- The paper demonstrates how fine-tuning only the classifier layer versus full-network tuning significantly affects accuracy density and training efficiency.
- It systematically evaluates eleven CNN architectures across five diverse datasets to reveal the tradeoffs in accuracy, model size, and computational cost.
- The findings highlight that models like SqueezeNet and ResNet-18 offer exceptional parameter efficiency, guiding optimal model selection for resource-constrained deployments.
Evaluation of Transfer Learning Strategies Across Deep Neural Network Architectures for Image Classification
Introduction
This paper systematically benchmarks transfer learning performance for image classification tasks using eleven canonical convolutional neural network (CNN) architectures, all pre-trained on ImageNet, and evaluates them across five target datasets (CIFAR-10, MNIST, Hymenoptera, an original smartphone dataset, and an augmented smartphone dataset). The study investigates two fine-tuning paradigms: retraining only the classifier layer while freezing feature extractors and full network fine-tuning. The evaluation considers not only classification accuracy but also accuracy density (accuracy per parameter), training time, and model memory footprint, providing a multi-criteria framework for model selection in practical scenarios with diverse computational or deployment constraints.
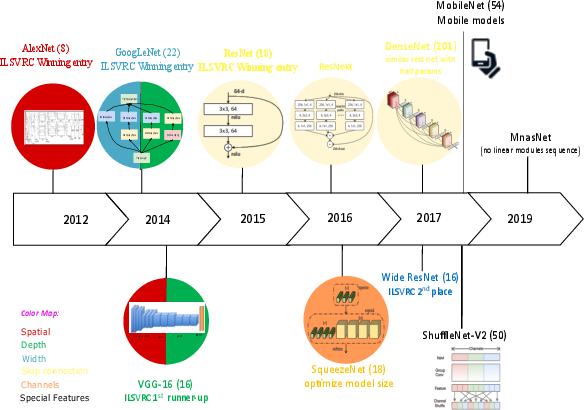
Figure 1: Infographic of the tested pre-trained models, showing their architectural family, parameter depth, and core design principle.
Models and Datasets
The architectural diversity spans early spatially-oriented models (AlexNet, VGG-16) through width/depth balanced designs (GoogLeNet, WideResNet), to compact/mobile-focused architectures (MobileNet, SqueezeNet, ShuffleNet-V2, MnasNet), and sophisticated skip-connection-based models (ResNet-18, DenseNet, ResNext). The model selection represents the dominant design patterns in modern CNNs, as highlighted in the architectural summary.
Target datasets were selected to vary in size, granularity, and domain distribution:
Experimental Design and Metrics
Two primary transfer learning protocols were evaluated for each architecture-dataset pair:
- Classifier-only fine-tuning: Only last-layer parameters updated; all other weights frozen.
- Full-network fine-tuning: End-to-end adaptation; all parameters updated.
Each protocol is tested in low-shot regimes: one-episode (single presentation per sample) and ten-episode (ten presentations each). Optimization leveraged the ADAM optimizer across a grid of learning rates, with batch size 10, and early stopping based on maximal validation accuracy.
Key evaluation metrics are:
- Absolute accuracy (standard classification performance)
- Accuracy density (accuracy/#parameters), measuring parameter efficiency
- Training time (seconds on a GTX 1080 Ti GPU)
- Model size (in MB, reflecting memory and deployment constraints)
Comparative Results
In the most constrained (one-episode) adaptation, SqueezeNet demonstrated the highest accuracy density under full-network fine-tuning, reflecting a strong design for parameter-efficient adaptation, while ResNet-18 was optimal when only classifier parameters were updated.
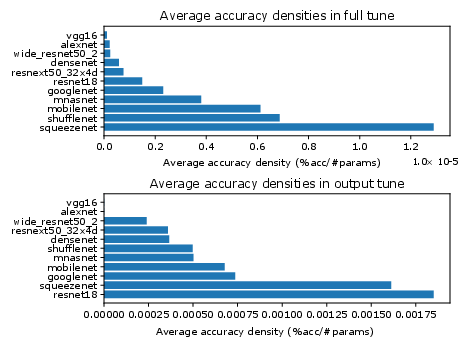
Figure 3: Average accuracy densities for all architectures across all datasets in the one-episode regime.
Dataset-specific results further revealed that certain architectures maintained consistent robustness or exhibited differential behavior based on target domain shifts, data augmentation, and training protocol.
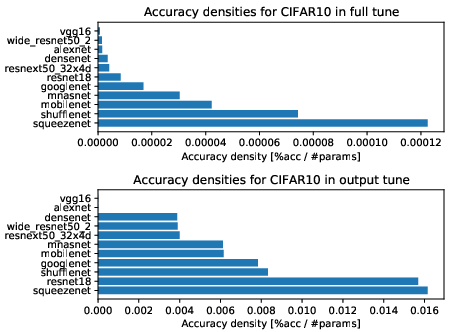
Figure 4: Accuracy densities for one-episode learning on CIFAR-10 show architecture-dependent shifts in relative efficiency.
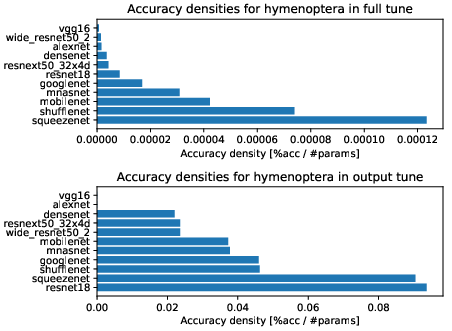
Figure 5: Performance density for one-episode learning on Hymenoptera, a small fine-grained dataset.
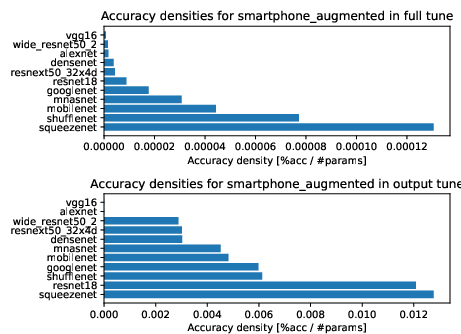
Figure 6: Accuracy densities on the challenging augmented smartphone dataset highlight varying generalization across architectures.
Model size and training time analyses exposed significant tradeoffs: while AlexNet had the shortest training time under all protocols, its accuracy density was markedly inferior to parameter-efficient architectures such as SqueezeNet and ShuffleNet-V2.
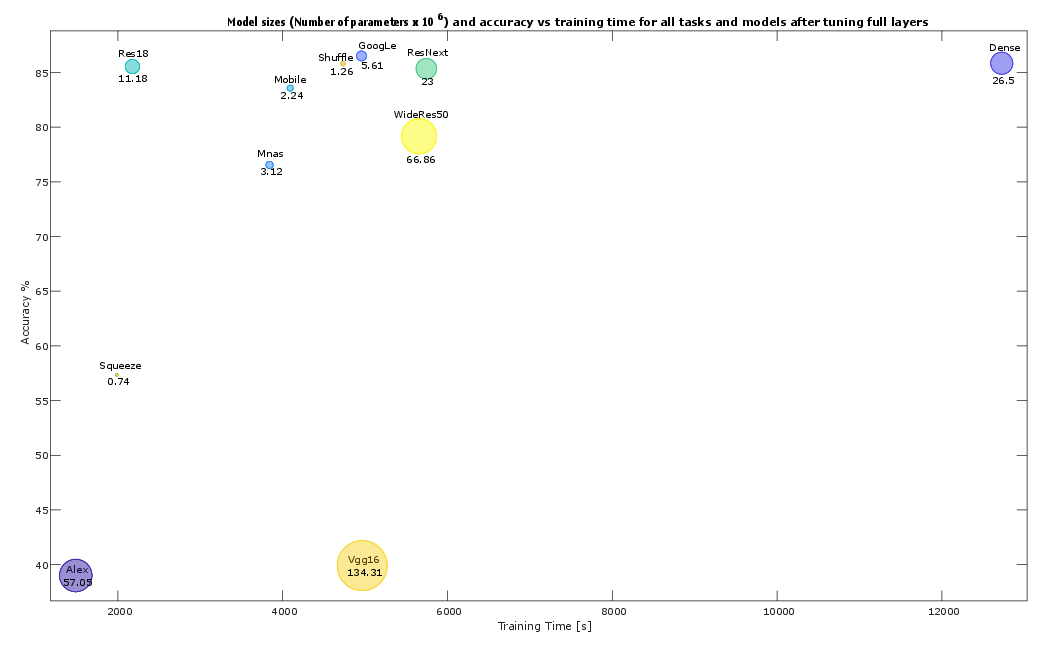
Figure 7: Model size and accuracy versus training time for all architectures and tasks after full-layer fine-tuning.
Ten-Episode Fine-Tuning
Increasing the number of training episodes produced only marginal gains in accuracy density and did not alter the ranking of architectures with respect to parameter efficiency and overall accuracy. Again, SqueezeNet led in accuracy density for full fine-tuning, and ResNet-18 dominated with classifier-only updates.
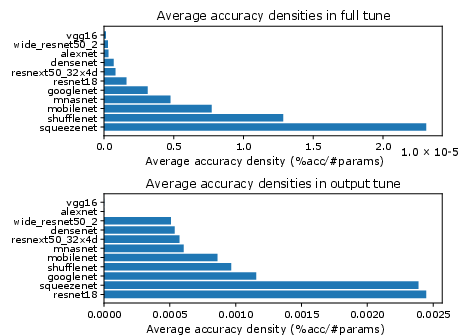
Figure 8: Average accuracy densities across architectures and datasets for ten-episode fine-tuning.
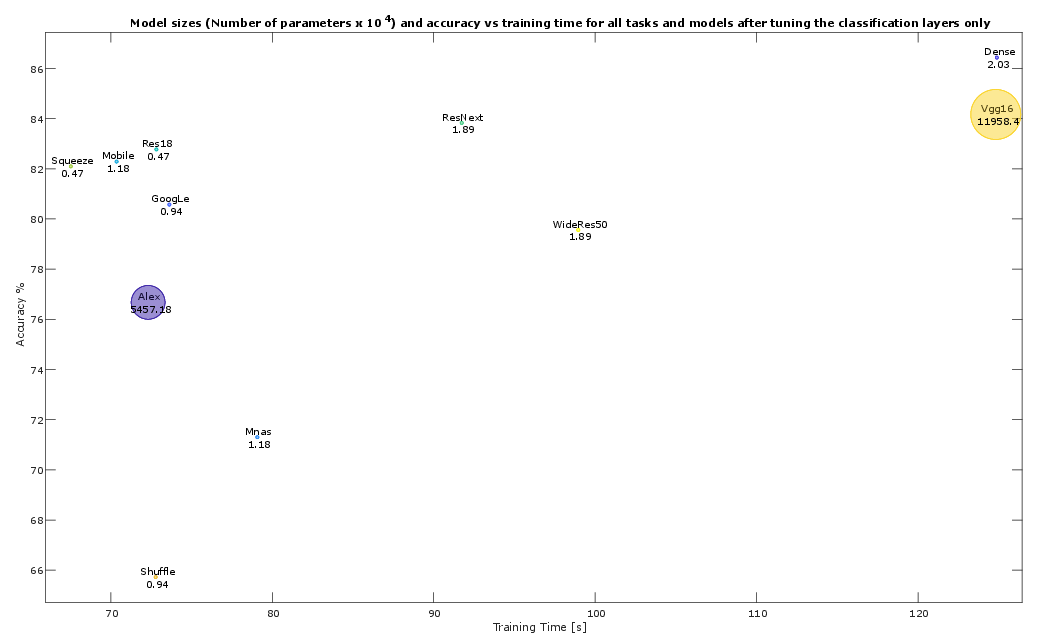
Figure 9: Model sizes and accuracy vs. training time for all tasks after classifier-only fine-tuning—parameter-efficient models are evident.
Model and dataset-specific scatter plots further contextualize these tradeoffs:
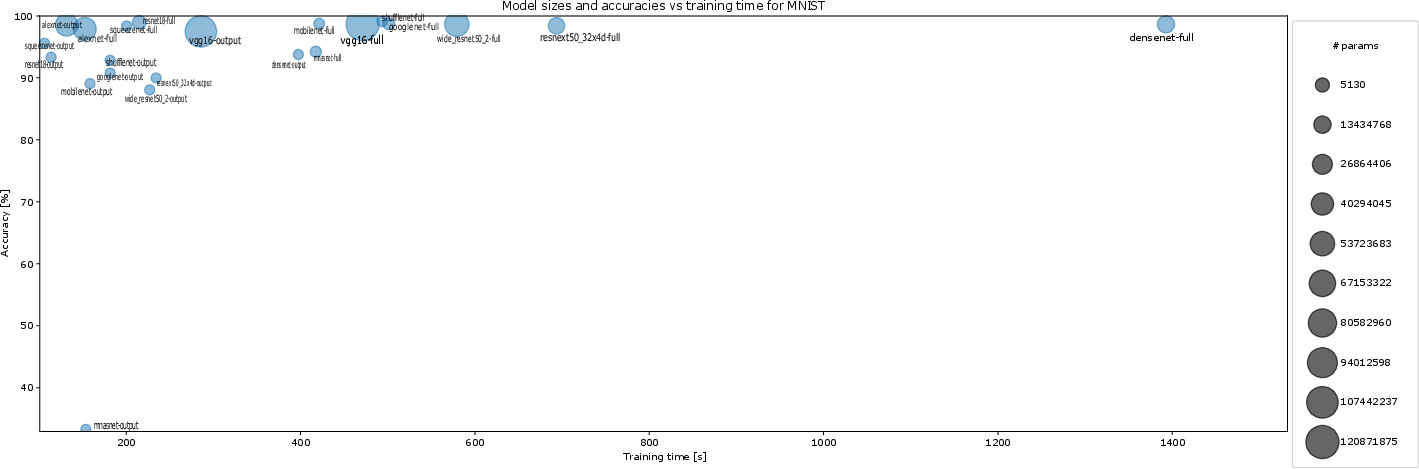
Figure 10: Accuracy, training time, and model size for MNIST under ten-episode training, indicating scale and efficiency clusters among architectures.
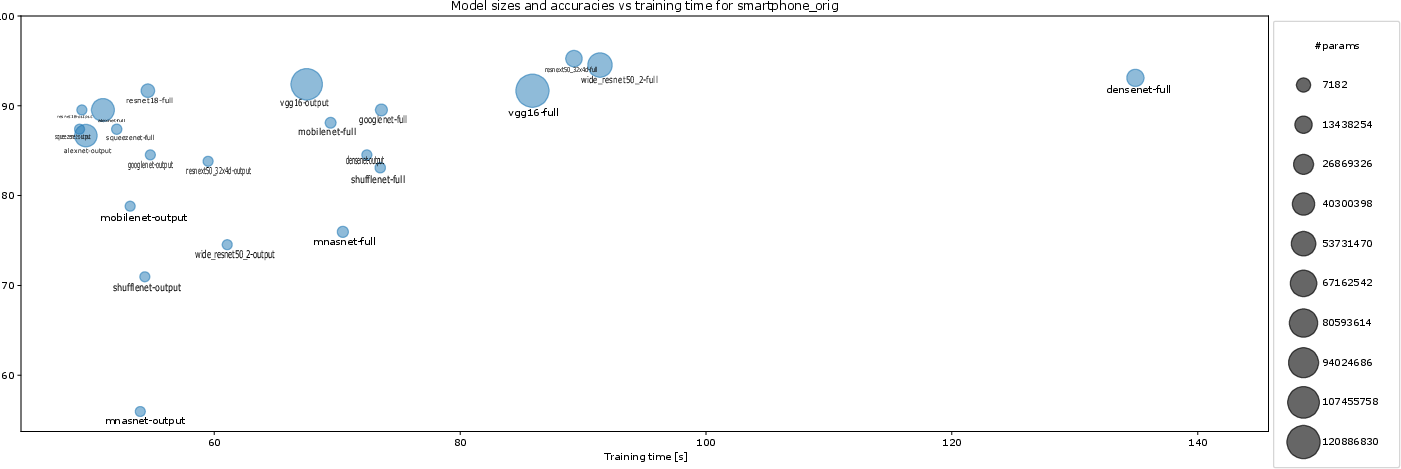
Figure 11: Tradeoffs for original smartphone data; compact models preserve real-time and deployment feasibility.
Cross-Task and Deployment Implications
The empirical evidence substantiates that optimal model choice is inherently context-dependent:
- For high-accuracy requirements, GoogLeNet, DenseNet, ShuffleNet-V2, ResNet-18, and ResNext are consistently top-tier, especially with adequate computational budget.
- Accuracy density maximization—an imperative for resource-constrained environments—favors SqueezeNet (full-tuning) and ResNet-18 (classifier-only).
- Training time minimization is dominantly achieved by AlexNet.
- For small model size (suitable for embedded/microcontroller deployment), SqueezeNet, ShuffleNet-V2, MobileNet, MnasNet, and GoogLeNet provide compactness with reasonable accuracy.
VGG-16 stands out as the least hardware-efficient model due to its large parameter count and relatively low accuracy density, thus unsuitable for deployment under memory or computation constraints despite acceptable absolute accuracy.
Theoretical and Practical Implications
These results challenge the prevailing practice of defaulting to highly over-parameterized models for transfer learning by systematically highlighting the efficiency–accuracy tradeoff. Architectural innovations like channel attentiveness (SqueezeNet), skip connections (ResNet-18/DenseNet/ResNext), and hardware-evolved design (MobileNet, ShuffleNet-V2, MnasNet) yield empirically distinct adaptation characteristics under diverse data regimes and target tasks.
The report also elucidates that, in practice, fine-tuning only the classification layer can deliver competitive accuracy density at drastically reduced training cost and negligible risk of overfitting, especially for datasets with limited labels. Full-network tuning confers additional marginal benefits only in high-data or high-bias settings, and its resource demands are often unjustified for incremental improvements. These nuances are critical for deployment in real-world settings where resources, latency, or memory footprint are operational bottlenecks.
Future Directions
To further refine transfer learning model selection, the authors acknowledge the need to expand evaluation to incorporate additional metrics such as robustness to domain shift, out-of-distribution generalization, and hardware-specific benchmarks. Automated meta-learning approaches leveraging both a priori (architecture/data statistics) and a posteriori (empirical adaptation curves) metadata are promising for algorithmic selection and hyperparameter tuning.
There is also substantial opportunity to investigate transferability bottlenecks for non-ImageNet domains, particularly those with domain-mismatched representations or limited task-relatedness, including non-RGB modalities and highly imbalanced class distributions.
Conclusion
This comprehensive benchmarking study clarifies the nuanced landscape of transfer learning model selection for image classification, revealing that:
- No single architecture is universally optimal across tasks, metrics, and resource constraints.
- SqueezeNet and ResNet-18 offer exceptional parameter efficiency, challenging the dominance of larger models.
- Deployment-oriented considerations (accuracy density, model size, and adaptation time) must be weighted alongside absolute accuracy to maximize practical utility.
- The choice of fine-tuning protocol—classifier-only versus full network—should be dictated by target data regime and application constraints.
This evidence-guided framework is valuable for both research and industrial practitioners, sharpening transfer learning model selection, and deployment strategy in diverse applied computer vision settings.
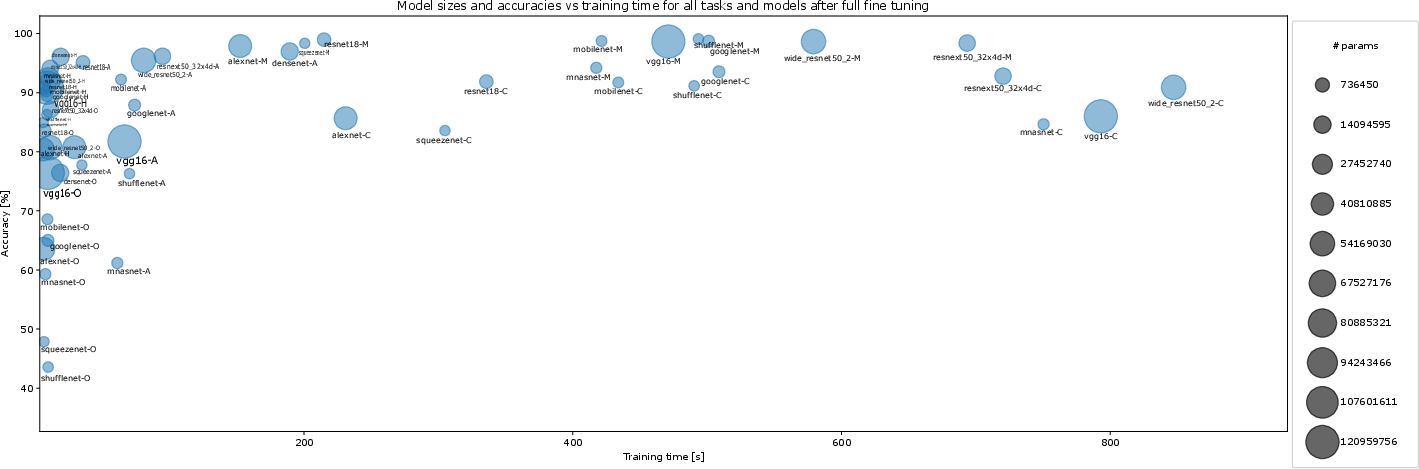
Figure 12: Holistic overview of model sizes, accuracy, and training time across all datasets and architectures following full fine-tuning, providing a global summary of efficiency trade-offs.


