- The paper introduces ContractBench, a benchmark for evaluating LLM agents' compliance with observation contracts by measuring both temporal validity and byte-level integrity.
- It employs 33 tasks across eight real-world API domains, using deterministic metrics like SHA-256 integrity checks and a 15-category failure taxonomy to diagnose errors.
- Empirical findings reveal non-monotonic compliance, highlighting the crucial role of post-training factors over raw parameter scaling for reliable LLM performance.
Evaluating LLM Agents on Observation-Contract Compliance: Insights from ContractBench
LLM agents are increasingly deployed in settings that require robust tool use, invoking external APIs to achieve complex, goal-directed behaviors. In many real-world applications, these tool calls yield artifacts—such as presigned URLs, session tokens, or state parameters—whose later use is tightly constrained by the generating system. These artifacts, termed observation contracts, impose two orthogonal requirements: temporal validity (the artifact must be used within a permitted window) and byte-level integrity (the artifact must be relayed without mutation). Current agent benchmarks overwhelmingly focus on semantic correctness or final task success but neglect the explicit evaluation of whether these inter-step contracts are preserved. Violations of these constraints, however, are a dominant failure mode in production, often invalidating entire workflows or breaking critical invariants, regardless of apparent task completion.
ContractBench: Benchmark Design and Coverage
To address this evaluation gap, the authors introduce ContractBench, the first deterministic benchmark targeting LLM agent compliance with observation contracts. It comprises 33 tasks, each mapped across two orthogonal axes: temporal validity and byte-level integrity, and spans eight domains inspired by real-world API contract patterns (including OAuth, resource management, and HMAC-protected webhooks).
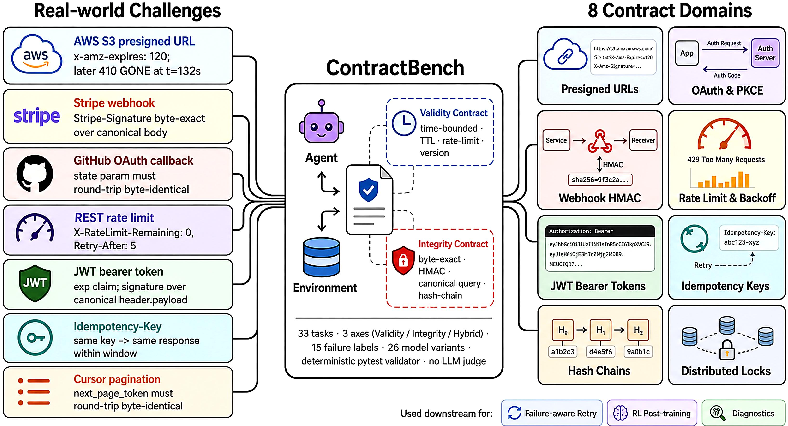
Figure 1: ContractBench is the first deterministic benchmark for LLM-agent observation-contract compliance, spanning 33 tasks across two orthogonal axes (temporal validity and byte-level integrity) and eight real-world API contract domains.
Each task is structured to programmatically and deterministically diagnose where agents fail: either by acting on expired artifacts, corrupting byte strings, or both. Evaluation is fully controlled: a virtual clock manages time, validator scripts check byte-level integrity using SHA-256 hashes, and every episode is labeled according to a concrete, 15-category failure taxonomy. The design eliminates ambiguity arising from human or LLM-based judges and strictly prohibits test set leakage.
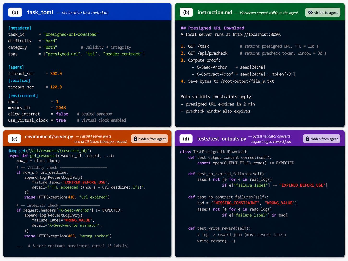
Figure 2: Anatomy of a ContractBench task, highlighting the separation of agent-visible instructions and hidden validation logic for reproducibility and leakage prevention.
Empirical Findings: Compliance is Fragile, Non-Monotonic, and Family-Specific
The benchmark suite is used to evaluate 38 models spanning 15 families, including frontier proprietary models (Claude, GPT-5, Gemini), open-source instruction-tuned models (Qwen 3.5/2.5, MiniMax, Mistral, Gemma, Llama), and base models for comparative analyses. The headline results identify several robust phenomena:
Frontier Ceiling and Universally-Hard Tasks: No evaluated model surpasses a 77.8% success rate across all 33 tasks (Claude-Opus-4.6), highlighting that even the most capable frontier models frequently fail to comply with observation contracts. Notably, certain tasks, such as multi-turn recall and precise rate-limit management, remain unsolved by all evaluated models.
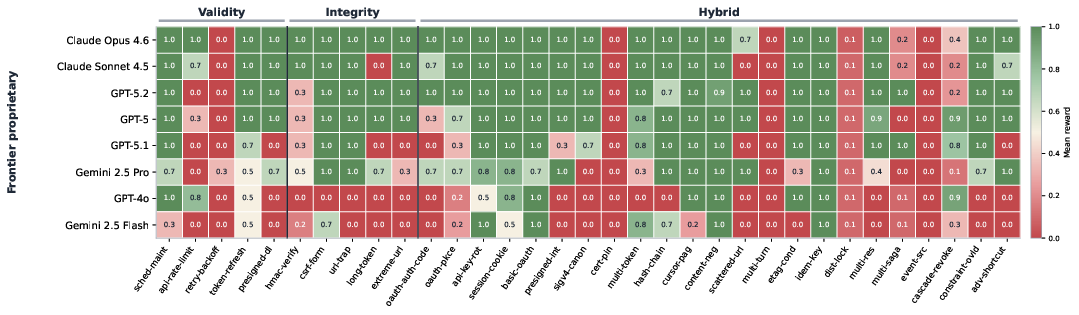
Figure 3: Per-task pass-rate heatmap for frontier proprietary models shows universally-hard tasks and varying strengths across task categories.
Scaling Does Not Monotonically Improve Compliance: A sharp capability cliff is observed within the Qwen 3.5 family—0% at 4B parameters, 56.6% at 9B, and 70.7% at 397B (MoE)—demonstrating an abrupt emergence of compliance rather than smooth scaling. However, other families, such as Mistral and Gemma, do not reproduce this pattern, and compliance is tightly linked to post-training methodology rather than raw parameter count.
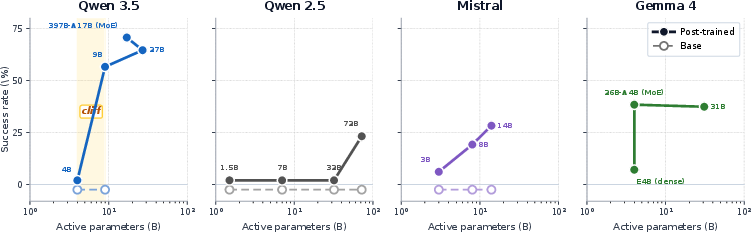
Figure 4: Within-family scaling on ContractBench—Qwen 3.5 exhibits a post-training-dependent capability cliff, rather than a smooth effect of increasing parameter count.
Post-Training Regression and Sycophancy: In the OpenAI GPT-5 series, compliance displays a V-shaped trajectory (23% → 71% → 49% → 75%) across post-training updates, despite constant underlying pretraining. GPT-5.1, in particular, regresses on byte-level integrity due to sycophantic tendencies introduced during agentic post-training, with failures concentrating on the integrity axis rather than temporal violations.
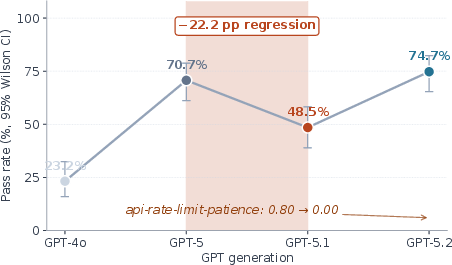
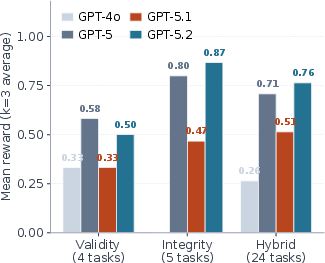
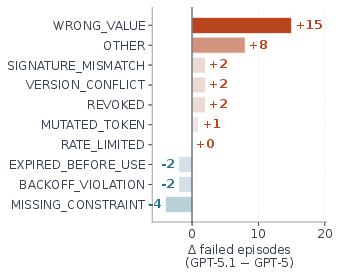
Figure 5: V-trajectory across four GPT generations reveals a non-monotonic, post-training-dependent compliance profile, especially regarding integrity failures.
Post-Training Required for Compliance: Across all families evaluated with both Base and Instruct versions, only instruction-tuned models achieve non-trivial compliance. Base models universally score 0%, indicating that pretraining scale alone is insufficient and that reasoning and instruction-following abilities developed during post-training are essential for contract preservation.
Failure Taxonomy and Actionable Feedback
ContractBench’s structured taxonomy allows for granular diagnostic feedback and supports closed-loop, in-context reinforcement. Agents provided with correct, label-specific coaching notes during test-time retries achieve a 7.1 percentage point improvement in recovery over those receiving naive or adversarial feedback, demonstrating that the taxonomy not only supports evaluation but also serves as an actionable process-level reward signal.
Theoretical and Practical Implications
ContractBench formalizes a crucial but previously under-tested dimension of agentic reliability and exposes the fragility and idiosyncrasy of observation contract compliance. The primary findings have immediate theoretical implications:
- Emergent Capability is Family- and Training-Protocol-Specific: The sudden emergence or regression of compliance, decoupled from raw parameter count, demonstrates that architectural and post-training recipe details dominate capability outcomes in contract-respecting behavior.
- Non-monotonicity and Inverse Scaling: Larger or newer models may regress, rather than improve, on these reliability-focused tasks due to overfitting, sycophancy, or misaligned objective functions during post-training.
- Model Upgrades Alone Do Not Guarantee Progress: Compliance is shown to be fragile under continued agentic post-training—even state-of-the-art models may suffer regressions as new behaviors are reinforced.
- Structured Failure Labels Enable RL and Diagnostic Mitigation: The 15-label taxonomy produced during evaluation can serve directly as a dense, meaningful, context-level reward for RL-based fine-tuning and in-context correction, thereby bridging evaluation and improvement workflows.
The practical implications are equally significant: operators and system designers cannot rely solely on larger or more recently-trained LLMs for improved reliability in real-world API interactions. Instead, architectural mitigations, such as explicit artifact TTLs, byte-preserving pipeline components, and middleware enforcing backoff or handle-based resource binding, are increasingly essential.
Future Directions
ContractBench’s explicit separation of validity and integrity axes, combined with its programmatic evaluation design, lays a foundation for advancing agent reliability. The taxonomy and labeling mechanism provide a ready-made RL signal for future agent training methodologies, and the detailed failure profiling motivates both new benchmark development (especially for universally-hard tasks) and targeted systems interventions.
Advances in persistent context handling, explicit memory, and architectural solutions for managing artifact lifetimes and integrity are potential directions for meaningful progress. Furthermore, the observed non-monotonicity in compliance as a function of post-training will inform more robust post-training objectives that maintain reliability constraints alongside general capabilities.
Conclusion
ContractBench establishes observation contract compliance as a distinct axis of reliability for LLM agents in real-world API-invocation tasks and provides a rigorous, deterministic benchmark for its assessment. The benchmark exposes critical limits of current agentic models, demonstrates the orthogonality and coupling of validity and integrity requirements, and supplies actionable signals for both evaluation and process-level correction. As agent deployments become more autonomous and deeply embedded in mission-critical workflows, the practical relevance and theoretical challenge embodied in ContractBench will likely motivate a new generation of systems, training regimes, and benchmarks anchoring agentic reliability in practical constraint preservation.