CoPE-VideoLM: Codec Primitives For Efficient Video Language Models
Abstract: Video LLMs (VideoLMs) empower AI systems to understand temporal dynamics in videos. To fit to the maximum context window constraint, current methods use keyframe sampling which can miss both macro-level events and micro-level details due to the sparse temporal coverage. Furthermore, processing full images and their tokens for each frame incurs substantial computational overhead. To address these limitations, we propose to leverage video codec primitives (specifically motion vectors and residuals) which natively encode video redundancy and sparsity without requiring expensive full-image encoding for most frames. To this end, we introduce lightweight transformer-based encoders that aggregate codec primitives and align their representations with image encoder embeddings through a pre-training strategy that accelerates convergence during end-to-end fine-tuning. Our approach reduces the time-to-first-token by up to $86\%$ and token usage by up to $93\%$ compared to standard VideoLMs. Moreover, by varying the keyframe and codec primitive densities we are able to maintain or exceed performance on $14$ diverse video understanding benchmarks spanning general question answering, temporal reasoning, long-form understanding, and spatial scene understanding.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
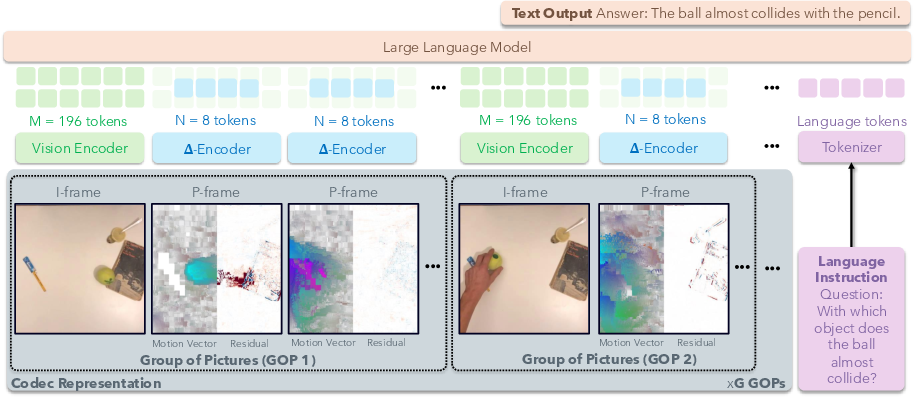
This paper is about making AI systems that “watch” and understand videos faster and more efficient. Today’s video-LLMs (VideoLMs) usually pick a few key frames from a video and treat each one like a full image. That can miss important moments and uses a lot of compute. The authors propose a smarter way: instead of re-processing full images for every frame, use the video’s built‑in compression signals—motion vectors and residuals—to encode only what changed. This cuts the number of visual tokens the model needs and speeds up how quickly it starts answering.
What are the main goals?
Here are the goals in simple terms:
- Reduce wasted work by not re-reading the whole picture every frame—only read the “changes.”
- Keep good understanding of both big events and small details across time.
- Make the model respond faster while using fewer tokens, so it can handle longer videos within the same limits.
How did they do it?
Think of a video like a flipbook:
- Some pages are “full pictures” (I-frames).
- Most pages are “difference pages” (P-frames) that say “move this here” and “add a tiny detail there.”
Video codecs (the rules that compress videos) already store this in two parts:
- Motion vectors: tiny arrows showing how blocks of pixels moved between frames.
- Residuals: small touch-ups that fix what motion didn’t capture.
Instead of turning every frame into a full image, the model does this:
- It processes I-frames as usual with a vision encoder (these are the full pictures).
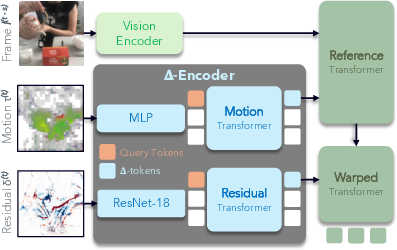
- It converts P-frames into compact “delta tokens” using two lightweight branches:
- One branch reads motion vectors (the arrows).
- Another reads residuals (the touch-ups).
- These branches are transformer-based, which means they use attention to focus on the most important bits, kind of like how you skim a page and look for bold words or highlights.
Because the model now understands “difference frames,” it can interleave I-frame tokens (full pictures) with delta tokens (changes) in order, like: full pic → changes → changes → full pic → changes, and so on. This keeps the story of the video intact while using fewer tokens.
A key step is pre-training: the team trains the delta encoders so their output “speaks the same language” as regular image features. They do this by teaching delta tokens to match what the vision encoder would produce for the next full frame. That alignment helps the whole system learn faster when fine-tuning end-to-end.
They also add a practical trick called P-frame fusion: they can group the changes from several frames together (for example, combine 30 frames’ changes into one delta) to trade fine detail for efficiency when you don’t need every moment at full granularity.
What did they find, and why does it matter?
The key results are:
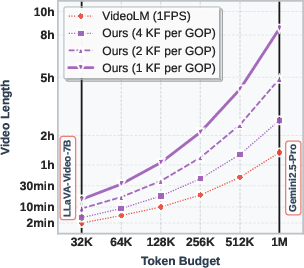
- Up to 93% fewer visual tokens used compared to standard ways that encode every frame as a full image.
- Up to 86% faster time-to-first-token (TTFT), meaning the model starts replying much sooner.
- Performance that matches or beats strong open-source models on 14 different video understanding tests, including general question answering, temporal reasoning, long videos, and 3D scene understanding.
Why this matters:
- Fewer tokens mean the model can “watch” longer videos without hitting its context limit.
- Faster “first answer” is better for user experience and critical for real-time uses like robotics.
- Using codec primitives leverages information that video files already have, so we don’t waste compute re-decoding everything.
What’s the big picture and impact?
By using motion vectors and residuals—the video’s own built-in “what changed” notes—this approach makes video AI:
- More efficient: less redundant processing and fewer tokens.
- More scalable: can handle longer videos within the same context window.
- More responsive: starts answering faster, which is useful for live assistance, streaming, or robot control.
- More practical: works with existing video standards and fits into current VideoLM pipelines with minimal changes.
In short, it’s a smarter way to watch videos: pay full attention only when you need a full picture, and otherwise focus on the changes. This could help future AI systems understand longer, more complex videos in real time, all while using fewer resources.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or left unexplored in the paper, phrased to enable concrete follow-up work:
- Lack of support for B-frames and bidirectional prediction: How to incorporate B-frame primitives (bidirectional motion vectors, dual residuals) in a causal VideoLM while preserving decode order, temporal consistency, and efficiency.
- Codec generalization beyond MPEG-4: Robustness across H.264/AVC, HEVC/H.265, AV1, and VP9, including variable GOP structures, reference lists, quarter-/sub-pixel motion, variable macroblock partitions, CABAC/CAVLC entropy modes, and encoder-specific nuances.
- Dependence on re-encoding: The pipeline re-encodes all videos to MPEG-4 (30 FPS, GOP=240), which may distort original codec statistics. How does performance change when using native source codecs and bitstreams without transcoding.
- Sensitivity to compression level and bitrate: Systematic evaluation of how different quantization parameters (QP), bitrates, and encoder profiles affect motion-vector/residual fidelity and downstream accuracy.
- P-frame fusion mechanics are underspecified: Precise algorithms for composing motion vectors and residuals across s fused P-frames (e.g., reference consistency, residual accumulation, handling multi-reference lists), quantitative error bounds, and drift analysis.
- Adaptive selection of fusion span s: A learned or content-adaptive policy for choosing s per segment (e.g., based on motion magnitude, scene cuts, residual sparsity) to balance token budget and temporal fidelity.
- Token allocation is static: Replace fixed Kτ=Kδ=4 with content-adaptive token budgets (e.g., gating/importance sampling based on residual/motion energy), and evaluate the accuracy–efficiency Pareto curve under dynamic tokenization.
- Architecture ablations are missing in main text: Sensitivity to Δ-encoder design choices (MLP depth, ResNet backbone size, transformer width/depth, grid resolution HG×WG), and comparisons to alternative designs (e.g., deformable attention, optical-flow-informed transformers).
- Pre-training objective design: Patch-wise MSE alignment to SigLIP tokens may under-capture semantics. Compare against contrastive, masked modeling, or teacher-distillation objectives; test robustness to domain shift; and quantify the stated “accelerates convergence” claim (speed, sample efficiency).
- Encoder interoperability: How well does the Δ-encoder transfer across different vision encoders (e.g., CLIP, EVA, InternVL) and LLM backbones; what calibration/adapter changes are required to maintain alignment.
- Removal of reference/warped branches at fine-tuning: Investigate whether retaining cross-attention to prior I-frame tokens (or a lightweight memory module) at inference improves temporal consistency and reduces error propagation.
- Positional and structural signaling: The LLM receives interleaved tokens without explicit markers for frame type, timestamps, or fusion span. Evaluate whether special tokens, temporal positional encodings, or segment boundaries improve reasoning.
- Error accumulation and drift over long sequences: Analyze failure modes where large camera motion, occlusions, or scene cuts break codec assumptions; quantify drift and investigate periodic re-synchronization strategies beyond I-frames.
- Handling variable frame rates and resolutions: Extend Δ-encoder to videos with changing FPS, resolution, aspect ratio, or dynamic scaling/cropping; assess performance and propose normalization or multi-scale handling.
- Real-time, streaming integration: Measure end-to-end latency including codec primitive extraction (NVDEC/VAAPI hardware decode), CPU/GPU data transfer, and batching; provide a breakdown of TTFT contributors and optimizations for robotics.
- Scalability beyond 7B and to long contexts in practice: Demonstrate actual end-to-end processing with 1M-token contexts (not just theoretical plots), including memory footprints, throughput, and accuracy at hour-scale inputs on real hardware.
- Benchmark coverage gaps: Provide detailed results and analysis for spatial scene understanding (ScanQA, SQA3D) referenced only in Supplement, and expand evaluation on tasks that stress fine-grained spatial detail under aggressive compression.
- Training data scale and modality: Quantify how reduced training corpus impacts specific benchmarks; study whether compressed-domain pre-training at larger scale (without RGB decoding) closes gaps on MVBench and other appearance-heavy datasets.
- Robustness to encoder noise and artifacts: Evaluate under packet loss, variable quantization across frames, and encoder artifacts common in low-bitrate streams; propose denoising or confidence-weighted tokenization strategies.
- Scene cut and shot boundary handling: Develop automatic detection and policies for reinitializing Δ-encoder state at cuts or transitions to avoid misaligned motion/residual tokens.
- Integration with audio and subtitles: Explore codec-aware multimodal fusion (audio codec primitives, subtitle timing) to improve instruction-following and long-form comprehension.
- Token- and compute-aware scheduling: Investigate curriculum or scheduling (e.g., prioritizing tokens from salient segments) to optimize TTFT and accuracy under strict budgets.
- Downstream tasks beyond QA: Validate benefits for video retrieval, action recognition, and tracking where compressed-domain signals are historically effective; compare against raw-domain baselines.
- Reproducibility and practical deployment: Provide implementation details for extracting motion vectors/residuals across common libraries (FFmpeg, PyAV) and hardware decoders, including edge cases (variable GOP, multi-ref) and failure handling.
Practical Applications
Immediate Applications
The following applications can be deployed today by leveraging CoPE-VideoLM’s codec-aware tokenization (motion vectors + residuals), the lightweight Δ-encoder, and the demonstrated runtime gains (up to 86% lower TTFT and up to 93% fewer visual tokens) without modifying downstream LLM architectures.
- Real-time content moderation and compliance scanning [Sector: Media/Platforms]
- What: Monitor livestreams and VOD for nudity/violence, copyright misuse, brand safety, and regulatory violations in near real time with lower latency and compute.
- Tools/Workflows: Integrate CoPE-VideoLM into ingestion pipelines; use FFmpeg/NVDEC to extract codec primitives; stream compact Δ-tokens to a VideoLM for continuous QA.
- Assumptions/Dependencies: Access to motion vectors and residuals from H.264/AVC/MP4 streams; P-frame fusion tuned to latency/recall targets; domain-specific instruction tuning to reduce false positives.
- Scalable video indexing and semantic search for archives [Sector: Media/Enterprise]
- What: Rapidly index and semantically tag long-form libraries (news, documentaries, training videos) and enable natural language search over hours of content within fixed token budgets.
- Tools/Workflows: Batch processing pipeline that fuses P-frames (e.g., 1 FPS) to Δ-tokens; build a vector store keyed by interleaved I/Δ token embeddings; query via MLLM.
- Assumptions/Dependencies: Stable GOP structure; variability in codec settings (bitrate/GOP size) affects MV/residual quality; may require domain finetuning for specialized corpora.
- Sports highlight detection and broadcast operations [Sector: Media/Sports]
- What: Live play detection, event tagging, auto-clip extraction, ad slot validation, and captioning with reduced latency and compute.
- Tools/Workflows: Ingest broadcast feeds; Δ-tokenize P-frames between sparse keyframes; run event detectors or QA prompts; push highlights to production tools.
- Assumptions/Dependencies: Access to production-grade streams (often H.264/H.265); model prompts or small task-specific heads for sport-specific events; human-in-loop for broadcast quality.
- Surveillance analytics and anomaly triage at the edge [Sector: Security/Public Safety]
- What: Multi-camera summarization, anomaly detection (loitering, intrusion), and retrospective query (“show all times a person dropped a bag”) with constrained compute on NVRs.
- Tools/Workflows: NVR plugin that extracts codec primitives directly from the hardware decoder; Δ-encoder + VideoLM for long-context understanding and alerting; daily digests.
- Assumptions/Dependencies: Hardware/driver support to expose MV/residuals (varies by vendor); privacy/compliance review; robustness to variable frame rates and re-encoding artifacts.
- Faster perception pipelines for teleoperation and instruction following [Sector: Robotics]
- What: Reduced TTFT for video-language-action agents; quicker grounding of visual queries and step feedback in human-in-the-loop setups.
- Tools/Workflows: Replace dense RGB tokenization with CoPE-VideoLM in VLA stacks (e.g., LLaVA-Video-based); adjust P-frame fusion to meet responsiveness and fidelity needs.
- Assumptions/Dependencies: Onboard or nearby compute with access to codec primitives; real-time constraints may limit fusion window; safety guardrails for action issuance.
- Meeting and lecture summarization, topic indexing, and Q&A [Sector: Enterprise/Education]
- What: Summarize multi-hour meetings/lectures, extract decisions/action items, support post-hoc Q&A with long-context coverage at low cost.
- Tools/Workflows: Recordings Δ-tokenized at 1 FPS; combine with ASR transcripts; build a timeline-indexed memory for retrieval-augmented response.
- Assumptions/Dependencies: Quality of screen capture/webcam encoding affects MV/residual signal; multi-modal fusion (audio/subtitles) boosts accuracy.
- Retail floor monitoring and planogram/compliance checks [Sector: Retail]
- What: Detect shelf out-of-stock, queue length, safety compliance using store cameras with constrained compute bandwidth.
- Tools/Workflows: On-prem VMS integration; Δ-token processing for continuous monitoring; rule- and LLM-based queries and periodic reports.
- Assumptions/Dependencies: Lighting and camera placement affect residual quality; domain prompts/finetuning recommended.
- Captioning and accessibility at scale [Sector: Media/Public Sector]
- What: Generate captions, key moments, and audio-described summaries for large backlogs of videos with reduced GPU hours and energy costs.
- Tools/Workflows: Batch Δ-token pipelines + multilingual MLLMs; integrate with CMS for accessibility compliance.
- Assumptions/Dependencies: For high accuracy and localization, combine with ASR and subtitle alignment; policy-compliant data handling for public content.
- Developer SDKs and MLOps integration for compressed-domain video AI [Sector: Software]
- What: Provide libraries to extract MVs/residuals (FFmpeg bindings), Δ-encoder modules (PyTorch), and drop-in adapters for popular VideoLMs.
- Tools/Workflows: “CoPE-VideoLM SDK”—data loaders, token budget planners, GOP-aware samplers, evaluation harnesses; exporters for Triton/ONNX.
- Assumptions/Dependencies: Maintenance across codecs (H.264/H.265/VP9/AV1) and hardware decoders; licensing constraints for certain codec stacks.
- Personal video library and home-camera assistant [Sector: Consumer/Daily Life]
- What: Local summarization and search for dashcam/bodycam/home security footage (e.g., “when did the delivery arrive?”) with reduced cloud dependence.
- Tools/Workflows: Lightweight Δ-tokenizer on NAS/NVR; nightly summarization and keyword indexing; privacy-preserving local queries.
- Assumptions/Dependencies: Consumer devices’ ability to expose codec primitives; storage and compute constraints; user consent/privacy settings.
Long-Term Applications
These opportunities require further R&D, scaling, or ecosystem maturation (e.g., B-frame support, hardware exposure of codec primitives, larger-context LLMs, regulatory validation).
- Bi-directional, B-frame-aware video reasoning for offline analysis [Sector: Software/Media]
- What: Higher-fidelity understanding by leveraging B-frames and decode-order modeling for non-causal tasks (editing, forensics).
- Tools/Workflows: Extend Δ-encoder to bi-directional primitives; train with decode-order sequences; new alignment objectives.
- Assumptions/Dependencies: Architectural changes for non-causal context; broader codec support; careful handling of display vs. decode order.
- City-scale multi-camera, long-horizon situational awareness [Sector: Public Safety/Transportation]
- What: Joint reasoning across many streams (traffic patterns, incident timelines) with token-efficient, synchronized Δ-token fusion.
- Tools/Workflows: Federated Δ-token aggregation; spatio-temporal graph fusion across cameras; long-context VideoLM backends (>1M tokens).
- Assumptions/Dependencies: Cross-stream time-sync and calibration; privacy-by-design deployments; compute orchestration and bandwidth planning.
- Surgical and clinical video assistants [Sector: Healthcare]
- What: OR/endoscopy workflow summarization, step recognition, safety checklists, and post-op analytics over long procedures.
- Tools/Workflows: Δ-token pipelines validated for clinical video; integration with EHRs and PACS; visual QA prompts with domain ontologies.
- Assumptions/Dependencies: Rigorous clinical validation; HIPAA/GDPR compliance; robustness to hospital-specific encoding and equipment.
- Driver monitoring and explainable ADAS event logs [Sector: Automotive]
- What: Long-duration cabin/road video analysis with causal explanations of detected events; bandwidth-efficient fleet analytics.
- Tools/Workflows: On-vehicle Δ-token extraction; post-hoc cloud summarization and querying of incidents; safety case generation.
- Assumptions/Dependencies: Automotive-grade hardware; certification for safety-critical systems; environmental robustness.
- Compressed-domain perception for autonomous robots [Sector: Robotics]
- What: Onboard, low-power video understanding and memory over extended missions (drones, AMRs) using Δ-tokens end-to-end.
- Tools/Workflows: Joint training of VLA with Δ-encoder; event-triggered P-frame fusion policies; on-device deployment with NPU offload.
- Assumptions/Dependencies: Hardware acceleration for Δ-encoder; robust operation across codecs, bitrates, and motion regimes.
- Conversational “video memory” agents for enterprises [Sector: Enterprise/Knowledge Management]
- What: Agents that “watch” hours/days of operational videos (manufacturing, support, field ops) and answer ad hoc queries with time-stamped evidence.
- Tools/Workflows: Continuous ingestion into long-context memories; RAG over I/Δ-token indices; governance and access controls.
- Assumptions/Dependencies: Stable long-context LLMs; storage/retention policies; data governance and provenance tracking.
- Hardware IP and standards to expose codec primitives for ML [Sector: Semiconductors/Standards]
- What: NVDEC/QSV/VA-API extensions and NPU blocks to surface/accelerate MV/residual extraction and Δ-encoding directly on-chip.
- Tools/Workflows: Co-design of decoder–Δ-encoder pipelines; SDK standardization; benchmarks for energy savings.
- Assumptions/Dependencies: Vendor adoption; standardization bodies (DASH/HLS/MPEG) alignment; IP/licensing considerations.
- Education: personalized tutors that “watch” lectures/labs [Sector: Education]
- What: Personalized Q&A, quizzes, and study guides grounded in long video sessions (labs, clinics, workshops) with temporal references.
- Tools/Workflows: Δ-token ingestion + ASR + slide OCR; learner model integration; analytics dashboards for educators.
- Assumptions/Dependencies: Pedagogical validation; privacy and consent in classroom recordings; equitable access across institutions.
- Legal/compliance e-discovery in video [Sector: Legal/Compliance]
- What: Efficient triage and timeline construction from vast CCTV/bodycam datasets for investigations and litigation.
- Tools/Workflows: Secure Δ-token processing; auditable chains-of-custody; timeline and evidence extraction tools.
- Assumptions/Dependencies: Judicial acceptance of compressed-domain analysis; stringent privacy controls; domain-specific finetuning.
- Multi-modal fusion over video/audio/subtitles with Δ-tokens [Sector: Search/Assistive Tech]
- What: Robust retrieval and QA by combining Δ-tokens with ASR/subtitles for better understanding of dialogue-driven content.
- Tools/Workflows: Cross-modal alignment and late-fusion architectures; temporal grounding across modalities.
- Assumptions/Dependencies: High-quality ASR; time alignment; additional training to resolve cross-modal conflicts.
- Generative video assistants for auto-editing and storytelling [Sector: Creative Tools/Media]
- What: Agents that select cuts, generate beat-aligned edits, and propose narratives from raw footage, guided by compact temporal understanding.
- Tools/Workflows: Δ-token-informed planning + generative editing models; user-in-the-loop interfaces.
- Assumptions/Dependencies: Reliable high-level temporal comprehension; IP/rights management; user safety and editorial control.
Notes on Feasibility and Cross-Cutting Dependencies
- Codec access: Feasible when MV/residuals are exposed by decoders (FFmpeg, hardware APIs). DRM/encrypted streams may restrict access.
- Codec variability: Performance depends on GOP size, bitrate, and motion estimation quality. Domain calibration or finetuning may be needed.
- Current scope: Method targets I-/P-frames and causal processing; B-frame support is a future extension for offline/bidirectional tasks.
- Context limits: Open-source LLMs typically have shorter context windows than proprietary models; Δ-tokens mitigate but don’t eliminate this constraint.
- Hardware: Latency/throughput gains are measured on high-end GPUs; edge devices need decoder/NPU support for best results.
- Safety/regulation: Healthcare/automotive/public-safety uses require rigorous validation, monitoring, and compliance processes.
Glossary
- Adapter: A module that aligns vision features to the LLM’s embedding space for multimodal fusion. "a modality alignment mechanism also known as adapter (e.g., linear projection, Q-Former~\cite{zhang2022vsa,zhang2023vision}, or gated cross-attention~\cite{flamingo})"
- Attention-based token compression: Methods that use attention signals to reduce visual tokens by pruning low-importance ones. "Attention-based token compression methods~\cite{fastv,fu2024framefusion,Xing2024PyramidDropAY,zhang2024sparsevlm} leverage the inherent sparsity of visual feature attention~\cite{shao2025tokens} to guide token pruning."
- B-frame: A codec frame predicted from both past and future frames to maximize compression. "A B-frame leverages both preceding and subsequent frames to encode its differences."
- Bi-directional predictive: A prediction mode where a frame is encoded using both preceding and subsequent frames. "B-frame~(bi-directional predictive)"
- Causal processing: Processing that depends only on past inputs, aligning with autoregressive models. "align naturally with the causal processing required by VideoLMs."
- Codec primitives: Fundamental compressed-video elements (motion vectors and residuals) that encode changes efficiently. "video codec primitives (specifically motion vectors and residuals)"
- Context window: The maximum sequence length a model can take as input. "VideoLMs have a maximum context window limiting the amount of information that can be provided as input."
- Delta tokens (-tokens): Compact tokens representing P-frame changes derived from motion vectors and residuals. "compact -tokens (delta for difference) obtained from motion vectors and residuals"
- Distillation-based approaches: Training techniques where a student model learns from a teacher’s outputs to transfer knowledge. "Distillation-based approaches~\cite{havasi2021training,compressedteacher} further align compressed-domain models with raw-domain teachers, but still require access to decoded RGB frames during training, reducing efficiency gains."
- End-to-End Latency (E2EL): Total time from input to the final generated output. "We report the Time-to-First-Token (TTFT) and End-to-End Latency (E2EL) for generating $64$ text tokens"
- Gated cross-attention: A cross-attention mechanism with gating to regulate information flow between modalities. "gated cross-attention~\cite{flamingo}"
- Group of Pictures (GOP): A codec sequence unit containing an I-frame and subsequent predictive frames. "Group of Pictures~(GOP)"
- I-frame: An intra-coded frame encoded independently, serving as a reference in a GOP. "An I-frame, , is an RGB image encoded independently without the use of preceding or subsequent frames."
- Instruction tuning: Fine-tuning on instruction–response data to improve model alignment and usability. "standard instruction tuning next-token prediction loss"
- LLM backbone: The LLM component handling decoding and reasoning over tokens. "an LLM backbone (e.g., LLaMA~\cite{llama}, Vicuna~\cite{vicuna}, or Qwen~\cite{Qwen-VL,Qwen2-VL,Qwen2.5-VL}) for multimodal decoding."
- Masked autoencoding: Self-supervised pretraining where masked inputs are reconstructed to learn robust representations. "introduces masked autoencoding pre-training in the compressed domain"
- Modality adapter: A module that makes features from one modality compatible with another’s embedding space. "We pre-train the -Encoder as a modality adapter that enables codec-derived primitives to be compatible with the embedding space defined by a vision encoder."
- Motion vectors: Block-wise displacement fields representing inter-frame motion. "Motion vectors , which describe block-wise displacements from the reference to the target frame, resembling coarse optical flow."
- Optical flow: A dense field indicating apparent pixel motion across frames. "resembling coarse optical flow."
- P-frame: A predictive frame that encodes only changes relative to a previous reference frame. "A P-frame contains only the changes from the previous frame, be it a reference frame or some other P-frame ."
- Patch-wise regression: Regression performed at the patch/token level to align representations. "we apply patch-wise regression against the outputs of a frozen vision encoder."
- Perceiver Resampler: A module that compresses inputs into a fixed set of latent tokens using the Perceiver architecture. "Perceiver Resampler~\cite{yao2024minicpm}"
- Prefill time: The time to compute initial states before the first output token is produced. "prefill time~\cite{vasu2025fastvlm}, delaying the time-to-first token (TTFT) of the VideoLM."
- Q-Former: A query-based transformer module producing compact token representations. "Q-Former~\cite{zhang2022vsa,zhang2023vision}"
- Residuals: Block-wise pixel corrections remaining after motion compensation. "Residuals , which capture block-wise pixel corrections that remain after motion compensation."
- Self-attention: An attention mechanism where tokens attend to other tokens in the same sequence. "attempt to leverage self-attention across codec primitives"
- Token budget: The allotted number of tokens available within a model’s context window. "This allows the token budget to better scale with video duration, matching the natural growth of information content."
- Token pruning: Removing low-importance tokens to improve efficiency. "to guide token pruning."
- Time-to-first token (TTFT): Latency until the model emits its first output token. "time-to-first token (TTFT)"
- Vision encoder: A neural encoder that converts visual inputs into token embeddings. "a vision encoder (e.g., CLIP~\cite{clip} or SigLIP~\cite{siglip})"
- Warping: Transforming features according to motion to align them with a target frame. "This is akin to the warping in Eq.~\ref{eq:codec-eq}."
Collections
Sign up for free to add this paper to one or more collections.