- The paper introduces a dual-stage design that uses block-level importance estimation and tile-level rescue to accelerate sparse prefill execution.
- The methodology leverages softmax mass estimation and robust rescue strategies to balance computational efficiency with task fidelity.
- Empirical results demonstrate up to 2.5× speedup on long-context models while maintaining near-baseline performance on key benchmarks.
Block-Filtered Long-Context Attention (BFLA) for Efficient Sparse Prefilling in LLMs
Motivation and Positioning
The computational bottleneck of transformer-based LLMs originates from the O(N2) complexity of scaled dot-product attention (SDPA), especially during the prefilling stage when processing long contexts. While linear and hybrid attention mechanisms offer acceleration, they frequently sacrifice fidelity by deviating from the softmax kernel, or require retraining. Sparse attention is unique in enabling training-free approximation of full attention outputs, making it particularly relevant for the deployment of pretrained LLMs in scenarios demanding large context windows.
Existing sparse attention techniques are classified as static (fixed, input-independent patterns) or dynamic (input-adaptive selection). Dynamic approaches have emerged as the dominant paradigm for long-context inference. BFLA distinguishes itself by combining a hierarchical, dual-stage design with fused sparse prefill execution, targeting plug-and-play acceleration without model modification or retraining.
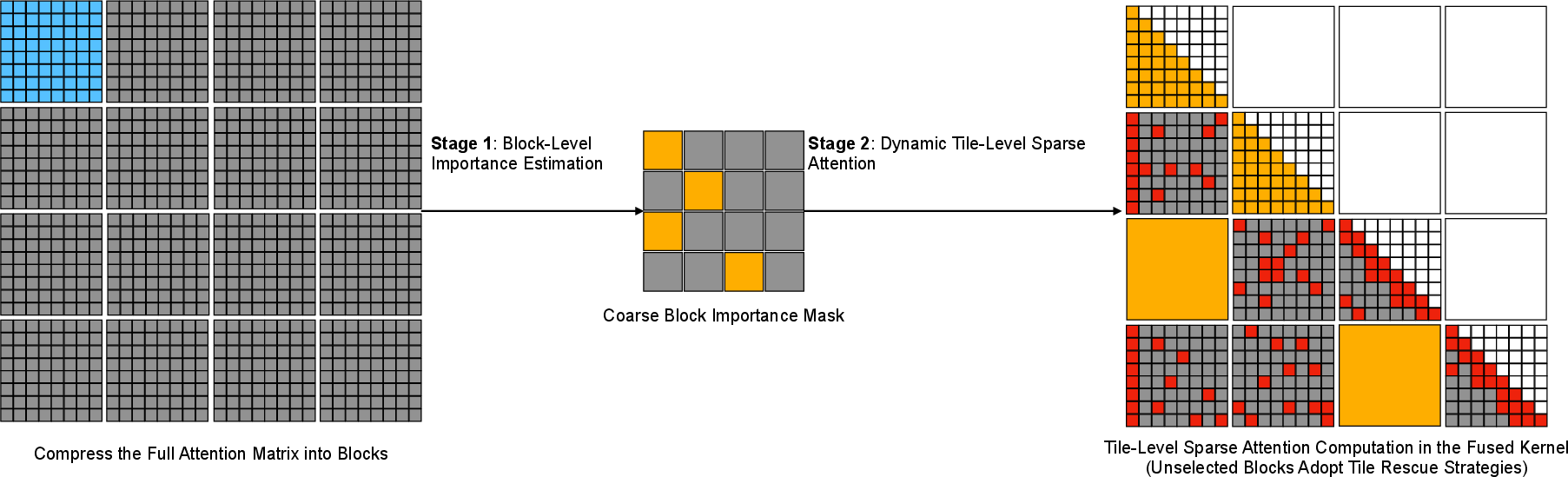
Figure 1: BFLA architecture with dual-stage processing—block-level importance estimation followed by expansion to the attention tile grid, leveraging multiple tile-level rescue strategies and fused sparse prefill computation.
Methodology
Stage 1: Coarse Block-Level Importance Estimation
BFLA partitions query and key sequences into blocks and generates pooled block representations via flattening-g pooling. Block-level scores are calculated using softmax mass estimation, which determines importance based on causal attention probability. The keep-mass selection sorts blocks by their probability and selects those exceeding a tunable threshold γ, producing a coarse mask. This mask is efficiently constructed via a combination of max-pooling and lightweight attention scoring, greatly minimizing construction overhead as compared to alternative block-sparse methods.
Stage 2: Tile-Level Sparse Execution and Rescue Mechanisms
The coarse block mask is expanded onto the Triton attention-tile grid. Within this, several robustness-oriented tile-level rescue strategies are applied:
- Local band rescue: Adds local windows to preserve locality-sensitive dependencies.
- Attention sink rescue: Ensures preservation of sinks (key initial tokens) critical for streaming and prompt alignment.
- Speculative/rescue: Optionally applied to stochastically or deterministically reintroduce some dropped tiles to counteract information loss.
This mask is then used by a fused sparse prefill kernel, which skips dropped tiles entirely and computes exact token-level causal attention within retained tiles. Notably, the sparsification does not materialize the sparse matrix; instead, it is directly fused into the prefill execution, minimizing memory I/O as well as runtime.
Experimental Analysis
Prefilling Efficiency
Empirical results across Gemma 4, Qwen 3.6, and other major models demonstrate strong context-dependent acceleration. BFLA achieves negligible or negative speedup at 2K context length; however, speedup increases consistently with longer contexts, reaching up to 2.501× at 128K (Qwen 3.6-27B). The throughput improvements are substantial (e.g., increasing from 7,216 tokens/s to 18,043 tokens/s for 128K context on Qwen 3.6-27B). This confirms that the mask-construction overhead is amortized over computational savings, particularly in long-context settings.
Task Fidelity
BFLA achieves minimal degradation on diverse benchmarks, matching or marginally deviating from full attention in key metrics:
- LongBench (average): BFLA (0.3975) vs. Full (0.4022)
- MMLU Pro, AIME 2026, GPQA Diamond, LiveCodeBench v6: Deviations are within 1%.
- On retrieval-heavy subtasks, modest degradation is noted, indicating sensitivity to aggressive sparsification. However, BFLA sometimes improves performance on summarization/comprehension tasks, possibly due to noise filtering.
Sparsity and Construction Overhead
BFLA enables significant sparsity control, achieving up to 91.25% sparsity with only 1.65ms mask construction overhead on Llama 3.1-8B. The mask-building overhead is up to 5× lower than XAttention under similar performance regimes. When more tiles are retained, BFLA approaches dense-attention performance while maintaining 56.63% sparsity and low construction time, confirming its flexibility.
Theoretical Implications
The hierarchical dual-stage design, accompanied by upper-bound analysis, affirms that the block-level importance estimation followed by tile-level expansion offers provable complexity reduction. The final computational complexity is O(κHqNqNkvC) where g0 is the kept fraction of tiles. The bound on output difference g1 is controlled by the norm of the mask difference and block selection quality, implying that high mass thresholds g2 and robust rescue configurations ensure fidelity.
Practical and Theoretical Impact
BFLA demonstrates practical utility for plug-and-play acceleration in vLLM-style inference pipelines, requiring no retraining, calibration, or architectural modification. Its capacity for runtime sparsity control and efficient mask fusion makes it suitable for system-level deployment in both cloud and device settings.
Theoretically, BFLA sets a template for hierarchical sparse attention, balancing accuracy with efficiency, and showing the viability of selective softmax-based sparsification in practical workload acceleration. Its methodology could inform future research on dynamic attention mechanisms, sparse memory management, and adaptive sequence modeling, including multimodal and sequential RL domains.
Future Developments
Anticipated future directions include:
- Adapting the mask-construction process for continuous, streaming, or multi-modal contexts.
- Integrating BFLA with state-space models (e.g., Mamba) and hardware-aware hybrid schemes.
- Investigating dynamic head pruning and further hierarchical decomposition—pushing computational efficiency boundaries while preserving task fidelity.
Conclusion
BFLA offers a dual-stage, block-filtered, training-free sparse attention mechanism tailored for efficient long-context inference in LLMs (2605.12193). It combines coarse mass-based block importance estimation, robust tile-level rescue strategies, and fused execution to achieve significant acceleration with minimal task degradation. BFLA is demonstrably system-friendly and accurate, being an effective sparse attention backend for modern LLM deployment, and establishes foundational principles for future scalable attention designs.