- The paper introduces a pipeline leveraging compositional sparsity through clique forest estimation to design neural models aligned with low-dimensional interactions.
- It demonstrates superior generalization and efficiency compared to dense models, especially in high-dimensional settings with limited samples.
- The approach offers reduced hyperparameter sensitivity and enhanced interpretability, paving the way for robust, data-driven design in various applications.
Compositional Sparsity as a Data-Driven Inductive Bias for Neural Architecture Design
Introduction
This paper addresses a foundational issue in high-dimensional machine learning: how to build neural architectures that generalize efficiently under the curse of dimensionality by encoding principled structural inductive biases. It posits that compositional sparsity—where the function to be learned decomposes as a composition of low-dimensional interactions—is essential for effective learning. The authors propose a pipeline in which Information Filtering Networks (IFNs), specifically via Maximally Filtered Clique Forests (MFCFs), are used to estimate data-driven sparse dependency structures, which are then codified into feedforward Homological Neural Networks (HNNs). The central claims are that such architectures (1) recover true underlying structures in synthetic tasks; (2) maintain superior performance over dense baselines, particularly when dimensionality is high and sample regime is limited; and (3) offer reduced sensitivity to hyperparameter tuning and higher interpretability.
Data-Driven Construction of Sparse Neural Architectures
The methodology is structured as a two-step process. First, dependency estimation is performed: given multivariate data, pairwise dependency matrices (typically using squared Pearson correlation, but easily extensible to richer mutual information/label-aware measures) are computed, and MFCF algorithms generate a chordal clique forest representing overlapping higher-order dependencies. The resulting clique structure defines the universe of variable subsets available for explicit modeling.
Second, the clique forest is algorithmically converted into a sparse neural architecture with a strict hierarchical organization. Each network layer corresponds to higher-order interactions (cliques of increasing size), with connections following strict subset inclusion relationships. Parameters are only assigned to those connections supported by the estimated topological structure, ensuring induced architectural sparsity.
Figure 1: The pipeline for constructing a HNN, from dependency estimation through to the data-driven neural architecture, leveraging clique hierarchies and inclusion-based layer wiring.
An all-layer readout aggregates activations from each interaction order, preserving the signal from low-order dependencies that do not propagate to deep layers due to gain thresholding in the MFCF.
Experimental Analysis: Synthetic and Real-World Data
Evaluation on Synthetic Sparse Hierarchical Tasks
The synthetic suite is constructed using random sparse Gaussian graphical models, from which targets are generated via nonlinear functions on clique-induced variable subsets. This setup allows for precise benchmarking: "oracle" HNNs are constructed with knowledge of the true interaction topology, while data-driven HNNs use only estimated dependencies.
Key findings:
A crucial control experiment replaces data-driven wiring with a random sparse topology (HNN rand oracle), isolating the effect of sparsity from data alignment; results confirm that structure, not mere sparsity or parameter pruning, is the dominant factor in robust generalization.
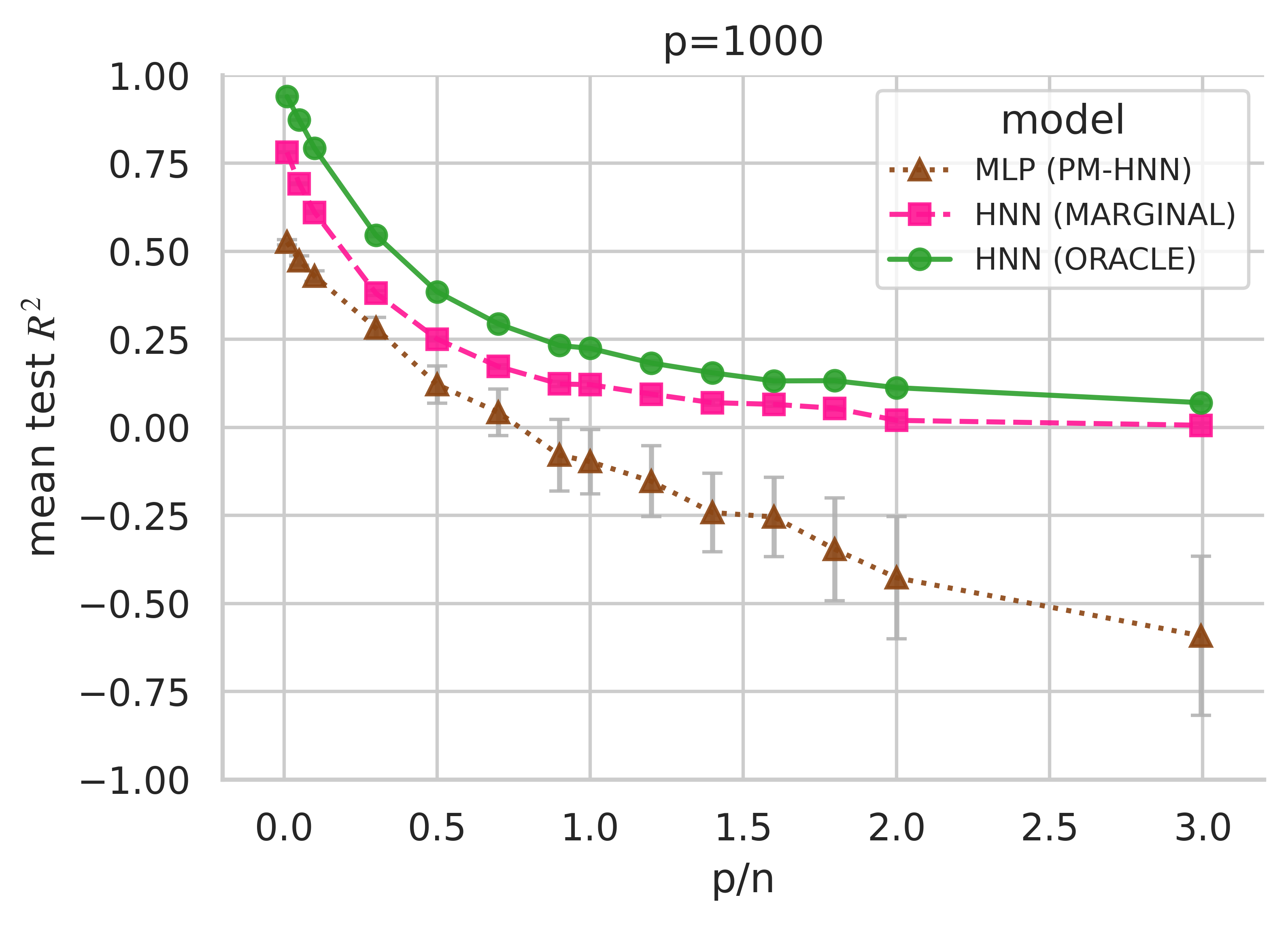
Figure 3: Comparison of HNN (marginal) to a parameter-matched single-layer MLP and HNN (oracle) for p=1000, demonstrating that interaction-structured wiring yields superior and more stable generalization with fixed model capacity.
Results on Real-World Tabular Regression (OpenML-CTR23)
The pipeline is evaluated on the OpenML-CTR23 suite of curated tabular regression benchmarks, which span a wide range of dataset sizes and feature dimensions. Under a strictly minimal-tuning protocol (no model- or dataset-specific architecture or learning rate adjustment), HNN (m-s) and HNN (marginal) variants achieve average test R2 ranks competitive with or superior to all dense MLP baselines. Despite up to 100-fold fewer parameters than the best-performing MLP, the HNN (m-s) is within one rank of XGBoost, the overall top performer on this suite.
Importantly, HNNs display lower performance variance and reduced sensitivity to hyperparameter settings compared to MLPs, as expected from architectures with built-in structural priors.
Theoretical and Practical Implications
The paper provides concrete empirical evidence in support of recent theoretical perspectives [see, e.g., (Danhofer et al., 3 Jul 2025)] that compositional sparsity is the critical structural property exploited by neural networks to defeat the curse of dimensionality and that architectural wiring, when aligned with interaction structure, is at least as important as breadth of parameter search or model size.
Practically, the results imply that data-driven sparse architectures—constructed without costly hyperparameter or architecture search—offer a robust, interpretable, and sample-efficient alternative for high-dimensional tabular and structured prediction tasks. Sparse architectures are desirable for downstream interpretability, computational efficiency (memory and FLOPs), and alignment with application-domain structure (e.g., scientific data with known dependency topology).
The proposed pipeline’s full modularity (decoupling structure estimation from training) also suggests compatibility with richer structural priors (label-aware or mutual information-based dependency estimates), integration with other advances in neural pruning, and possible extension to more expressive readout or recurrent modules. This may ultimately lead toward architectures that can adaptively adjust topology as data regime and signal complexity vary during learning, enhancing performance on dynamic or nonstationary tasks.
Future Directions
A current limitation is the reliance on pairwise correlation structure, which may not capture nonlinear or highly regime-dependent dependencies in practical data. Future research should include adaptive estimation of higher-order dependencies (via, e.g., kernel methods, information-theoretic measures, or stratified sample partitioning), automatic selection of clique size, and extendibility to sequence, relational, or multimodal domains. The compatibility of HNN-induced topologies with transformers, graph neural networks, or efficient architecture search warrants further investigation.
Conclusion
Through a blend of rigorous control experiments and cross-domain evaluation, the paper establishes compositional sparsity—instantiated through data-driven clique forest estimation and hierarchical sparse neural wiring—as a central inductive bias for robust high-dimensional learning (2605.14764). The HNN pipeline yields stable, sample-efficient performance and reduced hyperparameter dependence, outperforming capacity-matched and larger dense baselines on both synthetic and real-world tabular tasks. The methodology has direct implications for the future design of interpretable and high-performing neural architectures, and suggests new avenues for integrating principled statistical dependency modeling with modern deep learning pipelines.