- The paper introduces Med-StepBench, the first benchmark that deconstructs clinical diagnosis into sequential steps for localized hallucination detection.
- It employs a hierarchical framework with four expert-designed stages, rigorously evaluating both 2D and 3D PET/CT imaging for reasoning failures.
- Experiments reveal significant drops in performance during feature characterization and diagnostic synthesis, underscoring challenges with language priors and multi-step reasoning.
Med-StepBench: A Hierarchical Reasoning Benchmark for Hallucination Detection in Medical Vision-LLMs
Motivation and Context
The development of large multimodal vision-LLMs (VLMs) has rapidly accelerated progress in automated medical image interpretation, including medical visual question answering (MedVQA) and radiology report generation. However, VLMs present critical safety risks by generating clinically plausible yet incorrect statements—a phenomenon known as hallucination. Existing evaluation benchmarks are predominantly limited to 2D radiological images, largely ignore 3D modalities (critical for oncology with PET/CT), and assess only end-to-end outputs, failing to localize reasoning failures within the multi-step clinical diagnostic workflow. Med-StepBench addresses these limitations by offering the first large-scale, step-wise benchmark for hallucination detection in both 2D and 3D PET/CT data, with granular clinician-verified annotations for each sequence of diagnostic reasoning.
Hierarchical Step-wise Hallucination Evaluation Framework
Med-StepBench decomposes the clinical diagnostic pipeline into four sequential, expert-designed stages: Anatomical Mapping, Lesion Identification, Feature Characterization, and Diagnostic Synthesis. Each PET/CT case provides both 2D (axial, coronal, sagittal) and registered 3D imaging, with over 1 million image-statement pairs meticulously annotated by licensed clinicians. For each diagnostic stage, ground truth statements are paired with matched “hallucination distractors”—statements corrupted by controlled, anatomically plausible but visually inconsistent edits.
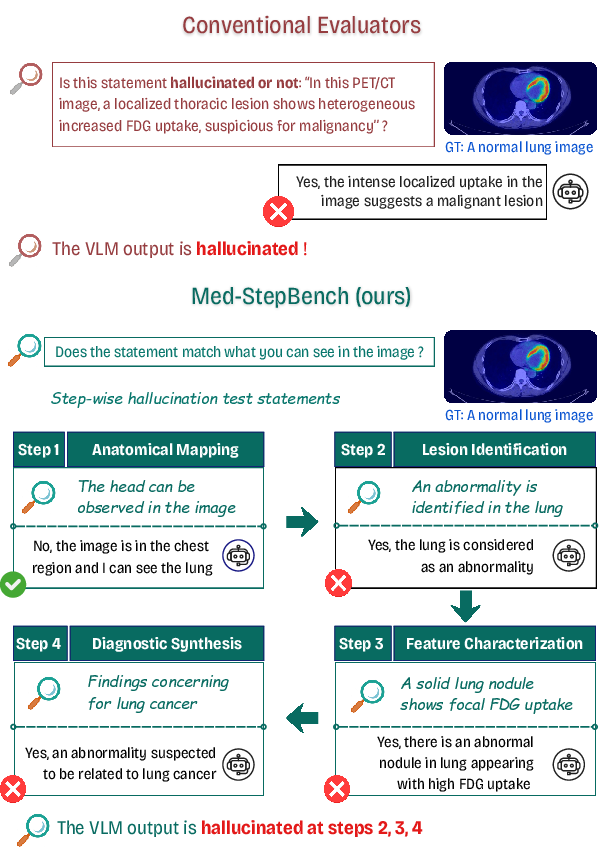
Figure 1: Qualitative examples from Med-StepBench illustrating how clinically plausible diagnoses can mask incorrect intermediate reasoning, and how step-wise evaluation reveals hallucinations.
This hierarchical structure enables detailed localization of reasoning breakdowns: for example, a VLM may provide a correct final diagnosis but rely on hallucinated intermediate lesion attributes or anatomical mislocalization, failures which standard end-to-end benchmarks cannot detect.
Data Acquisition and Annotation Design
PET/CT cases were retrospectively collected from a hospital in Vietnam, de-identified, and preprocessed according to clinical standards. Volumetric CT and fused PET/CT images follow clinical overlay conventions.
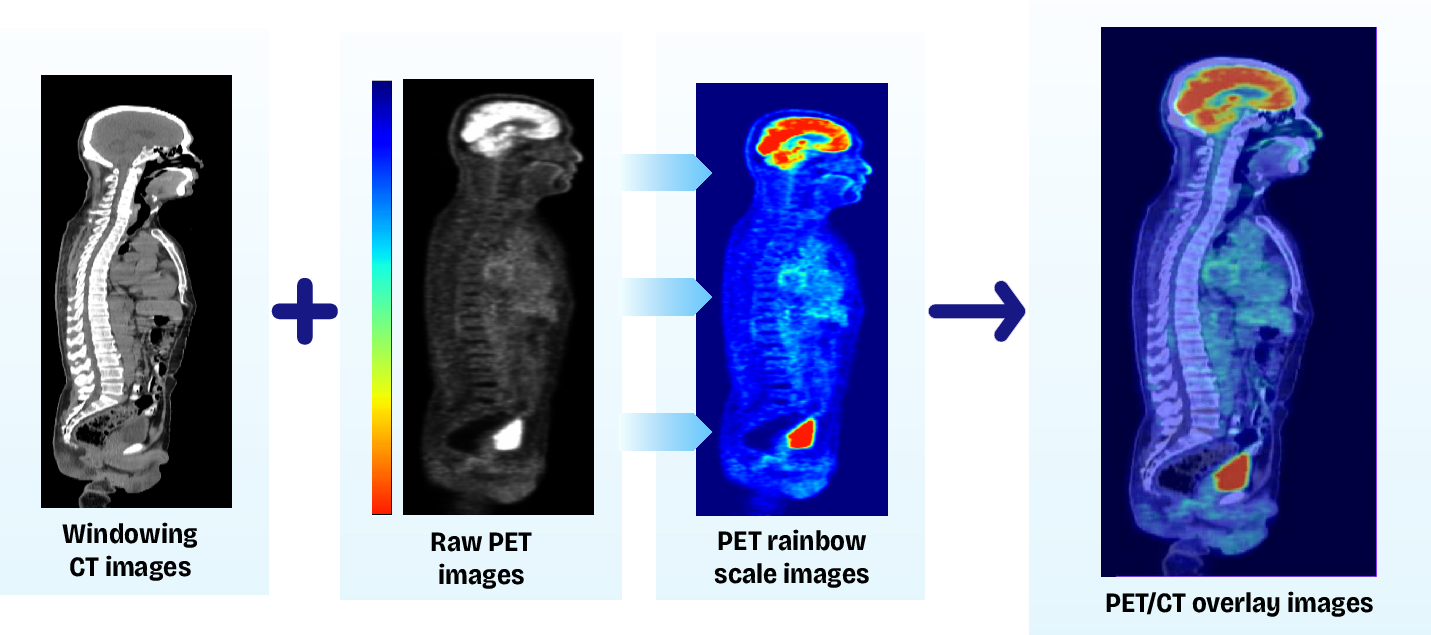
Figure 2: PET/CT overlay method. Oncologists routinely examine PET/CT overlay images during the diagnostic evaluation of patients.
All statement pairs are available in Vietnamese and in terminology-preserving English, allowing controlled evaluation of language effects on hallucination. For each image, clinical reasoning chains were annotated to generate both grounded and hallucinated statements at every stage, with mechanisms to inject prior step knowledge or external medical knowledge (via RAG) to probe contextual effects.
Step-wise Hallucination Definitions
Each step employs a clinically aligned hallucination taxonomy:
- Anatomical Mapping Hallucination: Errors in spatial localization or region mapping (e.g., asserting kidneys in head-neck images).
- Lesion Identification Hallucination: Hallucinatory detection or omission of lesions, misattribution to physiological uptake, or mislocalized findings.
- Feature Characterization Hallucination: Errors in numeric and attribute grounding, such as fabricated lesion size/SUV or omitted attributes.
- Diagnostic Synthesis Hallucination: Multi-hop reasoning errors, including unjustified disease claims, cognitive bias, or inconsistent conclusions.
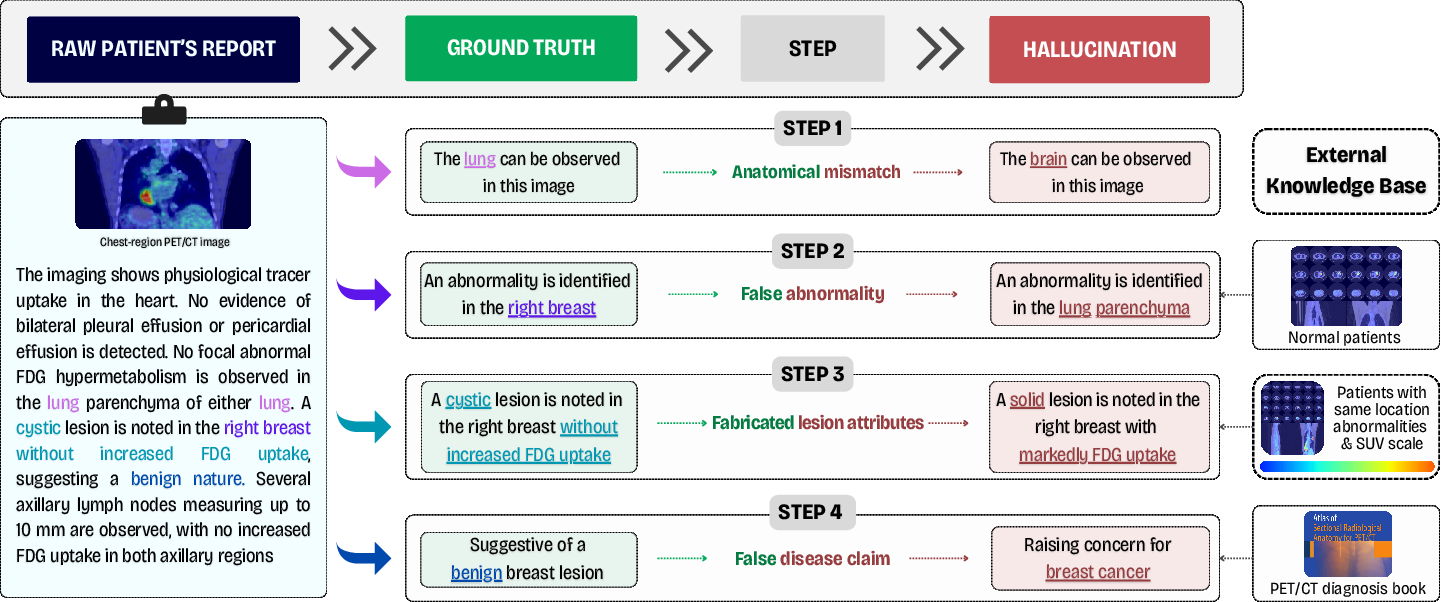
Figure 3: Step-wise hallucination evaluation framework. Decomposing each PET/CT case into four sequential reasoning stages and extracting clinician-verified step-level ground-truth statements. For each step, paired hallucinated statements are generated for fine-grained evaluation across the pipeline.
This fine-grained hierarchy allows quantifying not only the rate but also the clinical impact and propagational pathways of hallucination errors in VLMs.
Hallucination Detection Methodology
VLMs are evaluated by binary consistency judgment—deciding, given a medical image (and optionally, contextual knowledge), whether a provided statement (factual or hallucinated) is visually grounded. Precision, recall, and F1-score are computed at every reasoning step.
Experiments were conducted in both English and Vietnamese, and knowledge injection was evaluated via prior-step propagation and external retrieval-augmented generations. The evaluation suite spans frontier general-purpose VLMs (e.g., GPT-4o, Gemini 2.5 Pro/Flash, Qwen3-VL, LLaVA), medical-adapted VLMs (Med-Flamingo, LLaVA-Med, MedM-VL), and, critically, volumetric medical VLMs (MedM-VL 3D, M3D-LaMed).
Experimental Results and Analysis
Bottlenecks in Multi-stage Reasoning
Step-wise analysis reveals an unambiguous increase in hallucination rates as tasks progress from lower-level anatomical recognition to attribute characterization and complex diagnostic synthesis. The most substantial performance degradation occurs at Step 3 (feature characterization) for 3D models—e.g., MedM-VL 2D drops to F1 = 0.40 (EN), and MedM-VL 3D to F1 = 0.51—demonstrating that fine-grained attribute grounding in volumetric data remains an unsolved challenge.
For 2D models, Step 4 (diagnostic synthesis) yields the lowest F1, underscoring susceptibility to multi-hop reasoning failures.
Sensitivity to Plausible Rationales
Conditioning VLMs on intermediate rationales (especially clinician-written) significantly increases error rates. Models become susceptible to narrative persuasion and accept visually inconsistent conclusions, suggesting that language priors can override image verification. This effect is especially pronounced for models trained with substantial free-text in medical style.
Effect of Prior and External Knowledge
Injecting knowledge at intermediate stages (either prior ground-truth statements or external retrievals) produces only marginal improvements; in most cases, error redistribution is observed rather than meaningful hallucination mitigation. Lesion identification steps benefit the most; fine-grained attribute steps remain stubborn bottlenecks.
Importance of PET/CT Fusion
Fused PET/CT images (as opposed to simple channel concatenation) provide superior alignment and grounding, leading to substantial F1 improvements in most models, particularly for anatomical and attribute reasoning steps.
Implications and Future Directions
This work exposes persisting limitations in contemporary VLMs regarding clinical reliability:
- Error Propagation in Hierarchical Reasoning: Hallucinations introduced at any intermediate stage compromise the entire diagnostic pipeline, underscoring the need for VLMs with explicit step-wise self-checking or chain-of-thought verification.
- Vulnerability to Medical Priors and Language Bias: High-level medical styles and external rationales can exacerbate hallucination acceptance, warning against overreliance on language-only cues in critical decision frameworks.
- Modality and Spatial Grounding: True clinical deployment requires robust volumetric grounding across PET/CT, not just pattern recognition in 2D images. Effective clinical AI must address this challenge.
- Need for Step-Level and Multi-language Benchmarks: Med-StepBench sets a new bar for evaluation by enabling localization of failures and robust cross-lingual benchmarking, which is crucial for global clinical translation.
Future research should target VLM architectures capable of explicit multi-step verification, causality-aware reasoning, uncertainty estimation, and integrated feedback mechanisms to reduce propagation of hallucinations. Improved embeddings for multi-view 3D spatial grounding and stronger alignment of radiologic conventions will be critical, as will adversarial defense strategies against plausible but incorrect rationales.
Conclusion
Med-StepBench represents a step change in evaluation rigor for medical VLMs, enabling systematic, hierarchical, and multi-modal analysis of hallucination phenomena. The results highlight substantial limitations in present models, especially regarding multi-stage clinical reasoning and volumetric image understanding. Med-StepBench provides a practical and principled foundation for future research toward safer and more clinically aligned vision-language AI systems.
(2605.10002)

