Training-Free Generative Sampling via Moment-Matched Score Smoothing
Abstract: Diffusion models generate samples by denoising along the score of a perturbed target distribution. In practice, one trains a neural diffusion model, which is computationally expensive. Recent work suggests that score matching implicitly smooths the empirical score, and that this smoothing bias promotes generalization by capturing low-dimensional data geometry. We propose moment-matched score-smoothed overdamped Langevin dynamics (MM-SOLD), a training-free interacting particle sampler that enforces the target moments throughout the sampling trajectory. We prove that, in the large-particle limit, the empirical particle density converges to a deterministic limit whose one-particle stationary marginal is a Gibbs--Boltzmann density obtained by exponentially tilting a naive score-smoothed diffusion target. The mean and covariance of this distribution agree with the empirical moments of the training data. Experiments on 2D distributions and latent-space image generation show that MM-SOLD enables fast, robust, training-free sampling on CPUs, with sample fidelity and diversity competitive with neural diffusion baselines.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Training-Free Generative Sampling via Moment-Matched Score Smoothing”
Overview
This paper is about a faster, simpler way to make new, realistic-looking data (like images) without training big neural networks. The authors introduce a method called MM-SOLD that generates samples using only the original data and some clever math—no expensive training needed. It keeps the overall “shape” of the data (its average and how spread out it is) while still filling in the gaps between examples smoothly.
Key objectives and questions
The paper asks:
- Can we generate good samples without training a neural network?
- How do we smooth or “blur” the data enough to avoid copying the training examples, but not so much that everything becomes average and boring?
- Can we force the generated samples to keep the same overall average and spread as the training data so the results don’t collapse?
- What exact distribution (probability pattern) does this new method aim for?
How the method works (in everyday language)
First, a quick idea of diffusion models: Imagine you take a clear image and add a tiny bit of noise again and again until it becomes pure static. A diffusion model learns how to reverse this process: starting from noise, it slowly removes noise to rebuild a realistic image. The “score” is like a tiny arrow that tells you which direction makes the picture look more like real data.
The challenge:
- If you only have a finite dataset (a list of examples), the “arrows” point straight back to the nearest training pictures. That means you mostly just copy the training set—no new creativity.
- People try to smooth those arrows (like slightly blurring them), so the model doesn’t just snap back to training points. But if you blur too little, you still copy; if you blur too much, you average everything into bland, “blurry” results (think of taking the average of lots of faces—distinct features disappear).
The MM-SOLD idea:
- Use many particles (think of them as little points) that move around the space of data, guided by the smoothed arrows plus a tiny random wiggle. This “wiggle + push” movement is called Langevin dynamics; you can think of it as a jittery walk downhill on a landscape shaped by the data.
- Add group rules so these particles don’t drift into nonsense. Specifically, at every step the whole group is adjusted so: 1) their average position equals the training data’s average, and 2) their overall spread (covariance) matches the training data’s spread.
- This “moment matching” keeps the big-picture geometry (global shape) correct while allowing local interpolation (filling in plausible new points between examples).
- Mathematically, this ends up sampling from a “tilted” version of the smoothed data distribution—tilted just enough so its mean and spread exactly match the training data. That gives a precise target the method is aiming for.
Speed and practicality tricks:
- Instead of comparing to all training examples at once (which is slow), MM-SOLD looks only at nearby examples (nearest neighbors) and a few random extras to keep things fair.
- It uses “antithetic” noise (paired positive and negative tweaks) to reduce randomness and improve stability.
- It works well in a compressed “latent space” where data (like images) are represented with fewer numbers—making everything faster and CPU-friendly.
Main findings and why they matter
What they tested:
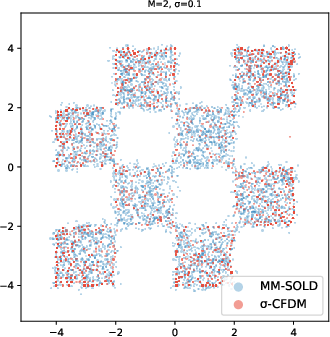
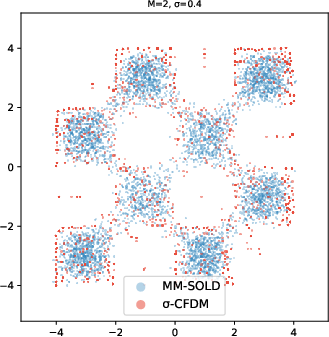
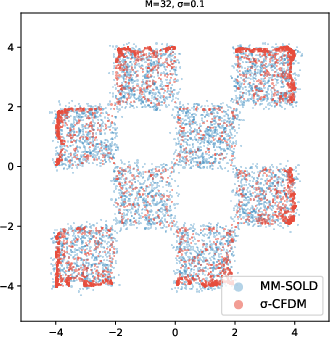
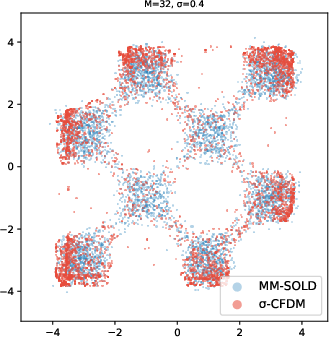
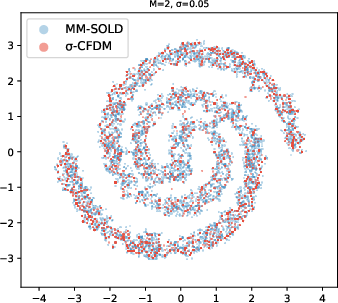
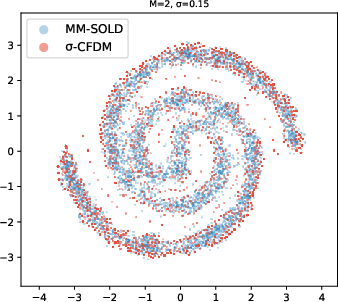
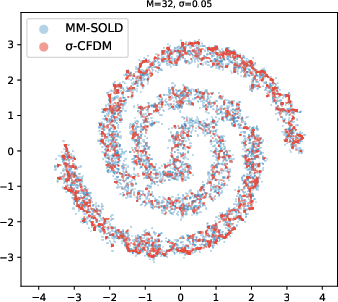
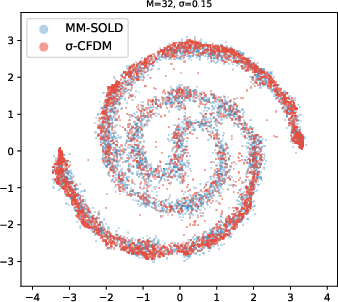
- 2D toy shapes (like spirals and checkerboards): MM-SOLD kept the true shape even when the smoothing level changed; earlier methods either memorized the training points or collapsed into averages.
- Handwritten digits (in a 100-number latent space):
- Classification: Using the paper’s “moment-matched” distribution to classify digits reached about 98% accuracy without training a classifier—strong evidence the distribution closely matches the real data.
- Generation: MM-SOLD made digit images that were both faithful and varied, and it avoided copying the training set. It beat a prior training-free baseline on key metrics and was competitive with a trained diffusion model, while needing no training and running fast on CPU.
- CelebA-HQ faces (in a 700-number latent space):
- MM-SOLD produced detailed and diverse faces. It outperformed the training-free baseline on quality and diversity, and came close to a trained diffusion model—again, without any training and with strong CPU performance.
Why this matters:
- MM-SOLD greatly reduces the “blurry average” problem that comes from over-smoothing.
- It avoids memorizing training samples, keeping results both realistic and diverse.
- It runs quickly on CPUs and needs no training, which is valuable when you have limited time, money, or hardware.
Implications and impact
- Training-free generation: MM-SOLD shows you can get high-quality, diverse samples without training heavy neural networks. This is useful in settings with little data, limited compute, or tight deadlines.
- Clearer theory: The paper proves that, in the limit of many particles, the method targets a specific “moment-matched” distribution—a precise, tilted version of the smoothed data. That makes the method principled, not just a trick.
- Practical progress: The approach is robust to tuning and scales to real datasets in latent spaces, giving competitive results with a fraction of the effort.
Limitations and future directions:
- It currently needs at least as many particles as the number of latent dimensions plus one, which can be a lot in very high-dimensional spaces.
- On the most complex, high-resolution images, top neural models still have an edge in sharpness. Combining MM-SOLD’s strengths with smart neural biases could close that gap.
In short, MM-SOLD is a smart, training-free way to generate realistic, non-copycat samples by smoothing the guidance gently and locking in the dataset’s overall average and spread. It’s fast, practical, and backed by clear math.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored, phrased concretely to guide future work:
- Derive finite-sample statistical error bounds between the proposed moment-matched limiting target and the true data distribution as functions of sample size , smoothing bandwidth , GMM scale , intrinsic manifold dimension, and curvature.
- Establish uniform-in- discretization error and mixing-time guarantees for the LM-integrated, manifold-constrained Langevin dynamics (Algorithm 1), including stability under retractions and explicit dependencies on .
- Prove mean-field/propagation-of-chaos type convergence for the finite- interacting particle system to the constrained free-energy minimizer, with pathwise approximation error over finite horizons.
- Characterize existence, uniqueness, and stability conditions for the tilting parameters in the constrained solution when is ill-conditioned or singular; extend the theory to low-rank (degenerate covariance) settings common in manifold data.
- Quantify how much moment matching mitigates barycentric collapse: e.g., provide curvature-distortion bounds or guarantees on support preservation relative to the naive score-smoothed target.
- Provide a bias–variance analysis and consistency guarantees for the plug-in estimators of from training data, including rates, confidence intervals, and robust variants under outliers or heavy tails.
- Address the parameterization burden for : develop shrinkage, low-rank, or structured (e.g., diagonal/block-diagonal) estimators with provable risk–accuracy trade-offs in high dimensions.
- Develop principled, data-driven selection rules for and (e.g., SURE/Lepski-type criteria, cross-validated risk proxies) with theoretical guarantees for the smoothed-score and log-smoothing objectives.
- Provide a rigorous bias/variance and complexity analysis of the nearest-neighbor score estimator (dependence on ), and quantify how its approximation error perturbs the stationary distribution and metrics such as KID/FID.
- Study the impact of antithetic perturbations and projected-space Gaussian sampling on estimator bias and variance; identify exactness conditions and error bounds versus full ambient-space sampling.
- Analyze scalability and complexity: quantify the per-iteration cost and memory of QR-based retractions and tangent projections (e.g., ), and propose cheaper retractions, block-updates, or preconditioning to reduce cost at large .
- Relax the requirement (needed for full covariance matching): design approximate, stochastic, or low-rank moment constraints that allow while controlling the induced bias.
- Provide strategies to obtain (approximately) independent samples at the end of a coupled run (e.g., thinning/decoupling procedures) while retaining the matched-moment guarantees and characterizing the residual dependence.
- Extend beyond global mean/covariance constraints: investigate higher-order or localized constraints (e.g., skewness/kurtosis, per-cluster/local covariances, Laplacian/graph-based constraints) and analyze their effect on geometry preservation and sample quality.
- Generalize smoothing beyond isotropic Gaussian kernels: design and analyze adaptive or anisotropic kernels (learned on-the-fly) with guarantees that avoid barycentric averaging without requiring oracle manifold geometry.
- Tighten the approximation that replaces with an isotropic GMM at small time: derive explicit error bounds in for the log-smoothing target and its score.
- Investigate adaptive and automated control of integrator hyperparameters (step size , number of steps ) and stopping criteria with guarantees on bias/mixing and computational budget.
- Quantify robustness to approximate nearest neighbors (ANN) and indexing errors in high- regimes; provide end-to-end guarantees that include KNN search error in the sampling error budget.
- Assess sensitivity to dataset shift and outliers; develop robust moment estimators (e.g., Huberized/shrinkage) within MM-SOLD and analyze the trade-offs between robustness, fidelity, and diversity.
- Bridge latent-space performance to pixel-space guarantees: quantify how encoder/decoder distortions affect geometry preservation, fidelity/diversity metrics, and memorization, and compare across different latent models (beyond NRAE).
- Extend evaluation beyond 2D and image latents to modalities with structured geometry (audio, molecules, graphs), including problem-specific smoothing/constraints and domain metrics.
- Develop conditional and controllable generation within MM-SOLD (e.g., class/attribute-conditioned moment constraints or classifier guidance) and characterize the induced target and guarantees.
- Provide privacy/memorization guarantees (beyond DupRate heuristics), e.g., formal bounds on training-sample leakage under MM-SOLD with smoothed scores and moment constraints.
- Compare against stronger training-free baselines (e.g., kernel, flow-based, or score-distillation methods without training) under standardized protocols, and perform broader ablations over with statistical significance.
- Explore theoretical connections to maximum-entropy and information geometry: interpret the constrained minimizer as an exponential family over the smoothed base measure and exploit this structure for preconditioning or improved samplers.
Practical Applications
Immediate Applications
The following applications leverage MM-SOLD’s training-free, CPU-efficient generative sampling, its moment-matching constraints (mean and covariance), and the nearest-neighbor score estimator for scalability. Each item lists target sectors, potential tools/products/workflows, and key assumptions/dependencies.
- Training-free data augmentation in low-data regimes
- Sectors: software/ML, healthcare (e.g., radiology, dermatology), manufacturing/quality control, document OCR.
- Workflow: encode data into a latent space (e.g., VAE/NRAE), compute empirical mean/covariance, index dataset for KNN (e.g., FAISS/Annoy), run MM-SOLD on CPU to generate synthetic latents, decode to input space, retrain classifiers.
- Evidence: the paper’s handwritten-digit experiment shows an MLP trained on MM-SOLD-augmented data improves accuracy (93.77% → 97.90%).
- Assumptions/dependencies: availability/quality of a pretrained encoder/decoder; hyperparameters (σ, M, step size h, number of particles P) tuned but relatively robust; no formal differential privacy guarantees.
- Rapid prototyping of generative workflows without GPU training
- Sectors: media/creative, enterprise analytics, small startups, academia.
- Tools/products: a Python library or CLI that takes a folder of examples, computes moments, and generates new samples via MM-SOLD; plug-ins for PyTorch pipelines; on-prem CPU microservices.
- Assumptions/dependencies: latent encoders for the domain (e.g., image autoencoders) should be available; fidelity may lag state-of-the-art neural diffusion for very complex data.
- Class-conditional generative classification via minimum ECM
- Sectors: software/ML, cybersecurity (e.g., embedding-based malware family densities), document processing.
- Workflow: fit per-class moment-matched densities (using the paper’s exponential-tilt formulation), calibrate per-class bias on validation data, classify by minimal energy.
- Evidence: achieved 98.00% test accuracy in the digits latent space without neural training.
- Assumptions/dependencies: reliable latent features and stable moment estimates; per-class validation set for bias calibration.
- Energy- and cost-efficient synthetic data services
- Sectors: public sector, NGOs, SMEs, sustainability-focused ML operations.
- Products: CPU-based synthetic data generators that avoid GPU training and reduce energy/carbon costs.
- Assumptions/dependencies: adequate CPU resources; acceptable quality in latent space for the task; encoder availability.
- On-device or edge generation (CPU-only) for latency-sensitive tasks
- Sectors: mobile apps, IoT, AR/VR prototyping, assistive technologies (e.g., OCR variants, icon/avatar generation).
- Workflow: deploy encoder and MM-SOLD sampler on edge devices; generate variations consistent with user/device data moments without network dependency.
- Assumptions/dependencies: lightweight latent encoder/decoder that fits edge constraints; data privacy constraints honored locally.
- Synthetic tabular/time-series scenario generation with moment control
- Sectors: finance (stress tests, backtesting), operations research (demand scenarios), supply chain (lead-time variability).
- Products: MM-SOLD-based scenario generators that enforce empirical means and covariances while adding local structure via score smoothing.
- Assumptions/dependencies: tabular embeddings or feature scaling that preserve structure; heavy tails and higher-order dependencies not fully controlled by mean/cov alone.
- Dataset auditing and diagnostics via moment-matched tilting
- Sectors: MLOps, regulatory/compliance analytics, academic research.
- Workflow: estimate tilting parameters (λ, Λ) per dataset/class; use magnitudes and structure of tilts to quantify mismatch between naive score-smoothing and empirical geometry; detect shifts or artifacts.
- Assumptions/dependencies: stable estimation of λ and Λ (requires enough samples); interpretability depends on the domain.
- Robust, training-free baselines for generative research and teaching
- Sectors: academia, education, research labs.
- Use case: demonstrate diffusion concepts, score smoothing, and manifold effects without GPUs; provide a reproducible baseline for student labs and ablation studies.
- Assumptions/dependencies: basic scientific Python stack; prepared datasets and encoders.
- Fast iterative adaptation to streaming or evolving datasets
- Sectors: online services, A/B testing, personalized content.
- Workflow: as new samples arrive, update empirical moments and KNN index, rerun MM-SOLD without retraining a neural generator.
- Assumptions/dependencies: efficient incremental updates to KNN structures; monitoring for distribution drift beyond first two moments.
- Robustness and stress testing of diffusion pipelines
- Sectors: ML research, applied ML teams.
- Use case: use MM-SOLD to probe sensitivity to smoothing bandwidths (σ) and to evaluate barycentric collapse risks; compare with trained models quickly.
- Assumptions/dependencies: access to the same latent encoders as production pipelines; consistent evaluation metrics (FID/KID/Recall).
- Privacy-aware data sharing (best-effort, non-DP)
- Sectors: healthcare research consortia, finance collaborations, public data portals.
- Workflow: produce synthetic datasets with low duplication rate (DupRate ~ 0 in experiments) for exploration/modeling by partners.
- Assumptions/dependencies: no formal DP/privacy guarantees; requires careful privacy assessment; moment matching can still reflect sensitive structure.
- Lightweight content generation for internal tools
- Sectors: enterprise UX, documentation, education technology.
- Use case: generate icons/diagrams/handwritten-like assets using small internal datasets in latent space; deploy as a CPU service.
- Assumptions/dependencies: pre-existing internal assets to encode; perceptual quality depends on the encoder.
Long-Term Applications
These applications require further research, engineering, or validation (e.g., scaling to higher dimensions, extending constraints, formal guarantees).
- Production-grade image/audio/video generation without neural training
- Sectors: media/creative, gaming, design tools.
- Vision: combine MM-SOLD with stronger latent encoders and additional inductive biases to approach DDPM-level fidelity without training.
- Research needs: higher-order constraints beyond covariance, manifold-aware kernels, theoretical finite-sample error bounds, and better tilting parameter estimation in high d.
- Differential privacy and formal privacy guarantees
- Sectors: healthcare, finance, public sector.
- Vision: integrate DP mechanisms (e.g., DP moment estimation, DP nearest-neighbor selection) with MM-SOLD to guarantee non-disclosure.
- Dependencies: rigorous DP accounting for interacting particle dynamics; validation of utility-privacy trade-offs.
- Independent sampling without particle-count constraints
- Sectors: general ML deployment.
- Vision: relax the P ≥ d+1 requirement via learned tilting or moment-penalized samplers to produce independent samples with matched moments.
- Research needs: stable optimization of tilts in high dimensions; variance control without interacting particles.
- Scientific data synthesis at scale (e.g., genomics, molecular design, climate data)
- Sectors: life sciences, materials, climate/earth systems.
- Vision: use domain-specific encoders to enable training-free sampling with global geometry preserved; generate diverse hypotheses/scenarios quickly.
- Dependencies: high-quality domain encoders; kernel choices suited to curved manifolds; validation metrics aligned with scientific constraints.
- Edge personalization with privacy-preserving constraints
- Sectors: mobile platforms, wearables, AR/VR, smart home devices.
- Vision: on-device MM-SOLD for personalized content (avatars, handwriting, UI elements) with privacy-aware updates to moments/indices.
- Dependencies: efficient on-device encoders/decoders; secure local storage; regulatory compliance for personal data.
- Low-carbon generative AI policy and procurement standards
- Sectors: government, NGOs, sustainability consortia.
- Vision: recommend training-free or CPU-first generative methods for prototyping/augmentation; integrate into green-AI procurement checklists.
- Dependencies: standardized energy benchmarks; quality thresholds for deployment acceptability.
- Hybrid neural–non-neural generative systems
- Sectors: software/ML, creative tools.
- Vision: use MM-SOLD as a fast pre-sampler or initializer; add lightweight neural refinement (e.g., score distillation, guidance) for better fidelity.
- Dependencies: interfaces to guide or re-score MM-SOLD outputs; stability analyses.
- Anomaly detection and shift monitoring via tilts
- Sectors: finance, cybersecurity, manufacturing.
- Vision: track λ and Λ over time; large deviations signal distribution shifts or anomalies in latent space.
- Dependencies: robust estimators and control charts; causal interpretation in specific domains.
- Robotics and control trajectory augmentation
- Sectors: robotics, autonomous systems.
- Vision: generate trajectory variations in latent dynamical spaces with controlled global statistics for robust policy training.
- Dependencies: learning encoders for dynamics; ensuring stability and safety constraints beyond first two moments.
- Higher-order moment or structured constraint matching
- Sectors: all domains where covariance is insufficient (e.g., heavy-tailed finance, complex textures).
- Vision: extend MM-SOLD to match skewness/kurtosis or structured dependencies; reduce mode collapse and improve realism.
- Dependencies: computationally tractable constrained manifolds; reliable estimators and samplers with acceptable overhead.
- Compliance and safety frameworks for training-free generators
- Sectors: regulated industries (healthcare, aviation), enterprise governance.
- Vision: certification pathways for training-free generators, including traceability of data usage, auditing of moment constraints, and risk mitigation plans.
- Dependencies: sector-specific validation protocols; interpretable metrics relating moments/tilts to safety criteria.
- AutoML integration as a general-purpose augmentation module
- Sectors: enterprise ML platforms, data science toolchains.
- Vision: plug-in MM-SOLD components in AutoML pipelines for fast augmentation, especially when training data are scarce or training budgets are tight.
- Dependencies: standardized APIs; heuristics for choosing σ/M/P based on dataset diagnostics.
Each long-term application would benefit from the paper’s future work directions: (1) finite-sample error bounds between the moment-matched target and the true data law, (2) relaxing the P ≥ d+1 constraint, and (3) incorporating additional inductive biases (architectural priors, manifold-aware kernels) to improve fidelity on highly curved, high-dimensional data manifolds.
Glossary
- Antithetic perturbations: A variance-reduction technique that pairs noise samples with their negatives to stabilize Monte Carlo estimates. Example: "antithetic perturbations and projected-space Gaussian sampling"
- Barycenters: Centroids or averages of points (often in Euclidean space), which can cause oversmoothing when overemphasized. Example: "produce only barycenters of training samples."
- Cholesky factor: A lower-triangular matrix whose product with its transpose equals a positive-definite matrix, used to factor covariances. Example: "let be the Cholesky factor of , i.e., "
- Corrector steps: Stochastic refinement steps used in predictor–corrector sampling for diffusion models. Example: "apply sufficient corrector steps between each sampling iteration"
- DDIM (Denoising Diffusion Implicit Models): A deterministic sampler for diffusion models that accelerates generation by using non-Markovian dynamics. Example: "$100$ DDIM sampling steps"
- Denoising Diffusion Probabilistic Model (DDPM): A class of generative models that learn to reverse a noising process by predicting denoised data. Example: "a latent denoising diffusion probabilistic model (latent DDPM)"
- DupRate: A memorization metric measuring the fraction of generated samples unusually close to training data. Example: "Novelty is measured by DupRate"
- Equivalence-of-ensembles argument: A probabilistic/statistical-physics argument relating constrained and unconstrained distributions in the large-system limit. Example: "an equivalence-of-ensembles argument in -coordinates"
- Exponential tilting: Reweighting a base density by multiplying with an exponential of linear/quadratic functions to enforce constraints. Example: "obtained by exponentially tilting a naive score-smoothed diffusion target"
- Free energy: An energy-entropy functional whose minimizer characterizes equilibrium distributions for Langevin dynamics. Example: "the minimizer of the free energy"
- Fréchet Inception Distance (FID): A generative quality metric comparing feature distributions of real and generated images. Example: "Fréchet Inception Distance (FID)"
- Gaussian mixture model (GMM): A probabilistic model expressing a distribution as a weighted sum of Gaussian components. Example: "a Gaussian mixture model (GMM)"
- Gibbs--Boltzmann density: A probability density proportional to the exponential of negative potential energy, common in statistical physics. Example: "a Gibbs--Boltzmann density"
- Gibbs equilibrium: The equilibrium distribution of a system under a Gibbs measure, possibly with constraints. Example: "ideal constrained Gibbs equilibrium"
- Gram matrix: A matrix of inner products that encodes geometric relationships among a set of vectors. Example: "using their Gram matrix"
- Kernel Inception Distance (KID): A generative quality metric based on MMD between Inception features of real and generated images. Example: "Kernel Inception Distance (KID)"
- Kullback–Leibler divergence (KL): A measure of dissimilarity between probability distributions. Example: "closest to it in KL"
- Leimkuhler--Matthews (LM) scheme: A numerical integrator for Langevin dynamics that reduces discretization bias. Example: "the Leimkuhler--Matthews (LM) scheme"
- Lyapunov equation: A matrix equation of the form AX + XAᵀ = Q, used here to solve for quadratic tilting parameters. Example: "the Lyapunov equation"
- Minimum expected cost of misclassification (ECM): A decision-theoretic classification criterion minimizing expected misclassification cost. Example: "minimum expected cost of misclassification (ECM)"
- Moment matching: Enforcing sample statistics (e.g., mean, covariance) to equal target moments during sampling. Example: "moment matching is built into the sampling dynamics"
- Nearest-neighbor score estimator: A local approximation of the score using nearest training samples (plus debiasing draws). Example: "nearest-neighbor score estimator"
- Nuclear Norm-Regularized AutoEncoder (NRAE): An autoencoder trained with nuclear-norm regularization on latent representations. Example: "Nuclear Norm-Regularized AutoEncoder (NRAE)"
- Overdamped Langevin dynamics: A diffusion process without inertia that samples from a target by following the gradient of its potential plus noise. Example: "overdamped Langevin dynamics"
- Pushforward measure: The distribution resulting from mapping a random variable through a function. Example: "the pushforward of the Stiefel Haar measure"
- Retraction (on a manifold): A map sending a tangent-space step back onto the manifold to maintain constraints. Example: "we retract via centered reduced-QR"
- Stiefel Haar measure: The uniform (Haar) measure on the Stiefel manifold of orthonormal frames. Example: "Stiefel Haar measure"
- Stiefel manifold: The set of matrices with orthonormal columns, representing orthonormal d-frames in Rⁿ. Example: "a centered and scaled Stiefel-type manifold"
- Stochastic differential equation (SDE): A differential equation driven by stochastic processes like Brownian motion. Example: "stochastic differential equation (SDE)"
- Tangent space (projection): The linear space of allowable directions at a point on a manifold; projections enforce constrained updates. Example: "onto the tangent space"
- Time reversal: The reverse-time dynamics of a stochastic process used to construct generative samplers. Example: "simulating the time reversal"
- Variational problem: An optimization problem over functions/distributions, often characterizing equilibria via functionals. Example: "a moment-constrained variational problem"
Collections
Sign up for free to add this paper to one or more collections.