- The paper demonstrates that digital personas, especially with retrieval-augmented architectures, can approximate aggregate survey distributions but fall short on individual-level accuracy.
- The study shows that methodological choices, including LLM selection and response conditioning, critically influence performance metrics like JSD and match rates.
- The research emphasizes the need for cautious application, as digital personas struggle to replicate high-variability, individualized survey responses effectively.
When Can Digital Personas Reliably Approximate Human Survey Findings?
Motivation and Problem Statement
LLMs are increasingly leveraged to generate "digital personas"—synthetic agents conditioned on human background variables and response histories—to substitute for or augment conventional survey respondents. This paradigm promises scalable, cost-efficient data collection for social science, pre-testing, and simulating various population subgroups. However, the central scientific question remains unresolved: when do digital personas faithfully preserve the empirical structure of real human survey data, both at the aggregate and individual levels, such that reliable scientific inference is possible?
Experimental Design and Framework
The work systematically addresses this question using the LISS panel, a probability-based longitudinal survey of Dutch households. For each respondent, digital personas are constructed using pre-2023 background variables combined with pre-2023 response histories. The central evaluation comprises two held-out prediction tasks:
- Single-wave prediction: Personas are given core-study histories and must predict single-wave responses occurring post-cutoff.
- Core prediction: Personas use single-wave histories to predict core-study responses post-cutoff.
Personas are generated using four architectures:
- Background only.
- Structured profile (behavioral summary).
- Profile + lexical retrieval (prior answers selected for lexical similarity).
- Profile + semantic retrieval (retrieved answers selected by embedding similarity).
Each is evaluated across three LLMs (GPT-5.4, Gemini 3 Flash, Claude Haiku 4.5), yielding 12 digital persona settings. Comparisons are made to a no-context baseline (LLM receives only the survey question without persona details).
Performance is measured in six dimensions: respondent-level and question-level match (exact accuracy), respondent-distribution and question-distribution alignment, demographic equity, and multivariate structure (clustering preservation).
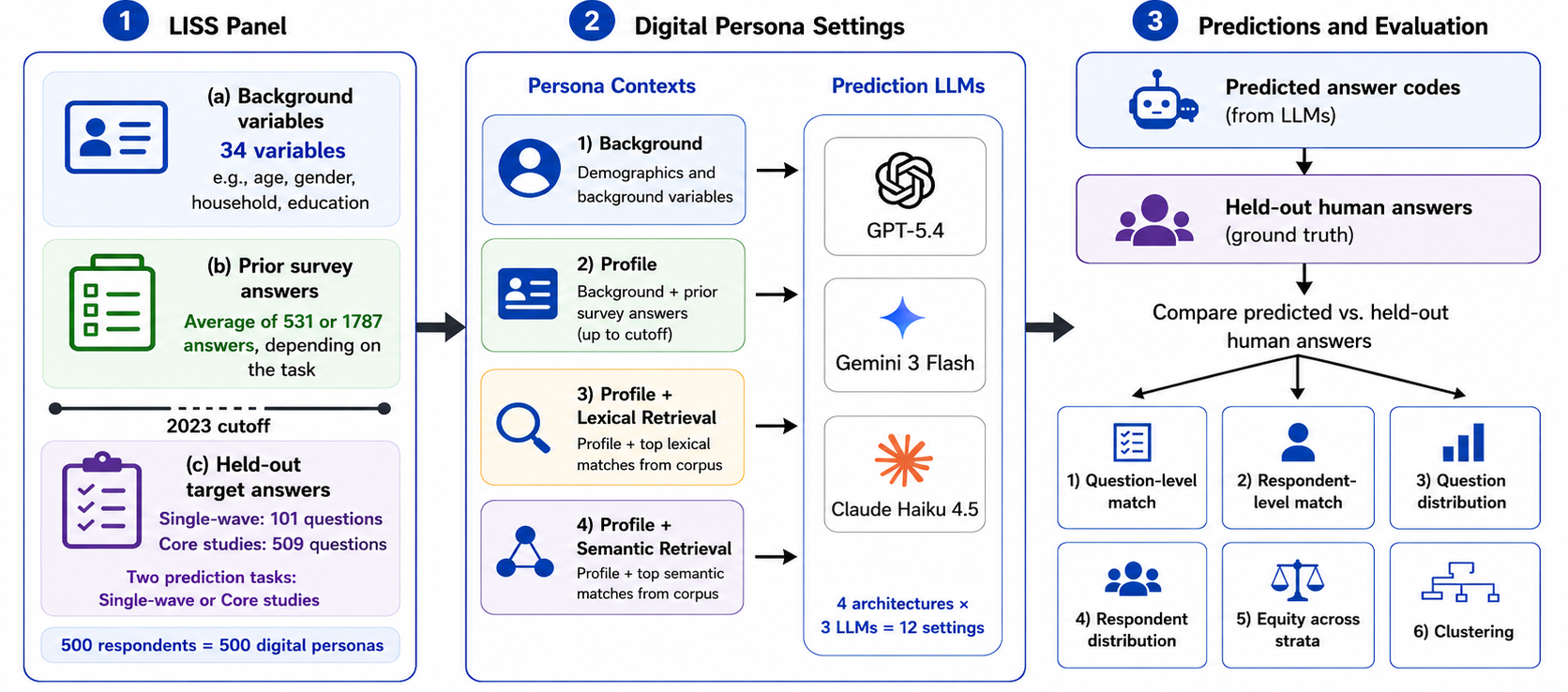
Figure 1: Overview of the persona construction and evaluation pipeline; digital personas are created from prior data, then evaluated on held-out responses for the same individuals.
Main Findings: Reliability Across Dimensions
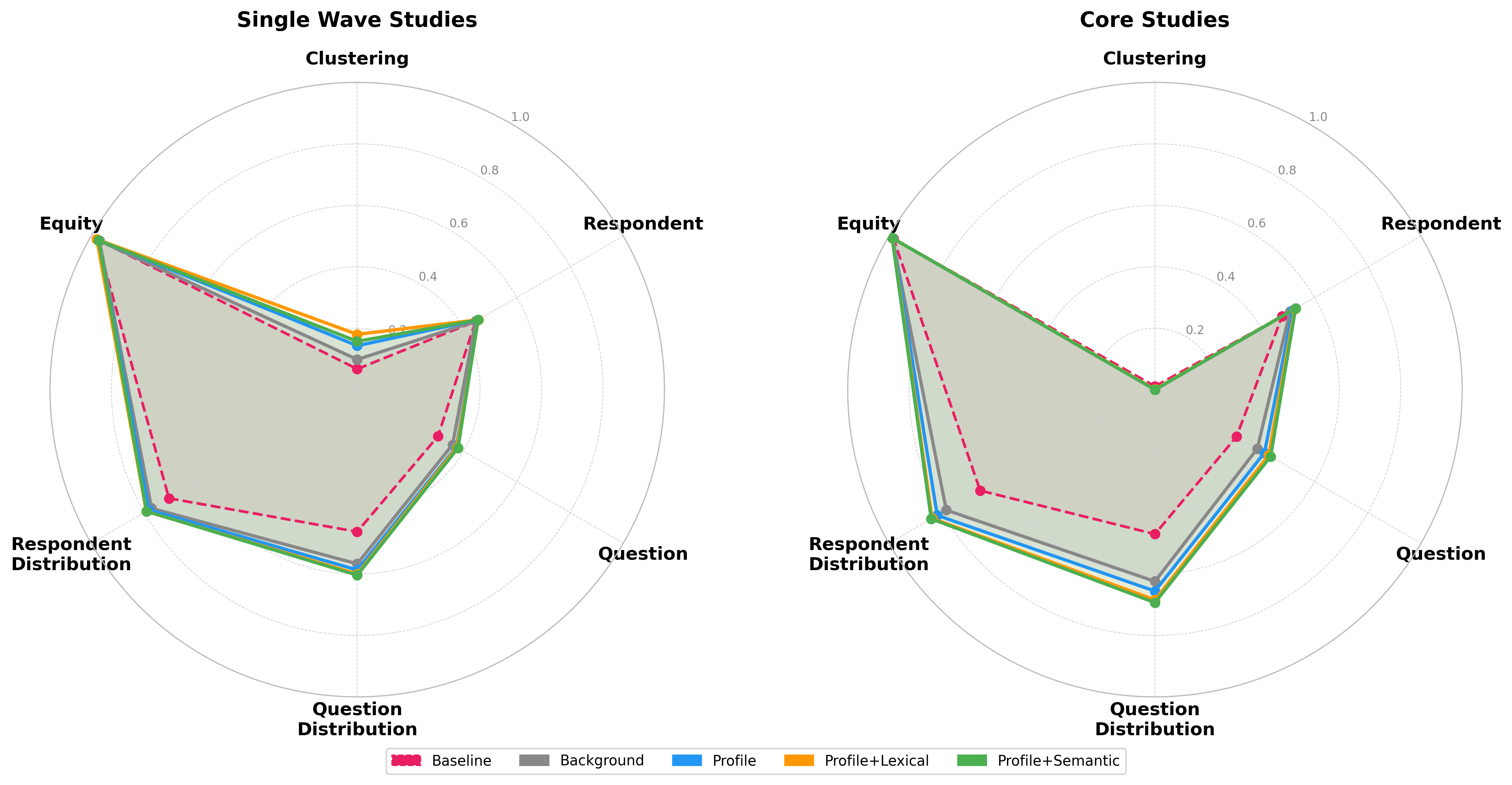
Figure 2: Radar plots summarizing the aggregate reliability of digital persona settings across six evaluation metrics. Retrieval-augmented architectures maximize distributional alignment but lag on exact individual prediction and clustering preservation.
The study yields several nuanced conclusions:
- Aggregate Distributional Approximation: Digital personas—especially with retrieval-augmented conditioning—substantially reduce the Jensen-Shannon distance between synthetic and human response distributions relative to the no-context baseline. This effect is domain-dependent and most pronounced for areas grounded in stable background variables (e.g., family and household, politics and values, religion and ethnicity), suggesting that answers anchored in enduring attributes are more accessible to synthetic agents.
- Individual-level Prediction: Despite gains in distributional alignment, exact-match rates at both respondent and question levels remain constrained (e.g., best respondent match rates peaking near 0.53 in core prediction). Personas fail to reliably substitute for individual respondents, especially for subjective, open-ended, or high-variability items.
- Demographic Equity: Stratified evaluation across gender, age, and household stage indicates broadly stable performance, with no substantial disparities emerging across core demographic strata (see Figure 3).
- Clustering and Multivariate Structure: Across architectures and LLMs, clustering similarity (Adjusted Rand Index) between human response profiles and persona outputs remains weak, indicating that higher-order, multivariate respondent structure is not preserved. This holds both globally and within demographic subgroups and across studies (Figures 8, 9, 10, 11).
- Error Patterns: The primary determinants of persona fidelity are question answer variability and respondent answer pattern rarity. Personas are most successful for low-entropy, common responses, and least faithful for high-entropy or rare patterns. The choice of LLM backbone (across the evaluated models) exerts less influence than retrieval-enhanced conditioning.
Numerical Results and Contradictory Claims
- Improved but Limited Distributional Alignment: For core prediction, digital personas reduce mean question-level JSD from 0.53 (baseline) to as low as 0.30 under profile+retrieval architectures. Similarly, MMD between respondent distribution matrices drops from 0.343 to ≈0.155 (best retriever) [see Table in appendix].
- Exact-Match Plateau: Respondent-level match rates, while improving over baseline (from 0.478 to ≈0.53; depending on LLM and architecture), never approach parity. Question-level weighted F1 scores follow a similar bounded pattern with maximal values ≈0.44.
- Clustering Non-recovery: Despite considerable gains on aggregate distributional metrics, clustering ARI remains close to zero under most settings for core studies, very occasionally exceeding 0.1 under single-wave scenarios. This underscores a strong decoupling between marginal distribution alignment and recovery of multivariate human structure.
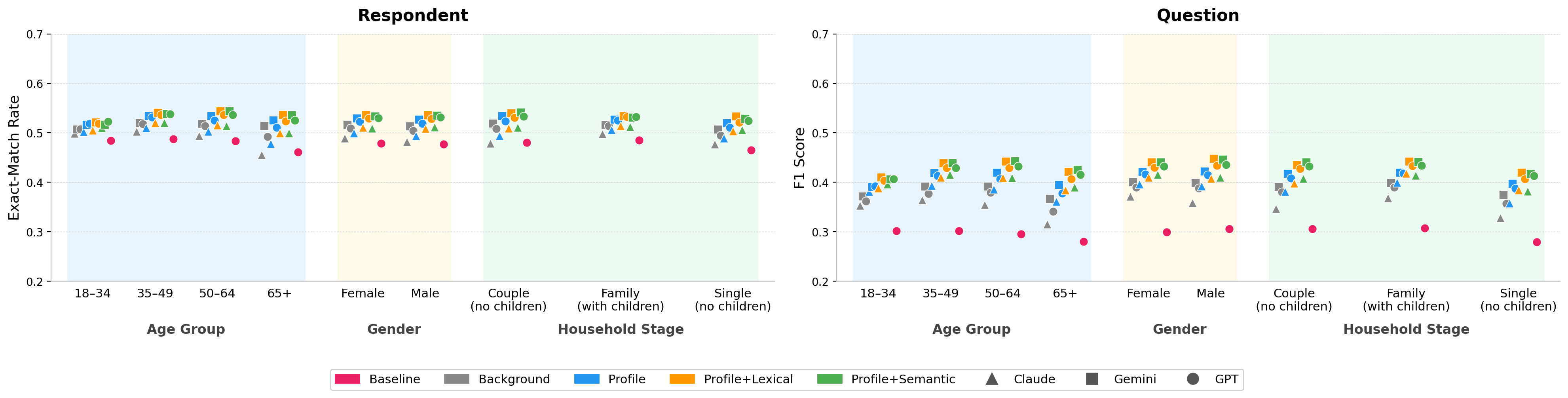
Figure 3: Exact-match accuracy across demographic strata, disaggregated by respondent and question; performance is stable, with limited variance between groups.
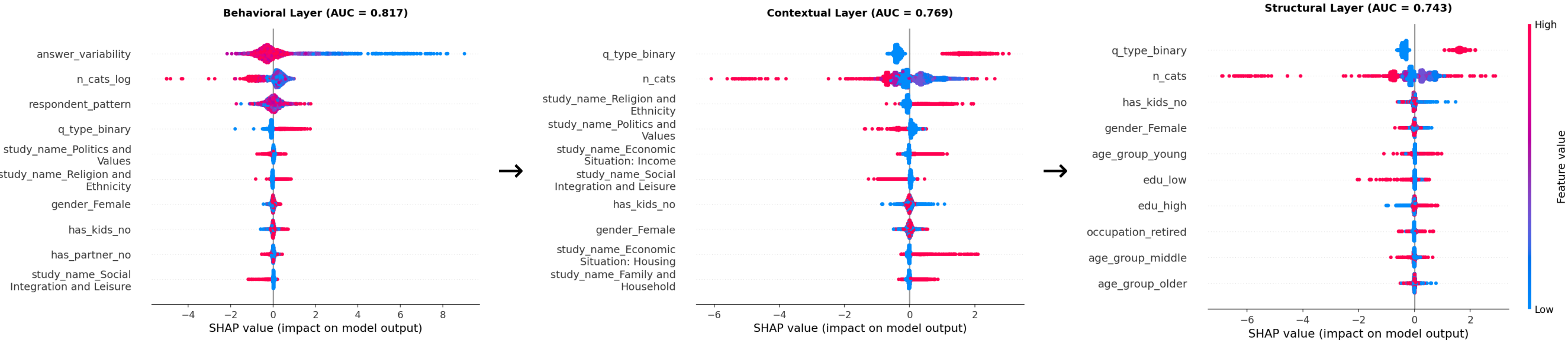
Figure 4: SHAP-based analysis of XGBoost error models reveals that answer variability and respondent pattern rarity are the dominant predictors of persona failure; question or profile complexity has secondary impact.
Implications and Theoretical Considerations
The findings deliver several implications for AI-driven social measurement:
- Conditional Applicability: Digital personas provide viable, computationally efficient proxies for aggregate-level inference in domains where responses are predictable from stable characteristics and prior history—e.g., instrument calibration or early-stage instrument development—but do not suffice for micro-level substitution or for tasks relying on joint respondent structure.
- Architectural Choices: Architectural improvements via retrieval-augmented prompting provide stronger gains than switching among recent high-performance LLMs, suggesting that context engineering is a more productive optimization axis than marginal LLM advancement (within the current model class).
- Inevitable Flattening: Even under optimal conditions, digital personas compress the diversity of response patterns and misrepresent rare or idiosyncratic human answer distributions. This property presents a risk for the study of minority opinion, subgroup analysis, or tasks sensitive to social or opinion heterogeneity—a risk corroborated by prior critiques of "flattened" digital identities [cf. (2605.10659, Park et al., 2024, Rupprecht et al., 19 Nov 2025)].
- Task Structure Dependency: The structure of the response task (answer variability, subjectivity, and respondent-level answer rarity) fundamentally dictates whether digital personas function as reliable surrogates. Model and prompt improvements have sharply diminishing returns for high-variance, subjective, or highly individualized survey items.
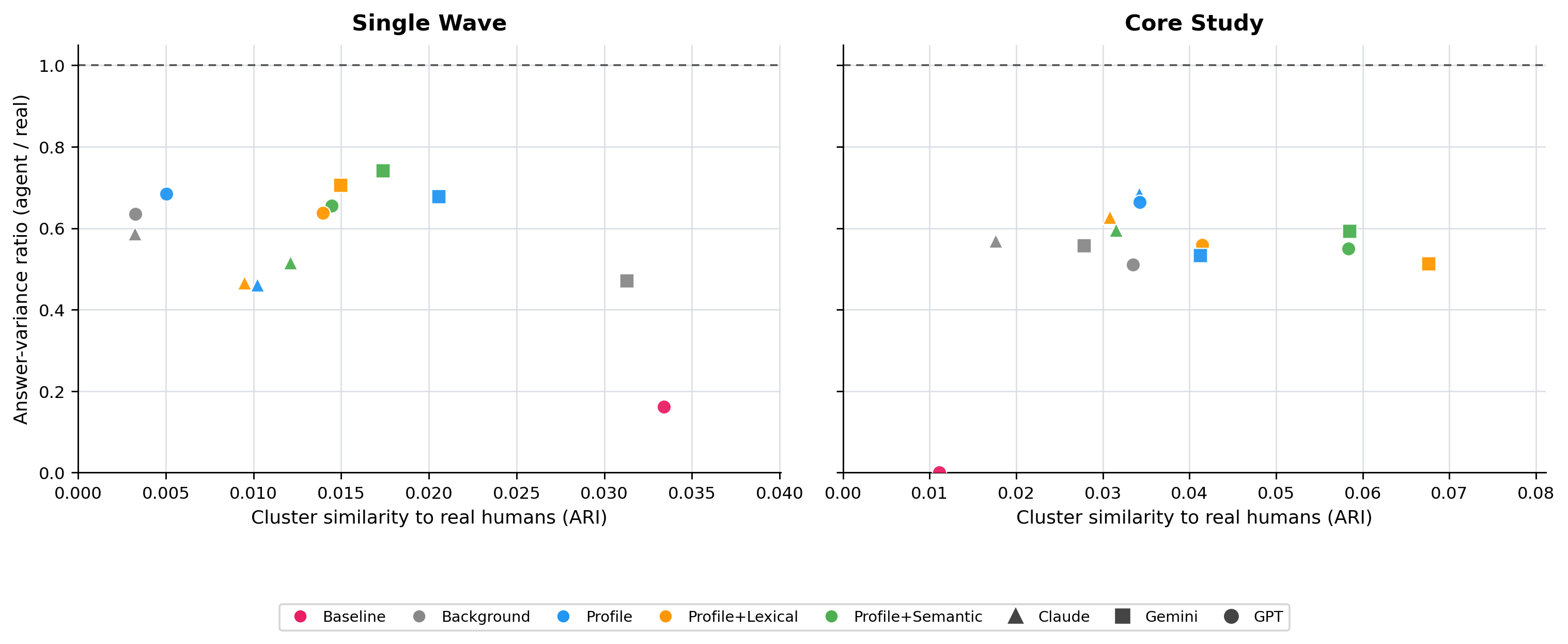
Figure 5: Clustering similarity and variance preservation for agent-generated responses, highlighting inability to match human diversity.
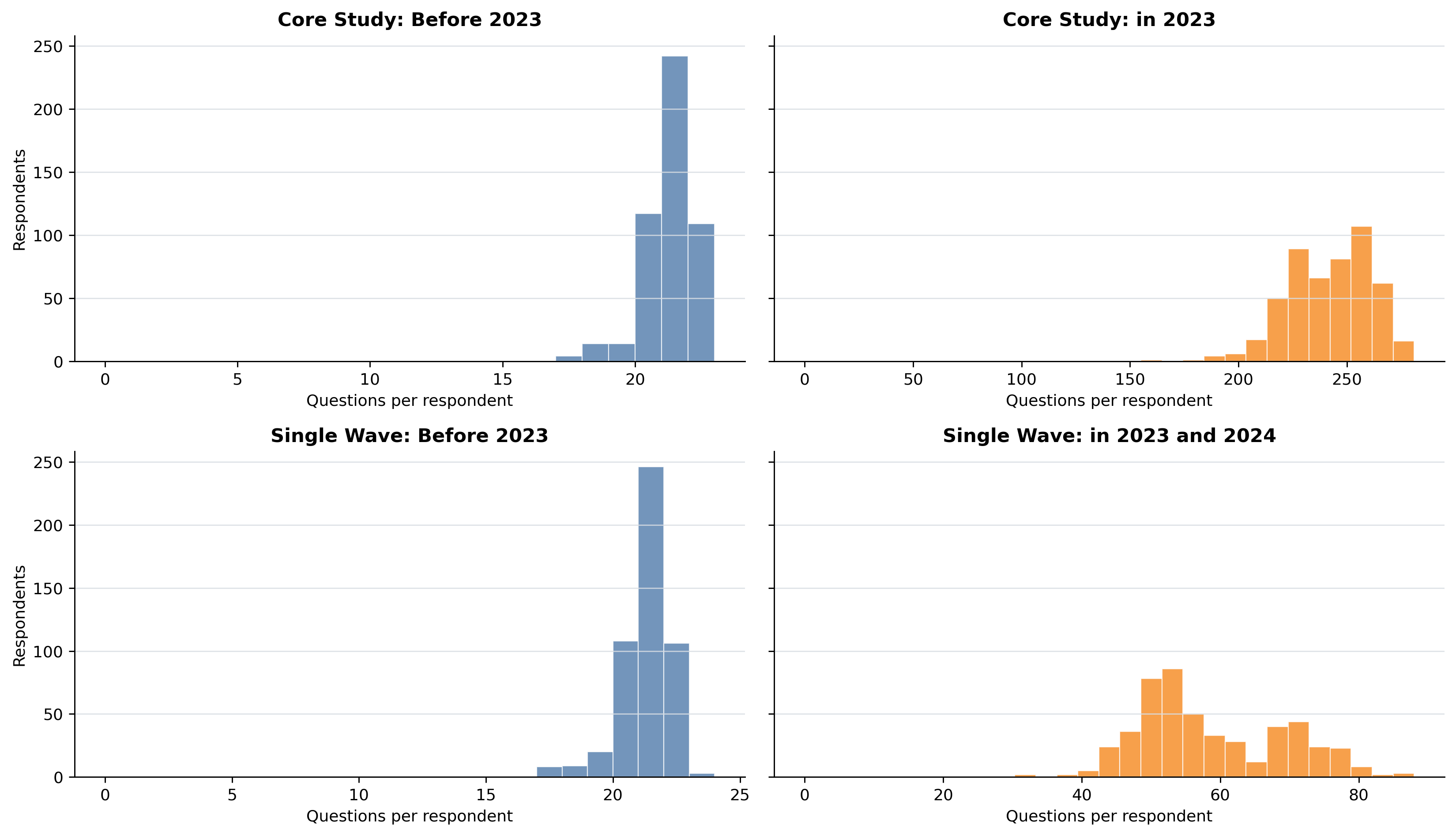
Figure 6: Distribution of answer coverage in prior vs. target survey splits supports robust respondent-level assessment.
Future Directions
Given these findings, several research avenues become prominent:
- Domains of Scalability: Further experiments should explore generalization to other languages, cultures, and non-panel survey populations to assess reliability under less structured or differently distributed response regimes.
- Architectural Expansion: Fine-tuned LLMs, memory-augmented agents, and dynamic retrieval strategies may offer incremental improvements, but fundamental limitations likely persist unless grounded in richer, more individualized behavioral histories or external situational data.
- Calibration for Minority Subgroups: Development of post-hoc calibration or data augmentation strategies tailored to rare response patterns and high-entropy items is vital for equitable and scientifically valid survey simulation.
- Validation Protocols: Theoretical and practical protocols should distinguish between use-cases for which digital personas suffice (e.g., distributional simulation) and those requiring human validation (e.g., subgroup discovery, individual behavioral modeling).
Conclusion
This extensive experimental framework demonstrates that the reliability of digital personas as substitutes for human survey data is fundamentally conditional. Personas serve as effective tools for simulating aggregate patterns in contexts tied to stable demographic and attitudinal anchors but are limited for individualized response prediction and do not recover finer multivariate respondent structure. The primary drivers of reliability are structural properties of the survey task—answer variability, subjective vs. objective content, and response rarity—rather than incremental LLM or architecture advances. These results support the use of digital personas in early-stage survey work and instrument testing, provided researchers remain cognizant of their systematic limitations and validate outcomes against genuine human data for tasks involving high response diversity or rare populations.