- The paper demonstrates that leveraging LLMs to formalize constraint structures yields more correct solutions than heuristic optimizations.
- It compares native Python, constraint modeling with OR-Tools, and declarative MiniZinc paradigms, highlighting model fluency as key to performance.
- The findings caution against heuristic prompts that trade speed for correctness, suggesting a decoupling of specification from solver inference.
Program Synthesis Paradigms for Combinatorial Solving with LLMs: Empirical Analysis and the Heuristic Trap
Introduction
The paper "Formalize, Don't Optimize: The Heuristic Trap in LLM-Generated Combinatorial Solvers" (2605.12421) presents a systematic study of LLM capabilities in synthesizing solvers for combinatorial problems. The authors develop the CP-SynC-XL benchmark (100 problems, 4,577 instances) and compare three paradigms for LLM-based solver generation: native algorithmic search (Python), constraint modeling via a Python solver API (Python + OR-Tools), and declarative modeling (MiniZinc + OR-Tools). The central questions addressed are: which modeling paradigm best aligns with LLM strengths, and is it beneficial or detrimental to prompt LLMs for heuristic-driven search optimizations? The answers have substantial ramifications for neuro-symbolic AI systems leveraging code synthesis for symbolic problem-solving.
Experimental Paradigms and Methodology
The study formulates a factorial experiment across two axes: solver-generation paradigm and prompt specificity (baseline correctness-oriented versus heuristic speed-oriented). LLMs generate reusable solver artifacts for each problem; artifacts are then evaluated for output conformance, correctness (as per a reference verifier), and runtime across a large-scale heterogeneous benchmark.
- Native Algorithmic Search (Python): LLMs generate entire problem-solving algorithms directly in Python, eschewing any solver backends.
- Constraint Modeling via Python (Python + OR-Tools): LLMs encode problem statements as constraint models using the OR-Tools CP-SAT backend via Python API—delegating search/propagation to the solver.
- Declarative Modeling (MiniZinc + OR-Tools): LLMs generate MiniZinc models, which are then solved using the same CP-SAT backend (with output formatters synthesized in a subsequent step).
Prompts are toggled between baseline (correctness only) and heuristic (requesting explicit efficiency improvements), with strict controls on paradigm adherence and external time management. Each artifact proceeds through a refinement protocol involving smoke and scaling checks, with up to four refinement rounds.
Macro Results: Correctness, Fidelity, and Outcome Decomposition
Modeling Surface Drives Correctness
Across all tested LLMs (GPT-5.3-Codex, Gemini 3.1 Pro, DeepSeek-V3.2), the Python + OR-Tools paradigm consistently achieves the highest instance-level correctness at fixed time budgets.
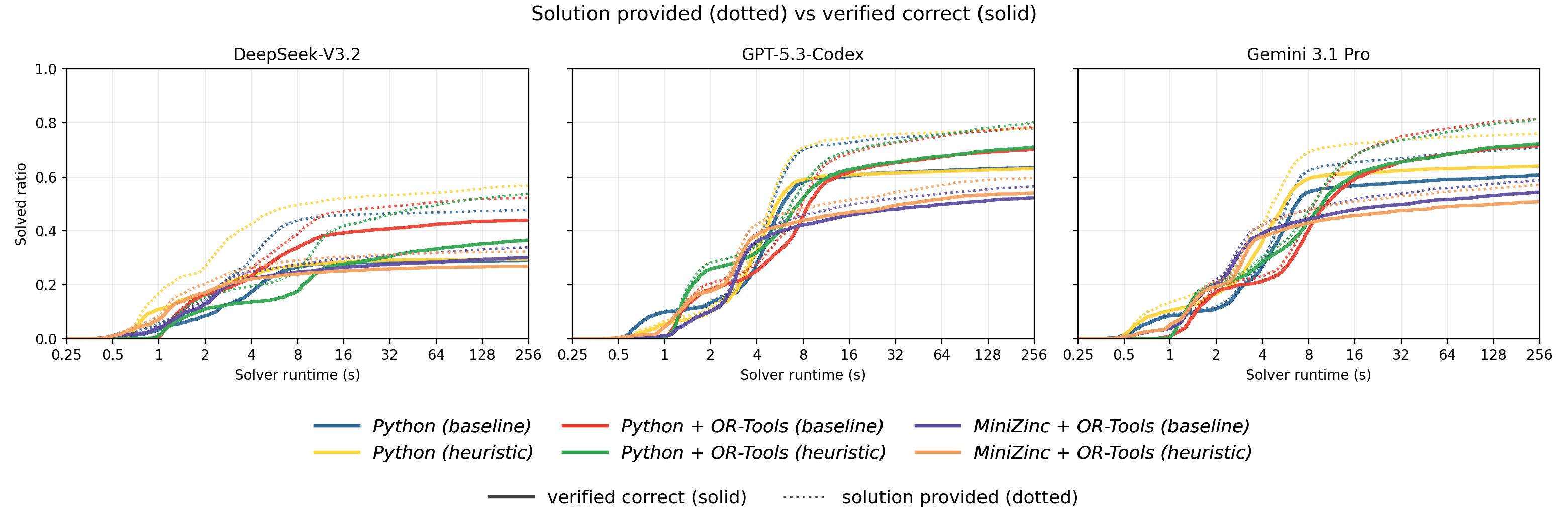
Figure 1: Solution provided (dotted) vs. verified correct (solid) by paradigm and prompt, per LLM (log time axis).
This result holds despite Python + OR-Tools and MiniZinc + OR-Tools sharing the same CP-SAT backend, with the absolute difference attributed to LLM fluency with the modeling API rather than intrinsic solver differences. Native Python trails, often producing schema-conformant but wrong solutions. MiniZinc + OR-Tools demonstrates the highest conditional fidelity (fraction of provided solutions passing verification) but lower coverage; its stricter type and well-formedness checks filter out invalid encodings before solving, leading to fewer but more often correct outputs.
Failure Taxonomy
Comprehensive decomposition of solver outcomes reveals:
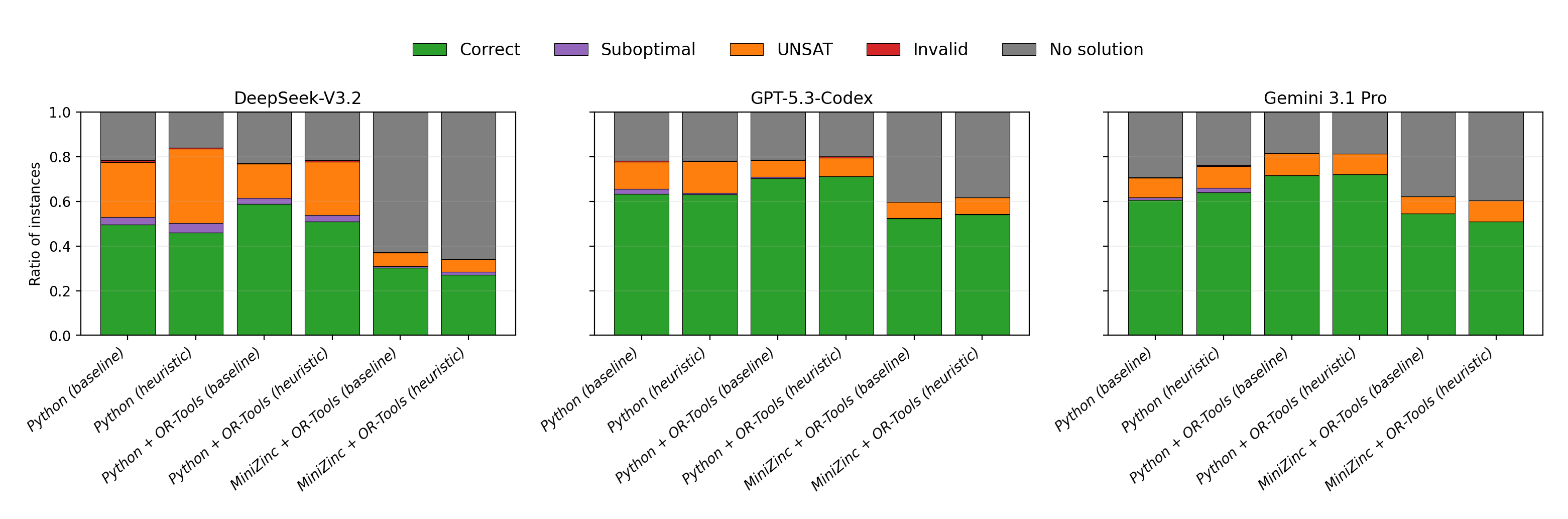
Figure 3: Five-way outcome decomposition by paradigm and prompt, one panel per LLM.
- The largest non-correct category is "no solution," predominantly due to timeouts, not execution failures.
- Suboptimal solutions are predominantly a Python (native search) artifact, where incomplete or greedy hand-written searches fail to guarantee optimality.
- UNSAT (schema-conformant outputs rejected by the verifier) dominates wrong outputs from both solver-backed paradigms, traced to systematic natural-language-to-modeling translation errors (e.g., constraint omission, output-schema ambiguity).
Prompting for Heuristic Optimization is Risky
Across all LLMs, requests for heuristic enhancements do not provide robust, reliable improvements. Speedups are modest (median 1.03–1.12×), often bimodal, and come at a clear cost: correctness reductions, especially for the weaker LLM (DeepSeek-V3.2). On baseline settings, the heuristics may introduce unproven bounds, incomplete local search substitutions, or over-constraining constructs—resulting in regressions that outweigh gains.
Per-Instance and Per-Problem Dynamics
Runtime curves, stratified by paradigm and LLM, show consistent superiority of Python + OR-Tools across instances and domains, while per-problem plots (Figures 5–7) expose specific subdomains especially prone to the heuristic trap.

Figure 2: Per-problem cumulative runtime curves (correct ratio) for GPT-5.3-Codex, highlighting paradigm and prompt variations.
Mechanistic Analysis: The Heuristic Trap
The "heuristic trap" describes six paradigm-specific failure modes induced by heuristic-oriented prompting:
- A (Unverified bounds): LLM-generated bounds or dominance constraints that aren't logically entailed, leading to infeasibility or omission of optima.
- B (Propagation-weakening rewrites): Semantics-preserving constraint transformations that cripple solver-level propagation, increasing solve times or causing timeouts.
- C (Hand-crafted seeding): Overconstrained models or candidate seeds, sometimes enforced as hard constraints, causing optimal region exclusion.
- D (Algorithm incompleteness): Native search solvers dropping complete procedures for incomplete ones (e.g., switching DP for greedy, adding arbitrary iteration caps).
- E (Optimization-to-satisfaction collapse): Heuristic prompt induces LLM to remove objectives and instead enforce unproven optimality as a hard constraint.
- F (Redundant machinery overload): Overcomplicated auxiliary constraint machinery in declarative models, sometimes boosting propagation but often overwhelming flattening or causing model explosion.
Incidence and regression rates for each failure mode are quantified per LLM. Notably, the frequency and impact of these modes differ sharply between stronger and weaker LLMs: heuristic constructs such as AddDecisionStrategy or first_fail are generally safe for GPT-5.3-Codex, frequently unsafe for DeepSeek-V3.2.
Detailed auditing of baseline (correctness-only) solvers demonstrates that most silent failures arise from natural-language-to-formal-language errors, not intrinsic solver deficiencies. Four mechanisms account for the majority:
- M1 (Associative recall): LLMs select an overly generic problem template before parsing the entirety of the natural-language specification.
- M2 (Attention drift): Omission of constraints from long problem descriptions, leading to under-specified models.
- M3 (Output-schema mismatch): Misalignment between the LLM-chosen output mapping and the verifier's expected schema.
- M4 (Sentinel misinterpretation): Incorrect handling of placeholder/sentinel values in inputs.
A fifth (M5) is unique to the native Python paradigm: search-procedure bugs, including incomplete search or fallback to trivial solutions on termination.
Implications for LLM Solver Synthesis
Practical Implications
The results mandate a conservative approach for deploying LLM-synthesized combinatorial solvers:
- Restrict LLMs to formalizing the variable, constraint, and objective structure of the problem; have a verified solver backend execute the search.
- Treat LLM-authored search heuristics with skepticism; validate any optimization claims rigorously using reference circuits before deployment.
- Declarative modeling languages (e.g., MiniZinc) provide higher output fidelity if LLM fluency is sufficient, but current deployment is bottlenecked by LLM code generation weaknesses on these surfaces.
- Avoid native Python search synthesis for high-stakes or large instances; it exhibits a higher rate of overconfident but wrong outputs and is less amenable to external verification.
Theoretical and Future Directions
- The divergence in performance between solver API–based and declarative paradigms rests more on the LLM's training-induced fluency than fundamental limits; future research should prioritize LLM pretraining or finetuning on declarative constraint modeling corpora.
- Symbolic neuro-symbolic pipelines should decouple specification (LLM role) from inference/search (verifiable solver role), using LLMs as "translators" not "optimizers."
- Advances in tool use or cross-representation learning may narrow the modeling-surface gap—targeted dataset augmentation with declarative exemplars, or auxiliary self-verification or repair loops for LLM-generated models.
- The benchmarking methodology here—large instance pools, explicit instance-level verification, and careful surface matching—should become standard for evaluation of AI code synthesis systems deployed in mathematical and industrial reasoning domains.
Conclusion
Empirical evaluation in this study demonstrates that LLMs are currently most effective as code synthesizers that formalize combinatorial problems for trusted, symbolic solvers, not as heuristic designers. Efforts to elicit or inject search optimization through LLM prompts either fail to generate net speedups or frequently reduce solution correctness, especially for less capable LLMs. The main bottleneck is not solver power, but representational fluency and reliable specification translation. Future progress will hinge on LLM-facing improvements in declarative modeling proficiency and on architectures that explicitly guard against the heuristic trap when synthesizing search-algorithmic content.