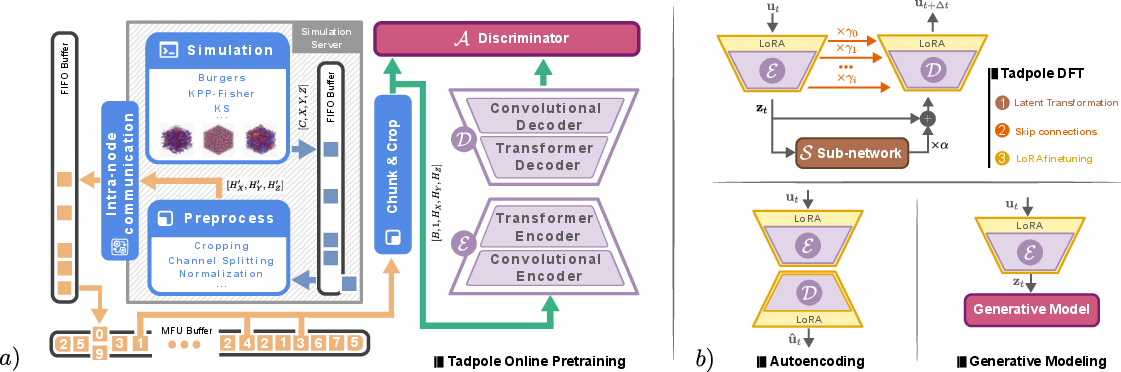
Tadpole: Autoencoders as Foundation Models for 3D PDEs with Online Learning
Abstract: We introduce Tadpole, a novel foundation model for three-dimensional partial differential equations (PDEs) that addresses key challenges in transferability, scalability to high dimensionality, and multi-functionality. Tadpole is pre-trained as an autoencoder on synthetic 3D PDE data generated by an efficient online data-generation framework. This enables large-scale, diverse training without storage or I/O overhead, demonstrated by scaling to an equivalent of hundreds of terabytes of training data. By autoencoding single-channel spatial crops, Tadpole learns rich and transferable representations across heterogeneous physical systems with varying numbers of state variables and spatial resolutions. Although pre-trained solely as an autoencoder, Tadpole can be efficiently applied for multiple downstream tasks beyond reconstruction, including dynamics learning and generative modeling. For dynamics learning, we propose a novel parameter-efficient fine-tuning strategy that integrates low-rank adaptation, latent-space transformations, and reintroduced skip connections, achieving accurate temporal modeling with a minimal number of trainable parameters. Tadpole demonstrates strong fine-tuning performance across various downstream tasks, highlighting its versatility and effectiveness as a foundation model for 3D PDE learning. Source code and pre-trained weights of Tadpole are available at https://github.com/tum-pbs/tadpole

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Tadpole, a general-purpose AI model that learns about 3D physical systems described by partial differential equations (PDEs). Think of PDEs as the rules that tell us how things like air, water, heat, or magnetic fields move and change over time in three-dimensional space. Tadpole is designed to understand many different kinds of physics and then quickly adapt to new tasks, like predicting what will happen next in a flow or creating realistic new examples of 3D physics.
Instead of trying to predict the future right away, Tadpole first learns to “compress and rebuild” 3D physics data really well. This makes it a strong base (a “foundation model”) that can be fine-tuned for several jobs, including:
- reconstructing high-resolution 3D fields,
- learning how systems change over time (dynamics),
- and generating new, realistic 3D physics examples.
Key Questions
The paper tackles three big questions in simple terms:
- How can we build a single 3D model that works well across many different physics problems (not just one)?
- How can we train on huge amounts of 3D data without needing to store massive datasets?
- Can one model handle multiple tasks (reconstruction, prediction, generation) and still be fast and accurate?
How They Did It (Methods)
Training as a “compress-and-rebuild” machine (Autoencoder)
Instead of learning to predict the future right away, Tadpole starts by learning to compress a 3D snapshot and then rebuild it. This is called an autoencoder:
- The encoder turns a big 3D input into a small, meaningful summary (like a zip file), called a latent space.
- The decoder turns that small summary back into the full 3D field.
- A helper network checks if the reconstruction looks realistic and pushes the reconstructions to be sharper.
Why this first? It’s easier and more stable to learn the “shape” of valid physics states before learning how those states move over time. Once Tadpole understands the space of possible states, it becomes much easier to fine-tune it for time prediction and other tasks.
Making training data on the fly (Online learning)
Storing huge 3D physics datasets (often terabytes) is slow and expensive. The authors avoid this by generating training data as needed:
- They run fast physics simulations on GPUs during training.
- A smart “buffer” system streams fresh 3D samples to the model so training never waits.
- This removes storage and file-loading bottlenecks and lets them train on the equivalent of hundreds of terabytes of diverse data without actually saving it to disk.
An analogy: it’s like baking fresh bread right onto a conveyor belt that feeds a sandwich machine, instead of baking, storing, and constantly fetching from a big freezer.
Training on small 3D chunks (“crops”)
Real 3D problems differ in size and how many variables they have (e.g., velocity, pressure, temperature, magnetic field). Tadpole handles this by training on small 3D cubes (crops) taken from larger volumes:
- During training, it sees many single-variable crops of size 64×64×64.
- At test time, it can process big volumes by scanning them in pieces and works with any number of variables.
- This makes Tadpole flexible with both resolution (small to very large) and variable count.
The model’s design
Tadpole uses a hybrid design:
- Convolutions (great for local patterns and “it works the same no matter where the pattern appears”),
- plus a transformer bottleneck (good for capturing larger, long-range structures).
- They remove “skip connections” in pre-training so the compressed space truly learns everything needed to rebuild the input. This forces a strong latent representation.
Fine-tuning for different jobs
Once pre-trained, Tadpole is adapted for new tasks with minimal extra training.
- Autoencoding: You can use it immediately to compress and reconstruct new 3D data, or fine-tune lightly for even better quality.
- Dynamics learning (predicting the future): The authors propose Tadpole-DFT, a parameter-efficient strategy:
- A small “latent transformation” module learns how the compressed summaries evolve over time and how different variables interact.
- They re-introduce skip connections (with careful scaling) so the model keeps fine details while learning time evolution.
- They use LoRA “adapters” (tiny add-on layers) to adjust the big pre-trained model without changing all of its weights. This keeps training stable and efficient.
- Generative modeling (creating new examples): They train a small generator in the compressed space to produce new realistic latent codes, then decode them into full 3D fields. Working in the compressed space makes this much faster and lighter on memory.
Main Findings
Here are the main takeaways from the experiments:
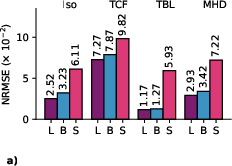
- Strong reconstructions right out of the box: Tadpole can reconstruct complex, high-resolution 3D physics it didn’t see during training, including turbulent flows and magnetized fluids. Larger Tadpole versions do even better.
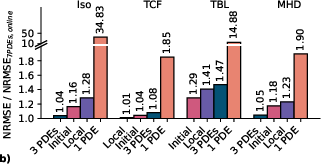
- Training diversity matters: Pre-training on many types of physics improves generalization. Generating data online (instead of using a fixed, saved dataset) leads to better results and avoids storage limits.
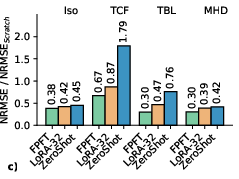
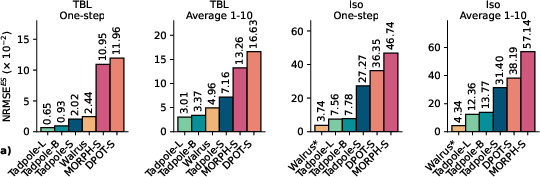
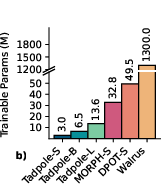
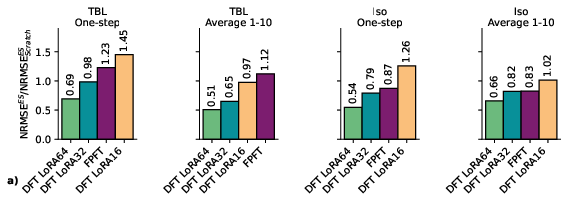
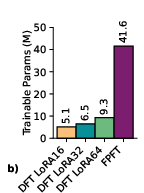
- Efficient and accurate dynamics: With Tadpole-DFT, the model predicts future states accurately while fine-tuning only a small fraction of the parameters. It often beats other state-of-the-art models and sometimes does so with 100× fewer trainable parameters.
- Generative modeling works well and fast: By generating in the compressed space and decoding, Tadpole produces realistic 3D physics samples that match the statistics of real data, and it does so faster than heavy, direct-in-3D methods.
- Scales to huge 3D sizes: Tadpole runs on volumes as large as 1024×1024×1024 (over a billion grid points), which is important for realistic applications.
Why It Matters
- Real-world relevance: Many important problems—like weather prediction, aerodynamics, ocean currents, and material science—are naturally 3D and extremely large. Tadpole shows that a single foundation model can handle them.
- Saves time and storage: Generating training data on the fly and using compact representations reduces storage needs and speeds up training.
- Flexible and reusable: Because Tadpole first learns a general 3D “language of physics,” it can be quickly adapted to new tasks and systems with little extra training.
- Multi-purpose: The same model supports reconstruction, prediction, and generation, making it a versatile tool for scientists and engineers.
Limitations and Potential Impact
- Current focus: Tadpole focuses on data on regular 3D grids; future work could extend it to irregular meshes used in some engineering applications.
- Long-term predictions: Like many models, it’s strongest on short- to medium-term forecasts; very long rollouts remain challenging.
- Even bigger models: Training even larger versions might push performance further.
Overall, Tadpole suggests a new recipe for 3D scientific AI:
- learn general, compact 3D physics representations via autoencoding,
- create vast training diversity by simulating data on the fly,
- and adapt efficiently to many tasks with small, smart updates.
This could accelerate research and applications in climate science, engineering, and beyond, by making 3D physics modeling faster, more flexible, and easier to reuse.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper proposes Tadpole, a 3D-PDE foundation model pre-trained as an autoencoder with online synthetic data generation, and demonstrates downstream performance on autoencoding, dynamics learning, and generative modeling. While promising, several concrete gaps and open questions remain:
Pre-training data and task design
- Limited boundary-condition coverage in pre-training: data are generated with globally periodic Fourier-spectral solvers and only converted to non-periodic samples via local crops. It remains unclear how well the learned representations transfer to PDEs with explicit non-periodic boundaries (e.g., walls, inflow/outflow, obstacles) or non-spectral discretizations. Future work: pre-train with solvers that natively impose diverse boundary conditions and geometries to quantify gains versus crop-based “local non-periodicity.”
- Single-channel crop pre-training ignores cross-variable couplings during representation learning. Cross-field interactions (e.g., velocity–pressure, velocity–magnetic field) are only addressed during dynamics fine-tuning via latent aggregation. Future work: assess multi-channel crop pre-training, cross-channel masking, or joint-field contrastive objectives to encode inter-variable physics.
- Limited PDE diversity and parameterization in pre-training: only seven synthetic PDEs are used; no explicit conditioning on PDE parameters, material properties, or boundary metadata during pre-training. Future work: expand the PDE set (e.g., compressible/shock-dominated flows, multiphase, reactive, non-Newtonian) and incorporate parameter/BC conditioning to test zero-/few-shot generalization across parameter ranges.
- Static reconstruction as the sole pre-training task may under-exploit temporal structure. Open question: does adding temporal self-supervision (e.g., masked spatiotemporal modeling, contrastive predictive coding) improve downstream dynamics and long-horizon stability compared to reconstruction-only pre-training?
Architectural choices and invariances
- Lack of enforced physical invariances beyond translation equivariance. Rotational, reflectional, scale, and Galilean invariances are not encoded. Future work: integrate equivariant layers or physics-informed constraints and measure effects on transfer and sample efficiency.
- No explicit divergence- or conservation-aware components in the autoencoder. For incompressible/MHD flows, constraints like ∇·u=0 or ∇·B=0 are not enforced during pre-training or reconstruction. Future work: add constraint-aware losses or corrective projection steps and quantify constraint violations.
- Generality beyond the P3D backbone is claimed but not empirically validated. Open question: do the autoencoding pre-training and Tadpole-DFT transfer consistently to other 3D backbones (e.g., Fourier neural operators, pure CNNs, other transformers)?
Dynamics fine-tuning (Tadpole-DFT)
- Generality of Tadpole-DFT across PDE families remains untested. Results are shown for two turbulent cases; broader validation on heterogeneous PDEs (e.g., elasticity, electromagnetics, porous media) is needed to assess robustness of the latent subnetwork + skip-connections + LoRA recipe.
- No guidance for selecting LoRA rank or subnetwork size under varying data regimes. Future work: establish principled heuristics or data-driven selection rules (e.g., via validation curves or information criteria) for LoRA capacity and adapter depth.
- Limited horizon stability analysis: evaluations focus on short rollouts (e.g., 10 steps). Open question: how do different components (latent S, skip connections, LoRA rank) affect long-term stability, error growth, and spectral drift under extended rollouts?
- Absence of parameter-conditioned dynamics. The pre-training removes parameter embeddings, and dynamics fine-tuning is per-system. Future work: introduce lightweight parameter/BC adapters to enable parametric dynamics with few-shot adaptation and evaluate interpolation/extrapolation across parameter ranges.
Generative modeling
- Only unconditional latent generative modeling is demonstrated on a single dataset (TCF). Open question: how well does latent flow matching extend to conditional generation (e.g., prescribed statistics, boundary conditions, or global flow rates) and to other PDE families?
- Physical validity of generated samples is not fully assessed. Metrics focus on distributional similarity (PQM, Wasserstein, MMD, NRMSE of mean/std) but do not evaluate conservation laws, constraint satisfaction (e.g., divergence-free), or spectra across scales. Future work: include physics-based metrics (energy/enstrophy spectra, fluxes, divergence norms) and evaluate downstream usability (e.g., initializing rollouts).
- Impact of the autoencoder’s adversarial-VAE training on latent generative quality is not analyzed. Future work: compare flow matching on latents from purely VAE, adversarial-VAE, and alternative self-supervised objectives to quantify trade-offs in sample fidelity and stability.
Evaluation scope and metrics
- Limited cross-domain, cross-resolution generalization analysis in dynamics. While autoencoding is shown at multiple resolutions, dynamics tests are fixed-size cropped volumes. Future work: test cross-resolution dynamics (coarse-to-fine and fine-to-coarse) and quantify performance under severe resolution/domain shifts.
- Incomplete physics-centric evaluation for autoencoding and dynamics. For MHD and turbulence, no reporting of constraint violations (e.g., ∥∇·u∥, ∥∇·B∥), conservation errors (mass, momentum, energy), or spectral fidelity beyond enstrophy metrics in dynamics. Future work: standardize physics metrics to evaluate physical consistency.
- Robustness to noise, sparsity, and partial observations is not studied. Since real measurements are noisy/incomplete, future work should test denoising, inpainting, and data assimilation settings to evaluate practicality.
Data generation and deployment realism
- Online generator relies on uniform, structured grids and spectral methods; unstructured meshes and complex geometries are out of scope. Future work: extend to finite-volume/finite-element solvers and mesh-based encoders to support curvilinear/unstructured domains.
- Cropping strategy could bias representations toward local features and limit capture of very large-scale/global structures (e.g., coherent structures spanning domains). Future work: experiment with multi-scale pre-training that mixes local crops and global contexts, and measure effects on anisotropic/inhomogeneous flows.
- Reproducibility and variability of online training are not quantified. Open question: how sensitive are learned representations to solver seeds, parameter sampling, and buffering policies? Report variance across multiple pre-training runs.
Scalability, efficiency, and practical usability
- Model size and training scale are modest (≤152M parameters) relative to cutting-edge foundation models; scaling laws and performance at larger capacity are not explored. Future work: study pre-training scaling curves, data–model size trade-offs, and diminishing returns.
- Memory and latency for very large 3D domains during inference are not characterized, especially for dynamics. Provide profiling (time/memory) for 1024³ autoencoding and scalable dynamics to guide deployment in HPC workflows.
- Few-shot adaptation and data efficiency are not systematically assessed. Open question: how does performance degrade with limited fine-tuning data, and does Tadpole consistently outperform training-from-scratch in low-data regimes?
Theory and interpretability
- No theoretical guarantees or analysis of the learned latent manifold (e.g., smoothness, dimensionality, coverage) across heterogeneous PDEs. Future work: quantify manifold structure and relate latent coordinates to physical invariants or modal decompositions (e.g., POD/DMD).
- Interpretability of learned features and task transfer mechanisms is not explored. Open question: can one identify latent directions corresponding to physical modes, symmetries, or parameters, and leverage them for controllability or diagnostics?
These gaps outline concrete avenues for improving Tadpole’s realism, robustness, and generality as a 3D PDE foundation model, and for deepening understanding of representation learning for scientific systems.
Practical Applications
Immediate Applications
The following applications can be deployed now with the provided codebase, pretrained weights, and described workflows (online data generation, Tadpole-DFT fine-tuning, latent generative modeling). Each item highlights sectors, concrete artifacts, and key assumptions/dependencies.
- Engineering (CFD) — Rapid surrogate rollouts for short-term 3D flow prediction
- What: Use Tadpole-DFT with LoRA to fine-tune the pretrained autoencoder for short-horizon dynamics (e.g., 10–100 steps) on domain-specific flows (e.g., isotropic turbulence, boundary layers).
- How: Collect a small number of high-fidelity snapshots, train LoRA adapters and the lightweight latent sub-network S, reintroduce skip connections, and deploy for fast inference on cropped or full domains.
- Tools/Workflows:
tadpolepretrained weights; LoRA fine-tuning scripts; mini-batch channel-wise encoding for large grids. - Assumptions/Dependencies: Regular grids; short-term stability prioritized over long horizons; access to GPU(s); downstream task data close to pretraining distribution (e.g., incompressible flows); boundary types not too far from periodic/cropped data.
- Engineering (CFD, MHD) — Learned compression and streaming of high-resolution 3D fields
- What: Encode large 3D fields (e.g., 10243) into compact latents for storage, visualization, and remote transfer with faithful reconstruction.
- How: Use Tadpole’s autoencoder zero-shot or LoRA-fine-tuned for the target data modality and resolution.
- Tools/Workflows: Encoder/decoder pipeline; integration into HDF5/Zarr-based workflows; potential ParaView plugin for streaming decoded tiles.
- Assumptions/Dependencies: Regular-grid tensor fields; acceptable lossy compression error; GPU decoding at scale.
- HPC & Scientific ML — Online synthetic data generation to remove I/O bottlenecks
- What: Adopt the paper’s GPU pseudo-spectral solver (ETDRK integrators), FIFO+MFU buffered data pipeline to pretrain/fine-tune models without storing terabytes of data.
- How: Integrate the buffer strategy on shared clusters; generate 3D PDE samples on-the-fly; train continuously with high throughput.
- Tools/Workflows: TorchFSM (Fourier spectral solvers), buffering scripts, multi-node extension; MLOps configuration for asynchronous producers/consumers.
- Assumptions/Dependencies: Access to FFT-accelerated GPU libraries; periodic global BCs in the simulator; network/storage constraints typical of HPC settings.
- Energy (Wind engineering, HVAC) — Fast design iteration on small domains
- What: Short-term predictions for micro-scale flow patterns around obstacles or in ducts to accelerate early-stage design iterations.
- How: Fine-tune LoRA adapters with limited domain examples (channel flow, duct flow), then roll out predictions over design variants.
- Tools/Workflows: Tadpole-DFT; channel-wise batching for multi-variable fields; automated evaluation using enstrophy-based metrics (NRMSEES).
- Assumptions/Dependencies: Near-incompressible, regular-grid setups; short horizons; transferability from pretrained manifold.
- Materials Science — Autoencoding and generative augmentation for 3D PDE-based microstructure fields
- What: Compress 3D microstructure PDE outputs (e.g., phase-field simulations) for storage; generate plausible fields to augment small datasets.
- How: LoRA-fine-tune Tadpole on microstructure snapshots; train a latent flow-matching model to sample new latents and decode to configurations.
- Tools/Workflows: Latent generative modeling code; reconstruction/generation evaluation with MMD/Wasserstein; dataset integration.
- Assumptions/Dependencies: Regular grids; similar spatial statistics to pretraining data; careful validation to prevent hallucinations.
- Earth/Environmental Engineering — Rapid what-if analysis on cropped pollutant dispersion or microclimate blocks
- What: Use Tadpole-DFT for quick, local rollouts on cropped 3D blocks to compare near-term scenarios (e.g., street-canyon dispersion).
- How: Map target data to model’s input format; LoRA fine-tune adapters on limited CFD runs; deploy with tiled inference.
- Tools/Workflows: Crop-based inference; mini-batch channel handling; performance monitoring via physically-informed metrics.
- Assumptions/Dependencies: Regular grid discretization; short horizon; validation against baseline solver before operational use.
- Education (STEM) — Interactive 3D PDE labs for teaching dynamics and statistics
- What: Provide students with fast reconstructions, short rollouts, and generative samples to explore turbulence and other 3D PDE phenomena.
- How: Package Tadpole with demo notebooks; enable scaling of crop sizes; visualize vortical structures and spectral statistics.
- Tools/Workflows: Pretrained weights; visualization notebooks; sample datasets; Colab-ready demos.
- Assumptions/Dependencies: GPU access for large resolutions; curated datasets for classroom-size experiments.
- Software & Tooling — “3D PDE Backbone” service with LoRA adapters
- What: Offer a service/library where practitioners upload 3D fields and get back reconstructions, compressed latents, short-horizon forecasts, or generated samples.
- How: Provide APIs for encode/decode/rollout; host and share LoRA adapters for specific PDE families; DevOps around model versioning.
- Tools/Workflows: Model hub for LoRA adapters; CI/CD for performance regression; instrumentation for latency and accuracy.
- Assumptions/Dependencies: Licensing of pretrained weights; GPU-backed inference; security routines for shared models.
- Manufacturing (Casting, Welding, Thermal processes) — Heat/diffusion PDE compression and short-term surrogates
- What: Compress and reconstruct thermal 3D fields; quickly estimate short-term temperature evolution for control prototyping.
- How: LoRA fine-tune on thermal simulation snapshots; run short rollouts for “what-if” control tuning.
- Tools/Workflows: Integrate with existing digital twin dashboards; use enstrophy-like or energy-based proxies for validation.
- Assumptions/Dependencies: Regular 3D grids; physics consistent with pretrained manifold; need rigorous QA before production control.
- Data Engineering in HPC — Cross-resolution field processing pipelines
- What: Use crop-based inference to handle varying spatial resolutions and numbers of state variables without model changes.
- How: Build ETL pipelines that normalize variables, tile volumes as needed, and batch channels for scalable inference.
- Tools/Workflows: Glue code for HDF5/Zarr → Tadpole → back; scheduling for chunk-wise inference.
- Assumptions/Dependencies: Translation equivariance via convolutional components; careful boundary handling across tiles.
Long-Term Applications
These opportunities require further research, scaling, or extensions (e.g., unstructured grids, long-horizon stability, broader PDE coverage, robust UQ) before deployment in high-stakes settings.
- Weather and Climate — High-resolution nowcasting and data assimilation on 3D cubes
- Vision: Extend Tadpole to assimilate observations and produce stable multi-hour/day forecasts at convection-permitting resolutions.
- Enablers: Long-horizon training strategies; physics constraints; multi-scale attention; boundary-aware training; UQ calibration.
- Dependencies: Robustness to non-periodic boundaries; training on diverse weather datasets; large-scale compute.
- Energy (Fusion, MHD) — Surrogate modeling and control for tokamak plasmas
- Vision: Apply Tadpole to 3D MHD states for rapid scenario exploration and real-time control assistance.
- Enablers: Pretraining on MHD-rich datasets; stability-focused fine-tuning; integration with control loops; uncertainty quantification.
- Dependencies: High-fidelity MHD data; safety margins for control; validation against trusted solvers.
- Healthcare (Hemodynamics) — Patient-specific blood flow prediction and planning
- Vision: Fast, near-real-time predictions for 3D artery/heart flows to assist surgical planning and device design.
- Enablers: Domain adaptation to non-periodic, wall-bounded flows; training on anatomically realistic geometries; physics-informed losses.
- Dependencies: Unstructured mesh support or robust voxelization; regulatory validation; clinically acceptable error bounds.
- Robotics & Aero — Onboard flow-field inference for control
- Vision: Predict local 3D flow fields around UAVs/robots for disturbance-aware control and energy optimization.
- Enablers: Model compaction; hardware acceleration; robust short-horizon rollouts; sensor-fusion for partial observations.
- Dependencies: Onboard compute constraints; generalization across operating regimes; safety verification.
- Urban Planning & Policy — City-scale air quality and microclimate scenario testing
- Vision: Perform rapid what-if analyses across many urban configurations to support policy and design decisions.
- Enablers: Hierarchical tiling; boundary-aware training on realistic boundary conditions; trusted UQ for decision support.
- Dependencies: Integration with GIS/CAD; stakeholders’ confidence via benchmarking and interpretable metrics.
- Subsurface & Reservoir Simulation — Fast proxies for 3D porous media flow
- Vision: Surrogate rollouts and generative priors for uncertain reservoir characterization and management.
- Enablers: Training on heterogeneous permeability fields; physics-informed conditioning; handling of complex BCs.
- Dependencies: Extension beyond periodic FFT regimes; incorporation of multiphase physics; uncertainty-aware workflows.
- Materials & Additive Manufacturing — Inverse design via latent search over PDE solution manifolds
- Vision: Use Tadpole’s latent space for guided exploration of microstructures/thermal histories that meet target performance.
- Enablers: Coupling with differentiable solvers; optimization in latent space; constraints and manufacturability filters.
- Dependencies: Strongly validated structure–property surrogates; reliable inverse mapping under constraints.
- Scientific Data Infrastructure — Learned codecs for 3D scientific data in HDF5/Zarr/netCDF
- Vision: Standardize learned compression/inference (encode/decode) interfaces for massive 3D PDE datasets.
- Enablers: Reproducible codecs; metadata standards; error bounds tied to physical metrics; toolchain integration.
- Dependencies: Community consensus; performance on diverse physics/modalities; maintenance and governance.
- Digital Twins at Scale — Stable long-term surrogates coupled with differentiable solvers
- Vision: Hybrid pipelines where Tadpole reduces dimensionality, provides surrogate dynamics, and interfaces with differentiable solvers for control/optimization.
- Enablers: Stability under long rollouts; error control and correction mechanisms; adjoint-compatible modules.
- Dependencies: Algorithmic advances for stability; standardized solver coupling; domain-specific certification.
- Scientific Discovery — PDE/operator discovery aided by latent manifolds
- Vision: Use learned latent representations to regularize/operator-learn governing equations from data (e.g., weak form discovery).
- Enablers: Joint training with symbolic components; multimodal conditioning (text/symbolic); sparse operator constraints.
- Dependencies: Rich, labeled datasets; validation on canonical benchmarks; interpretability requirements.
Cross-Cutting Assumptions and Dependencies
- Data and Grids: Current approach assumes regular grids and training on crops derived from globally periodic simulations; generalizing to unstructured meshes and complex BCs remains future work.
- Time Horizons: Demonstrated strength is short-term rollouts; long-term stability and drift control require additional techniques.
- Compute: High-resolution training/inference needs GPUs and memory-efficient tiling; FFT-centric solvers for online generation.
- Domain Shift: Best performance when downstream PDEs resemble pretraining distribution; OOD generalization needs careful fine-tuning and validation.
- Safety & Governance: In high-stakes domains (healthcare, energy, policy), adopt physics-informed constraints, uncertainty quantification, and rigorous benchmarking before deployment.
These applications leverage Tadpole’s key innovations—online synthetic training (eliminating I/O bottlenecks), crop-based transferable representations, parameter-efficient fine-tuning (LoRA + latent sub-network + skip gating), and latent-space generative modeling—to create practical, scalable workflows across science and engineering.
Glossary
- Adversarial loss: A discriminator-driven objective used to make reconstructions sharper or more realistic by training against a learned critic. Example: "with an adversarial loss to encourage sharper reconstructions"
- Anisotropic (flow): Having direction-dependent properties; in fluid dynamics, structures that vary with direction. Example: "which exhibits complex, anisotropic flow structures"
- Autoencoder: A neural network trained to compress data into a latent representation and reconstruct it back, learning informative features. Example: "Tadpole is pre-trained as an autoencoder on single-channel crops of 3D PDE data"
- Compute-adaptive tokenization: A strategy that adapts the number/structure of tokens to available compute or stability requirements in transformer-like models. Example: "Walrus \cite{Walrus2025}, the latter introducing compute-adaptive tokenization to maintain stability."
- Enstrophy: A measure related to the intensity of vorticity in a fluid; used to evaluate turbulence spectra. Example: "We utilize an enstrophy-based spectrum metric NRMSE"
- Exponential Time Differencing Runge--Kutta (ETDRK) schemes: High-order time integration methods that handle stiff PDEs by separating linear and nonlinear parts. Example: "time integration is performed using Exponential Time Differencing Runge--Kutta (ETDRK) schemes"
- Fast Fourier Transforms (FFTs): Algorithms to efficiently compute the discrete Fourier transform, often used for spectral differentiation. Example: "Spatial derivatives are computed via pseudo-spectral methods based on Fast Fourier Transforms (FFTs)"
- First-In-First-Out (FIFO) buffer: A queue where the earliest inserted items are the first to be removed; used for streaming data pipelines. Example: "Simulation outputs are first written to a small First-In-First-Out (FIFO) buffer"
- Flow matching: A generative modeling objective that learns continuous-time probability flows to map simple distributions to data distributions. Example: "using a standard flow matching~\cite{flowmtaching2023} objective"
- Foundation model: A large, pre-trained model designed to learn transferable representations that can be adapted to many tasks. Example: "We introduce Tadpole, a novel foundation model for three-dimensional partial differential equations (PDEs)"
- Fourier-spectral solvers: PDE solvers that represent fields in the Fourier basis to compute derivatives spectrally. Example: "Although Fourier-spectral solvers impose periodic boundary conditions at the global domain level"
- Full-Parameter Fine-Tuning (FPFT): Updating all parameters of a pre-trained model during task-specific training. Example: "most PDE foundation models still rely on full-parameter fine-tuning (FPFT)"
- High-Performance Computing (HPC): Large-scale computational infrastructure enabling parallel, high-throughput workloads. Example: "The designed communication and buffer strategy can be effectively extended to multi-node HPC setups"
- In-Context Learning (ICL): The ability of models to adapt behavior based on prompts or examples at inference time without parameter updates. Example: "recent studies investigated In-Context Learning (ICL) for PDE foundation models"
- Isotropic turbulence (Iso): Turbulence with statistical properties identical in all directions. Example: "isotropic turbulence (Iso, )"
- Latent distribution: The probabilistic representation (e.g., mean and variance) of encoded variables in a generative encoder. Example: "The encoder transforms the input into a latent distribution"
- Latent generative model: A generative model trained in the compressed latent space of an autoencoder to synthesize high-dimensional data efficiently. Example: "we can efficiently build a latent generative model~\cite{latentdiffusion2021} for 3D PDEs"
- Latent space: A lower-dimensional representation learned by an encoder capturing salient factors of variation in data. Example: "explicitly optimizing a continuous latent space to capture the underlying data manifold"
- Latent-space transformations: Task-specific manipulations learned within the latent representation to adapt or predict dynamics. Example: "integrates low-rank adaptation, latent-space transformations, and reintroduced skip connections"
- Latent flow matching: Applying flow matching within the latent space for more memory-efficient generative modeling. Example: "generative modeling via latent flow matching."
- Low-dimensional manifold: A structured, lower-dimensional surface embedded in high-dimensional space that captures valid solution states. Example: "learning the low-dimensional manifold of admissible PDE solutions"
- Low-Rank Adaptation (LoRA): A fine-tuning technique that updates models via low-rank decompositions while keeping base weights frozen. Example: "LoRA approximates the update via a low-rank decomposition: "
- Magnetohydrodynamics (MHD): The study of electrically conducting fluids where magnetic fields interact with fluid flow. Example: "magnetohydrodynamics (MHD, )"
- Maximum Mean Discrepancy (MMD): A statistical distance between distributions measured via kernel embeddings. Example: "Maximum Mean Discrepancy with a Radial Basis Function kernel "
- Most-Frequently-Used (MFU) replacement policy: A cache policy that retains frequently accessed items and evicts less-used ones. Example: "a larger cache governed by a Most-Frequently-Used (MFU) replacement policy"
- Normalized Root Mean Squared Error (NRMSE): A scale-normalized measure of reconstruction or prediction error. Example: "Reconstruction NRMSE of Tadpole-B fine-tuned with different LoRA ranks on the Iso dataset."
- NRMSE (enstrophy-based spectrum metric): An error metric computed in spectral space weighted by enstrophy for turbulence evaluation. Example: "We utilize an enstrophy-based spectrum metric NRMSE to accurately evaluate the rollout performance"
- Online learning framework: Training setup where data are generated/ingested on-the-fly during training, avoiding storage and I/O bottlenecks. Example: "A synthetic online learning framework: We propose an efficient online learning framework"
- Parameter-Efficient Fine-Tuning (PEFT): Techniques that adapt a pre-trained model with a small number of additional parameters. Example: "Parameter-Efficient Fine-Tuning (PEFT) have become standard benchmarks"
- Partial Differential Equations (PDEs): Equations involving multivariable functions and their partial derivatives, governing many physical systems. Example: "three-dimensional partial differential equations (PDEs)"
- Periodic boundary conditions: Boundary conditions that wrap field values around domain edges to enforce periodicity. Example: "Fourier-spectral solvers impose periodic boundary conditions at the global domain level"
- Pseudo-spectral methods: Numerical methods that compute derivatives in spectral space (e.g., Fourier domain) for high accuracy. Example: "pseudo-spectral methods based on Fast Fourier Transforms (FFTs)"
- Residual connection: A skip pathway that adds input to output of a layer or sub-network to ease training and preserve information. Example: "Tadpole-DFT introduces a lightweight sub-network S between the pre-trained Tadpole encoder and decoder with a residual connection."
- Skip connections: Direct links between non-adjacent layers (e.g., encoder and decoder) to transmit high-resolution information. Example: "the skip connections between the encoder and decoder are re-established"
- Spectral distribution analysis: Examination of how energy or variance is distributed across frequencies/wavenumbers. Example: "We perform a spectral distribution analysis on the pre-training dataset"
- Translation equivariance: A property where translating the input results in a correspondingly translated output, common in convolutions. Example: "This configuration leverages the translation equivariance of convolutions."
- Transitional boundary layer flows (TBL): Flows in boundary layers transitioning from laminar to turbulent regimes. Example: "transitional boundary layer flows (TBL, )"
- Turbulent channel flow (TCF): Turbulent flow confined between parallel walls, a canonical benchmark in fluid dynamics. Example: "turbulent channel flow (TCF, )"
- Variational Autoencoder (VAE): A probabilistic autoencoder that learns a distribution over latent variables via a variational objective. Example: "Specifically, Tadpole is pre-trained as a Variational Autoencoder (VAE) with an adversarial loss"
- Wasserstein-1 distance: An optimal-transport-based metric measuring the cost to transform one probability distribution into another. Example: "Wasserstein-1 distance "
- Zero-shot (generalization/settings): Evaluating or applying a model to tasks or data it was not explicitly trained on, without task-specific fine-tuning. Example: "We first evaluate Tadpole in zero-shot settings."
Collections
Sign up for free to add this paper to one or more collections.