- The paper introduces ProfiliTable, a multi-agent system that uses dynamic profiling to resolve ambiguities and ensure runnable outputs in tabular data processing.
- It employs iterative feedback, role-specialized LLM agents, and RAG-based operator retrieval to decompose and refine complex table tasks.
- Empirical results show that ProfiliTable achieves a 100% task-wise runnable rate and superior accuracy compared to existing baselines on multi-step workflows.
ProfiliTable: Profiling-Driven Tabular Data Processing via Agentic Workflows
Motivation and Problem Landscape
The increasing ubiquity of tabular data in high-stakes domains exposes substantial deficits in existing LLM-based automation for table processing. Semantic inconsistency, data incompleteness, and heterogeneity in structure demand adaptive, context-aware solutions for cleaning, transformation, augmentation, and matching. Most prior LLM-centric methods are brittle in the face of ambiguous instructions and complex workflows, frequently yielding syntactically valid but semantically erroneous code. Notably, these deficits stem from the lack of structured, dynamic profiling and feedback mechanisms; existing tools either narrowly focus on atomic operations or employ static rule-driven profiling, failing to capture and resolve real-world ambiguities.
Approach: Dynamic Profiling and Multi-Agent Architecture
ProfiliTable introduces a multi-agent framework driven by dynamic profiling, treating the semantic construction of tabular context as an interactive, evolving process rather than static metadata consumption. The system orchestrates a set of role-specialized LLM agents—Interpreter, Profiler, Decompositer, Generator, Evaluator, Summarizer, and Finalizer—within a self-improving closed-loop pipeline. This architecture is centered around three core mechanisms:
- Interactive ReAct Profiling: The Profiler actively explores table context to resolve ambiguities in user instructions by sampling and analyzing actual cell values instead of relying on column metadata. This enables the resolution of tasks involving implicit mappings or contextual standardizations.
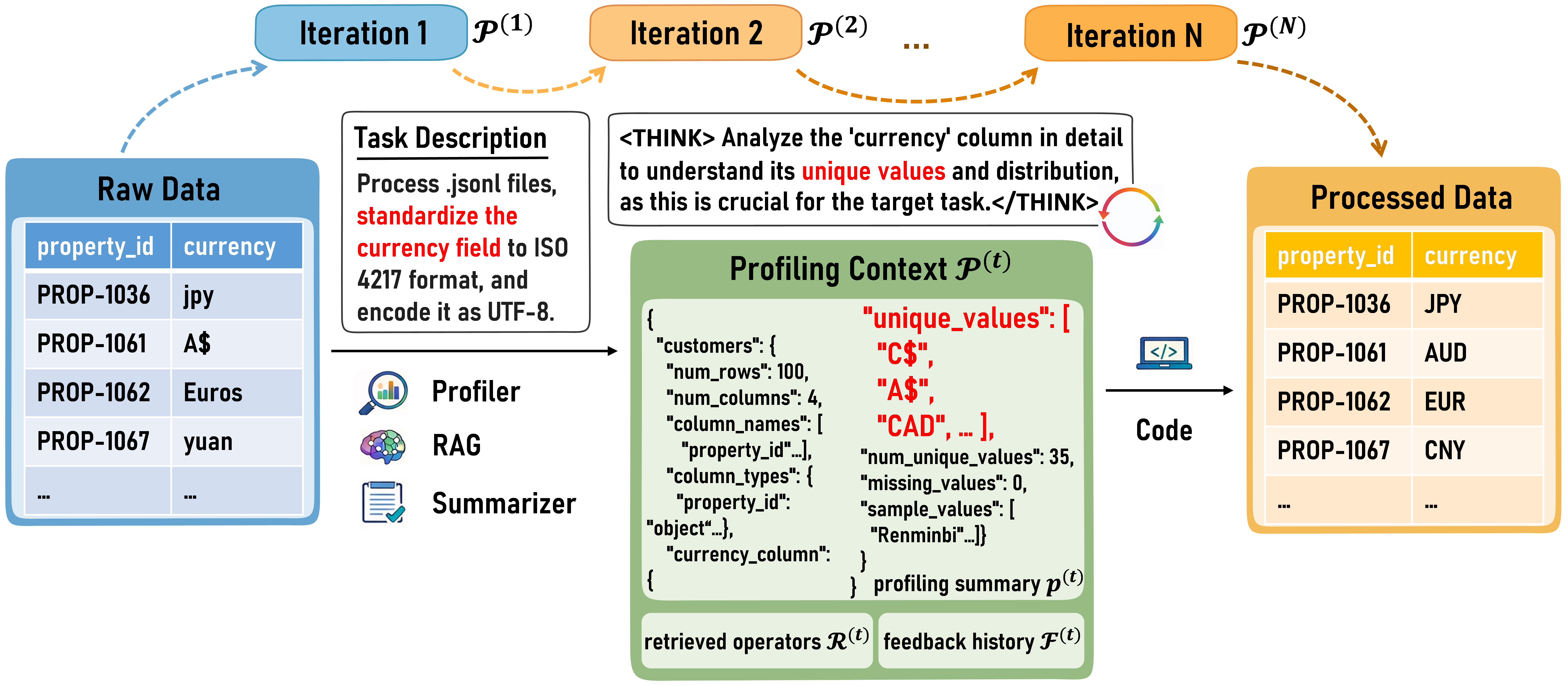
Figure 1: Profiling reveals ambiguous instructions and recovers concrete currency symbols for accurate ISO 4217 mapping.
- Knowledge-Augmented Synthesis: For each atomic or decomposed subtask, the Generator retrieves pre-validated operator templates via RAG, grounding code synthesis in domain-specific primitives.
- Feedback-Driven Iterative Refinement: The pipeline integrates structured feedback at each iteration, including execution scores, error diagnostics, and alignment assessments. The Summarizer systematically validates outputs using a ReAct-style loop and propagates insights for subsequent refinement.
Figure 2: The autonomous workflow of ProfiliTable: a self-improving, closed-loop pipeline centered around a dynamic profiling context with specialized LLM agents.
Decomposition of multi-step tasks is handled by the Decompositer, which translates complex objectives into sequenced, granular subgoals, each independently profiled and solved. The iterative architecture ensures convergence via the Finalizer, guaranteeing that the most performant candidate—measured by rigorous task-specific metrics—is always returned, even when perfect completion is unattainable.
Experimental Evaluation and Quantitative Results
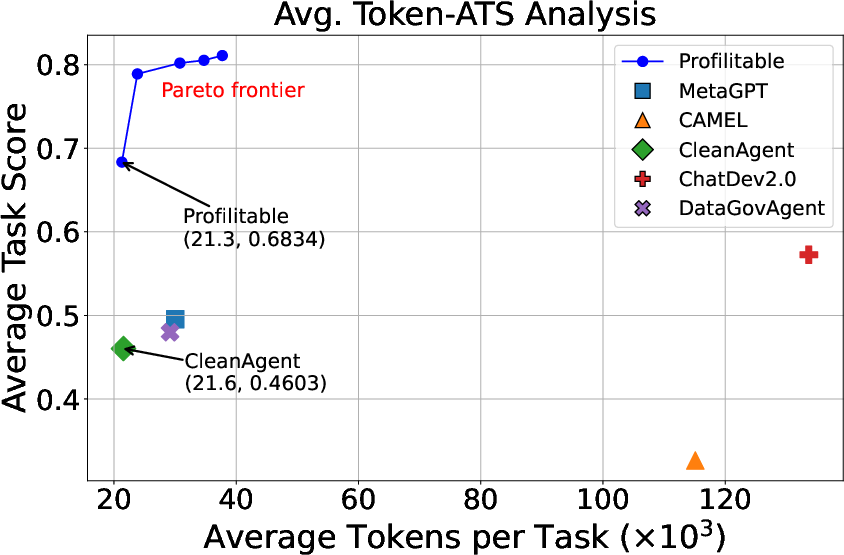
Extensive benchmarking across 18 fine-grained categories (cleaning, transformation, augmentation, matching) reveals that ProfiliTable outperforms all compared baselines (DataGovAgent, CleanAgent, CAMEL, ChatDev2.0, MetaGPT, DeepAnalyze), particularly in challenging multi-step workflows. Notably, ProfiliTable is the only method achieving a 100% task-wise runnable rate in multi-step settings, ensuring every task yields an executable output suitable for production.
Key numerical findings:
ProfiliTable also traces a Pareto frontier in cost-effectiveness (minimal tokens for maximal accuracy), evidencing high efficiency relative to solution quality. Performance is sharply sensitive to the RAG hyperparameters: optimal retrieval of k=2 operators at a similarity threshold θsim=0.5 maximizes both diversity and relevance, preventing context pollution from irrelevant or noisy exemplars.
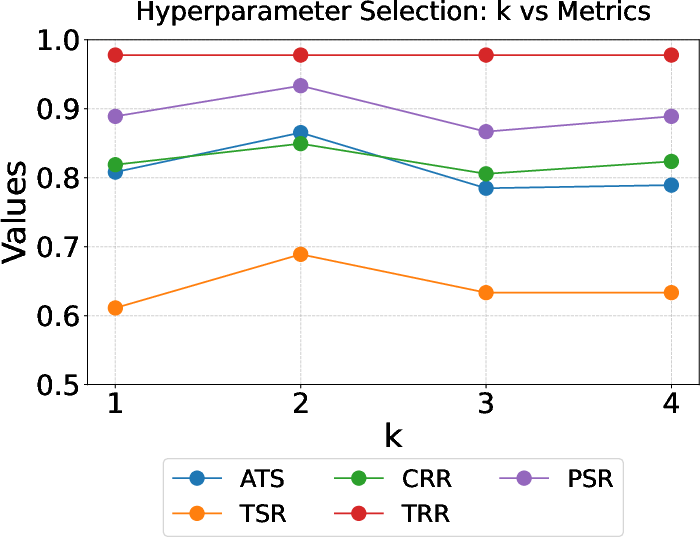
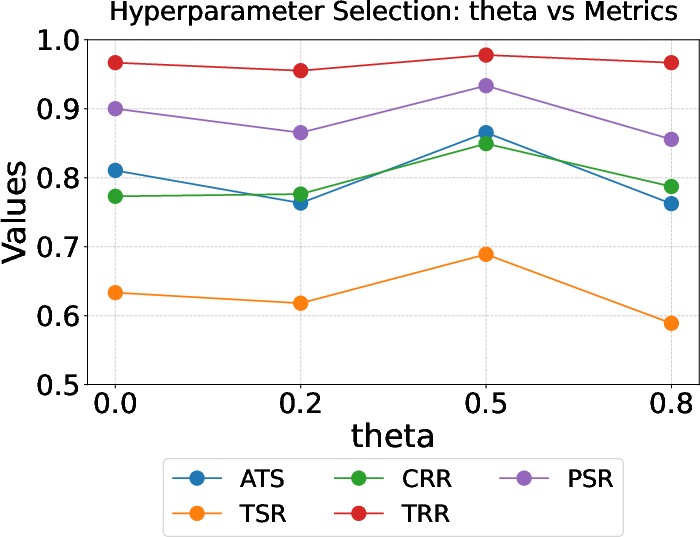
Figure 4: Effect of hyperparameters k and θsim on single-step performance (gpt-4o).
Ablation and Component Analysis
Ablation studies indicate that all core modules are indispensable:
- ReAct Profiler: Disabling this module causes marked drops in accuracy and robustness, especially in multi-step workflows, reverting the system to static profiling reminiscent of inferior baselines.
- Feedback Mechanism: The absence of the Summarizer and iterative refinement causes the most severe degradations across correctness metrics and propagates failures in multi-step composition.
- RAG-Based Operator Retrieval: Removing RAG leads to higher hallucination rates and decreased correctness, although its impact is less pronounced than profiling/feedback.
- Decompositer: Targeted ablation shows its maximal benefit at mid-complexity steps in multi-step tasks, sharply increasing ATS and preventing error accumulation by enforcing granular, ordered execution.
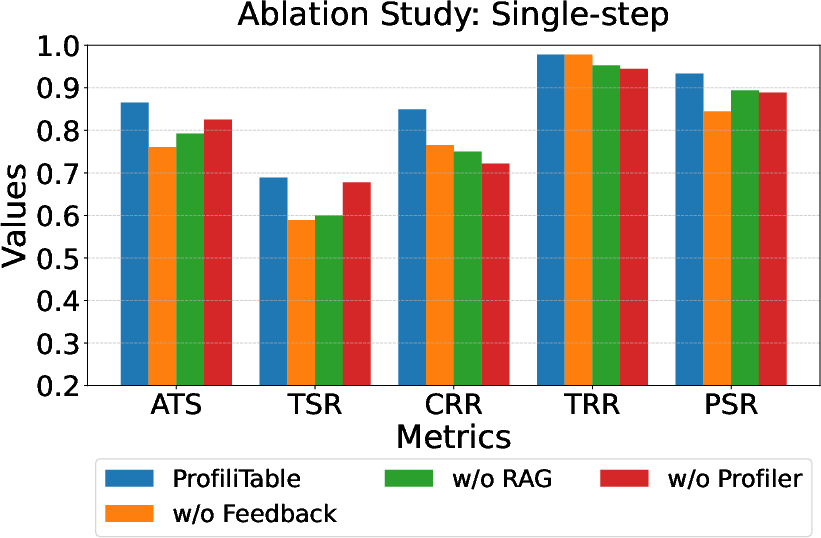
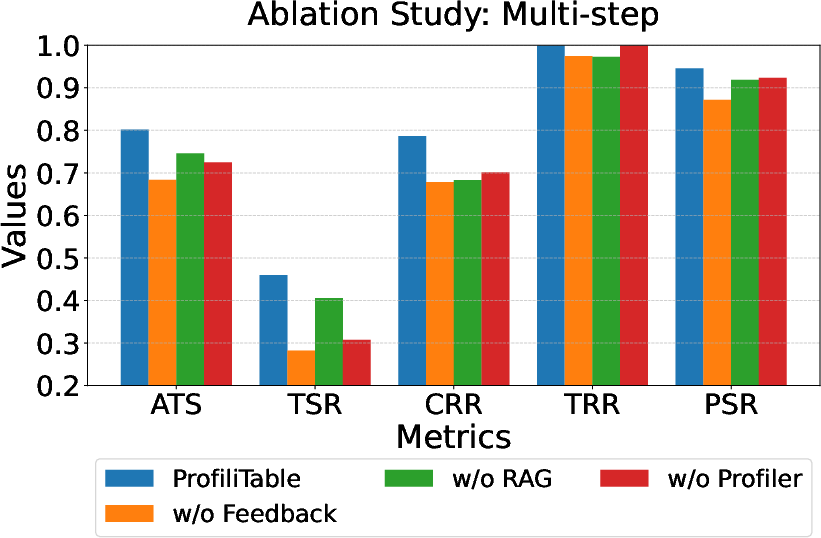
Figure 5: Ablation study of ProfiliTable components across task complexities. Removing any module degrades performance, with severe drops upon disabling feedback.
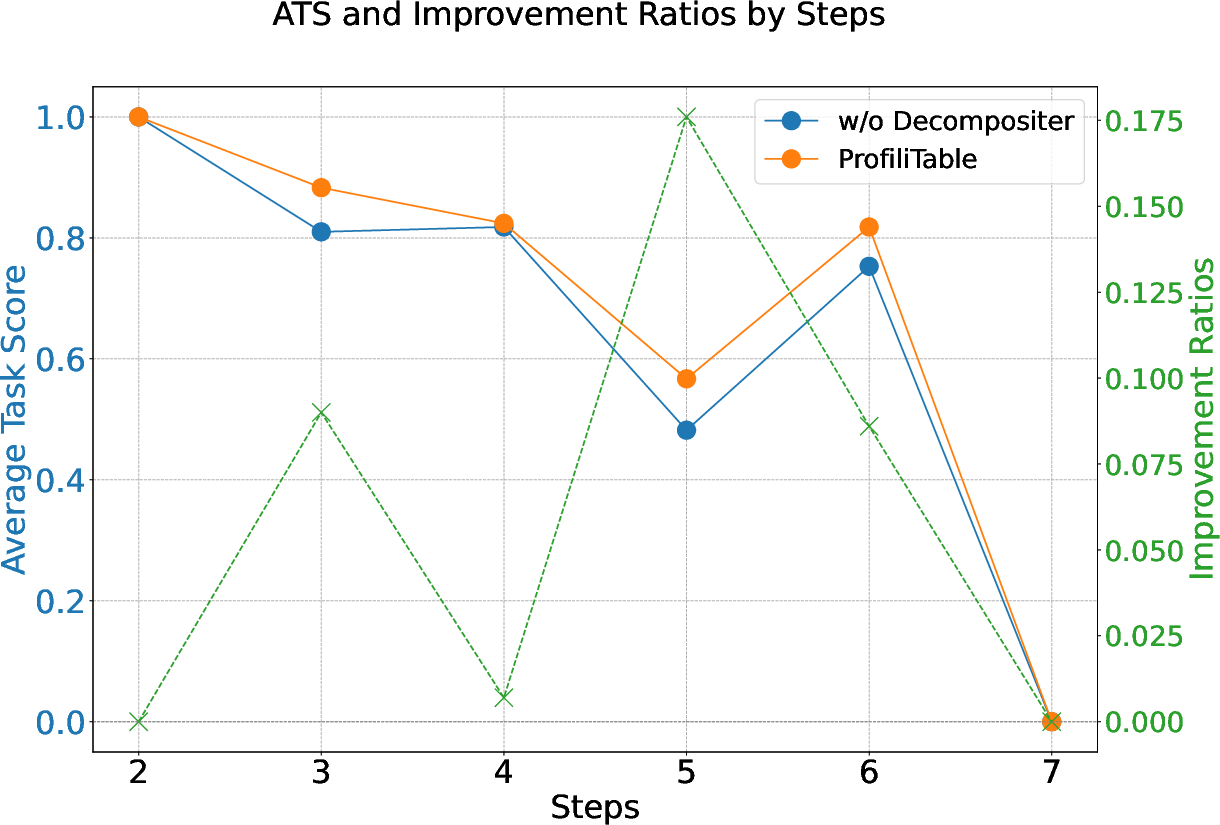
Figure 6: Impact of enabling or disabling the Decompositer module on step-wise performance in multi-step tasks (gpt-4o).
Practical and Theoretical Implications
The empirical superiority of ProfiliTable demonstrates that LLM-based automation for table processing cannot circumvent the need for dynamic, hypothesis-driven profiling and reflection. This framework guarantees both high-fidelity output and operational reliability (i.e., code always runs), aligning with deployment requirements in production data pipelines. The paradigm of profiling-driven agency—where agents iteratively ground their actions in active data exploration, structured retrieval, and rigorous feedback—substantiates a shift from static script generation to interactive, self-correcting workflows.
Remaining bottlenecks include diminished performance in ultra-deep pipelines and interpretive failures arising from vague or contextually incomplete instructions—challenges that point to the need for richer data-centric training and advances in task decomposition strategies. The agentic paradigm instantiated by ProfiliTable is extensible beyond table processing, suggesting fertile ground for future research in interpretable, closed-loop AI workflows for heterogeneous data modalities.
Conclusion
ProfiliTable establishes dynamic profiling as the cornerstone of robust, scalable, and governance-compliant tabular data processing via autonomous multi-agent workflows. The closed-loop architecture, grounded in specialized agent collaboration and active context construction, achieves superior accuracy, efficiency, and reliability compared to prevailing methods. This work signals a methodological shift in LLM-based automation: from passive, static prompt engineering towards profiling-driven, reflection-centric agentic systems, setting a precedent for deployment-grade, adaptive AI in real-world data pipelines (2605.12376).