- The paper introduces a beam search-guided context optimization pipeline that mitigates context pollution and local optima in post-deployment LLM adaptation.
- It leverages active, web-based retrieval to dynamically integrate external knowledge across translation, healthcare, and reasoning tasks.
- Empirical results demonstrate significant performance gains and data efficiency with as few as 32 training samples compared to traditional methods.
Context Training with Active Information Seeking: A Technical Synthesis
Introduction and Motivation
Contemporary LLMs typically suffer from adaptation brittleness post-deployment: parameter fine-tuning is expensive, prompts are brittle, and closed-loop context optimization workflows cannot induce knowledge not encoded in the parameters. The study presented in "Context Training with Active Information Seeking" (2605.13050) addresses these limitations by re-casting post-deployment task specialization as an iterative context optimization process augmented with active, web-grounded information retrieval. This approach systematically investigates the tension between knowledge generalization, context pollution, and exploration in LLM-centric systems, providing strong empirical evidence across translation, healthcare, and reasoning benchmarks.
Methodological Innovations
The central contribution is a hybrid context optimization pipeline where the optimizer agent is augmented with information-seeking tools (Wikipedia and web browser interfaces) and the optimization proceeds via a beam search rather than naive sequential updates. This dual modification addresses two dominant failure modes in prior context optimization:
- Context Pollution: A small, low-quality edit (e.g., an irrelevant external snippet) can irreversibly degrade downstream performance due to a lack of context recovery/backtracking.
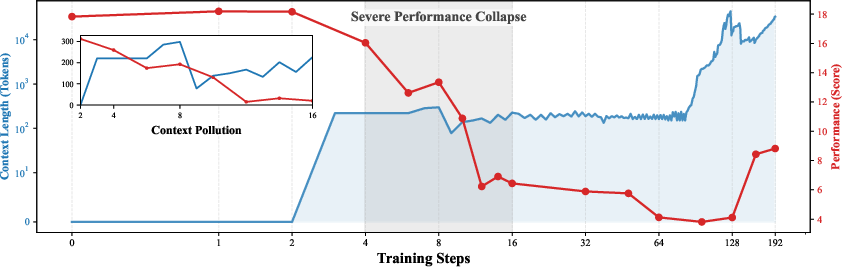
Figure 1: Context pollution in sequential training—small updates can cause severe, persistent context degradation.
- Local Optima: Greedy sequential updates become trapped in strategy basins (e.g., repeatedly adding/removing dictionary entries in low-resource translation), failing to discover higher-utility context compositions.
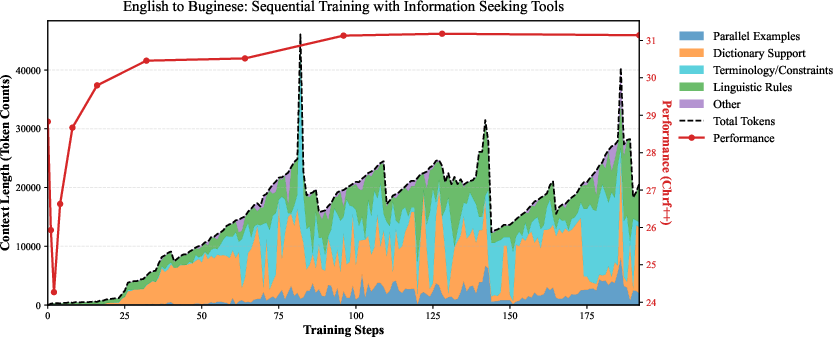
Figure 2: Sequential, linear training can be trapped in local optima, e.g., adding/removing redundant dictionary entries.
The beam search-guided pipeline explicitly maintains a population of candidate contexts, expanding and validating multiple alternative branches in parallel. This facilitates exploration and empirically enables the optimizer to reject both polluted and suboptimal strategies.
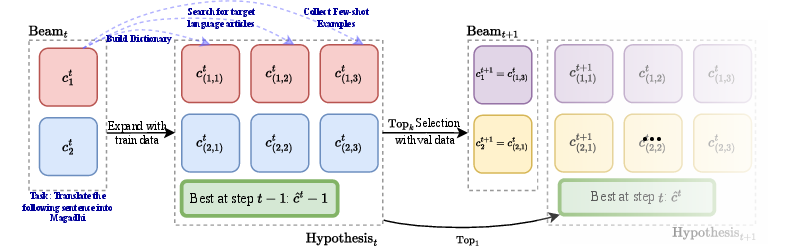
Figure 3: Beam search-guided context training, enabling parallel exploration and guarded acceptance/rejection of context updates.
Experimental Validation
The method is benchmarked across low-resource machine translation (FLORES+), clinical interactions (HealthBench), and reasoning/code-generation tasks (LiveCodeBench, Humanity’s Last Exam).
Low-Resource Translation
Sequential training augmented with information seeking (Seq-IS) exhibits performance degradation, confirming the context pollution hypothesis. Conversely, the beam search variant (BeamSearch-IS) achieves a substantive performance uplift compared to all baselines, including larger models (Gemini-2.5-Pro):
- BeamSearch-IS average score: 34.51, outperforming BoN (31.94), Seq (31.13), and even Gemini-2.5-Pro (30.37).
- This demonstrates that robust verification and pruning mechanisms are essential when introducing external context.
Healthcare Dialogues
BeamSearch-IS not only achieves parity with much larger LLMs on HealthBench, but also exhibits theme-specific gains (e.g., Emergency Referrals), signifying that effective context verification can outperform pure model scaling for high-stakes, error-intolerant tasks.
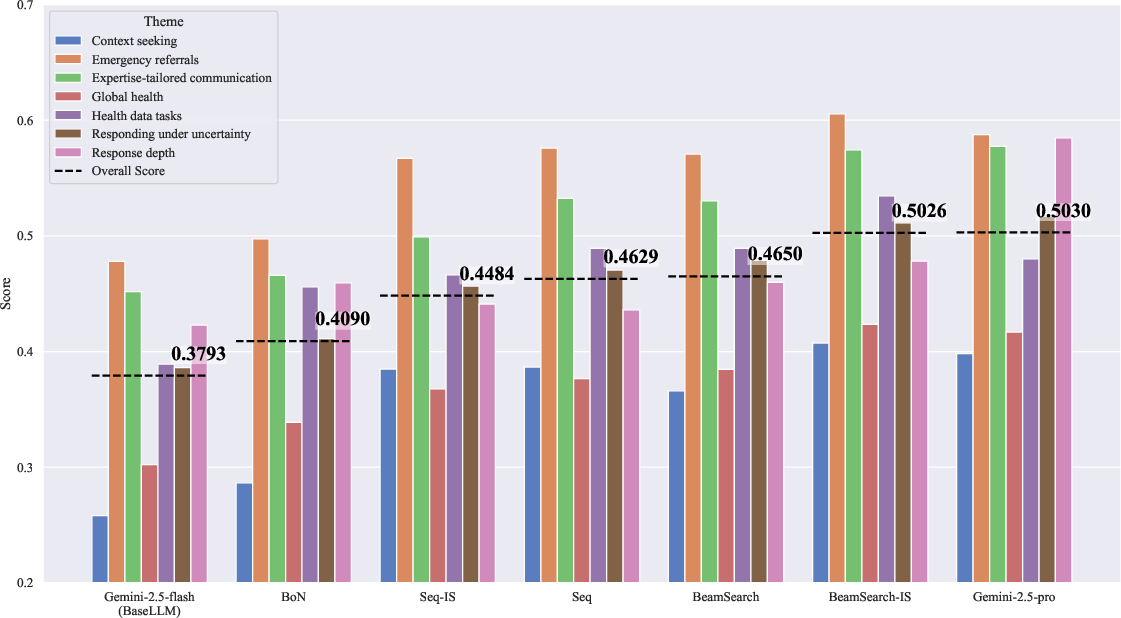
Figure 4: HealthBench results—BeamSearch-IS yields gains on overall and specific scenario metrics compared to both smaller and larger models.
Reasoning and Coding
In reasoning-heavy domains, only BeamSearch-IS provides consistent improvements; methods that lack either external information seeking or sufficient exploration fail to yield material gains, especially in high-variance, instance-specific evaluations. Seq-IS may even regress performance—further validating the necessity for intelligent exploration/backtracking under open-ended information acquisition.
Analysis: Mechanistic and Practical Insights
Trajectory Analysis and Exploration
Visualization of context composition trajectories demonstrates that beam search enables selective retention of diverse, high-value knowledge resources (e.g., linguistic rules, parallel examples) over myopic, local strategies, thus escaping context collapse prevalent in greedy updates.
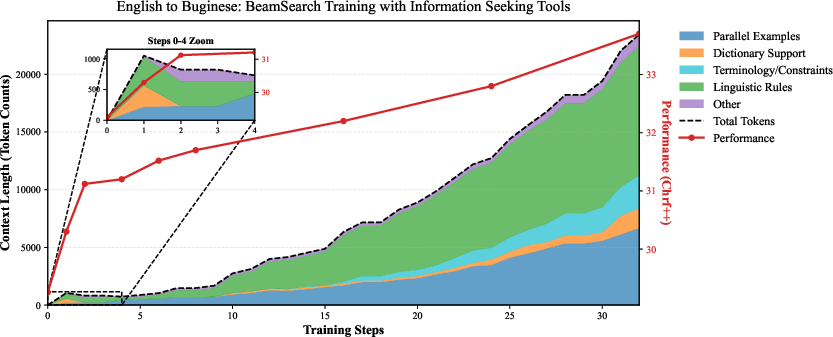
Figure 5: Resource-type composition and translation accuracy—beam search supports "self-correction," discarding ineffective strategies early in training.
Data and Hyperparameter Efficiency
BeamSearch-IS achieves high accuracy with as few as 32 training samples, highlighting its superior sample efficiency versus sequential pipelines. The method is robust to a broad range of hyperparameters, degrading only under extreme, unbalanced settings (e.g., excessive breadth with insufficient depth).
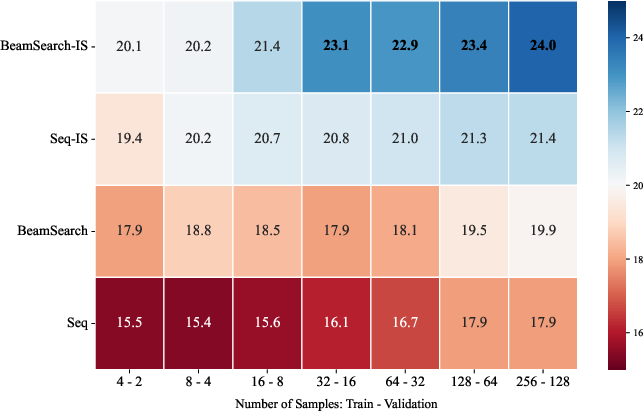
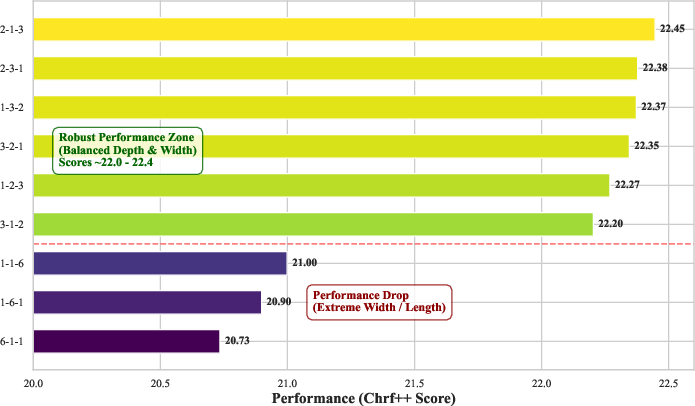
Figure 6: Data efficiency—BeamSearch-IS rapidly converges to high accuracy with limited supervision.
Context Utility and Generalization
Utility heatmaps reveal a sparse, modular context landscape: while many retrieved resources are beneficial only in narrow scenarios, a subset of "dominant resources" generalize across diverse test samples—without evidence of data leakage. Cross-model transfer experiments further show that contexts optimized by BeamSearch-IS generalize to stronger models (Gemini-3-Flash), often yielding even larger gains on reasoning benchmarks. Seq-based optimization, in contrast, primarily captures executor-specific statistics.
Implications and Future Directions
The results presented have several theoretical and practical ramifications:
- Dynamic context optimization requires guarded, population-based search rather than naive, greedy updates, especially when integrating external knowledge. Even in simple plug-and-play contexts, insufficient verification amplifies noise and leads to irreversible context pollution or collapse.
- Active information seeking substantially broadens the effectiveness domain for LLM adaptation, as long as context updates are vetted by parallel validation and selection pressure—otherwise, external grounding may be counterproductive.
- Fine-tuning LLMs via context optimization achieves competitive or superior performance with reduced computational cost and enhanced data efficiency, particularly valuable in low-supervision or emerging domains.
- Generalization of context is shaped by resource composition and exploration breadth, with a small subset of universally helpful resources unlockable only through sufficient search diversity.
- Model-capability bottleneck: Gains from optimized context depend on the executor's capacity to utilize injected knowledge—future work must address both improved context utilization (e.g., architectural attention mechanisms) and more aggressive, diverse context exploration protocols.
Conclusion
"Context Training with Active Information Seeking" formalizes and validates a methodology for enhancing post-deployment LLM adaptability without parameter updates by marrying active web-based retrieval with robust, search-driven context optimization. The beam search mechanism proves essential for suppressing context pollution and fostering task-adaptive generalization. These findings motivate further study of agentic workflows that blend retrieval, exploration, and dynamic context engineering as foundational components of open-ended AI systems.

