- The paper demonstrates that iterative audits using sub-agent LLMs reveal hidden prompt-specification defects across multi-agent system documents.
- It employs a seven-dimensional checklist and evolving audit protocol to detect both structural and semantic inconsistencies.
- The study shows that cross-file, iterative reviews reduce defect density and improve prompt engineering quality assurance.
Iterative Agent-Driven Audit Convergence in LLM-Orchestrated Multi-Agent Systems
Introduction and Context
The paper "Iterative Audit Convergence in LLM-Managed Multi-Agent Systems: A Case Study in Prompt Engineering Quality Assurance" (2605.12280) presents an empirical study of iterative structured auditing applied to prompt specifications in a production multi-agent pipeline managed by LLMs. The central focus is the AEGIS (Autonomous Engineering Governance and Intelligence System) orchestration pipeline, comprising seven autonomous lanes coordinated via prompt specification files (PROMPT.md) and a shared Ticket Contract, totalling roughly 7150 lines across eight files. Prompt specifications, increasingly treated as behavioral contracts in agentic architectures, often lack rigorous inspection workflows akin to software code review, creating vulnerability to integration inconsistencies.
Structured inspection traditions from classical software engineering (e.g., Fagan-style code inspection, checklist walkthroughs) are adapted for prompt engineering. The study operationalizes an iterative audit workflow using sub-agent LLMs (Claude), follows a seven-dimensional checklist, and integrates successive defect remediation, jointly evolving the audit protocol. The methodology aligns with case-study conventions and articulates precise research questions: (RQ1) defect classes emergent only via iterative expanded-scope review; and (RQ2) convergence behavior across audit rounds in a real-world specification surface.
Audit Methodology and Protocol Evolution
Each audit round spawned LLM sub-agents with access to one or more specification documents. Early rounds executed strictly per-file audits, while later rounds incorporated cross-lane context, enabling explicit contract validation and producer-consumer schema analysis. The review protocol encompassed version consistency, cross-lane data contract alignment, Jira boundaries, label conventions, lane-count propagation, cadence/scheduler alignment, and internal contradiction checks. Findings were structured with precise line references and category assignments. Defects were remediated between rounds, and verification greps tracked applied fixes.
Context loading evolved: rounds 1–2 saw single-file audits, rounds 3–5 introduced partial cross-lane comparison, and rounds 6–9 achieved full-scope multi-file visibility. The audit terminated after round 9 yielded a clean pass (operationally, zero findings), though the recommending protocol (locked post-study) prescribes stricter fixed-point criteria (e.g., two consecutive clean passes).
Audit Convergence Dynamics and Defect Discovery
The audit process surfaced 51 prompt-specification consistency defects across nine rounds, with per-round counts exhibiting pronounced non-monotonicity: 15, 8, 12, 2, 8, 1, 4, 1, and 0. Early rounds remediated structural issues and version drift; later rounds exposed semantic inconsistencies, cross-lane schema mismatches, and contract gaps—defect classes undetectable by single-file review.
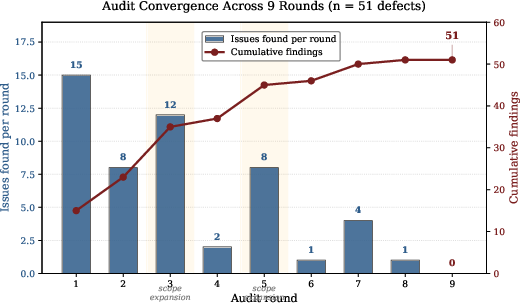
Figure 1: Audit convergence across nine rounds. Bars show per-round defect counts; the line displays cumulative defect discovery with scope expansion highlighted.
Scope expansion in rounds 3 and 5 correlated with increased defect surfacing after structural fixes enabled deeper checks. Cascading edits were directly observed, where remediating one inconsistency exposed previously masked inconsistencies in other documents, analogous to regression introduction in code inspection.
Defect Taxonomy and Severity Distribution
A seven-category post-hoc defect taxonomy was devised: version drift (17.6%), stale Jira references (23.5%), cross-lane schema mismatches (9.8%), missing recent-extension coverage (13.7%), label/contract gaps (11.8%), semantic misleading text (15.7%), and formula/timing drift (7.8%). All cross-lane schema mismatches were coded as high severity, due to their potential for silent runtime failure.
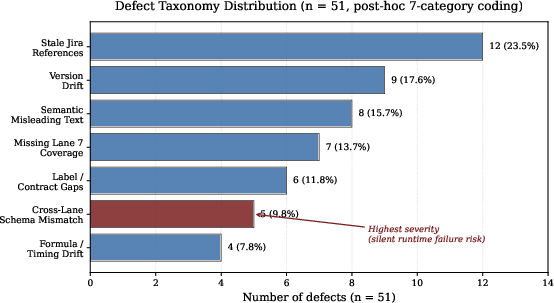
Figure 2: Defect taxonomy distribution (n = 51). Cross-lane schema mismatch is author-coded highest severity.
Structural, operational, and semantic defects manifested early, while high-severity schema mismatches and formula drift surfaced in later, full-scope rounds. This progression emphasizes the necessity of multi-file and iterative review for surfacing integration defects.
Defect density, at ~7.1 defects per thousand lines, offers a magnitude reference but is not directly comparable to historical code-inspection metrics without normalization for artifact type and inspector variance.
Category Progression Across Audit Rounds
Defects cross-tabulated by audit round reveal concentrated resolution of version drift and stale Jira references in rounds 1–3. Semantic misleading text was dominant in round 3, and cross-lane schema mismatches emerged exclusively from round 4 onwards, coinciding with expanded audit scope.
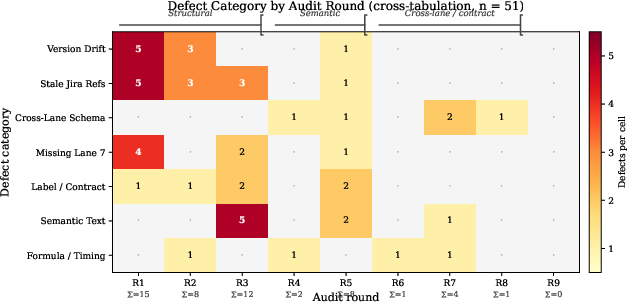
Figure 3: Defect category by audit round; phase brackets delineate structural, semantic, and cross-lane/contract audit phases.
This phase-bracketed progression underscores limitations of single-file review; only iterative, scope-expanding audits could resolve contract-level integration errors.
Practical and Theoretical Implications
Prompt specifications as behavioral contracts: The study reinforces engineering positions advocating promptware lifecycle rigor (2503.02400), emphasizing prompt artifacts as first-class code deserving structured inspection. Data contracts and inter-lane communication schemas embedded in prompt files require full-scope consistency validation.
Audit protocol design for agentic systems: Single-file review is categorically insufficient for surfacing cross-document defects. Iterative, full-scope, checklist-driven audits are recommended. The audit protocol itself must be co-evolved and locked post-discovery to avoid prompt-tuning bias.
Specification drift and aging: Documentation accuracy degrades as specification surfaces evolve, mirroring classical software aging [parnas1994software]. Semantic inconsistencies outlast structural fixes, and specification-aging demands persistent quality gates beyond automated greps.
Replication requirements: The case-study limitations are explicit: same LLM family authored and audited the specifications; taxonomy is single-coder and post-hoc. Generalizability mandates replication across architectures, LLMs, and human reviewers, preferably with locked audit prompts, fixed protocol, and inter-rater taxonomy validation.
Agentic QA and multi-agent system robustness: The findings are consistent with recent literature documenting failure modes in multi-agent LLM systems (Cemri et al., 17 Mar 2025), and with benchmarking efforts on repository-level reasoning and contract validation (Li et al., 7 Jan 2026). The study extends agentic QA discourse with production-deployment evidence, not synthetic benchmarking.
Future Directions
- Protocol standardization: Audit checklists and convergence criteria should be codified for promptware quality assurance, with artifact release for reproducibility and inter-rater validation.
- Cross-agent diversity: Stronger replications should leverage auditor LLMs dissimilar from specification authors, and human-auditor teams, to minimize shared-blind-spot bias.
- Runtime integration: Specification-layer audit must be complemented by runtime validation and adversarial testing to ensure both internal consistency and operational correctness.
- Benchmark development: Synthetic mini-specifications with seeded defects could serve as ground truth for protocol evaluation and taxonomy reliability measurement.
- Holistic governance: Prompt audits should be integrated within broader agentic governance frameworks (e.g., MANDATE, LATTICE, TRACE), supporting traceability and contract assurance across evolving orchestration pipelines.
Conclusion
This case study empirically demonstrates that iterative, multi-agent, full-scope auditing is necessary to surface and remediate specification-layer defects in LLM-orchestrated multi-agent systems. Single-file review categorically misses cross-document contract issues. Audit convergence is non-monotonic, shaped by cascading edits and scope expansion. The locked audit protocol and taxonomy, while bounded to this case, crystallize operational recommendations for prompt engineering QA and underscore the necessity of fixed-point iterative review. Future replications, incorporating architectural diversity, independent auditors, and runtime contract validation, are required to substantiate the generalizability of these findings and to evolve agentic QA methodology for prompt-driven systems.

