- The paper introduces the SGMRI-VQA benchmark that enables multi-frame spatial reasoning in 3D MRI, leveraging expert-annotated QA pairs and chain-of-thought traces.
- It employs a hierarchical evaluation framework combining image-level and volume-level tasks to assess detection, localization, classification, and captioning in brain and knee MRI.
- Practical results show that fine-tuned models, such as Qwen3-VL-8B, achieve high detection accuracy and improved pixel-level localization, highlighting gaps in current VLM spatial grounding.
Multi-Frame Spatial Reasoning and Grounding in Volumetric MRI: SGMRI-VQA
Motivation and Benchmark Design
The paper "Beyond a Single Frame: Multi-Frame Spatially Grounded Reasoning Across Volumetric MRI" (2604.15808) addresses a critical deficiency in clinical vision-LLMs (VLMs): the lack of spatially grounded reasoning across volumetric medical imaging. While prior VLMs have demonstrated proficiency in visual question answering (VQA) on single-frame 2D images, clinical interpretation of MRI requires multiframe reasoning, localization, and anatomical grounding. The SGMRI-VQA benchmark is thus introduced to evaluate VLMs in realistic diagnostic scenarios, requiring models to detect, localize, classify, and caption findings across both image-level and volume-level tasks in 3D MRI of the brain and knee.
SGMRI-VQA comprises 41,307 rigorously curated QA pairs, each supported by expert radiologist annotation from fastMRI+, including chain-of-thought reasoning traces and slice-indexed bounding box coordinates. Figure 1 illustrates the class distribution, emphasizing the dominance of abnormal findings, which more accurately reflects clinical workflow.
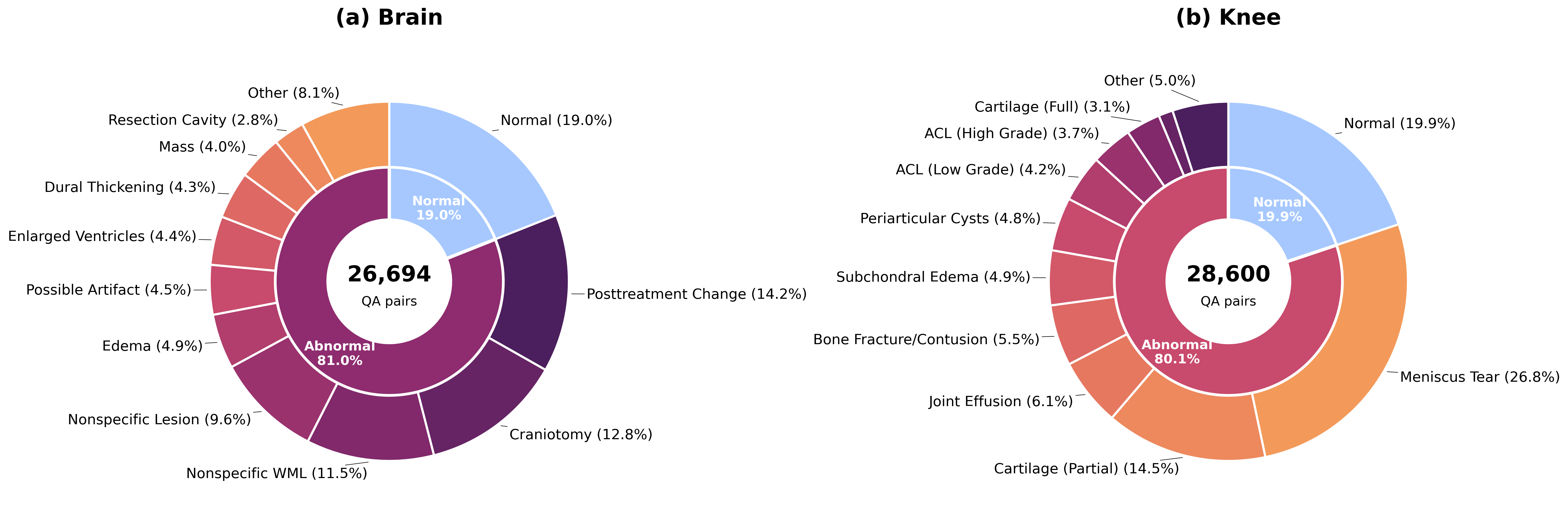
Figure 1: Finding category distribution shows prevalence of abnormal cases and fine-grained pathological categories.
Data processing ensures spatial consistency and laterality correctness. Quality assurance required domain-expert annotation to correct GPT-4o-generated hallucination errors, particularly with hemisphere and knee compartment labels. For anatomical orientation, the fibula side was manually annotated to resolve ambiguities in knee MRI spatial labeling, as shown in Figure 2.
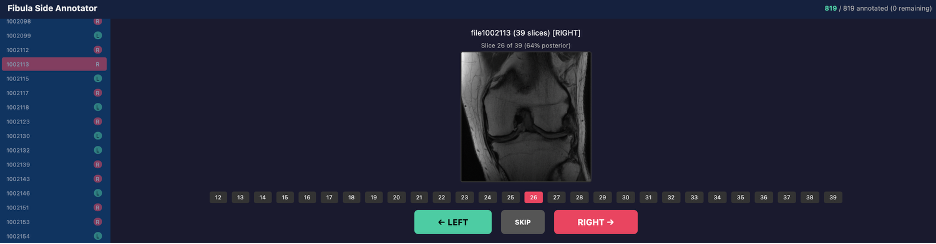
Figure 2: Web tool for annotating fibula laterality, determining medial/lateral orientation in knee MRI.
Benchmark Structure and Dataset Analysis
SGMRI-VQA hierarchically organizes evaluation at both slice (image-level) and volume (multi-frame) scales. Image-level tasks include detection, localization (both anatomical description and pixel-level bounding boxes), classification, diagnosis, and free-text captioning. Volume-level tasks follow a radiological diagnostic pipeline: detection → localization → classification → counting → captioning, requiring models to reconstruct findings across sequential slices.
The dataset is comprised of 50K+ slices across 1,970 volumes (996 brain, 974 knee) and supports granular statistical analyses. Figure 3 visualizes dataset distributions, including QA pairs-per-sample, question length, and answer length stratified by answer format and reasoning trace inclusion.
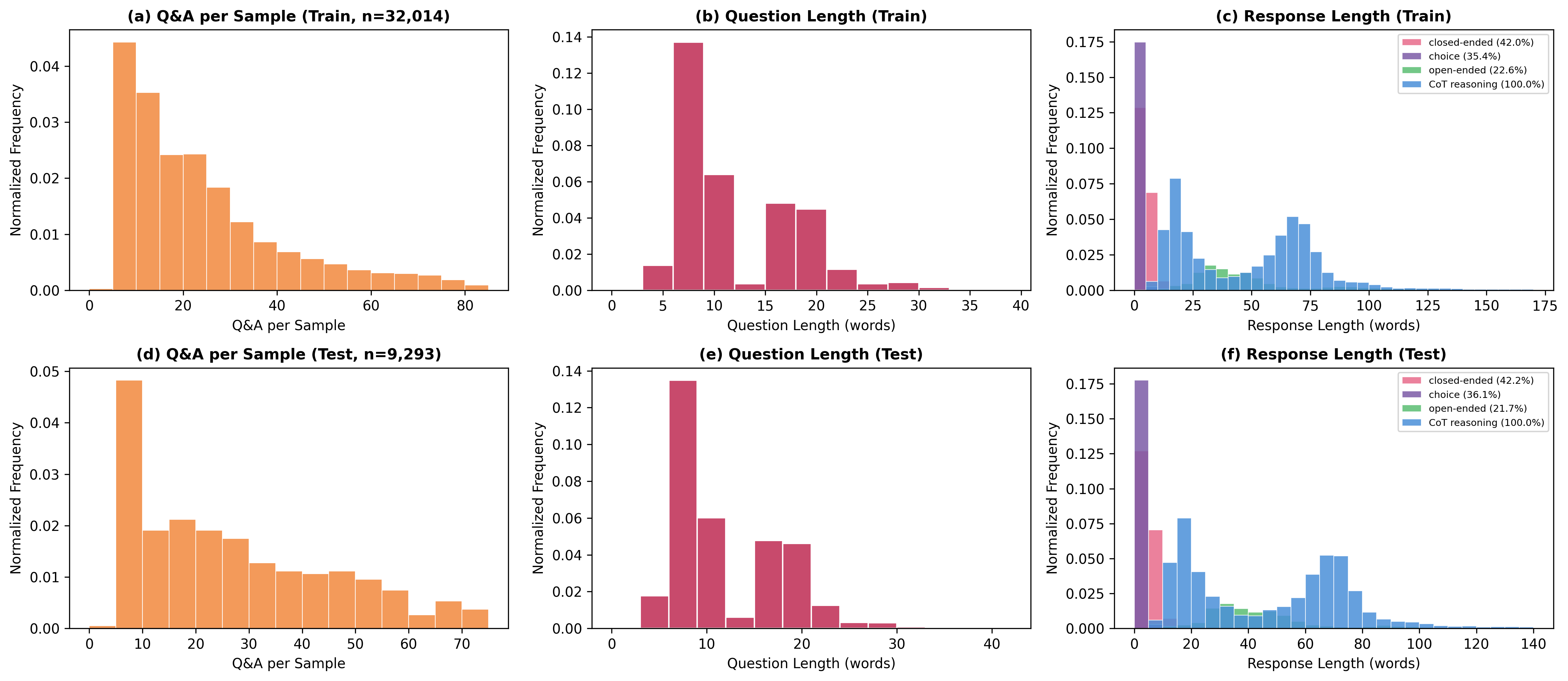
Figure 3: Statistical analysis of SGMRI-VQA—QA pairs per sample, question length, and response length by format and chain-of-thought traces.
SGMRI-VQA introduces cross-slice visual grounding: models must specify both anatomical region and spatial coordinates for findings, including slice indices across a 3D volume.
Model Evaluation and Experimental Results
Ten VLMs are systematically evaluated—three proprietary (GPT-4o, Gemini 2.5 Pro, Gemini 2.5 Flash), five open-source (Qwen3-VL-8B, Qwen2.5-VL-7B, Eagle2.5-8B, InternVL2.5-8B, LLaVA-Video-7B), and two domain-specific medical VLMs (LLaVA-Med-v1.5, MedGemma-1.5). Evaluation metrics include:
- A-Score: Factual answer accuracy (exact match, F1, embedding similarity)
- AR-Score: Reasoning quality (GPT-4o-mini judge, BERTScore, BLEU, ROUGE-L)
- V-Score: Pixel-level spatial grounding (mean IoU of predicted vs. ground truth bounding boxes)
Strong numerical results are achieved through full supervised fine-tuning. Qwen3-VL-8B-SGMRIVQA, fine-tuned with spatially annotated data, delivers best-in-class performance—image-level detection at 95.11%, classification at 97.56%, diagnosis at 94.50%, localization V-Score at 15.51% (2.6× higher than previous best Gemini-2.5-Flash), and overall average score at 59.45%. On volume-level tasks, detection reaches 99.18%, classification 97.70%, and localization V-Score 5.97%. All baselines (including GPT-4o and Gemini) exhibit a marked gap between textual spatial understanding and pixel-level grounding.
Qualitative results highlight the model’s cross-slice spatial precision and anatomical reasoning. Figure 4 presents localization outcomes for both image-level and volume-level MRI tasks, with radiologist-labeled ground-truth and predicted bounding boxes.
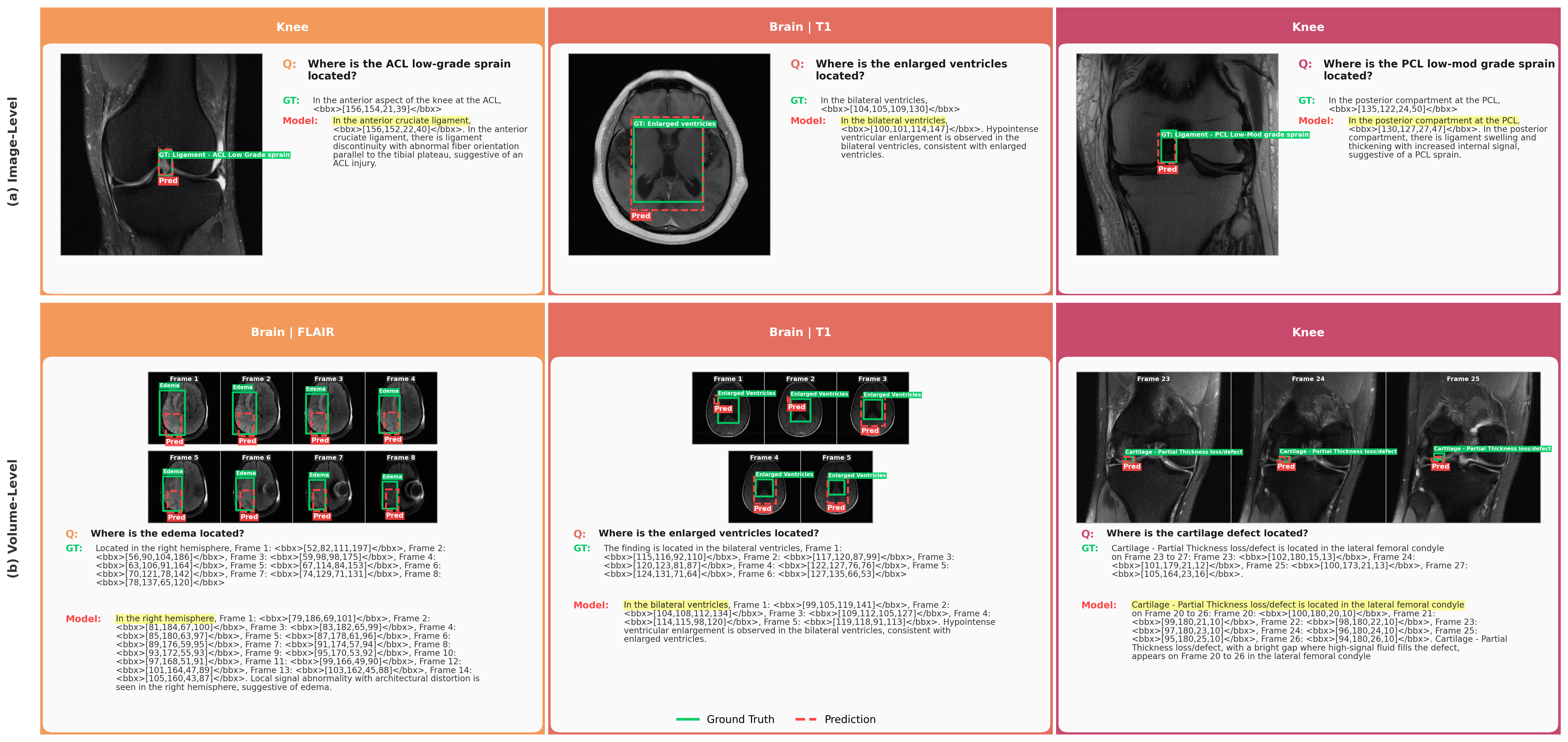
Figure 4: Fine-tuned Qwen3-VL-8B achieves accurate spatial grounding at both image- and volume-level granularity.
Quality assurance analysis reveals persistent errors in baseline spatial reasoning, particularly hemisphere assignment in brain MRI and medial/lateral compartment in knee MRI. Figure 5 describes typical GPT-4o hallucination errors corrected during dataset cleaning.
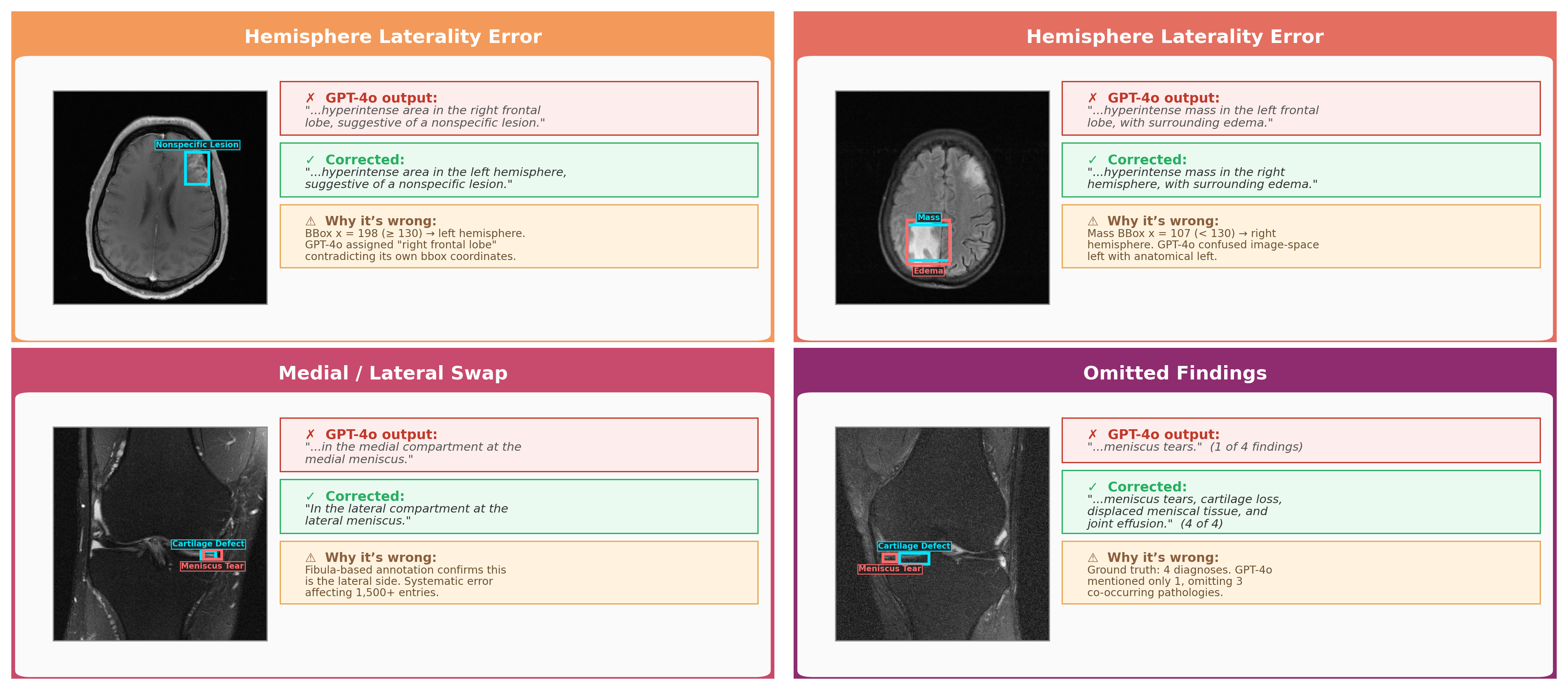
Figure 5: Typical hallucination errors in spatial reasoning—incorrect hemisphere and knee laterality, omission of findings.
Practical and Theoretical Implications
SGMRI-VQA sets a new standard for spatially grounded clinical VQA on 3D MRI, revealing a critical gap in current multimodal models: textual spatial reasoning is robust, but pixel-level spatial grounding remains weak. Domain-specific fine-tuning demonstrably improves spatial grounding precision, but large-scale spatially annotated medical datasets are necessary for substantial gains. The results suggest that current VLM training pipelines, even for large-scale proprietary systems, do not adequately address the spatial grounding requirements for volumetric medical imaging.
Practically, this benchmark and its domain-expert-aligned reasoning traces support reinforcement learning for clinical-grade reasoning and localization. The dataset provides a path toward explainable clinical co-pilots, integrating transparent spatial decision-making essential for trust in clinical deployments.
Theoretically, SGMRI-VQA strengthens the case for hierarchical, multi-modal task design reflective of real-world clinical workflows, where reasoning, localization, and diagnosis are entangled across a volumetric context.
Future work should prioritize:
- Expansion to additional anatomical domains and modalities
- Larger model scale evaluation (70B+ parameters)
- Integration of hierarchical reinforcement learning for spatially-grounded reward optimization
- Automated spatial annotation pipelines to support further scaling
Conclusion
SGMRI-VQA offers the first rigorous volumetric benchmark for spatially grounded reasoning in knee and brain MRI. Fine-tuned open-source VLMs outperform proprietary baselines, but spatial grounding remains a bottleneck. This work unlocks new directions for transparent, multimodal clinical AI with precise spatial grounding and executable chain-of-thought reasoning across 3D medical scans.