- The paper presents a novel three-stage progressive training framework that bridges the gap between visual perception and complex spatial reasoning.
- The paper leverages the multimodal SpatialLadder-26k dataset, achieving state-of-the-art gains with up to 70.9% accuracy on spatial reasoning benchmarks.
- The paper demonstrates that reinforcement learning with chain-of-thought reasoning enhances model generalization and performance across diverse spatial tasks.
Progressive Training for Spatial Reasoning in Vision-LLMs: The SpatialLadder Framework
Introduction and Motivation
Spatial reasoning in Vision-LLMs (VLMs) remains a persistent challenge, particularly in tasks requiring the integration of perception and abstract reasoning. Existing VLMs exhibit a pronounced gap between visual perception and spatial reasoning, often failing to generalize beyond memorized patterns. The SpatialLadder framework addresses this deficit by introducing a hierarchical, progressive training methodology that systematically builds spatial intelligence from foundational perception to complex reasoning. The approach is grounded in the hypothesis that robust spatial reasoning emerges only when models are trained to first perceive, then understand, and finally reason about spatial relationships.

Figure 1: Perception-reasoning gap in spatial reasoning. Left: Three experimental conditions with increasing perceptual hints. Right: Qwen2.5-VL-3B improves with hints, but SpatialLadder achieves high performance with minimal reliance on external prompts.
SpatialLadder-26k: Dataset Construction and Task Hierarchy
SpatialLadder-26k is a multimodal dataset comprising 26,610 samples, systematically covering object localization, single-image, multi-view, and video-based spatial reasoning. The dataset is constructed via a standardized pipeline leveraging 3D scene reconstructions from ScanNet and SR-91k, ensuring high-quality annotations and comprehensive coverage across modalities. The task hierarchy spans seven spatial dimensions: relative direction, relative distance, absolute distance, object size, counting, room size, and appearance order. This design enables the curriculum to progress from basic perception to complex spatiotemporal reasoning.
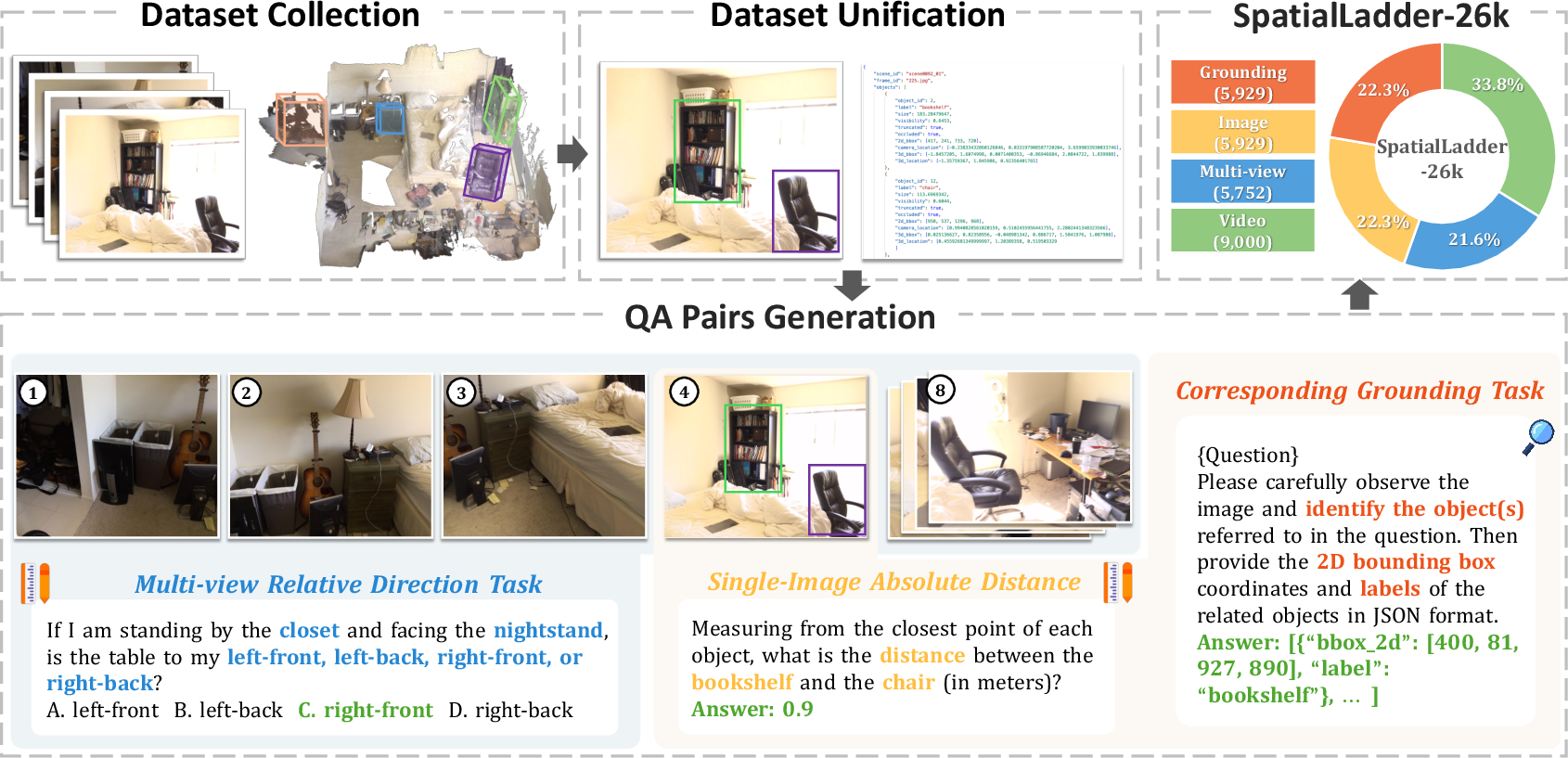
Figure 2: Overview of SpatialLadder-26k dataset construction pipeline, illustrating the progression from raw data to diverse spatial reasoning tasks.
Three-Stage Progressive Training Framework
The core of the SpatialLadder methodology is a three-stage progressive training framework:
- Stage 1: Perceptual Grounding Models are trained on object localization tasks, learning to map linguistic queries to visual regions and produce precise bounding box outputs. This stage establishes the perceptual foundation necessary for subsequent spatial reasoning.
- Stage 2: Spatial Understanding The model is fine-tuned on multi-dimensional spatial reasoning tasks across single-image, multi-view, and video modalities. This stage develops robust spatial representations and the ability to generalize across visual contexts.
- Stage 3: Reinforcement Learning for Reasoning
Group Relative Policy Optimization (GRPO) is employed with task-specific verifiable rewards, including both format and accuracy components. Chain-of-thought generation is explicitly encouraged, enabling the model to articulate structured reasoning processes.
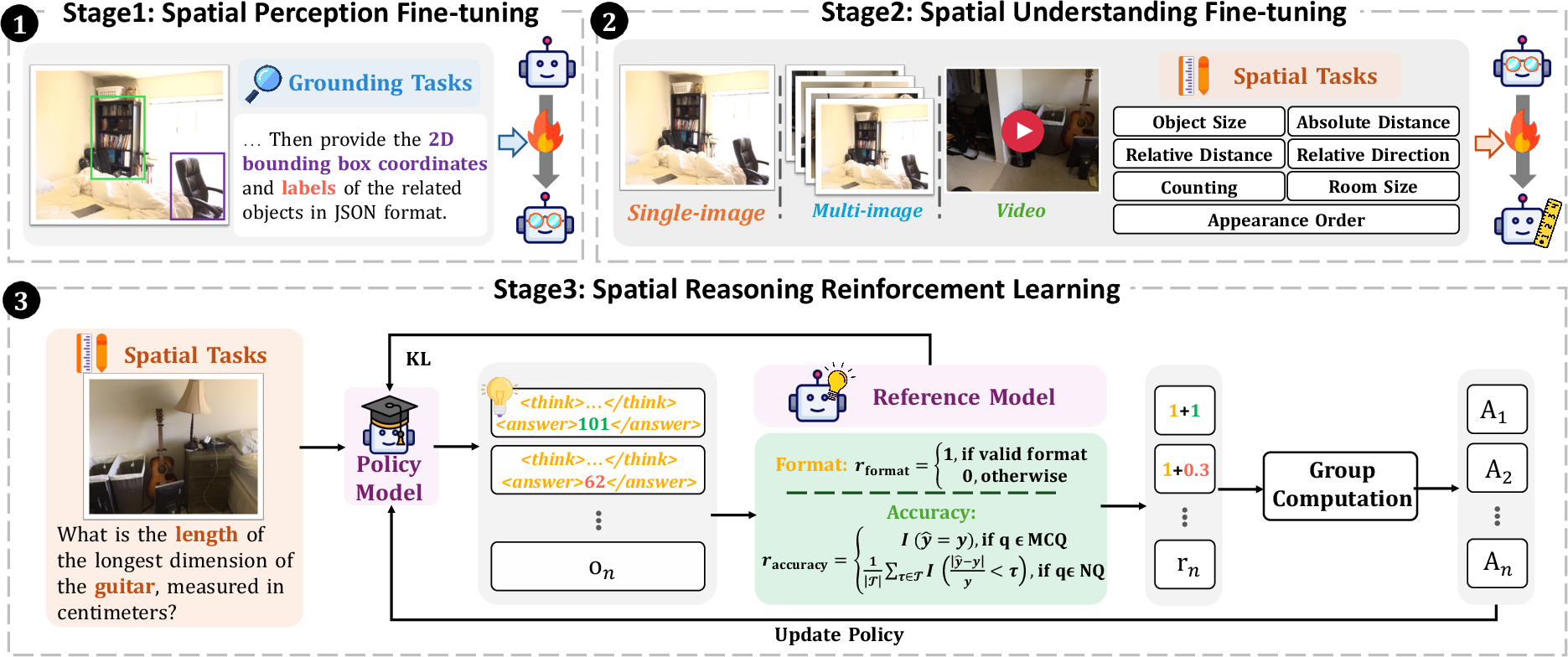
Figure 3: Three-stage progressive training framework of SpatialLadder, illustrating the hierarchical development from perception to reasoning.
SpatialLadder, instantiated as a 3B-parameter model based on Qwen2.5-VL-3B, achieves state-of-the-art results across multiple spatial reasoning benchmarks. On VSI-Bench, SpatialLadder attains 45.7% accuracy, outperforming the base model by 16.3%. On SPBench-SI and SPBench-MV, the model achieves 70.2% and 70.9% accuracy, respectively, with relative improvements of 29.9% and 34.3%. Notably, SpatialLadder surpasses GPT-4o by 20.8% and Gemini-2.0-Flash by 10.1% on overall spatial reasoning tasks.
Generalization is validated on out-of-domain benchmarks, with SpatialLadder maintaining a 7.2% improvement over the base model and demonstrating robust transfer to novel spatial configurations and perspectives.
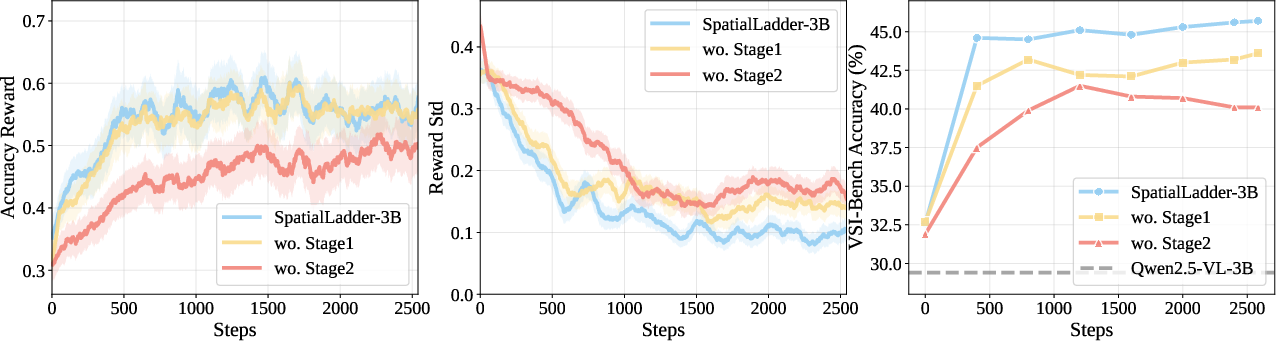
Figure 4: Impact of progressive training stages on accuracy rewards, training stability, and benchmark performance.
Ablation and In-depth Analysis
Ablation studies confirm the necessity of each training stage, with the removal of Stage 2 causing the largest performance drop (9.4%), underscoring the importance of explicit spatial understanding. Multimodal diversity is critical, as exclusion of single-image and multi-view data results in a 16.4% loss. Chain-of-thought reasoning consistently yields performance gains and improved training stability.
Semantic entropy analysis reveals that uncertainty increases during perceptual and understanding stages, then decreases during reinforcement learning, indicating a transition from exploration to reasoning convergence.
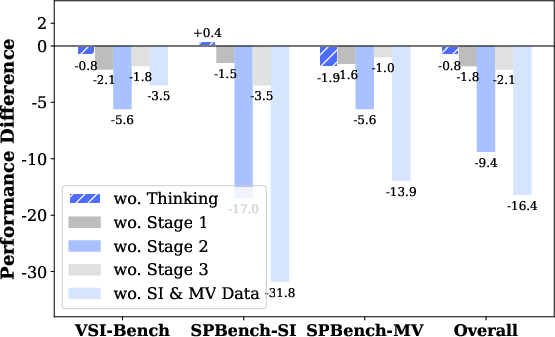
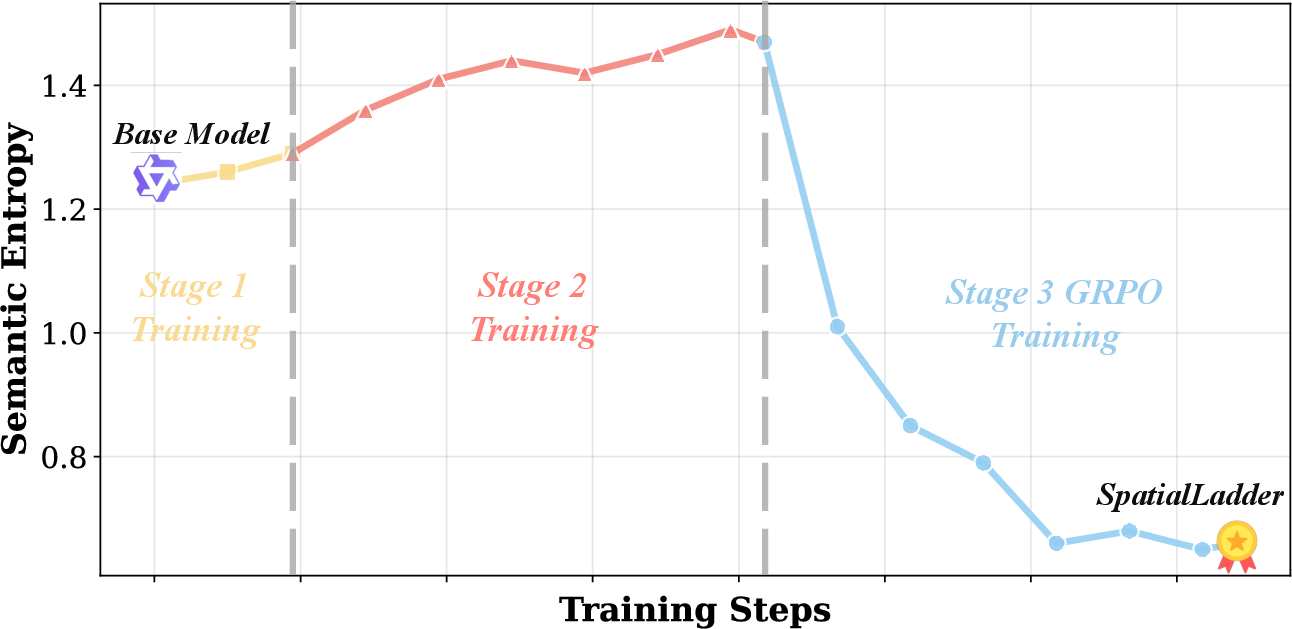
Figure 5: Ablation study results, quantifying the contribution of each training component.
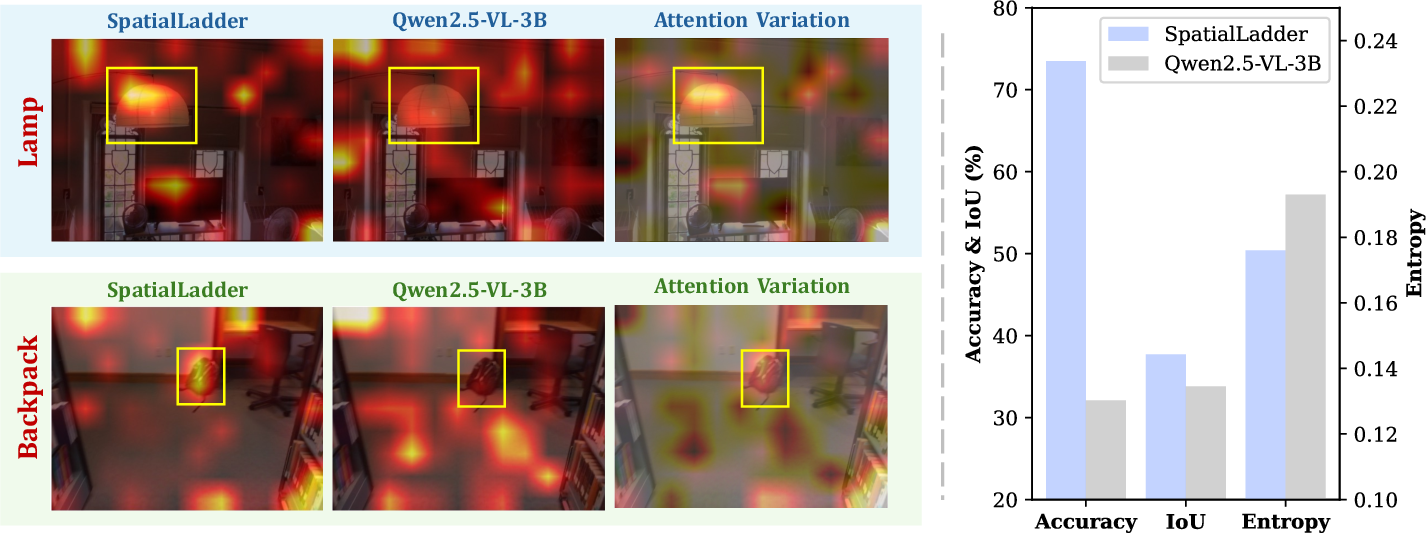
Figure 6: Visual attention comparison between SpatialLadder and Qwen2.5-VL-3B, showing more precise, object-centric attention in SpatialLadder.
Qualitative analysis demonstrates that hierarchical reasoning structures emerge naturally from perceptual foundations, with the model exhibiting self-verification and error correction mechanisms.

Figure 7: Hierarchical reasoning process demonstration in SpatialLadder, illustrating structured spatial cognition.
Scaling and Dataset Efficiency
SpatialLadder-26k achieves superior performance with significantly fewer samples compared to prior datasets, validating the efficacy of strategic dataset curation and progressive training. Scaling analysis indicates that performance continues to improve with increased dataset size, without saturation at current scales.
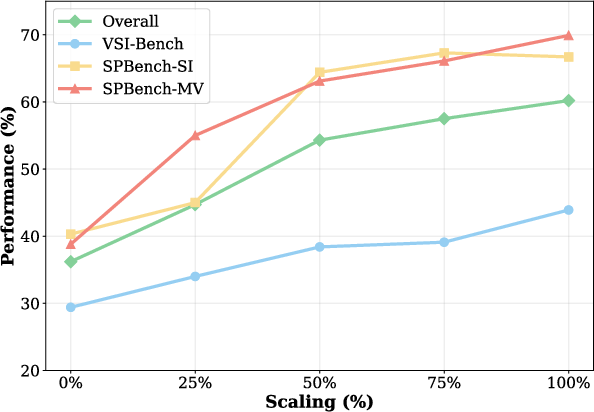
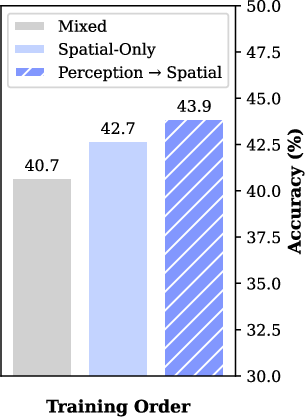
Figure 8: Dataset scaling analysis across spatial reasoning benchmarks, demonstrating consistent performance gains with increased data.
Implementation Considerations
SpatialLadder is implemented using Qwen2.5-VL-3B as the base model, with training conducted on a 4 × NVIDIA A6000 GPU cluster. Stages 1 and 2 utilize supervised fine-tuning, while Stage 3 employs GRPO via the VLM-R1 framework. The reward function integrates both format and accuracy components, with chain-of-thought reasoning enforced through prompt engineering. The approach is computationally efficient, achieving strong results with a relatively small model and dataset.
Implications and Future Directions
SpatialLadder establishes a new paradigm for spatial reasoning in VLMs, demonstrating that progressive, hierarchical training is essential for robust spatial intelligence. The methodology is broadly applicable to domains requiring spatial understanding, including robotics, autonomous navigation, and embodied AI. Future work should explore scaling to larger models, expanding dataset diversity, and developing adaptive training frameworks that dynamically adjust learning sequences. Validation in real-world applications will further elucidate the practical impact of progressive spatial learning.
Conclusion
SpatialLadder addresses the perception–reasoning gap in VLMs by introducing a comprehensive dataset and a three-stage progressive training framework. The approach yields substantial improvements in spatial reasoning performance and generalization, validated through extensive experiments and ablation studies. The results demonstrate that hierarchical, curriculum-based training is critical for developing genuine spatial intelligence in VLMs, providing a foundation for future research in spatially-aware AI systems.

