SceneParser: Hierarchical Scene Parsing for Visual Semantics Understanding
Abstract: General scene perception has progressed from object recognition toward open-vocabulary grounding, part localization, and affordance prediction. Yet these capabilities are often realized as isolated predictions that localize objects, parts, or interaction points without capturing the structured dependencies needed for interaction-oriented scene understanding. To address this gap, we introduce Hierarchical Scene Parsing, an interaction-oriented parsing task that represents physical scenes as explicit scene -> object -> part -> affordance hierarchies with cross-level bindings. We instantiate this task with SceneParser, a VLM-based parser trained for unified hierarchical generation with structural-completion pseudo labels and curriculum learning. To support training and evaluation, we construct SceneParser-Bench, a large-scale benchmark built with a scalable hierarchical data engine, containing 110K training images, a 5K validation split, 777K objects, 1.14M parts, 1.74M affordance annotations, and 1.74M valid object-part-affordance chain instances. We further introduce Level-1 to Level-3 conditional metrics and ParseRate to evaluate localization, cross-level binding, and hierarchical completeness. Experiments show that existing MLLMs and perception-stitching pipelines struggle with hierarchical parsing on our SceneParser-Bench, while SceneParser achieves stronger structure-aware performance. Besides, ablations, evaluations on COCO and AGD20K, and a downstream planning probe demonstrate that our SceneParser is compatible with conventional tasks and provides an actionable representation for visual understanding.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces a new way for computers to “understand” pictures called Hierarchical Scene Parsing. Instead of just finding objects (like “a door” or “a cup”), it asks the computer to:
- find objects,
- break each object into its useful parts (like a door’s handle),
- and say what actions those parts allow (like “pull” on the handle),
all linked together in a neat, tree-like structure: scene → object → part → affordance.
“Affordance” means what you can do with something. For example, a handle affords “pull,” a button affords “press,” and a mug’s handle affords “grip.”
The team builds a model called SceneParser to do this, plus a large dataset and new tests to measure how well it works.
The big questions the paper asks
- How can we move from scattered predictions (just boxes and labels) to a clear, connected picture of a scene that tells us what we can actually do with things?
- Can a single model directly “write out” a scene as an object → part → action (affordance) hierarchy?
- How do we build enough training data and fair tests for this new kind of output?
- Does a structured approach work better than current multimodal models or “stitching together” separate object/part/affordance tools?
- Will this structured understanding help with normal tasks (like object detection) and with planning actions?
How they approached it (in everyday terms)
Think of a scene like a family tree:
- The “scene” is the top.
- “Objects” (like door, cup, chair) are the children.
- “Parts” (handle, lid, button) are the objects’ children.
- “Affordances” (pull, press, grip) are the actions attached to parts, often with a small point showing where to act.
The authors did three main things:
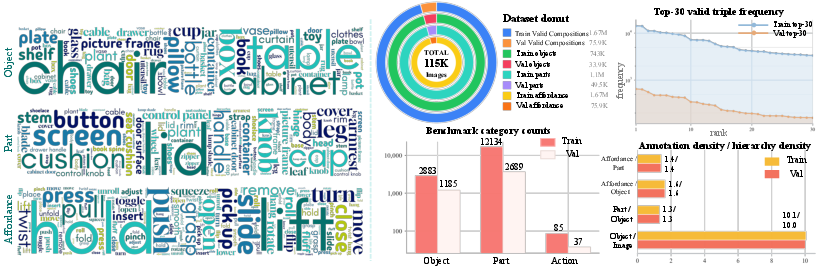
1) Built a large benchmark (SceneParser-Bench)
They made a big training and testing collection with:
- 110,000 training images and 5,000 validation images,
- 777k objects, 1.14M parts, and 1.74M affordance annotations,
- all connected into 1.74M object–part–affordance chains,
- covering thousands of object and part categories and 85 action types.
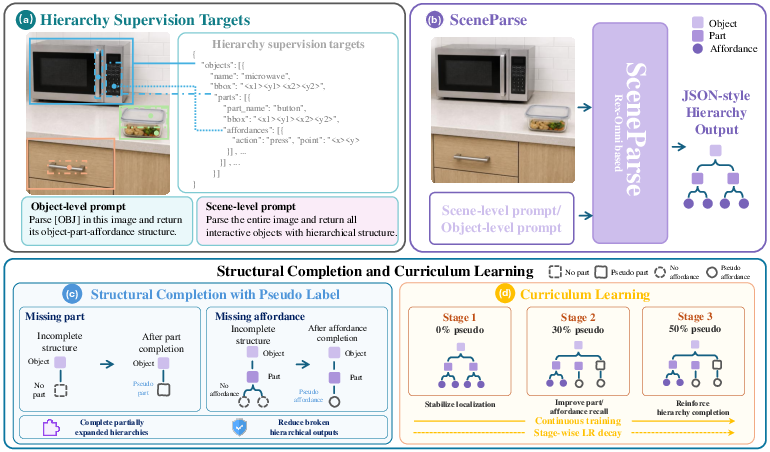
How they created it (three-stage “data engine”):
- Stage 1: Find objects in the full image (bounding boxes = rectangles around objects).
- Stage 2: For each object, zoom in and find its parts (again, boxes).
- Stage 3: For each relevant part, mark what action it supports and a point where you would do that action (like a dot on the handle). They then link these together carefully and remove duplicates or inconsistent links.
2) Designed a model (SceneParser) that generates hierarchies
SceneParser is a vision-LLM (VLM). It “reads” the image and “writes” a structured, JSON-like hierarchy that lists:
- objects and their boxes,
- each object’s parts and their boxes,
- each part’s possible actions and a point on the image.
Two training tricks helped:
- Structural-completion pseudo labels: If some objects don’t have part or affordance annotations, the model adds safe “placeholder” entries so the structure stays intact. This reduces broken or incomplete trees during training.
- Curriculum learning: Like learning in levels—start with reliable, simpler data (objects/parts/points that are well-labeled), then gradually add more with placeholders. This balances accuracy and completeness.
3) Created new, structure-aware evaluation
They introduced conditional levels to fairly test the “tree”:
- Level 1 (L1): Object is correct if the name and location are correct.
- Level 2 (L2): Part is only counted correct if its parent object is already correct.
- Level 3 (L3): Affordance is only correct if the object and part are correct, the action name is right, and the point lies in the right area.
They also made ParseRate: a completeness score that checks whether models expand objects into the parts and affordances they should (not just detect the object and stop).
Main findings and why they matter
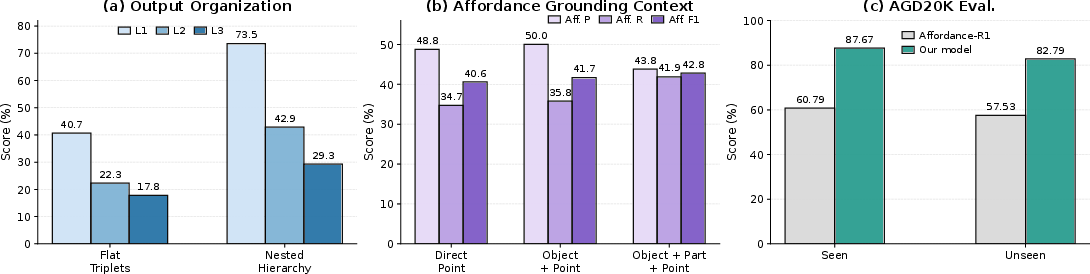
- Existing multimodal models often do fine on objects (L1) but drop sharply on parts and especially on affordances (L2 and L3). In other words, finding objects is not the same as understanding how to interact with them.
- “Stitching together” separate tools for objects, parts, and actions looks good on paper but breaks down when you need clean links between levels (object ↔ part ↔ action).
- SceneParser does much better on the full chain (L2/L3) and on ParseRate (the completeness measure). It produces more coherent, linked structures.
- An ablation (side test) showed a nested, tree-like output beats a “flat list of triplets.” The shape of the output itself matters.
- Giving the model object and part context improved affordance (action point) accuracy—actions are easier to place when you know exactly which part they belong to.
- Curriculum learning improved how “complete” the hierarchies were without hurting accuracy much.
- Transfer to standard tasks:
- On COCO object detection, SceneParser’s object boxes remain competitive, even though it’s not just an object detector.
- On an affordance dataset (AGD20K), SceneParser placed action points more accurately than a baseline on both seen and new objects.
- For planning tasks, providing the parsed hierarchy helped a planner produce more complete and consistent action plans (e.g., choosing the right part to interact with).
Why this matters: Robots and assistive systems don’t just need to “see” objects; they need to know what to do with them. A clear, connected scene breakdown—what’s there, what parts matter, and where to act—makes next steps (like planning a task) more reliable.
What this could lead to
- Better robot helpers: A robot that knows “that’s a door → that’s the handle → we can pull here” is more dependable than one that only sees “door.”
- Safer, clearer decisions: Structured outputs are interpretable—humans can check them and spot mistakes.
- Stronger generalization: Knowing parts and actions can help models deal with new objects (“this also has a handle, so it probably affords pulling”).
Limitations and future work:
- Some of the dataset labels come from automatic tools, so there may be noise.
- It works in 2D images; it doesn’t yet model 3D shapes or physical forces.
- The planning test is qualitative; real robot trials would be the next step.
- Extremely rare (long-tailed) combinations of objects, parts, and actions are still hard and need better generalization.
In short
This paper takes scene understanding a step closer to how people think and act in the real world: not just recognizing “what” is there, but “where on it” to do “what action,” all tied together in a clear structure. SceneParser and its new benchmark show that this structured approach is both doable and useful for future interactive AI systems.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
Dataset and Benchmark (SceneParser-Bench)
- Quantify and mitigate annotation noise introduced by the automatic data engine (GPT-5, SAM3, multi-model fusion); provide a human-audited subset with inter-annotator agreement to calibrate true error rates at object, part, and affordance levels.
- Assess reproducibility by replacing closed-source components (e.g., GPT-5, SAM3) with open-source alternatives and reporting performance sensitivity to the data-engine choices.
- Release a normalized ontology (synonym mappings, hierarchical taxonomies) for object/part/affordance names and evaluate how strict string matching penalizes semantically equivalent predictions; add ontology-aware matching in evaluation.
- Measure and report the accuracy of the hierarchy reconstruction step (textual + geometric linking of affordances to parts) with an error analysis of mis-assignments and failure modes in ambiguous cases.
- Validate affordance interaction points (currently sampled from boxes/masks) with human-labeled interaction clicks; quantify how point-sampling strategies bias training and L3 scores.
- Address domain bias from building on EgoObject (egocentric, indoor-heavy): evaluate cross-domain generalization to exocentric, industrial, outdoor, and robotic workspaces; consider adding such splits.
- Provide explicit few-shot/long-tailed and compositional generalization splits to test rare object–part–affordance combinations and unseen compositions.
- Introduce a held-out test set and/or evaluation server to prevent overfitting to the 5K validation set; document train/val leakage checks.
Representation and Task Formulation
- Move beyond 2D boxes and points: incorporate masks, depth/multi-view cues, 3D geometry (surface normals, contact patches), and uncertainty in location/extent to better support manipulation.
- Support variable-depth hierarchies (subparts and recursive part structures) instead of a fixed scene → object → part → affordance chain; explore parsing of functional assemblies.
- Represent inter-object relations and relational affordances (e.g., “pour from cup into bowl,” “open door with handle”), including multi-object and multi-parent dependencies that current per-object chains cannot capture.
- Enrich affordance outputs beyond a single point (e.g., orientation, approach vector, contact region, force/torque constraints), enabling more actionable control interfaces.
Modeling and Training
- Analyze the impact of 1000-bin coordinate quantization on localization accuracy (especially small/elongated parts) and compare against continuous or mixed discrete–continuous decoding.
- Report the rate and impact of invalid or ill-formed JSON generations; investigate grammar-constrained decoding, structured decoders, or pointer mechanisms to guarantee well-formed hierarchies.
- Examine possible biases introduced by placeholder tokens (e.g., the model overusing placeholders or under-expanding); compare against alternative formulations (explicit “no-part/no-affordance” classification, constrained decoding, or expansion predictors).
- Provide sensitivity studies for curriculum design (stage lengths, pseudo-label ratios, temperature schedules); explore self-paced, competence-based, or uncertainty-aware curricula.
- Add calibrated confidence estimates at each level and study hierarchical confidence propagation (e.g., how low object confidence should suppress part/affordance assertions).
Evaluation Protocol
- Extend beyond exact string matches and greedy one-to-one matching: add ontology-aware label matching, soft/semantic similarity scoring, and alternative matching strategies for many-to-many or shared parts.
- Report metrics across a range of IoU thresholds and include AP/mAP and area-under-curve summaries; clarify defaults (e.g., τ values) and analyze robustness to threshold choices.
- Revisit L3 spatial validity: the fallback to the parent part box when affordance boxes are missing may inflate scores—report results with and without this fallback and on human-verified affordance regions.
- Add efficiency and resource metrics (inference latency, memory, and cost per image) for scene-level parsing with large hierarchies; profile scaling with object count.
- Evaluate robustness to prompt variations and paraphrases in text-conditioned settings (naming variance, synonyms, multi-lingual labels).
Generalization and Robustness
- Stress-test performance under occlusions, clutter, small objects, textureless parts, transparent/reflective materials, and unusual viewpoints; include ablations for these factors.
- Evaluate zero-shot generalization to unseen objects, parts, and affordances (OOD settings) with explicit splits and report failure characterizations.
- Test language robustness and cross-lingual generalization (non-English labels, mixed-language scenes) for both training and evaluation.
- Analyze scalability to scenes with dozens of objects and deep hierarchies, including decoding stability and failure rates under long outputs.
Downstream Use and Embodied Validation
- Move beyond qualitative planning probes: conduct closed-loop robotic experiments (navigation, grasp-and-use, tool manipulation) with success rates, safety metrics, and ablations on hierarchy usage vs. baselines.
- Bridge parsed affordances to executable actions by deriving grasp poses, approach directions, and constraints; quantify how hierarchical detail improves task success and reduces failure/safety risks.
- Study how uncertainty and errors at different hierarchy levels affect downstream planning; design planners that can exploit confidence and structure (e.g., re-planning, active perception).
Broader Considerations
- Investigate potential biases in affordance annotations (e.g., unsafe suggestions, culturally specific use) and develop safeguards or human-in-the-loop correction mechanisms.
- Clarify licensing and reproducibility constraints stemming from closed-source models in the data engine; provide instructions and expected performance when substituting open alternatives.
Practical Applications
Overview
Based on the paper “SceneParser: Hierarchical Scene Parsing for Visual Semantics Understanding,” below are actionable, real-world applications that leverage its findings, methods, benchmark, and evaluation protocol. Each item specifies sector(s), concrete use cases, possible tools/products/workflows, and assumptions or dependencies.
Immediate Applications
- Robotics (manipulation and mobile manipulation)
- Use case: Grasping and interaction targeting via object→part→affordance chains (e.g., grasp mug by handle; press appliance button; pull door handle).
- Tools/products/workflows:
- Robot perception module that outputs JSON hierarchies to planning stacks (e.g., a ROS2 node
scene_parserfeeding MoveIt grasp planners or behavior trees). - “Hierarchy guardrail” in existing pipelines: reject affordance points not bound to a valid part/object.
- Assumptions/dependencies:
- 2D image input; no explicit 3D geometry or force modeling.
- Works best in controlled lighting and object distributions similar to training data (egocentric, indoor).
- Requires integration with grasp planners and calibration for camera viewpoints.
- Warehousing and logistics
- Use case: Shelf replenishment and pick-and-place—identify flaps, handles, zippers, or tabs; target pull/push affordance points to reduce failures.
- Tools/products/workflows:
- Plug-in for vision-based picking systems to propose “functional grasp points” with parent object/part context.
- Assumptions/dependencies:
- Non-safety-critical tasks first; domain-specific finetuning recommended for packaging variations.
- Industrial quality control and assembly verification
- Use case: Check presence and placement of functional parts (e.g., caps, levers, buttons) and their intended affordances (twist, press), linking parts to products.
- Tools/products/workflows:
- Visual inspection software that flags missing/incorrect parts or misaligned affordance regions on production lines.
- Assumptions/dependencies:
- 2D-only limits—no depth/dynamics; may need multi-view cameras or depth for robustness.
- Smart home and consumer devices
- Use case: On-device guidance for interaction (“where to press/turn”) for appliances; voice assistants can ground instructions on parts/affordances in camera view.
- Tools/products/workflows:
- Mobile/edge app that overlays affordance points with labels (“press power button”) on a live camera feed.
- Assumptions/dependencies:
- Real-time performance on edge hardware; privacy constraints for in-home cameras.
- AR/VR and assistive user interfaces
- Use case: AR overlays that highlight actionable parts for training or accessibility (e.g., show “pull here” on doors; “press here” on kiosks).
- Tools/products/workflows:
- AR SDK module that consumes model JSON output for UI overlays.
- Assumptions/dependencies:
- Latency and robustness in diverse environments; not yet modeling 3D alignment.
- E-commerce and media search
- Use case: Fine-grained search and tagging (e.g., “products with zippers,” “bottle with cap to twist”) for product images or user-generated content.
- Tools/products/workflows:
- Index pipelines that extract object/part/affordance tags for media catalogs.
- Assumptions/dependencies:
- Domain adaptation for retail imagery; handle long-tail categories.
- Academic research and benchmarking
- Use case: Evaluate perception systems with structure-aware metrics (L1/L2/L3, ParseRate) that condition lower-level correctness on upper-level matches.
- Tools/products/workflows:
- Adoption of SceneParser-Bench and metrics for comparing VLMs/MLLMs beyond flat detection.
- Assumptions/dependencies:
- Community uptake; clarity on evaluation thresholds and matching rules.
- Dataset and annotation acceleration
- Use case: Bootstrapping hierarchical annotations from raw images using the paper’s hierarchical data engine (object grounding → part parsing → affordance parsing).
- Tools/products/workflows:
- Semi-automatic labeling tools that generate pseudo-labels for objects/parts/affordances; human-in-the-loop correction.
- Assumptions/dependencies:
- Engine references GPT-5/SAM3; practical substitutions (current VLMs/segmenters) may be needed; noise control processes required.
- Agentic systems and multimodal LLMs
- Use case: Provide structured visual “world state” for agents (e.g., tool-use agents) to reduce hallucinations and improve plan consistency.
- Tools/products/workflows:
- Middleware that converts images to JSON hierarchies fed into planners or chain-of-thought prompts.
- Assumptions/dependencies:
- Agent needs to consume structured inputs; no dynamics/physics yet.
- Education and training content
- Use case: Instructional materials that highlight functional parts and demonstrate correct interaction points for lab equipment and tools.
- Tools/products/workflows:
- Authoring tools that auto-annotate images with object-part-affordance labels and hotspots.
- Assumptions/dependencies:
- Domain finetuning for specific instruments and settings.
Long-Term Applications
- Safety-critical robotics (household assistants, cobots, surgical support)
- Use case: Reliable, explainable action targeting with explicit object→part→affordance chains, integrated with 3D geometry, force, and compliance constraints.
- Tools/products/workflows:
- “Affordance API” married with tactile sensing and motion planners; certification-ready perception stack using hierarchy-aware metrics.
- Assumptions/dependencies:
- Requires 3D, dynamics, and strong robustness; regulatory validation; extensive domain data.
- Field maintenance and industrial operations
- Use case: Inspect and operate complex control panels/pipes/valves—identify functional parts and safe actuation points in variable conditions.
- Tools/products/workflows:
- Helmet-mounted or drone-based systems that guide technicians; audit workflows logging parts and actions.
- Assumptions/dependencies:
- Harsh environments; multi-view/thermal/depth integration; safety protocols.
- Autonomous vehicles and urban robots
- Use case: Understanding interactive urban elements (crosswalk buttons, door handles, kiosks) for service robots/humanoids.
- Tools/products/workflows:
- City-scale perception modules combining hierarchical parsing with SLAM and scene graphs.
- Assumptions/dependencies:
- Open-world variability, occlusions; requires 3D mapping and robust domain adaptation.
- Healthcare and assistive care
- Use case: OR equipment interaction support; hospital device identification and correct-use guidance for staff or assistive robots.
- Tools/products/workflows:
- Clinically validated perception layer that grounds instruments’ functional parts and safe affordance points.
- Assumptions/dependencies:
- Strict regulatory/sterility constraints; extremely high precision/recall; legal compliance.
- Policy, standards, and certification
- Use case: Procurement and certification benchmarks for embodied AI that require cross-level binding and structural completeness (L1–L3, ParseRate).
- Tools/products/workflows:
- Standards bodies adopt hierarchy-aware evaluation for compliance across sectors (manufacturing, healthcare, domestic robotics).
- Assumptions/dependencies:
- Consensus building in industry/academia; reproducible test suites.
- Smart-home safety and compliance
- Use case: Continuous monitoring of dangerous affordances (e.g., uncovered stove knobs, unlocked cabinets) and childproofing checks.
- Tools/products/workflows:
- Home monitoring hubs that flag risky affordances and suggest mitigations.
- Assumptions/dependencies:
- Privacy-preserving deployment; extremely low false positives in diverse homes.
- Digital twins and CAD integration
- Use case: Map 2D-observed objects to 3D CAD part hierarchies and annotate actionable regions; synchronize “interactables” in digital twins.
- Tools/products/workflows:
- Tooling to fuse SceneParser outputs with CAD metadata; simulation-to-real pipelines that maintain affordance correspondences.
- Assumptions/dependencies:
- 2D→3D correspondence, pose estimation, and multi-view reconstruction.
- Creative industries and game engines
- Use case: Auto-identify interactable components for in-game objects to drive game logic or AR experiences (e.g., doors, drawers, buttons).
- Tools/products/workflows:
- Importers that convert real images into interactable blueprints within engines (Unity/Unreal).
- Assumptions/dependencies:
- Needs 3D asset alignment; quality thresholds for user experience.
- Insurance, audits, and compliance documentation
- Use case: Visual evidence analysis focusing on functional parts (e.g., damaged handles, broken latches); verify presence/condition of safety equipment.
- Tools/products/workflows:
- Claim processing tools that tag parts/affordances and generate structured checklists.
- Assumptions/dependencies:
- Domain-specific finetuning; clear guidance on acceptable error rates.
- Agriculture and lab sciences
- Use case: Identify plant/tool parts and recommended interaction points (e.g., cut points), or lab apparatus components and their functions.
- Tools/products/workflows:
- Domain-tuned models integrated into field/lab apps for task guidance.
- Assumptions/dependencies:
- Specialized datasets; extension beyond current egocentric household bias.
Notes on Feasibility, Assumptions, and Dependencies
- Representation limits:
- Current method is 2D, image-centric (bounding boxes, points); no explicit 3D geometry, dynamics, forces, or temporal consistency.
- Long-tailed categories and rare object–part–affordance combinations may require domain-specific finetuning.
- Data and training:
- SceneParser-Bench is partly auto-labeled; noise remains despite quality control.
- The original data engine references models like GPT-5/SAM3; practical deployments may need readily available substitutes (current VLMs/segmenters) and re-tuning.
- Performance and reliability:
- Strong in non-safety-critical settings; safety-critical uses require additional validation, redundancy (e.g., depth, tactile), and stricter thresholds.
- Real-time constraints depend on hardware and model size; optimization or distillation may be necessary.
- Privacy and compliance:
- In-home/enterprise deployments must address data privacy, consent, and secure on-device processing where feasible.
- Integration:
- Best value is realized when the JSON hierarchy feeds downstream planners/agents; success depends on planner compatibility and clear affordance-to-action mappings.
Glossary
- AGD20K: A large-scale dataset for affordance understanding used to evaluate action-related perception. "Cross-task evaluations on COCO and AGD20K affordance grounding further indicate transferability to conventional tasks."
- Affordance: A perceived action possibility on an object or its part, typically labeled with an action and a point. "and each affordance is represented by an action label and an interaction point."
- Affordance grounding: Localizing and labeling action opportunities in images, often as points or regions. "Cross-task evaluations on COCO and AGD20K affordance grounding further indicate transferability to conventional tasks."
- Autoregressively: Generating outputs token-by-token in sequence, where each step conditions on previous ones. "Given an RGB image, it autoregressively generates a unified object-part-affordance hierarchy"
- Curriculum learning: A training strategy that stages data or objectives from easier to harder to stabilize learning. "We further use curriculum learning to progressively balance object-level localization stability, part decomposition, affordance grounding, and hierarchical completeness."
- Cross-level bindings: Explicit links that tie predictions across semantic levels (object→part→affordance) into a coherent structure. "represents physical scenes as explicit scene → object → part → affordance hierarchies with cross-level bindings."
- Downstream planning probe: An evaluation that tests whether the parsed structure improves subsequent planning or decision-making. "and a downstream planning probe demonstrate that our SceneParser is compatible with conventional tasks and provides an actionable representation for visual understanding."
- Flat triplet prediction: Predicting object, part, and affordance elements as independent triplets without hierarchical structure. "nested object-part-affordance generation outperforms flat triplet prediction."
- Hierarchical Scene Parsing: Parsing an image into a structured scene→object→part→affordance representation for interaction-centric understanding. "we introduce Hierarchical Scene Parsing, an interaction-oriented parsing task"
- Hierarchical data engine: A pipeline that builds multi-level (object/part/affordance) annotations and links them into hierarchies. "a large-scale benchmark built with a scalable hierarchical data engine"
- Hierarchy-aware evaluation: An assessment protocol that conditions lower-level correctness on matches at higher levels in the hierarchy. "our hierarchy-aware evaluation conditions lower-level correctness on upper-level matches"
- Interaction point: A 2D coordinate indicating where to execute an action (affordance) on a part. "and the interaction point is spatially valid."
- IoU (Intersection over Union): A metric for overlap between predicted and ground-truth boxes, used for matching. "Given an IoU threshold τ, we define three conditional levels."
- JSON-style hierarchy: A serialized, tree-structured output format representing objects, parts, and affordances. "SceneParser learns serialized object-part-affordance hierarchy targets and generates JSON-style hierarchies."
- Level-1 to Level-3 conditional metrics: Progressive evaluation levels for objects (L1), object–part pairs (L2), and full object–part–affordance chains (L3) under hierarchical constraints. "We further introduce Level-1 to Level-3 conditional metrics and ParseRate"
- MLLM (Multimodal LLM): A large model that processes both language and visual inputs for tasks like grounding and parsing. "Experiments show that existing MLLMs and perception-stitching pipelines struggle with hierarchical parsing"
- Object grounding: Localizing objects specified by categories or language descriptions in an image. "Object grounding and referring expression comprehension enable models to localize targets"
- Object-part-affordance chain: The full linked structure tracing from an object to its functional part to a specific action point. "consistent object-part-affordance chain."
- Open-vocabulary detectors: Detectors that can localize categories beyond a fixed label set, guided by text. "Open-vocabulary detectors, such as GLIP and Grounding DINO, further localize objects described by arbitrary categories, phrases, or referring expressions"
- Open-vocabulary grounding: Localizing entities using arbitrary text labels or descriptions rather than a closed label set. "toward open-vocabulary grounding"
- ParseRate: A metric measuring whether parse-eligible objects/scenes are structurally completed with required parts and affordances. "ParseRate further measures whether parse-eligible objects and scenes are structurally completed with the required part and affordance expansions."
- Perception-stitching pipelines: Systems that combine separate predictors (objects, parts, affordances) post hoc rather than producing a single structured output. "existing MLLMs and perception-stitching pipelines struggle with hierarchical parsing on our SceneParser-Bench"
- Point-in-mask accuracy: The fraction of predicted interaction points that fall inside ground-truth affordance masks. "SceneParser achieves higher point-in-mask accuracy than Affordance-R1"
- Referring expression comprehension: Understanding natural-language phrases to localize the corresponding visual target. "Object grounding and referring expression comprehension enable models to localize targets"
- Structural-completion pseudo labels: Artificial placeholders added during training to complete partial hierarchies and regularize outputs. "we introduce structural-completion pseudo labels to model valid non-expandable cases and reduce broken hierarchies."
- VLM (Vision-LLM): A model jointly trained on visual and textual data to perform tasks like grounding and structured generation. "We instantiate this task with SceneParser, a VLM-based parser"
Collections
Sign up for free to add this paper to one or more collections.

