Always Learning, Always Mixing: Efficient and Simple Data Mixing All The Time
Abstract: Data mixing decides how to combine different sources or types of data and is a consequential problem throughout LLM training. In pretraining, data composition is a key determinant of model quality; in continual learning and adaptation, it governs what is retained and acquired. Yet existing data mixing methods address only one phase of this lifecycle at a time: some require smaller proxy models tied to a single training phase, others assume a fixed domain set, and continual learning lacks principled guidance altogether. We argue that data mixing is fundamentally an online decision making problem -- one that recurs throughout training and demands a single, unified solution. We introduce OP-Mix (On-Policy Mix), a data mixing algorithm that operates across the entire LLM training lifecycle. Our main insight is that candidate data mixtures can be cheaply simulated by interpolating between low-rank adapters trained directly on the current model, eliminating separate proxy models and ensuring the search is always grounded in the model's actual learning dynamics. Across pretraining, continual midtraining, and continual instruction tuning, OP-Mix consistently finds near-optimal mixtures while using a fraction of the compute of the baselines. In pretraining, OP-Mix improves upon training without mixing by 6.3% in average perplexity. For continual learning, OP-Mix matches the performance of both retraining and on-policy distillation while using 66% and 95% less overall compute, respectively. OP-Mix suggests a different view of LLM training: not a sequence of distinct phases, but a single continuous process of learning from data.
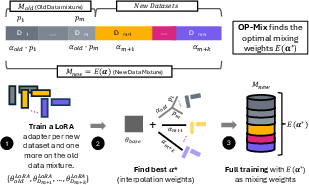
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “Always Learning, Always Mixing: Efficient and Simple Data Mixing All The Time”
What is this paper about?
This paper is about a simple, fast way to choose the “right mix” of training data for LLMs at every stage of their life. Training a model is like making a smoothie: the ingredients (types of data like books, code, or social media) and how much of each you use make a big difference in taste (model quality). The paper introduces OP-Mix, a method that keeps adjusting the recipe as new ingredients arrive, without wasting lots of time and computer power.
What questions are the researchers trying to answer?
They focus on three big questions:
- How do we decide the best ratio of different data sources to train on?
- How can we keep making good decisions as new data shows up over time, without redoing everything from scratch?
- Can one method work for all stages of training—pretraining, midtraining, and instruction tuning—instead of using different tricks for each?
How does OP-Mix work? (Explained simply)
Think of the model as a camera, and each data source (like ArXiv papers, Reddit posts, or math problems) as a different lighting condition. You want the camera to do well in all lights, and you must decide how much practice to give it under each one.
OP-Mix uses three clever ideas:
- Small add-ons instead of full retraining
- Instead of retraining the whole camera for each lighting condition, it trains a tiny “clip-on” attachment called a LoRA adapter for each data source.
- LoRA (Low-Rank Adaptation) is a lightweight plug-in that changes how the model behaves without changing all its parts. It’s much faster and cheaper to train than a full model.
- Try mix ratios without retraining
- OP-Mix “blends” these tiny adapters—like mixing paint colors—to simulate what would happen if you trained on different data mixtures (for example, 30% Reddit + 70% ArXiv).
- This blending (interpolation) is done by mixing the adapter weights directly, so you can test lots of mixtures with just forward passes (no big training runs).
- Pick the best blend, then train once
- After testing different blends, OP-Mix fits a simple curve that predicts performance for any mixture.
- It then picks the best ratio and trains the base model on that mixture for real.
- When new data arrives later, OP-Mix adds one more small adapter and repeats the process—no need to start over.
A few helpful terms:
- Data domain: a category of data (e.g., scientific papers, web text, programming problems).
- Continual learning: learning new things over time without forgetting old ones.
- On-policy: making decisions using the current model itself (like test-driving your own car), not a smaller, different “practice” model.
- Perplexity: a measure of how “surprised” the model is by text; lower is better.
What did the researchers find?
Across three training stages, OP-Mix is both strong and efficient:
- Pretraining (learning from scratch on large mixed text)
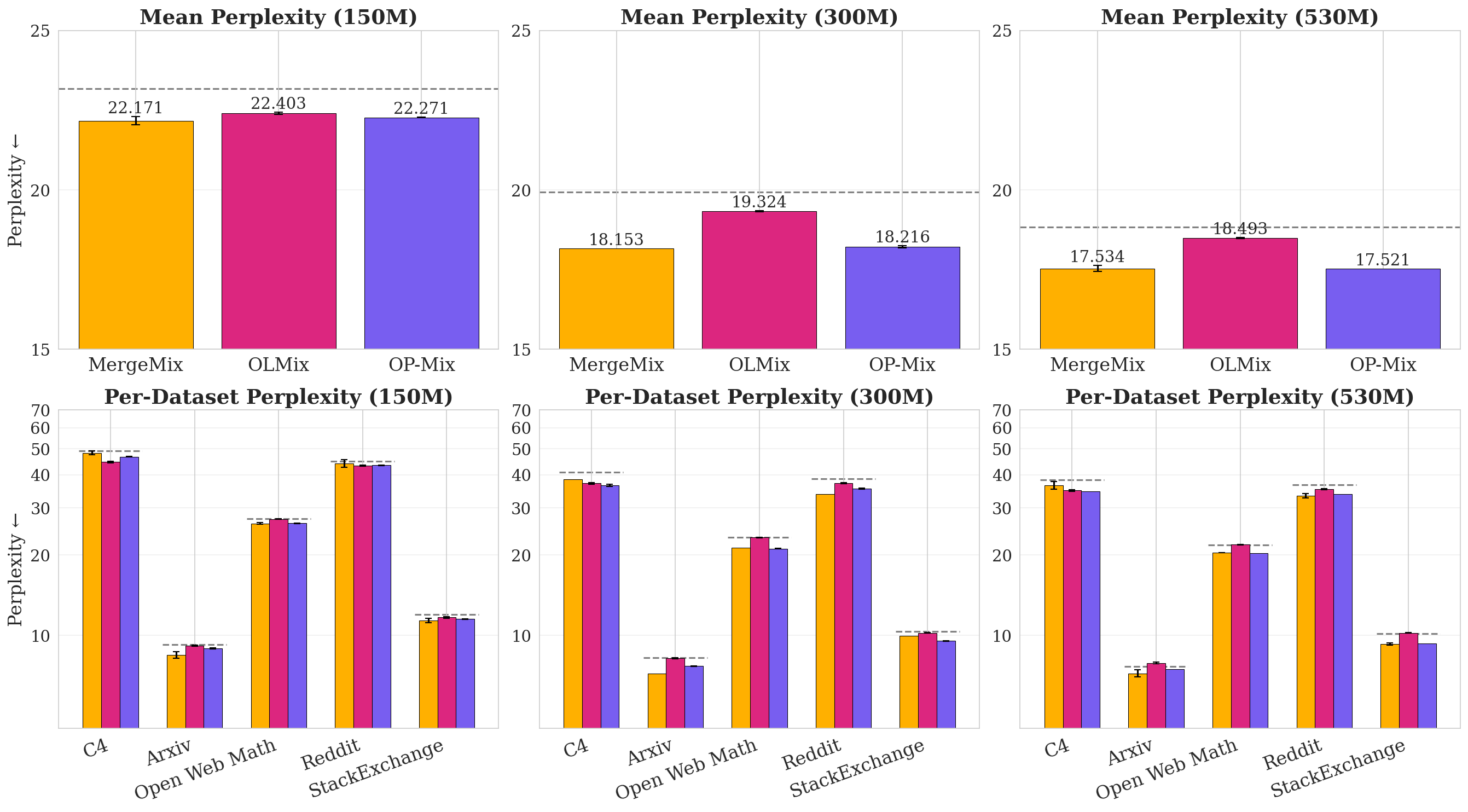
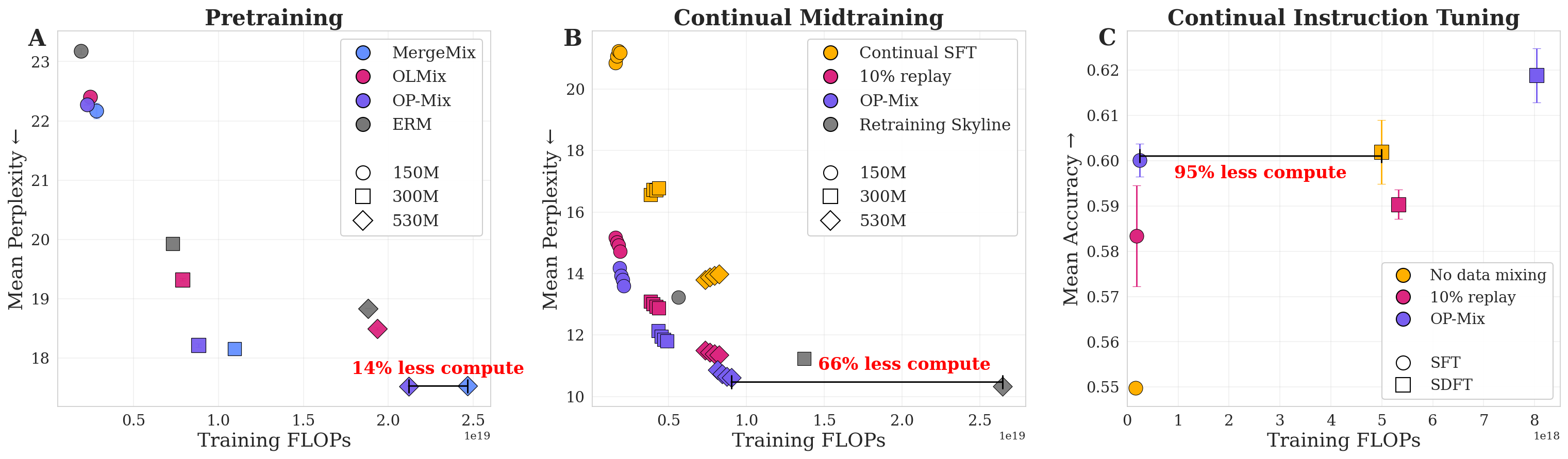
- OP-Mix improved average perplexity by 6.3% compared to not optimizing the mix.
- It matched the best competing method while using up to 14% less compute.
- Continual midtraining (tuning a pretrained model on new large datasets)
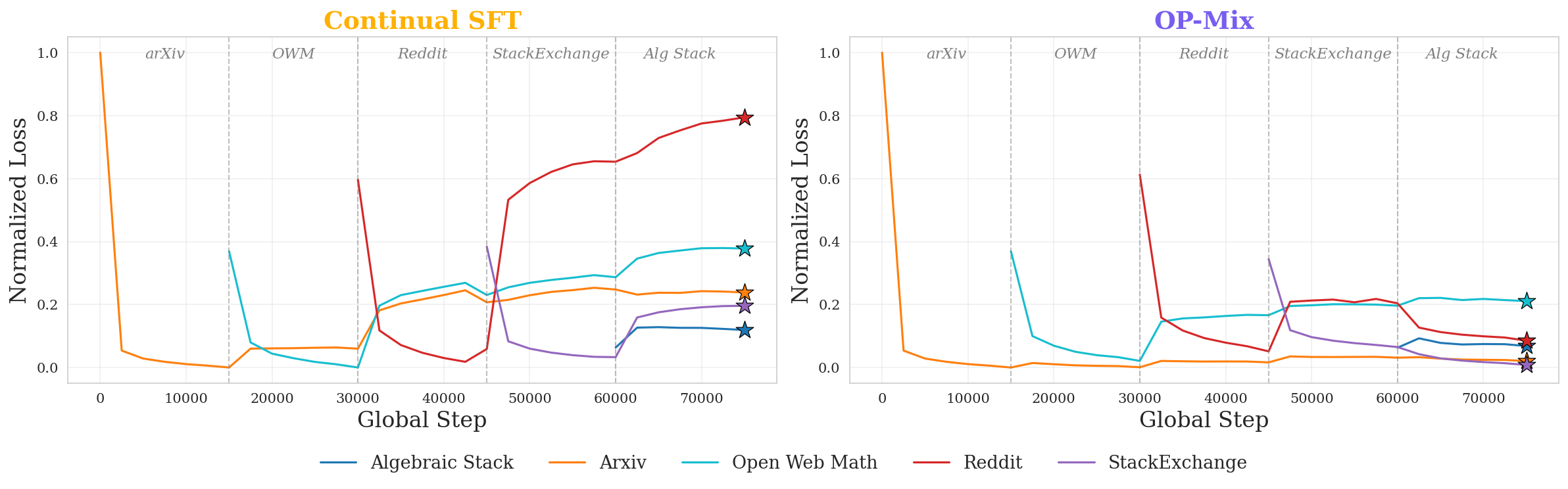
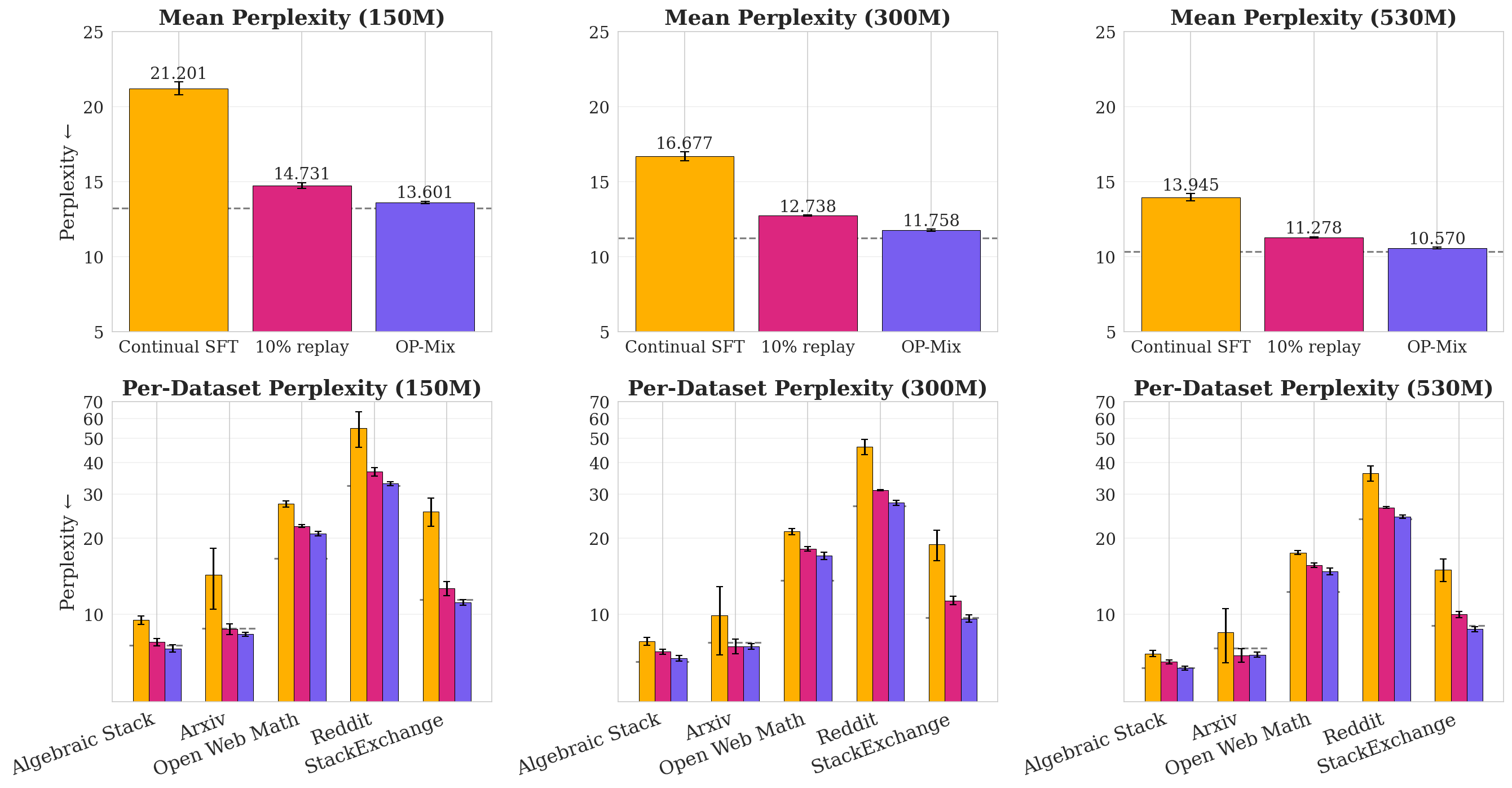
- OP-Mix nearly matched the performance of retraining on all data at once but used about 66% less compute.
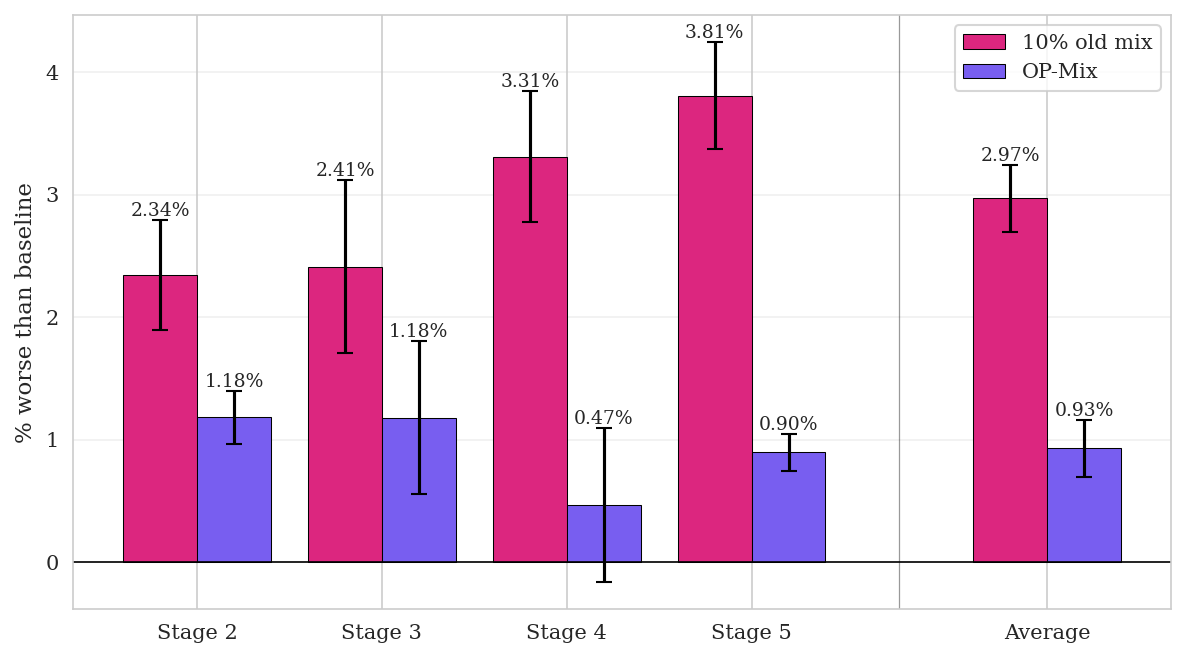
- It reduced “forgetting” of old skills better than other continual learning baselines.
- Continual instruction tuning (teaching the model to follow instructions across new tasks)
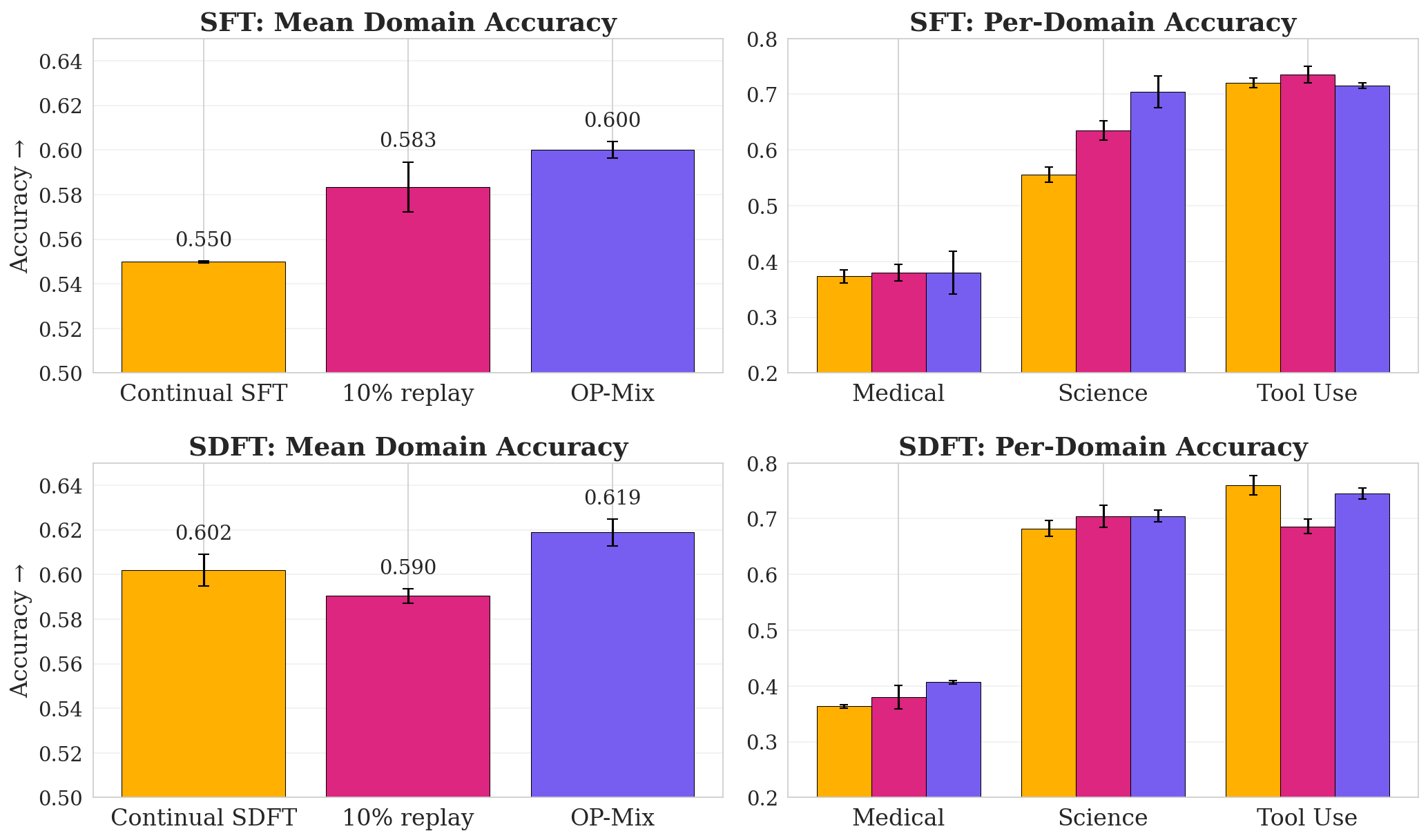
- OP-Mix matched a much more expensive method called self-distillation fine-tuning (SDFT) while using 95% less compute.
- Even better, combining OP-Mix with SDFT gave the top score, showing they help in different ways.
Overall, OP-Mix “Pareto-dominates” on efficiency: for the amount of compute you spend, no other method gives better performance across these settings.
Why are these results important?
- One method for the whole journey: Instead of using different techniques for each training stage, OP-Mix works across all of them.
- Saves time and money: Training large models is expensive. OP-Mix cuts compute costs while keeping or improving performance.
- Handles change well: As new data shows up (new tasks, new topics), OP-Mix can quickly adjust the mix without forgetting older skills.
- Uses the real model (on-policy): It avoids the common trap of relying on smaller proxy models, which often don’t behave like the big one you care about.
What could this mean for the future?
- Faster updates: Companies and labs can update models more often as new data arrives, without paying the full cost each time.
- Greener AI: Less compute means less energy usage.
- Simpler pipelines: Training can be seen as one continuous process, not several disconnected phases needing special tools.
- Next steps: Testing OP-Mix at even larger scales and with more types of data, and applying it to other training goals like reward-based tuning.
In short
OP-Mix is like a smart smoothie chef for AI: it learns which ingredients to mix, keeps adjusting as new flavors arrive, tests recipes quickly with small attachments instead of cooking from scratch, and serves a drink that’s tastier with less effort.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to enable concrete follow-up work:
- Frontier-scale validation: Does OP-Mix’s LoRA-based on-policy proxy and linear interpolation remain accurate and compute-efficient at 70B+ parameters and multi-trillion-token regimes?
- Many-domain scalability: How does the approach behave when the number of domains grows to 10–100+? What is the sample complexity (number of interpolation points P) required to fit reliable mixture surfaces in high-dimensional simplices?
- Old-mixture rigidity: OP-Mix freezes the relative proportions of previously seen (“old”) domains by collapsing them to a single “old” adapter; what is the performance loss from not re-optimizing weights within the old set as new data arrives, and how can intra-old rebalancing be made tractable?
- Approximation guarantees: Theoretical bounds only decompose error into ε_merge and ε_LoRA without characterizing them; under what architectural, data, and training conditions are these terms provably small, and how do they scale with domain dissimilarity and model size?
- Beyond linear merges: When (and why) do linear weight-space interpolations between adapters misestimate mixed-data training outcomes? Are non-linear or Fisher-weighted merges, or function-space interpolations, more faithful for certain domains?
- Adapter design sensitivity: How do LoRA rank, module placement, and adapter training budget affect the fidelity of the proxy and the optimal mixture estimate? Provide systematic ablations and default settings.
- Proxy staleness across stages: As the base model evolves, previously trained adapters may become off-policy; can incremental adapter updates or cheap adapter recycling reduce re-training overhead without hurting accuracy?
- Uncertainty-aware fitting: The regression over merged adapters is deterministic; can Bayesian or ensemble regressors quantify uncertainty in the estimated loss surface and guide adaptive sampling of α to reduce evaluations P?
- Robustness to tiny/noisy domains: How reliable is the LoRA proxy (and the resulting mixture) when new domains are small, noisy, or highly skewed (e.g., 1–10k examples)? What regularization or data filtering stabilizes the estimates?
- Objective generality: Does OP-Mix extend to reward-based/post-training objectives (e.g., RLHF, DPO, preference models) where training signals are non-stationary and adapters may learn different representations?
- Multi-objective control: The method minimizes a user-weighted sum F; how should weights w_j be set in practice (e.g., constraints, Pareto frontiers), and can OP-Mix solve constrained formulations (e.g., maintain performance floors on legacy domains)?
- Prior and regularization selection: How sensitive are mixtures to the KL regularization strength λ and prior μ? Provide principled schemes (e.g., data-quality-aware priors, hyperpriors, annealing schedules) and ablations.
- Warmup dependence: Pretraining uses a fixed 20% ERM warmup; what are the effects of warmup duration and alternative curricula on mixture quality and downstream/generalization?
- Ordering effects at scale: While some orderings are tested, how does OP-Mix fare under adversarial or highly correlated domain arrival orders, and can it detect/order domains to minimize forgetting?
- Fairness/safety constraints: Can OP-Mix incorporate fairness, toxicity, or safety constraints directly into the mixture optimization, and what are the trade-offs between capability gains and risk metrics?
- Out-of-domain generalization: How do mixtures optimized on the chosen eval set affect performance on unseen domains/capabilities (e.g., code, multilingual, reasoning), and does mixture tuning overfit to the in-use evaluation suite?
- Data quality and deduplication: How do cross-domain duplicates, contamination, or variable data quality distort mixture estimates, and can quality-weighted or de-duplicated sampling be integrated into OP-Mix?
- Compute and latency budgets: What are wall-clock, memory, and engineering overheads of training one adapter per new domain plus an “old” adapter in production settings with frequent data arrivals?
- Active mixture search: Instead of random simplex sampling, can adaptive or gradient-based search over α reduce evaluations while improving optimality, especially as domain count grows?
- Alternative adapters: Do other lightweight adapters (e.g., IA3, prefix-tuning, adapters for attention-only blocks) yield better proxy fidelity or efficiency trade-offs than LoRA?
- Safety under negative transfer: How does OP-Mix detect and mitigate negative transfer between conflicting domains (e.g., high interference), and can it enforce per-domain performance guardrails during mixture selection?
- Instruction tuning breadth: Results are shown on three small instruction domains; does the method hold on larger, more diverse instruction mixtures (e.g., FLAN/UltraFeedback-scale), tool-use ecosystems, and multilingual settings?
- Tokenization and modality shifts: How do tokenization differences (e.g., code vs. natural language) or modality shifts (e.g., vision-language) affect adapter interpolation validity and mixture estimation?
- Long-horizon accumulation: Does the approximation error accumulate over many continual steps, and can periodic “recalibration” (e.g., selective re-training or adapter pruning) prevent drift?
- Baseline coverage: How does OP-Mix compare to stronger continual-learning baselines (e.g., rehearsal buffers with adaptive sampling, EWC/L2 regularizers, parameter-isolation or orthogonal LoRA methods) under matched compute?
Practical Applications
Practical Applications of OP-Mix (On-Policy Data Mixing)
OP-Mix is a lifecycle-wide data-mixing algorithm for LLMs that uses on-policy LoRA adapters and adapter interpolation to cheaply simulate candidate mixtures, enabling efficient, continual optimization of data composition across pretraining, midtraining, and instruction tuning. Below are actionable, real-world applications derived from its findings and methods.
Immediate Applications
These can be deployed with current tools and practices in industry and academia.
- Lifecycle-wide data-mix optimizer for foundation model training (Software/AI industry)
- What: Replace static or proxy-based data schedules with OP-Mix to continuously optimize token allocation across corpora throughout pretraining, midtraining, and instruction tuning.
- Tools/products/workflows:
- “Data Mix Manager” service integrated into training pipelines (PyTorch/Lightning/Ray) that: (1) trains per-domain LoRA adapters on the current base model, (2) evaluates adapter interpolations via forward passes, (3) fits log-linear regressors, and (4) emits an updated sampling distribution.
- Mixture prior and CVXPY-backed optimization to incorporate business constraints.
- A “LoRA bank” storing per-domain adapters tied to the current model checkpoint.
- Assumptions/dependencies:
- Domain labels for datasets and a batch sampler capable of mixture-based sampling.
- The LoRA/linear-interpolation proxy tracks full finetuning well (supported up to 530M–7B in the paper; behavior at >70B is unverified).
- Access to a small evaluation harness whose metrics correlate with end goals.
- Continual midtraining for enterprise domain adaptation (Healthcare, Finance, Education, Software)
- What: Incorporate new high-quality corpora (e.g., medical guidelines, financial regulations, developer docs) while mitigating forgetting of prior capabilities and avoiding full retraining.
- Tools/products/workflows:
- OP-Mix step executed on new-data arrival: train LoRA for the new domain and a single LoRA for “old” data, interpolate to select old/new weights, then resume training with the computed mix.
- Reported savings: matches retraining and on-policy distillation quality with ~66% and ~95% less compute respectively in the evaluated settings.
- Assumptions/dependencies:
- Some replay or continued access to “old” data (or a curated subset) for adapter fit and evaluation.
- Organizational policy must allow mixing of historical and new data; privacy and data-locality constraints must be respected.
- Continual instruction tuning under tight compute budgets (Software, Consumer AI, EdTech)
- What: Maintain or improve multi-skill performance as new instruction datasets arrive, with minimal compute; optionally compose with self-distillation to boost performance.
- Tools/products/workflows:
- Add OP-Mix to existing SFT pipelines (and optionally SDFT). Use OP-Mix alone to approximate SDFT gains or combine for the best results.
- “Skill Balancer” workflow for instruction data: LoRA per skill/dataset → interpolation → optimized mixture → SFT pass.
- Assumptions/dependencies:
- Enough task-aligned evaluation data to reflect performance priorities.
- Distillation-specific compute assumptions if composing with SDFT.
- Pretraining mixture rebalance after warmup (Software/AI industry)
- What: After an ERM warmup, automatically reweight corpora to improve perplexity and downstream performance with less tuning and fewer proxy runs.
- Tools/products/workflows:
- Scheduled OP-Mix checkpoints (e.g., every 10–20% tokens) to re-estimate mix as learning dynamics evolve.
- Assumptions/dependencies:
- Multi-domain pretraining corpora with scalable per-domain sampling.
- Data budgeting and compute-aware training planning (Energy, Finance/Operations, MLOps)
- What: Forecast ROI of adding or upweighting a dataset using LoRA-based “what-if” analysis before committing to full training runs.
- Tools/products/workflows:
- A lightweight evaluation harness that computes the fitted loss surface from LoRA merges and predicts expected changes in perplexity/accuracy per token.
- Assumptions/dependencies:
- Proxy accuracy holds for the planned training regime; accurate internal cost models for planning.
- Dataset triage and acquisition decisions (Academia, Data curation teams)
- What: Quickly assess the marginal utility of candidate datasets (or cleaned variants) and select the best additions to a corpus.
- Tools/products/workflows:
- Triage panel: train LoRA adapters for candidate sources, rank them by OP-Mix’s estimated benefit under fixed token budgets.
- Assumptions/dependencies:
- Representative evaluation metrics; small LoRA overfitting on tiny datasets must be monitored.
- Compliance and regionalization-aware data scheduling (Policy & Regulated sectors)
- What: Maintain performance while satisfying jurisdictional or policy constraints (e.g., exclude certain geographies; weight privacy-preserving corpora higher).
- Tools/products/workflows:
- Mix optimization with KL regularization to a policy-defined prior (e.g., caps per region or per content class).
- Assumptions/dependencies:
- Robust data provenance and policy-to-prior mapping; governance to review outcomes.
- Strong baseline for continual learning and forgetting mitigation (Academia, Research)
- What: Use OP-Mix as a compute-efficient, on-policy baseline for continual learning studies and ablation frameworks.
- Tools/products/workflows:
- Open-source OP-Mix modules plus evaluation harnesses for reproducible CL experiments.
- Assumptions/dependencies:
- Community adoption and standardized dataset-domain taxonomies.
Long-Term Applications
These require further scaling, validation, or integration work.
- Extension to RLHF and reward-based post-training (Software/AI industry)
- What: Use LoRA-based on-policy proxies to mix preference/reward datasets and guide RLHF data schedules.
- Potential tools/workflows:
- “Reward Mix Optimizer” that trains LoRA adapters on preference data or policy-gradient snapshots, then interpolates to choose data/reward proportions.
- Assumptions/dependencies:
- LoRA fidelity for RL objectives; stable mapping between proxy surface and RL outcomes.
- Frontier-scale deployment (70B+ models and larger domain counts) (AI labs, Cloud providers)
- What: Integrate OP-Mix into frontier pipelines to cut mixture-search compute as domains proliferate.
- Potential tools/workflows:
- Distributed LoRA training and evaluation services; adapter registries versioned with model checkpoints; automated domain discovery and labeling.
- Assumptions/dependencies:
- Empirical validation that adapter interpolation remains predictive at scale and with 10–100+ domains; memory and I/O optimizations for large adapter banks.
- Multimodal and robotics instruction/data mixing (Robotics, Multimodal AI)
- What: Apply on-policy mixing to language–vision–action datasets, balancing general language, perception, and task-specific instructions for embodied agents.
- Potential tools/workflows:
- Modality-specific adapters (e.g., for vision encoders and language decoders) with joint interpolation and mixture search.
- Assumptions/dependencies:
- Linear mode connectivity and LoRA efficacy across multimodal architectures; aligned evaluation suites.
- Fairness and representation-aware governance of training data (Policy, Responsible AI)
- What: Optimize mixtures under fairness constraints (e.g., demographic/language representation targets) and audit data schedules as part of governance.
- Potential tools/workflows:
- Constraint-augmented OP-Mix (e.g., group quotas, disparity penalties) and dashboards for auditors.
- Assumptions/dependencies:
- Reliable metadata and measurements for protected groups; clear policy-to-optimization translation.
- Near-real-time continual learning for deployed assistants (Consumer AI, Enterprise AI)
- What: Nightly/weekly updates using new interaction logs and curated feedback, with mixture schedules that preserve stability while adding capabilities.
- Potential tools/workflows:
- “Rolling Mix” pipelines that train new adapters on fresh logs and re-optimize mixtures on a fixed budget.
- Assumptions/dependencies:
- Privacy-preserving data handling; robust evaluation to prevent regressions/drift; guardrails for overfitting recent data.
- Data marketplace enablement via adapter proxies (Ecosystem/Platforms)
- What: Dataset providers ship LoRA proxies alongside datasets, letting buyers preview impact through OP-Mix before purchase or integration.
- Potential tools/workflows:
- Standards for adapter packaging, signing, and compatibility metadata; marketplaces that host adapter previews.
- Assumptions/dependencies:
- Trusted sharing protocols, IP/licensing clarity, and security vetting for third-party adapters.
- Unified “always online” training decisions (Beyond mixing) (Research, Tooling)
- What: Generalize the online decision framing to learning-rate schedules, objective selection (e.g., distillation vs. CE), and curriculum strategies.
- Potential tools/workflows:
- A broader “Training Policy Optimizer” that co-optimizes mixtures, LR schedules, and objectives using on-policy proxies.
- Assumptions/dependencies:
- Reliable proxy objectives for each decision dimension; orchestration that safely tests multiple policies.
- Continuous knowledge updating for high-stakes domains (Healthcare, Finance, Legal)
- What: Stream new guidelines/regulations into models without eroding general knowledge, with auditable schedules and compute bounds.
- Potential tools/workflows:
- Compliance-grade OP-Mix: explainable mixture reports, change logs, and rollback mechanisms.
- Assumptions/dependencies:
- Gold-standard evals for domain correctness; human oversight loops.
Notes on cross-cutting feasibility
- OP-Mix depends on the quality of on-policy LoRA proxies and the linear interpolation assumption (supported in the paper’s scale range). Validate proxies at your target scale and domain count.
- Mixture optimization requires informative, stable evaluation metrics aligned with deployment goals; build or adopt robust eval suites.
- Governance, privacy, and data-locality constraints may limit replay or mixing; incorporate policy constraints as priors or hard constraints in optimization.
- Operationally, teams need a domain-labeled dataset registry, adapter storage/versioning tied to model checkpoints, and dataloaders that respect per-domain sampling distributions.
Glossary
- Adapter interpolation: Linearly combining the parameters of multiple trained adapters to approximate training on a mixed dataset without additional optimization. "Interpolate adapters to simulate different data mixtures without retraining and then estimate the optimal mixture ratio."
- Catastrophic forgetting: The degradation of performance on previously learned tasks when training on new data. "During continual midtraining, continual SFT suffers severe catastrophic forgetting (Figure \ref{fig:continual-learning-dynamics})"
- Chinchilla-optimal: A data–compute scaling regime that specifies optimal token counts for a given parameter count to maximize performance. "to Chinchilla-optimal \citep{hoffmann2022training} token counts of 3.2B, 6.5B, and 10.5B, respectively."
- Continual instruction tuning: Successively fine-tuning a LLM on streams of new instruction-following datasets over time. "Across pretraining, continual midtraining, and continual instruction tuning, OP-Mix consistently finds near-optimal mixtures"
- Continual learning: A training paradigm where new datasets arrive over time and the model must learn them without forgetting previously acquired knowledge. "This induces a natural continual learning problem, where the goal is to incorporate new data without catastrophically forgetting what the model has already learned."
- Continual midtraining: A stage between pretraining and instruction tuning where a pretrained model is further trained on curated datasets, here in a sequential/continual fashion. "Across pretraining, continual midtraining, and continual instruction tuning, OP-Mix consistently finds near-optimal mixtures"
- Data mixture: A probability distribution over data domains specifying the sampling proportions used during training. "A data mixture is a probability vector "
- Data mixing: The process of choosing how to combine different datasets or domains during training to optimize downstream performance. "Data mixing decides how to combine different sources or types of data and is a consequential problem throughout LLM training."
- Distributionally robust optimization: An optimization approach that seeks solutions robust to worst-case shifts within a set of distributions. "several online data mixing algorithms have been proposed for pretraining based on distributionally robust optimization, including DoReMi \citep{xie2023doremi}, DoGE \citep{fan2024doge} and GRAPE \citep{fan2025grape}."
- Empirical Risk Minimization (ERM): Training by minimizing average loss on the observed (empirical) data distribution, often equivalent to uniform or size-proportional sampling. "ERM samples from each data domain with probability proportional to domain size, equivalent to not optimizing the data mixture."
- Kullback–Leibler (KL) divergence: A measure of dissimilarity between two probability distributions; used here as a regularizer toward a prior mixture. "\lambda \, D_{\text{KL}!\bigl(E(\boldsymbol{\alpha}) \,\big|\, \mu\bigr)."
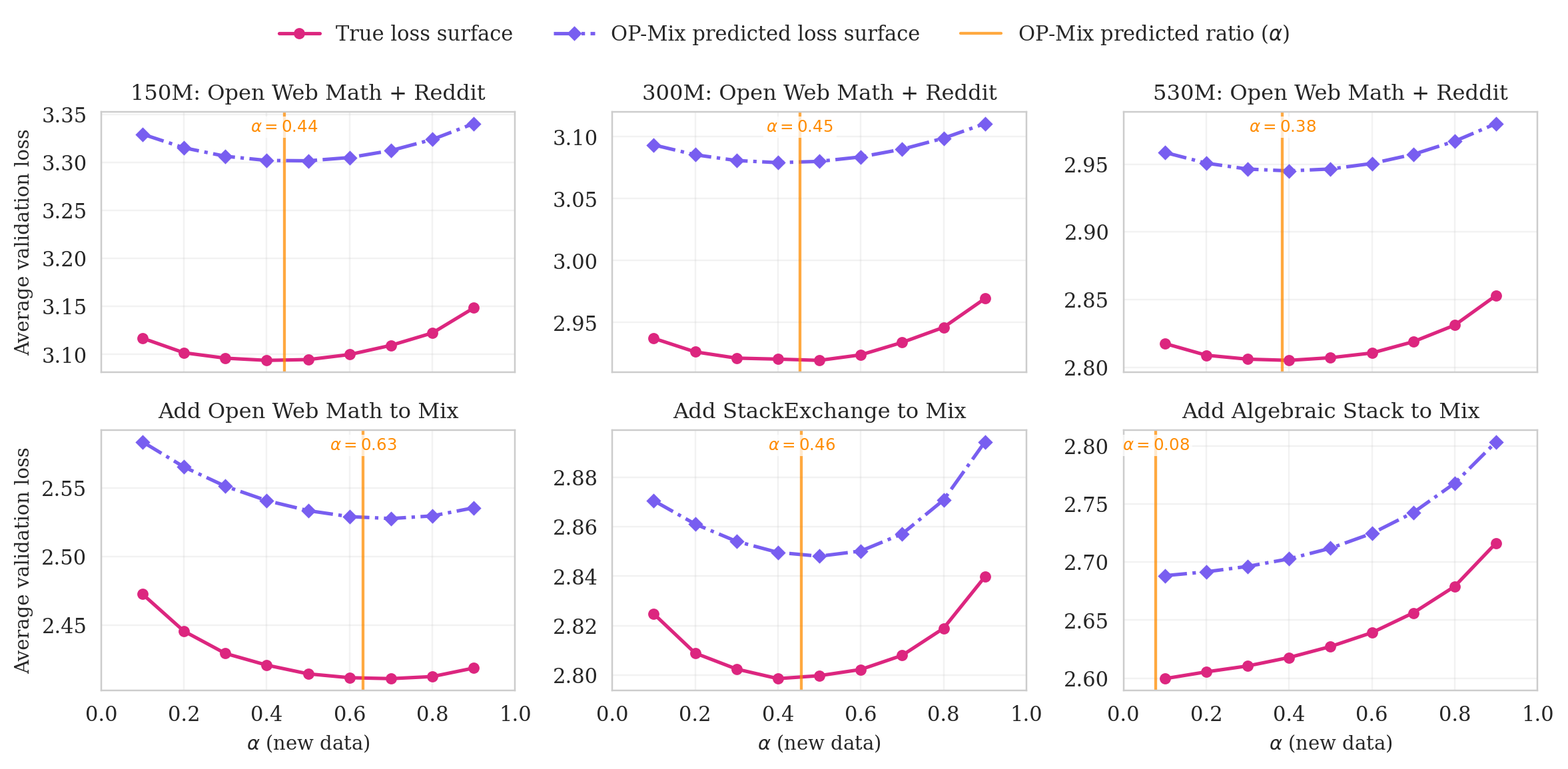
- Linear interpolation: Forming convex combinations between parameter sets (e.g., adapters) to approximate intermediate models or mixtures. "it uses linear interpolation between LoRAs as a proxy for the loss surface of full data mixing"
- Linear mode connectivity: The empirical phenomenon that different trained models can be connected by low-loss linear paths in parameter space. "Furthermore, $\varepsilon_{\text{merge}$ being small is empirically supported by linear mode connectivity \citep{lmc-lth,pmlr-v162-wortsman22a}, which observes that linear interpolation does not incur large loss spikes when the finetuned models share a base model"
- Log-linear model: A model where the logarithm of the target quantity depends linearly on inputs; used here to predict performance from mixture proportions. "Previous work has shown that future performance is well-predicted by a log-linear parametric form: "
- LoRA (Low-Rank Adaptation): An efficient fine-tuning method that adds low-rank updates to weight matrices, enabling lightweight adaptation. "OP-Mix uses Low-Rank Adaptation (LoRA, \cite{hu2022lora}) to cheaply estimate the performance of full training."
- Loss surface: The landscape mapping model parameters or mix weights to training/evaluation loss. "as a proxy for the loss surface of full data mixing"
- Off-policy: Using proxies or signals derived from a different model or state than the one currently being trained. "they rely on off-policy proxy models."
- On-policy: Using proxies or signals derived from the current model so they reflect its present learning dynamics. "keeping the proxy model on-policy with the model being trained—i.e. reflective of its current state."
- On-policy self-distillation: A distillation approach where the teacher signals are generated from the same model (or its recent checkpoints) during training. "Finally, in continual instruction tuning, OP-Mix composes with on-policy self-distillation"
- Pareto dominance: A comparison where one method is better in at least one metric without being worse in others, defining the Pareto frontier. "OP-Mix (purple) Pareto-dominates the performance-efficiency frontier"
- Perplexity: A standard language modeling metric equal to the exponentiated average negative log-likelihood; lower is better. "In pretraining, OP-Mix improves upon training without mixing by 6.3\% in average perplexity."
- Proxy model: A smaller or auxiliary model used to cheaply estimate or predict the performance of a larger target model. "some require smaller proxy models tied to a single training phase"
- Replay-based methods: Continual learning approaches that mitigate forgetting by rehearsing or mixing in previously seen data. "OP-Mix is a replay-based method."
- Reinforcement Learning from Human Feedback (RLHF): Training that optimizes a model using reward signals derived from human preference judgments. "Future work can extend OP-Mix to reward-based objectives like RLHF \citep{ouyang2022training}"
- Scaling law: A predictable relationship (often power-law or log-linear) that links performance to factors like data mixture, data size, or model size. "A common technique is to fit the scaling law by randomly sampling mixtures from the probability simplex"
- Self-distillation: Training a model to match its own predictions or outputs, often improving performance or stability. "on-policy self-distillation"
- Self-Distillation Finetuning (SDFT): A specific fine-tuning procedure that repeatedly generates and distills from the model’s own outputs. "Self-Distillation Finetuning (SDFT, \citet{shenfeld2026selfdistillation})"
- Simplex (probability simplex): The set of nonnegative vectors that sum to one, commonly used to represent mixture proportions. "fit the scaling law by randomly sampling mixtures from the probability simplex"
- Supervised fine-tuning (SFT): Fine-tuning a pretrained LLM on labeled input–output pairs using supervised objectives like cross-entropy. "Applied atop standard SFT during continual instruction tuning, OP-Mix recovers the gains of self-distillation finetuning"
- Weight-Stable-Decay-Simplified (WSD-S): A learning rate schedule designed to improve stability in continual learning settings. "WSD-S learning schedule, a method specifically designed for continual learning \citep{wen2025understanding}."
Collections
Sign up for free to add this paper to one or more collections.