- The paper introduces an optimal transport-based method for training-free token compression that preserves semantically crucial evidence in Video-LLMs.
- It employs saliency-weighted spatial pruning and adaptive per-pair budget allocation to balance aggressive compression with token importance.
- Experimental results show up to 10% token retention with minimal performance loss and a 2× inference speedup on challenging video tasks.
Optimal Transport Temporal Token Compression for Video-LLMs: An Expert Analysis of "OTT-Vid" (2605.11803)
Introduction and Motivation
As Video LLMs (Video-LLMs) advance towards understanding increasingly complex and longer video sequences, the computational inefficiency induced by the burgeoning volume of visual tokens becomes a practical bottleneck during inference. While training-free token compression offers a path to efficiency without retraining, existing temporal token compression pipelines predominantly rely on either cross-frame token similarity or heuristic segmentation criteria. These approaches neglect intra-frame semantic roles and fail to dynamically adapt compression based on the unique temporal redundancy profile of individual frame pairs, resulting in suboptimal preservation of temporally-persistent, semantically important evidence.
"OTT-Vid: Optimal Transport Temporal Token Compression for Video LLMs" introduces a transport-based allocation framework that addresses these critical limitations in training-free token compression by formulating the temporal compression process as an optimal transport (OT) allocation problem. This approach simultaneously captures token importance and cross-frame compressibility to drive aggressive yet semantically faithful visual token reduction for Video-LLMs.
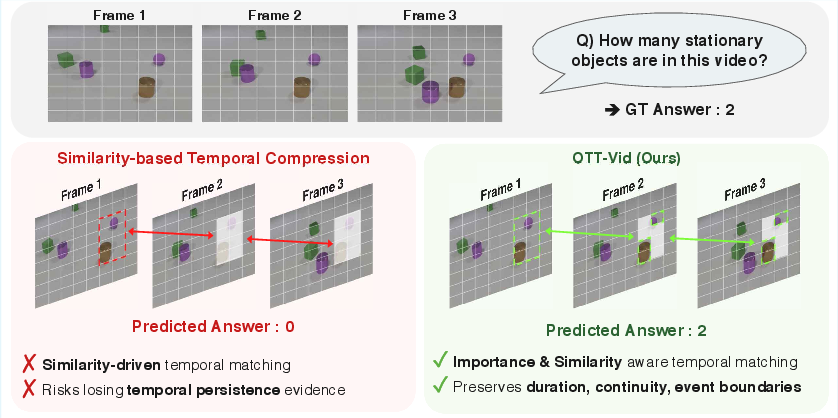
Figure 1: OTT-Vid's approach preserves stationary object tokens—semantically critical but highly similar across frames—by considering both token importance and similarity, whereas similarity-driven methods risk eliminating essential temporal evidence.
Methodology
System Overview
OTT-Vid operates through a two-stage pipeline for token compression:
- Spatial Pruning and Mass Assignment: Each video frame is independently compressed by selecting tokens that maximize saliency-weighted coverage, guaranteeing both semantic representativeness and spatial diversity. Token masses, reflecting preservation priority, are inversely assigned based on their leave-one-out semantic contribution.
- Temporal Compression via Optimal Transport: For each adjacent frame pair, an entropically regularized OT problem is solved. Here, the row/column marginals encode token importance via non-uniform mass, while the OT cost is a blend of semantic feature dissimilarity and spatial distance—balanced adaptively based on inter-frame similarity statistics. The solution yields a transport plan ranking token correspondences for potential compression and quantifies overall frame-pair compressibility (transport difficulty).
- Adaptive Budget Allocation and Compression Execution: A global compression budget is distributed non-uniformly across frame pairs according to each pair's transport difficulty, with highly redundant pairs receiving larger budgets. Token merging or pruning is then performed by ranking OT plan entries, further constrained to avoid semantically unreliable merges (via cost thresholding and dynamic execution).
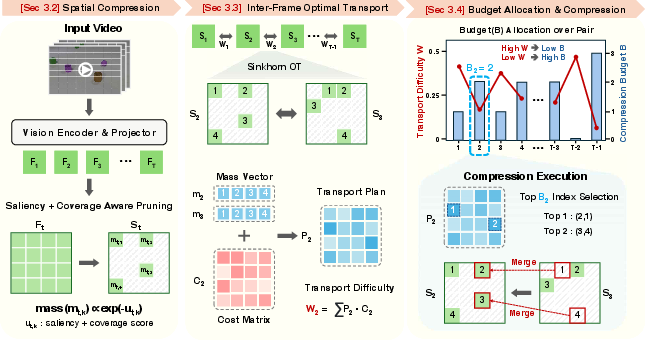
Figure 2: Comprehensive overview of OTT-Vid, depicting independent spatial pruning with importance-aware mass assignment, OT-based cross-frame coupling, and dynamic per-pair budget allocation for compression.
Key methodological contributions include:
- Saliency-weighted Representative Token Selection: Unlike prior approaches that separate representativeness or importance, OTT-Vid employs a coverage gain weighted by the saliency of covered (not candidate) tokens for subset selection.
- Importance-aware OT Marginals: In contrast to uniform-mass OT, the marginal mass for each token is inversely proportional to its leave-one-out representational loss, resulting in OT solutions preserving core evidence against aggressive compression.
- Locality-Adaptive OT Cost: By dynamically mixing semantic and spatial distances based on estimated framewise motion, OTT-Vid avoids both improper merging of unrelated tokens in dynamic shots and over-restriction in static views.
- Softmax-adaptive Per-pair Budgeting: Compression operations are allocated using a negative softmax over transport difficulties, achieving global budget consistency and targeted redundancy removal.

Figure 3: Visualization of compressed tokens—uniform-mass approaches discard semantically critical regions (e.g., hand and object), while OTT-Vid's importance-aware mass better preserves these regions at high compression ratios.
Experimental Results
Comparative Evaluation
OTT-Vid was rigorously evaluated on six challenging benchmarks (four VQA, two VTG) with three diverse Video-LLM backbones (Qwen2.5-VL-7B, LLaVA-OneVision-7B, LLaVA-Video-7B). At an aggressive 10% token retention ratio, OTT-Vid retains 95.8% of VQA and 73.9% of VTG performance on Qwen2.5-VL-7B—exceeding state-of-the-art baselines by 1–7.3 percentage points, with the largest gains in temporal grounding where prior similarity-driven methods underperform due to loss of temporal evidence.
Ablation Studies
Key ablation findings:
- Importance-aware mass alone yields a 9.1 percentage-point improvement in VTG retention over uniform mass, verifying that cross-frame similarity is insufficient for temporal evidence preservation.
- Budget adaptation produces positive gains, especially in benchmarks where temporal compressibility is highly non-uniform.
Efficiency Analysis
OTT-Vid achieves a 2.0× total inference time speedup at 10% token retention, with competitive peak memory (18.22 GB) and TFLOP usage (∼26). The overhead of the OT-based compression is modest compared to reductions in LLM compute demand, reaffirming its practicality for real-world long-context video reasoning.
Qualitative Insights
Visualizations confirm that importance-aware mass selectively retains tokens tracking temporally diagnostic events (e.g., hands, manipulated objects), while uniform-mass or similarity-driven methods indiscriminately eliminate evidence, resulting in incorrect model predictions.
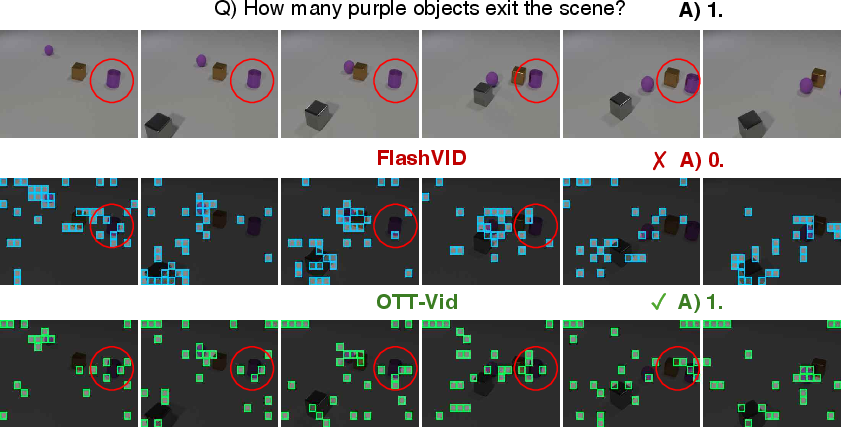
Figure 4: OTT-Vid versus similarity-driven methods on MVBench at 10% retention; OTT-Vid reliably retains question-relevant regions (red circles) throughout the sequence.

Figure 5: Action localization on ActivityNet-TimeLens shows OTT-Vid preserving hand and tool tokens over the action's timespan, matching ground-truth localization more accurately.
Analysis and Implications
Theoretical and Practical Impact
OTT-Vid's framework establishes a new paradigm wherein token-level compressibility and global budget allocation are unified via OT, with importance-aware constraints ensuring semantically faithful compression. Its performance, especially in preserving fine-grained event boundaries during high-ratio compression, indicates that naive similarity-driven redundancy removal is fundamentally inadequate for temporal reasoning tasks.
OTT-Vid's design is modular: alternative spatial pruning strategies can be integrated without sacrificing the advantages of transport-based temporal compression. The underlying OT toolkit might generalize well to other efficiency-sensitive multimodal tasks where long-context processing is required.
Limitations and Future Directions
One limitation is that OT problems for all frame pairs are solved in parallel from initial pruned representations; thus, iterative propagation of representational changes across compression steps is omitted. Sequential OT updates could further enhance fidelity at the cost of computational expense—a promising avenue for future research.
Moreover, while OTT-Vid is grounded in static hyperparameters, dynamic adaptation based on task- or content-aware criteria (e.g., utilizing cross-modal query information) could further optimize token selection. Integrating trainable modules atop the OT allocation could bridge to hybrid, partially-trainable compression regimes.
Conclusion
OTT-Vid delivers a principled and highly effective framework for training-free video token compression in Video-LLMs. By leveraging optimal transport with importance-aware mass, locality-adaptive costs, and budget-aware allocation, it achieves superior semantic preservation at extreme compression ratios, maintains practical inference efficiency, and addresses key shortcomings of prior heuristic and similarity-driven schemes. OTT-Vid's insights on token prioritization and transport allocation will likely inform subsequent advances in scalable, efficient video-language modeling.