The Art of Being Difficult: Combining Human and AI Strengths to Find Adversarial Instances for Heuristics
Published 23 Jan 2026 in cs.LG and cs.DS | (2601.16849v1)
Abstract: We demonstrate the power of human-LLM collaboration in tackling open problems in theoretical computer science. Focusing on combinatorial optimization, we refine outputs from the FunSearch algorithm [Romera-Paredes et al., Nature 2023] to derive state-of-the-art lower bounds for standard heuristics. Specifically, we target the generation of adversarial instances where these heuristics perform poorly. By iterating on FunSearch's outputs, we identify improved constructions for hierarchical $k$-median clustering, bin packing, the knapsack problem, and a generalization of Lovász's gasoline problem - some of these have not seen much improvement for over a decade, despite intermittent attention. These results illustrate how expert oversight can effectively extrapolate algorithmic insights from LLM-based evolutionary methods to break long-standing barriers. Our findings demonstrate that while LLMs provide critical initial patterns, human expertise is essential for transforming these patterns into mathematically rigorous and insightful constructions. This work highlights that LLMs are a strong collaborative tool in mathematics and computer science research.
The paper demonstrates that Co-FunSearch leverages human expertise and LLMs to systematically generate adversarial instances that challenge combinatorial optimization heuristics.
It employs an iterative method combining evolutionary search and expert analysis to reveal superpolynomial and exponential lower bounds in classical problems like knapsack and bin packing.
The framework refines heuristic design and theoretical bounds by exposing structural weaknesses, setting new performance standards for adversarial benchmarking.
Human-AI Collaboration for Adversarial Instance Generation in Combinatorial Optimization
Motivation and Context
The paper analyzes the synergy between human mathematical expertise and LLM-driven automated search in constructing adversarial instances for classic heuristics in combinatorial optimization. Adversarial instance generation is of high importance: it exposes the limitations and failure modes of heuristics, tightens theoretical bounds, and facilitates heuristic design by revealing structural weaknesses. While prior efforts in this space have utilized black-box metaheuristics or neural architectures, these approaches tend to generate opaque solutions lacking interpretability and generalizability. Recent advances such as FunSearch have demonstrated that LLMs can synthesize interpretable Python programs representing mathematical constructions, thus supporting human inspection and refinement.
Co-FunSearch: Methodological Framework
The authors propose Co-FunSearch, a collaborative framework wherein LLMs (via FunSearch) are leveraged to generate candidate instances or programs that encode hard instances for specific heuristics, which are then manually inspected, distilled, and generalized by human experts. The iterative cycle consists of:
Seeding FunSearch with initial trivial or structured programs encoding combinatorial instances.
Running evolutionary search with LLMs to generate programs maximizing the adversarial objective (e.g., approximation ratio of heuristic vs. optimum).
Manually analyzing generated programs for structural patterns, redundancies, and possibilities for simplification/generalization.
Feeding back refined programs or leveraging their structure for mathematical proofs of strengthened bounds.
This approach systematically transfers the burden of brute-force exploration to LLMs while reserving high-level reasoning, theoretical generalization, and formal proofs for humans.
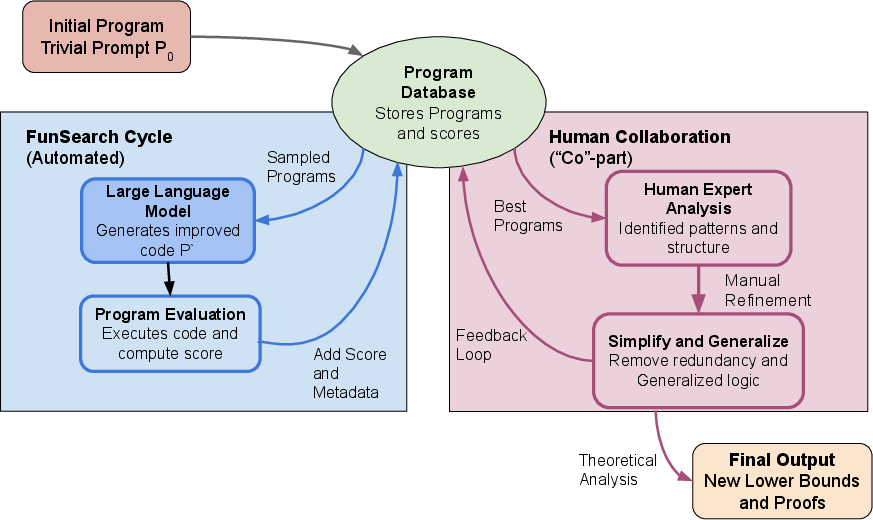
Figure 1: A diagrammatic representation of Co-FunSearch, showing the iterative feedback loop between FunSearch's syntactic instance generation and human-guided analysis.
Empirical and Theoretical Results
Knapsack Problem (Nemhauser-Ullmann Heuristic)
The bi-objective knapsack problem asks for Pareto-optimal subsets balancing profit and weight. The longstanding open question is whether Nemhauser-Ullmann runs in output-polynomial time. Co-FunSearch generated instances where intermediate Pareto sets (Pi) vastly outsize the final Pareto set (Pn), yielding a superpolynomial lower bound of nO(n) on runtime—directly contradicting the output-polynomial hypothesis (2601.16849). Later, an exponential lower bound construction (by independent methods, but also confirmed via the framework) emerged.
Bin Packing (Best-Fit Heuristic)
Best-Fit in the random order model previously had a lower bound of 1.3 for its expected ratio over optimum, versus an upper bound of 1.7. Co-FunSearch empirically and theoretically constructs a family of adversarial instances where the ratio provably reaches 1.5, narrowing the gap and improving the previous best lower bound (2601.16849). The scenario relies on particular patterns where coprimalities force bins to overflow.
Hierarchical k-Median Clustering (Price of Hierarchy)
For k-median hierarchical clustering, no nontrivial lower bounds existed for the “price of hierarchy”—the worst-case ratio between hierarchical and unconstrained clusterings. Co-FunSearch discovers high-dimensional constructions where the lower bound converges to the golden ratio (≈1.618), delivering the first nontrivial results in this regime (2601.16849).
Gasoline Problem (Iterative Rounding Algorithm)
A variant of Lovász's gasoline puzzle, generalized to d dimensions, was conjectured to admit a 2-approximation guarantee via the iterative rounding algorithm. Co-FunSearch refutes this, finding explicit families that empirically reach ratios up to 4.65 for higher d, violating the conjectured bound and implying open questions regarding approximation algorithms for this setting (2601.16849).
Comparative Evaluation and Ablation
Across all tasks, FunSearch outperforms classical local search in both the quality of adversarial instances and the modularity/interpretability of solutions. The approach is robust to hyperparameters (e.g., model size, temperature, initial prompt structure), as ablation studies indicate smaller LLMs can sometimes find stronger individual adversarial examples due to higher sample diversity. Relevant details are systematically presented in the empirical section.
Implications
Practical
The framework operationalizes LLMs as effective searchers for hard instances, widening their role from conjecture generation to adversarial benchmarking of classic heuristics. This lowers manual effort for instance discovery in algorithm analysis and offers a template for semi-automating adversarial construction in future algorithm design and evaluation pipelines.
Theoretical
The results update best-known lower bounds—sometimes by disproving longstanding conjectures—in multiple canonical settings. Importantly, they demonstrate the necessity of human mathematical reasoning atop LLM outputs to distill structural insights and formal generalizations, as LLMs alone do not consistently yield proof-ready constructs.
Speculative Future Directions
Integration of proof-assistance tools with LLMs could further automate the discovery-proof cycle.
The methodology is extensible to other domains (e.g., scheduling, graph algorithms, cryptography).
Scaling up model size and engineering for higher-level mathematical reasoning could reduce the gap between empirical and provable adversarial bounds.
Adversarial benchmarking via LLM-human collaboration might become an industry standard for algorithm certification.
Conclusion
The paper establishes that human-AI collaboration—specifically the use of interpretable program synthesis via LLMs, paired with expert-guided formalization—can drive meaningful advances in adversarial instance generation for combinatorial optimization heuristics. The Co-FunSearch framework notably improves or refutes state-of-the-art bounds in several classic algorithmic domains. While limitations persist in full automation and generalizability, this paradigm signals a step-change in the methodological toolbox available to algorithm designers and theoreticians, with wide-ranging implications for both theory and practice.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.