- The paper introduces an end-to-end system, ScaleGANN, which leverages cost-effective cloud spot GPUs to accelerate large-scale ANN indexing by decoupling GPU-based construction from CPU-driven query serving.
- The paper presents a disk-resident partition-and-merge strategy with adaptive vector partitioning and selective replication that reduces memory overhead to as low as 33% of full replication baselines.
- The paper validates its approach through experiments achieving up to 9x build acceleration and 6x cost reduction compared to traditional CPU-based ANN systems.
ScaleGANN: Accelerating Large-Scale ANN Indexing with Cost-effective Cloud GPUs
Introduction
ScaleGANN presents an end-to-end system for accelerating large-scale, high-dimensional Approximate Nearest Neighbor Search (ANNS) index construction by leveraging cost-effective spot GPU resources in distributed cloud environments. The central focus is to address the inefficiency and cost bottlenecks of existing billion-scale ANNS systems, particularly targeting the dominant computational overhead of graph index construction, while optimizing resource utilization strategy between build and query stages. The proposed framework emphasizes the separation of GPU-accelerated construction (using preemptible spot instances for short-lived, compute-intensive tasks) from CPU-based query serving, thus achieving both high-speed construction and cost-effective, scalable deployment.
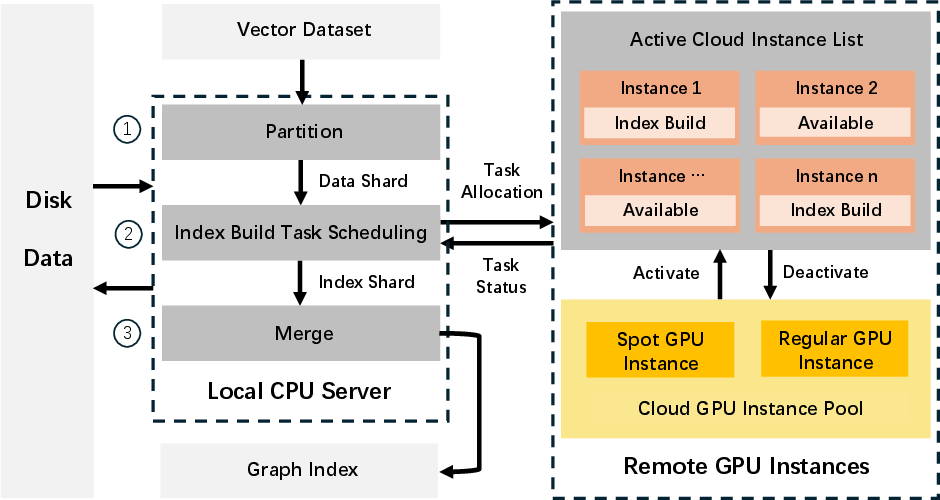
Figure 1: Overview of the ScaleGANN index build framework, demonstrating hybrid CPU-GPU resource allocation and cloud-native task scheduling.
Technical Contributions
Disk-resident Partition-and-Merge Graph Index Construction
ScaleGANN extends the classical partition-and-merge strategy by introducing an adaptive vector partitioning method with selective replication. Instead of uniform, full replication, vectors are assigned using blockwise, adaptive policies with tight cluster capacity and data-distribution-aware replica thresholds, thereby reducing storage overhead and diminishing unnecessary inter-shard connectivity, while ensuring optimal global graph quality. This selective replication is governed by tunable distance-based and cluster-radius-based constraints. As a result, the overall replication rate can be tuned to as little as 33% of the baseline, yielding significant reductions in both memory and disk I/O requirements.
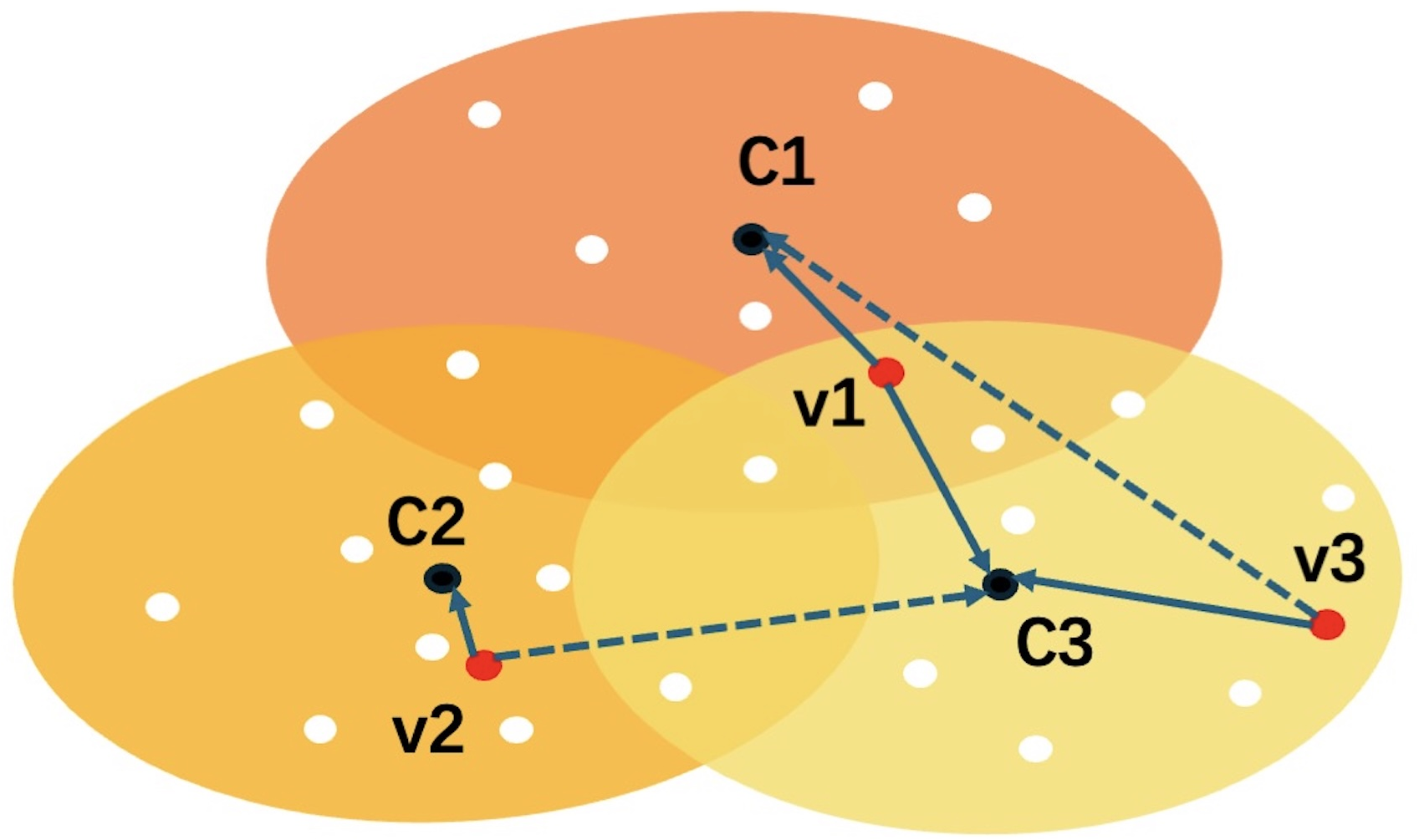
Figure 2: Illustration of ScaleGANN's assignment policy for selective, blockwise-adaptive vector replication.
GPU-Accelerated Shard-wise Graph Indexing with Cloud Spot Instances
The framework orchestrates the index build process by assigning shard-level graph construction tasks to ephemeral GPU spot instances, exploiting massive parallelism while minimizing cost. The decoupled nature of shard indexing tasks aligns precisely with the operational characteristics of spot resources: short duration, failure-tolerant, and parallelizable. A cloud-native task scheduler is designed to dynamically assign pending tasks to available spot instances, taking into account task duration estimation (using dataset sampling and build-time proportion scaling) and spot instance termination probability, to minimize preemption-induced rework. All disk and tightly-coupled operations—partitioning and merging—are retained on CPUs, reflecting their parallelism limitations and disk-centric access patterns.
Integration with State-of-the-Art GPU Indexing Algorithms
ScaleGANN is agnostic to the underlying shard indexer. In this demonstration, the framework integrates with CAGRA—a highly parallel GPU-based KNN graph construction method—for fast build performance. The selective replication mechanism is compatible with both CAGRA and Vamana-based indices, underscoring its generality.
Experimental Analysis
Selective Replication: Index Build Efficiency and Search Quality
Comprehensive experiments on datasets ranging from 100M to 1B vectors validate the efficacy of selective replication. For example, on Sift100M, reducing replication to one-third using a selectivity parameter ϵ=1.1 leads to a build time of 2,220 seconds (down from 3,564 seconds for naive full replication) without any degradation in recall or query throughput. Indeed, for moderate ϵ, search QPS even improves, as replicated vectors' redundancy—and thus unnecessary traversal—is reduced.
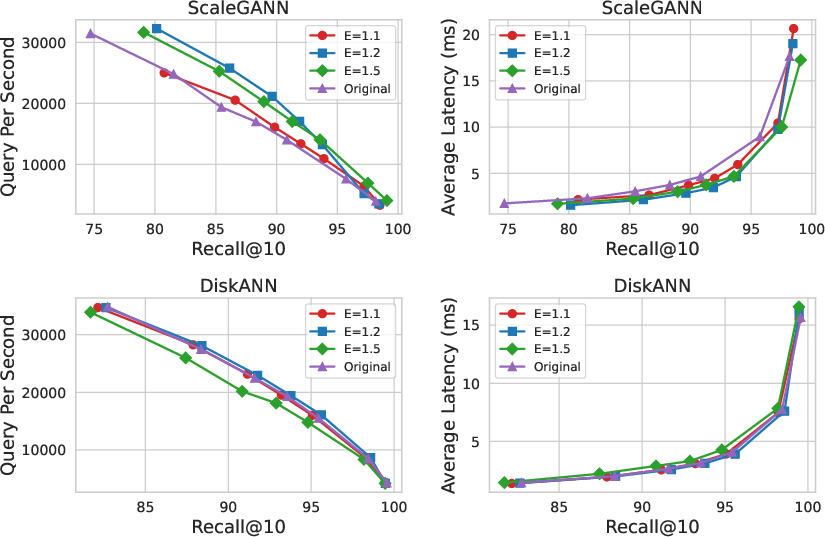
Figure 3: Impact of selectivity parameter ϵ on Sift100M search quality and index build time.
ScaleGANN consistently outperforms CPU-based DiskANN by a wide margin: on Laion100M at index degree R=128, the framework achieves 9x end-to-end build acceleration and reduces cost by up to 6x. The GPU build-only time for ScaleGANN is consistently less than 2x of Extended CAGRA, despite the latter operating without replication or merging. In comparison with GGNN, ScaleGANN achieves a 3x speedup at large graph degrees by leveraging more effective task parallelism and lower data redundancy.
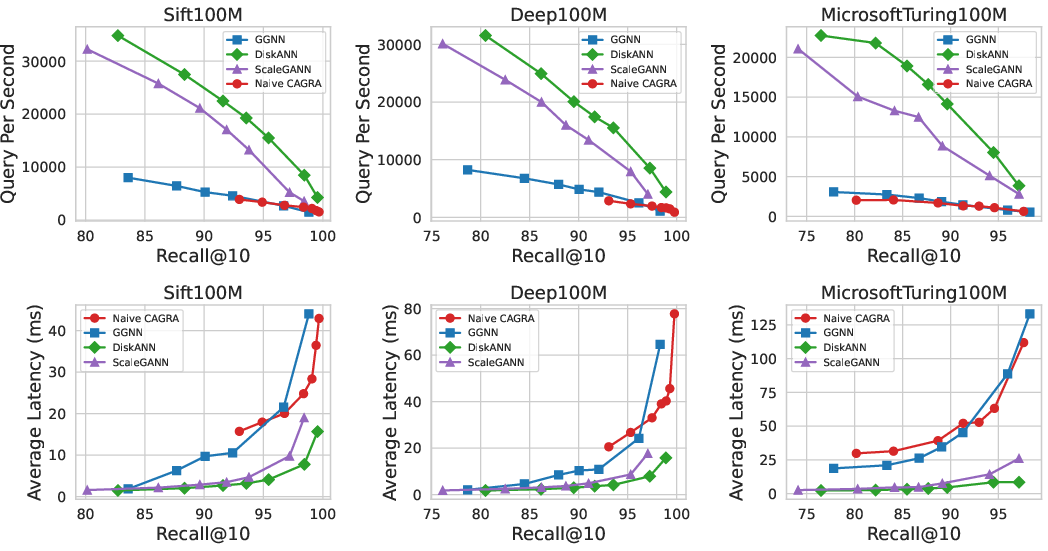
Figure 4: Search performance comparison on low-dimensional datasets for top-10 recall, query-per-second (QPS), and latency across all systems.
For large-scale, high-dimensional benchmarks such as Laion100M, ScaleGANN demonstrates both superior build scalability and competitive query performance due to its unified merged index structure, outperforming split-only approaches that suffer from costly aggregation during querying.
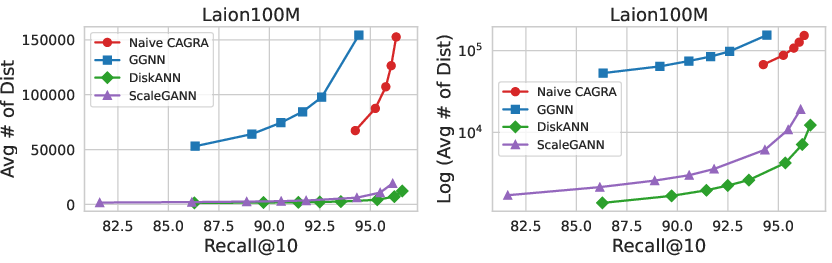
Figure 5: Search performance of integrated (merged) indices on Laion100M, with competitive recall/QPS versus alternative methods.
Multi-GPU Parallelism
Empirical results confirm near-linear speedup when scaling from 1 to 4 GPUs, demonstrating the partitioned shard-wise approach aligns well with cloud-native resource elasticity. Under typical workloads, shard-level tasks can complete in under a few minutes each, permitting fine-grained load balancing and rapid failover in the presence of spot preemptions.
Cost-Effectiveness Analysis
Cost models, validated against AWS and Alibaba Cloud pricing, indicate that ScaleGANN using spot GPU instances achieves up to 6x lower expense than DiskANN on comparable workloads. Even on-demand cloud GPUs can yield cost savings due to reduced active runtime; however, spot instance utilization further amplifies savings, especially when coupled with efficient checkpointing and rescheduling mechanisms.
Practical and Theoretical Implications
The approach advocated by ScaleGANN implies a shift in large-scale ANN system architecture: decoupling construction from serving in both compute and economic dimensions. This separation admits specialized optimization in each phase, minimizing both turnaround time and operational cost. The demonstrated compatibility with existing GPU-based indexers ensures broad applicability, while the partition-and-merge paradigm preserves global index quality and query efficiency.
From a theoretical perspective, the selective replication strategy provides new avenues for studying the connectivity-quality trade-off in disk-resident large-scale graph indices, with implications for further reducing space/time complexity without sacrificing recall.
Future Directions
Challenges remain in further embracing heterogeneity and preemption dynamics intrinsic to spot instance environments. Opportunities exist for incorporating robust checkpointing, fault-tolerant scheduling, and migration strategies to further minimize wasted work. Adaptation to heterogeneous GPU memory capacities and compute profiles may yield even better efficiency/cost trade-offs. At the system level, serverless or ephemeral-cloud-native variants may offer even finer resource granularity, further reducing the effective cost of one-off intensive ANNS index builds.
Conclusion
ScaleGANN demonstrates a significant leap in scalable, cost-effective billion-scale ANN index construction by leveraging a cloud-native, GPU-accelerated, partition-and-merge architecture with selective replication and dynamic resource allocation. The framework achieves major reductions in build time and operational expense compared to leading baselines, while preserving or enhancing index quality. The work paves the way for robust, high-throughput, and affordable solutions to large-scale vector search, setting new standards for ANN system design and cloud resource utilization.