- The paper introduces a normalized energy-based model that directly evaluates posterior probabilities for a range of linear inverse tasks.
- It leverages anisotropic noise modeling with covariance-conditional energy functions, enabling unbiased sampling and uncertainty quantification.
- Empirical results demonstrate superior PSNR, LPIPS, and FID scores in tasks like inpainting and super-resolution with flexible autoregressive sampling.
Learning Normalized Energy Models for Linear Inverse Problems
Motivation and Problem Setting
Generative modeling using diffusion-based methods has achieved considerable success in high-dimensional image synthesis. While score-based and diffusion models have become powerful priors for solving inverse imaging problems, prevailing approaches encounter two fundamental barriers: (1) the prior density is implicitly represented and thus cannot be directly evaluated or normalized, and (2) Bayesian methods that approximate the posterior require restrictive or inaccurate likelihood models, which induce sampling bias and preclude unbiased uncertainty quantification. This work addresses these limitations by proposing a unified framework wherein an explicit and normalized energy-based model (EBM) is trained to act as a posterior for a range of linear inverse problems. The approach leverages a connection between linear degradations and anisotropic denoising, and introduces a regularization that guarantees normalization across varying noise structures.
Anisotropic Energy-based Modeling
The core insight is that linear inverse problems can be transformed into denoising with structured (anisotropic, correlated) noise. For a given linear degradation operator H and observed measurement y=Hx+σϵ, the posterior over x conditioned on y can be recast as a denoising problem with additive colored noise of covariance Σ determined by H and σ. By training a covariance-conditional energy function Uθ(y,Σ) to encode −logp(x∣y), the model enables direct evaluation and sampling of the posterior across a wide range of linear degradations without retraining.
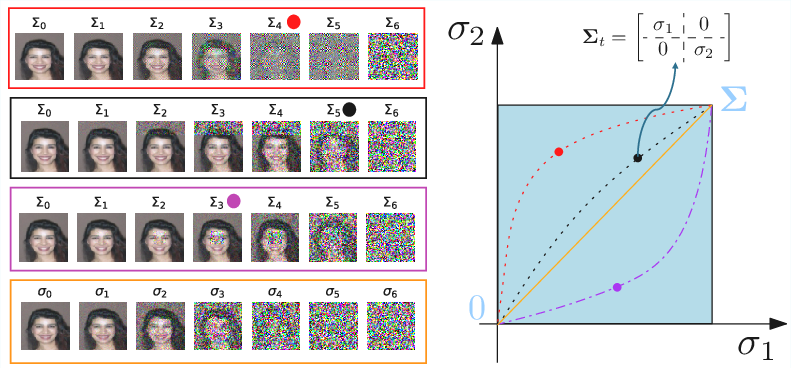
Figure 1: Illustration showing anisotropic models allow diverse paths in covariance space, where signal components are noise-corrupted at different rates, in contrast to isotropic models.
A crucial extension is to allow the forward process in diffusion models to be governed not just by scalar (isotropic) noise schedules, but by general covariance matrices that may differ across tasks (e.g. inpainting, deblurring, super-resolution). This "anisotropic" noise modeling leads naturally to the conditioning of the energy model on the covariance.
Dual Score Matching and Normalization
Training the EBM employs an anisotropic generalization of dual-score matching. The first score (data score) matches the gradient of the energy with respect to the noisy input, akin to the denoising score matching objective in conventional diffusion models. The second (covariance score) matches gradients with respect to the entries of the covariance, thus regularizing the energy over the space of noise schedules. The covariance score regularizer enforces consistency with the Fokker–Planck equation governing the evolution of the marginalized densities – a property unavailable in existing isotropic or regression-based frameworks. This dual objective guarantees that normalization constants become independent of the specific covariance, enabling absolute and comparable likelihood evaluations.
The final objective combines both terms (weighted appropriately by the ambient dimension) and ensures, after training, that Uθ(y,Σ) is normalized such that probabilities are comparable across covariances.
Model Architecture and Conditioning Mechanisms
y=Hx+σϵ0 is parameterized as a quadratic form where the score component is realized via a modern UNet backbone. Covariance conditioning is introduced via two branches: one each for covariances diagonal in spatial and in spectral domains, covering a wide range of canonical imaging operators (spatial masks for inpainting, frequency diagonal for blurring, etc.).
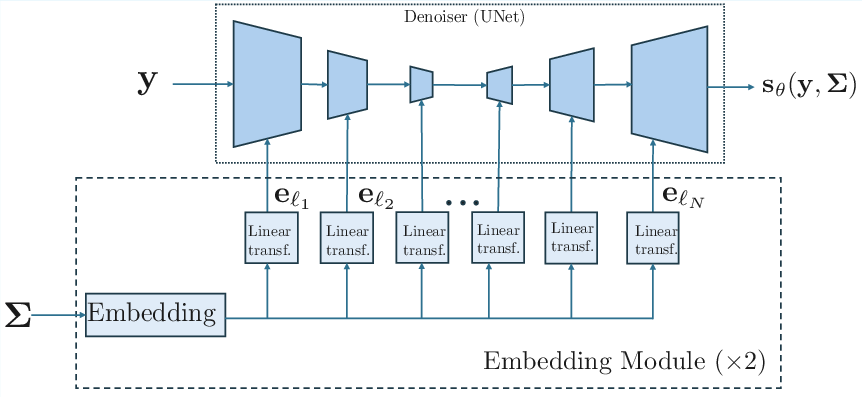
Figure 2: UNet-based architecture with novel embedding modules for injecting spatial and spectral covariance information.
The covariance embeddings are incorporated multiplicatively into each UNet layer, by embedding the covariance parameters and broadcasting them to appropriate spatial or frequency dimensions. This mechanism introduces negligible overhead compared to isotropic conditioning.
Empirical Evaluation and Numerical Results
The model is validated on standard image datasets (CelebA, ImageNet, AFHQ-Cat, MNIST) and various inverse problems (inpainting, deblurring, super-resolution). The EBM achieves competitive or superior PSNR, LPIPS, and FID scores compared to strong Bayesian (DPS, DAPS, RED-Diff) and conditional regression baselines. Notably, a single unified model handles all considered degradation types without retraining.

Figure 3: CelebA inpainting qualitative results show that the proposed approach and DPS produce sharper completions compared to RED-Diff.
Direct comparison of the log-probabilities of posterior and prior samples, using the learned energy, shows the method yields well-calibrated densities, with generated images distributing probability mass consistent with both the prior and evidence.
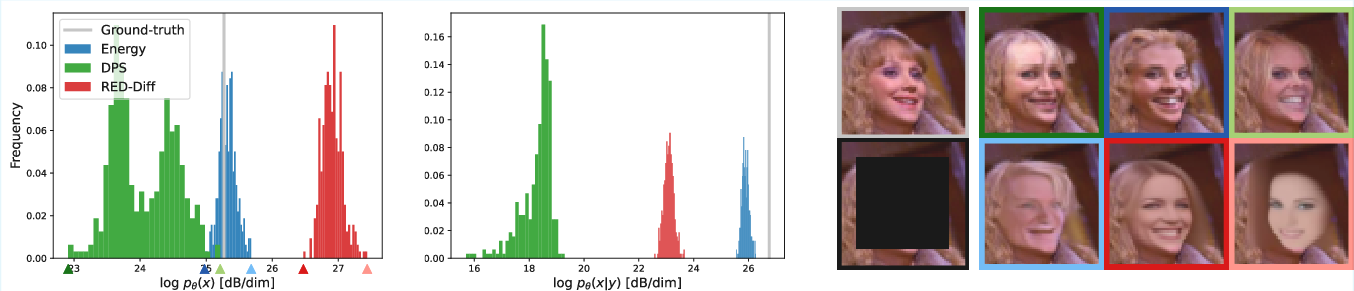
Figure 4: Left/middle: Histogram of log-likelihoods over samples; right: image examples sorted by decreasing prior probability. Smoother, less detailed images have higher probability as expected.
Autoregressive and adaptive-schedule sampling is enabled by the explicit dependence of y=Hx+σϵ1 on the covariance, allowing sampling of measurements, pixels, or patches in arbitrary order or with adaptive unmasking rates. Empirically, for sparse inverse tasks (e.g. MNIST inpainting), an energy-guided adaptive sampler outperforms fixed geometric schedules, significantly reducing classification error as the number of observations grows.



Figure 5: Three sampling orders for autoregressive patch-based generation, highlighting flexibility of ordering in the framework.
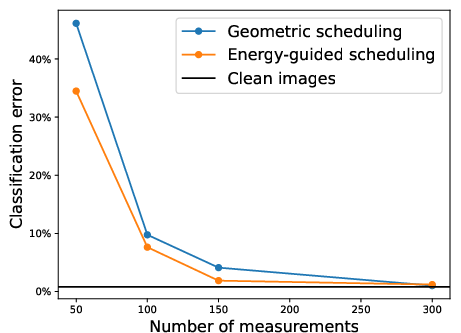
Figure 6: The energy-guided adaptive schedule has lower classification error than geometric schedules in sparse pixel observation tasks.
The model supports unbiased Metropolis-adjusted Langevin corrector steps (MALA) due to direct access to the normalized energy; increasing the number of corrector steps yields consistent gains—a property unavailable to prior non-normalized or regression approaches.
Blind Operator Estimation
Because the energy is normalized across covariances, the framework enables blind estimation of the unknown noise covariance or degradation operator by maximizing y=Hx+σϵ2. Empirical results validate that the method accurately recovers both the structure and scale of measurement noise without supervised information.

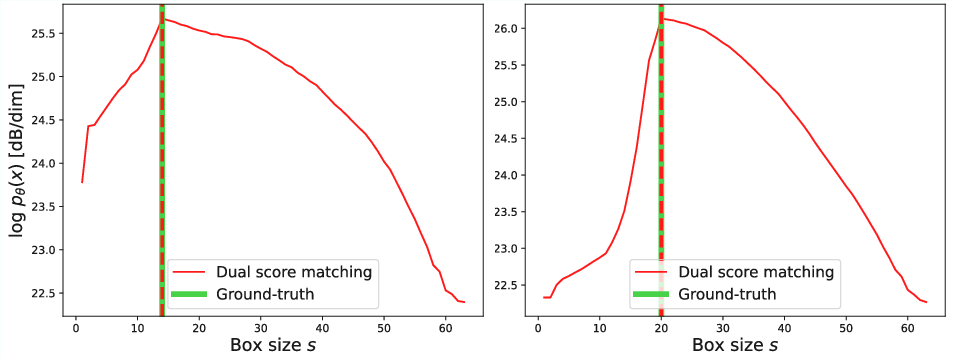
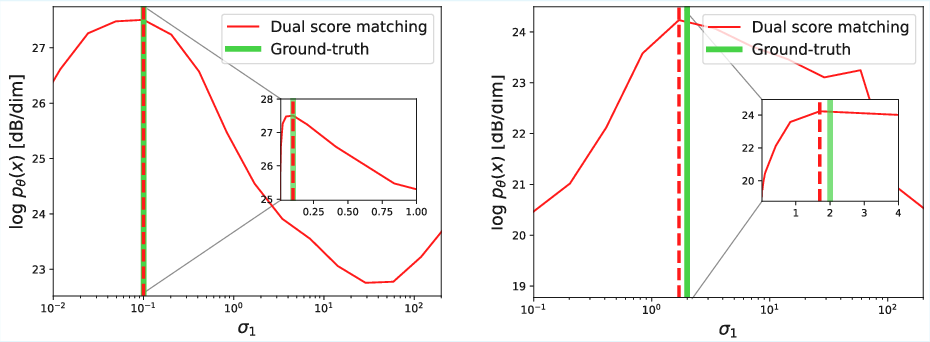
Figure 7: Blind reconstruction experiment shows that maximizing energy w.r.t. covariance parameters accurately estimates both noise region and variance.
Theoretical and Practical Implications
This methodology for learning normalized posterior densities allows for: (1) direct likelihood quantification and energy-based comparison across tasks; (2) a principled separation (and re-coupling) of prior and likelihood in the context of general inverse problems; (3) task-specific adaptation (e.g. adaptive scheduling, MALA correction) that was previously infeasible due to implicitness of the density. The model additionally supports one-shot MMSE denoising for arbitrary noise structures and may facilitate information-theoretic analysis of measurements (e.g., mutual information estimation).
The approach interpolates between pure Bayesian inference (which provides explicit likelihoods but suffers from tractability issues in high dimensions) and regression-based models (which are tractable but lack a modular prior/likelihood separation and normalized densities). By enforcing a global continuity constraint in covariance space, the method provides a pathway to more general, modular, and interpretable generative models for inverse problems.
Limitations and Future Directions
The cost of training dual-score EBMs is higher than for vanilla score-matching models, mainly due to extra gradient computations. The diagonal spatial and frequency covariance restriction, while expressive, limits applicability to a subset of all possible operators. Future work should seek scalable architectures supporting low-rank or arbitrary covariance conditioning and implement efficient training (e.g., using sliced score matching). Extensions toward high-dimensional scientific imaging and measurement design optimization are particularly promising avenues.
Conclusion
This work establishes that normalized energy-based models, regularized via anisotropic dual score matching, provide a scalable and flexible solution for a broad class of linear inverse problems. The framework enables normalized density computation, unbiased sampling and correction, task-adaptive inference, and blind operator estimation, subsuming and improving upon both Bayesian and regression paradigms in imaging inverse problems.

