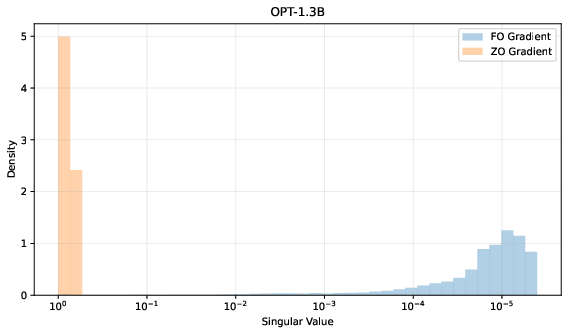
Figure 1: FO vs. ZO gradient spectra on OPT-1.3B fc2 weights, demonstrating energy concentration versus noisy tail.
Partial Orthogonalization via Power Iteration
The central contribution is the ZO-MOPI algorithm, which introduces partial spectral orthogonalization tailored to noisy ZO gradients. The core procedure, Streaming Power Iteration (SPI), efficiently tracks only the top-k dominant singular directions, suppressing high-variance spectral tails. This approach avoids the detrimental noise amplification inherent in full-spectrum orthogonalization.
SPI maintains a cached right singular subspace across iterations, leveraging momentum to ensure temporal continuity and smooth evolution of the dominant directions. Subspace ZO estimation further reduces effective gradient variance: the ZO perturbations are constrained to a low-dimensional subspace defined by projected momentum, dramatically decreasing the search dimension and associated noise.
The theoretical convergence analysis establishes that the algorithm achieves a stationary point with a rate dictated by the reduced subspace dimension. The tracking error of the dominant subspace remains bounded under smooth drift assumptions, supported by matrix perturbation theory.
Algorithmic Integration and Ablations
ZO-MOPI combines three components: subspace ZO gradient estimation, projected momentum accumulation, and SPI-based partial orthogonalization. The streaming nature of SPI (warm-starting with cached singular vectors) necessitates momentum for stability; without it, subspace drift causes instability, as empirically demonstrated. Lazy (periodic) subspace sampling is vital—overly frequent refreshes destabilize spectral tracking and degrade convergence.
Hyperparameter studies (Figures 5 and 6) reveal the tradeoff in spectral and subspace rank choices. Too small k or r loses essential information; too large k or r incorporates noise, impairing accuracy and slowing final convergence.
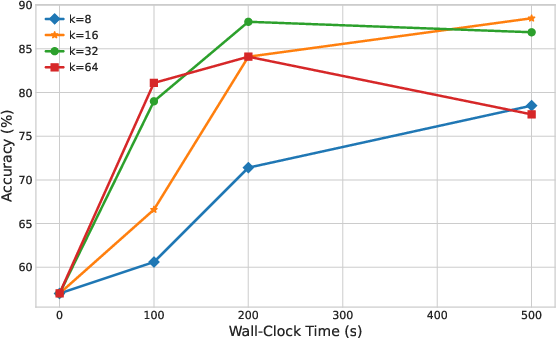
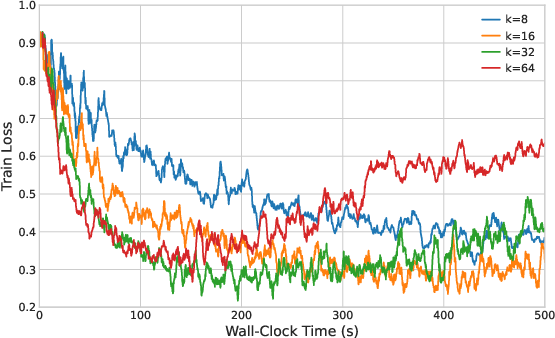
Figure 2: Impact of spectral rank k on OPT-1.3B SST-2; intermediate k balances signal extraction and noise suppression.
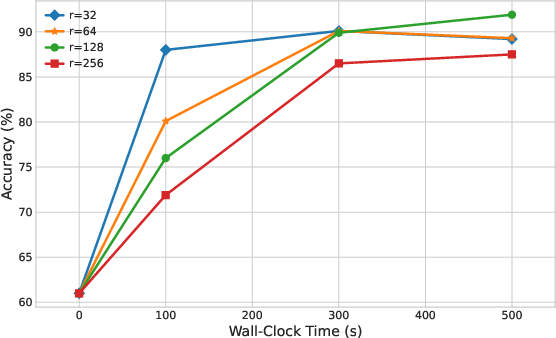
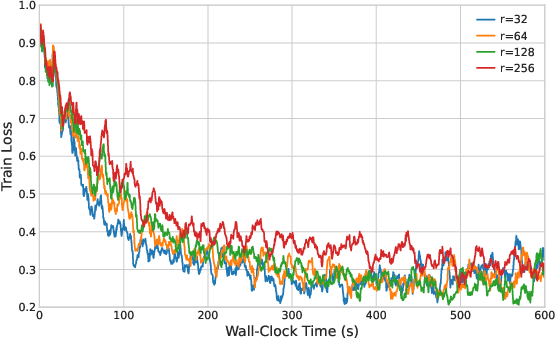
Figure 3: Impact of subspace rank r on OPT-2.7B SST-2; moderate r optimizes spectral coverage and variance reduction.
ZO-MOPI demonstrates substantial acceleration compared to prior ZO baselines (MeZO, LOZO, ZO-Muon). On multiple SuperGLUE tasks and LLMs (OPT-13B, Gemma2-2B, LLaMA3-8B), ZO-MOPI consistently achieves competitive or superior final accuracy in significantly less wall-clock time.
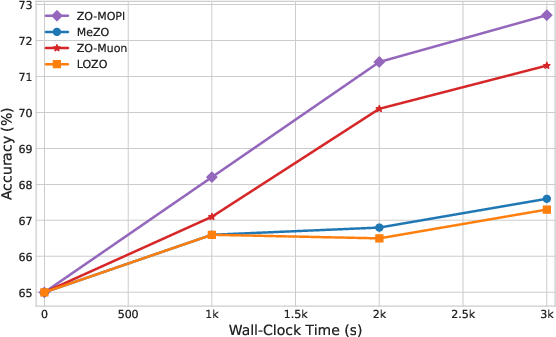
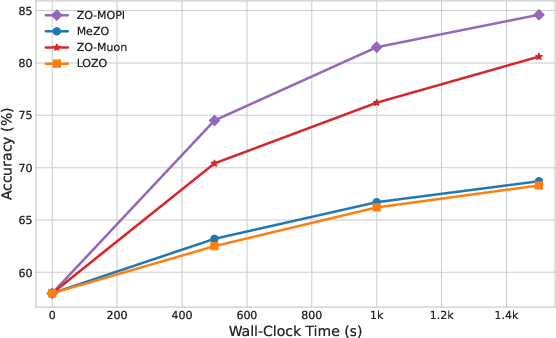
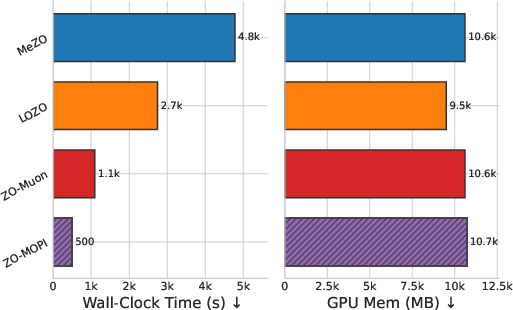
Figure 4: Gemma2-2B fine-tuning on BoolQ/SQuAD and SST-2: ZO-MOPI reaches strong accuracy faster, with memory efficiency.
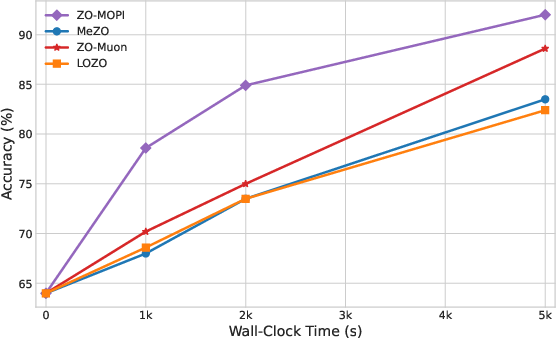
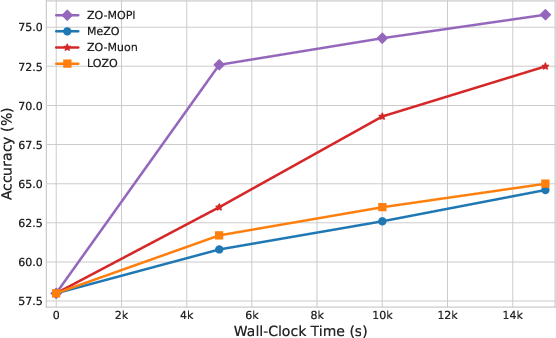
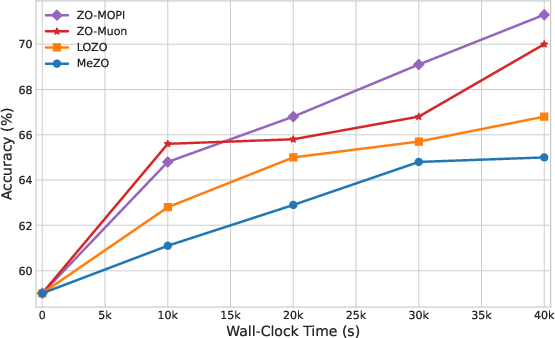
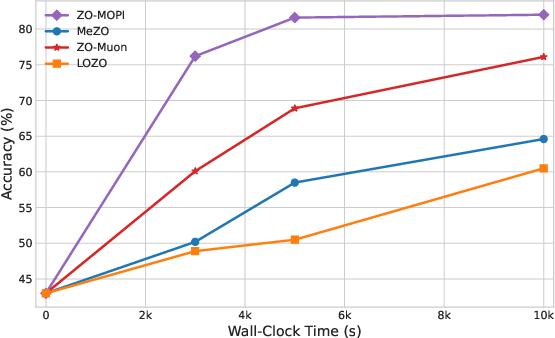
Figure 5: OPT-13B fine-tuning efficiency (Accuracy vs. Time) on four SuperGLUE tasks: ZO-MOPI converges rapidly.
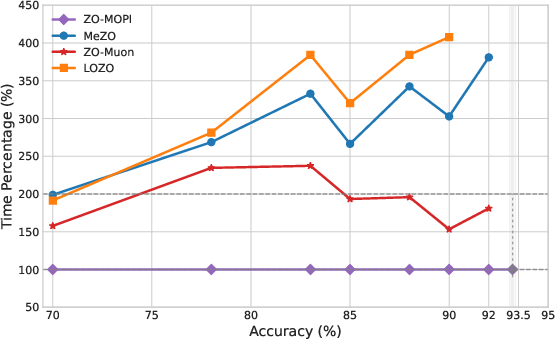


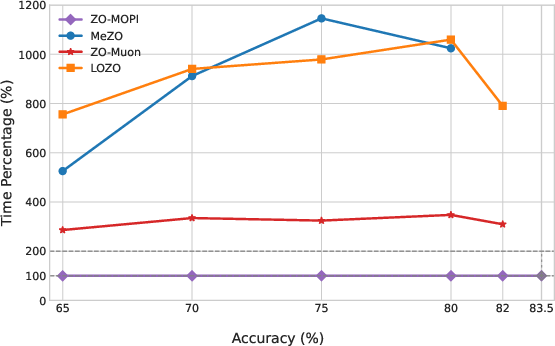
Figure 6: OPT-13B relative time-to-same-accuracy: ZO-MOPI outpaces baselines, especially ZO-Muon, by large margins.
Training/evaluation loss curves across LLMs confirm faster, more stable optimization dynamics with ZO-MOPI (Figures 7–12).
ZO-MOPI maintains negligible memory overhead relative to the full parameter matrices, as confirmed in runtime/memory benchmarks. The low-rank momentum and subspace tracking state add only rn+nk memory, with r,k≪min(m,n).
Practical and Theoretical Implications
Partial orthogonalization dramatically improves ZO gradient exploitation in high-dimensional matrix settings, bridging the gap between low-variance FO optimization and practical ZO approaches. By aligning the optimizer with the spectral structure of ZO gradients and concentrating updates in robust directions, ZO-MOPI fosters rapid convergence—an essential property for scalable, resource-constrained LLM fine-tuning.
The theoretical guarantees on convergence in reduced subspaces, and robust empirical evidence across diverse tasks and models, suggest the viability of spectral ZO algorithms for parameter-efficient adaptation beyond edge scenarios. Future directions include extending spectral techniques to generalized large-scale training, integrating low-rank adaptation and spectral anisotropy further, and refining spectral tracking mechanisms for nonstationary regimes.
Conclusion
ZO-MOPI proposes partial spectral orthogonalization coupled with streaming power iteration to accelerate ZO optimization for LLMs, selectively amplifying dominant directions while suppressing noise. Comprehensive evaluation establishes strong empirical and theoretical efficiency, outperforming stateful ZO baselines in both speed and accuracy while retaining low memory complexity. The framework provides a foundation for advanced spectral ZO methods applicable to broader large-scale, resource-agnostic training settings.