- The paper introduces a novel compositional approach that replaces global joint modeling with local, pairwise object relations for complex 3D scene generation.
- The methodology leverages point cloud geometric encoding and Transformer-based blocks to predict multi-modal, physically valid object placements.
- Experimental results demonstrate that Pair2Scene outperforms baseline models with lower FID/KID and higher scene complexity, ensuring efficient procedural generation.
Pair2Scene: A Relational Approach for Scalable Procedural 3D Scene Generation
Motivation and Context
Procedural generation of high-fidelity 3D indoor environments is a longstanding bottleneck in virtual world construction, particularly where semantically consistent, physically plausible complex layouts are targeted. Data-driven methods are fundamentally limited by the scale and distributional diversity of available datasets, while recent text-driven generative approaches leveraging LLMs/VLMs are generally ineffective at resolving fine-grained spatial relationships in dense scenes. The "Pair2Scene" framework (2604.11808) critiques the inefficiency of global joint distribution modeling and proposes instead a compositional approach grounded in explicit local (pairwise) rules that govern support and functional dependencies, leveraging asset geometry and hierarchical scene structure for physical consistency.
Methodology
A scene is decomposed into a sequence of relational tuples, each defining a dependent object, its mandatory support anchor, and an optional functional anchor. The scene is thus generated incrementally, where each new object placement is conditioned only on its relevant anchors, which have been (causally) generated prior in the sequence. The formulation models the conditional probability density for the dependent's placement—parameterized as a Mixture of Logistics (MoL) distribution—given the point cloud geometry of all involved objects and the spatial configuration of the anchors. This approach explicitly captures placement multi-modality (e.g., multiple valid chair positions relative to a table).
Model Architecture
The model architecture (Figure 1) processes the geometric asset clouds and bounding boxes for the dependent, support, and functional anchors. Point-MAE encoders extract latent geometric embeddings, and a sequence of cascaded Transformer-like blocks performs relational self-attention and geometry-aware cross-attention operations on learnable object tokens. This fuses spatial context and geometric priors, culminating in an MLP that outputs the parameters for the MoL distribution describing the dependent bounding box.
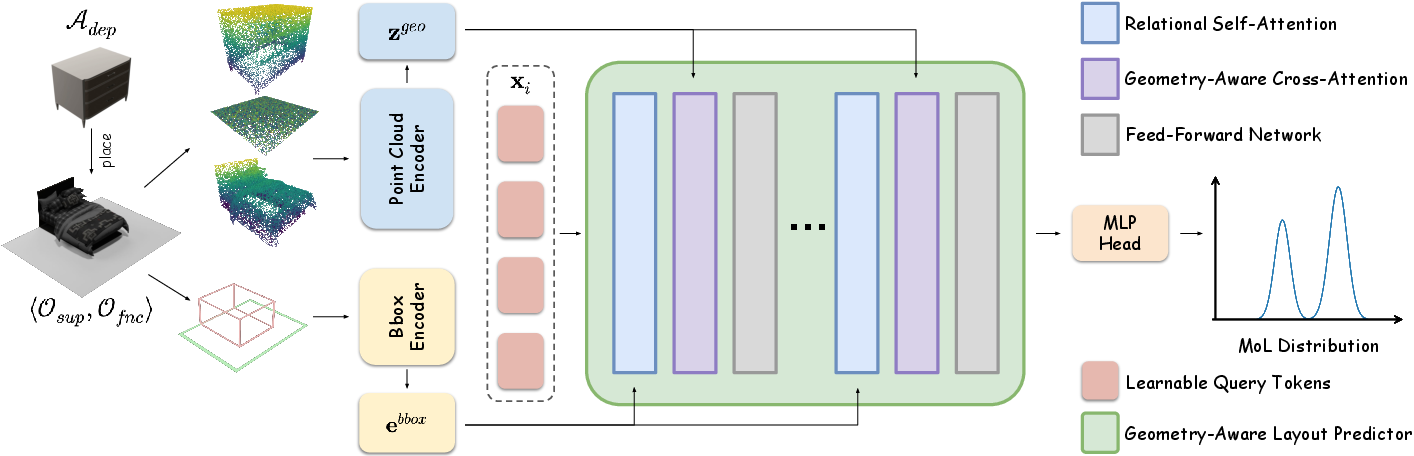
Figure 1: Pair2Scene architecture, combining geometric and spatial features from asset point clouds and anchor configurations to predict multi-modal local placement distributions via a Transformer-based pipeline.
Procedural Scene Assembly Pipeline
At inference, scene layout proceeds by:
- Parsing a prompt or room type into support and functional trees (hierarchical relational graphs).
- Serializing these trees into an ordered sequence of placement operations.
- Querying the trained local relation model for each dependent’s probable configurations given the anchors.
- Applying collision-aware rejection sampling and lightweight gravity simulation after each step to enforce global non-collision and physical plausibility.
This compositional generation approach is summarized in Figure 2.
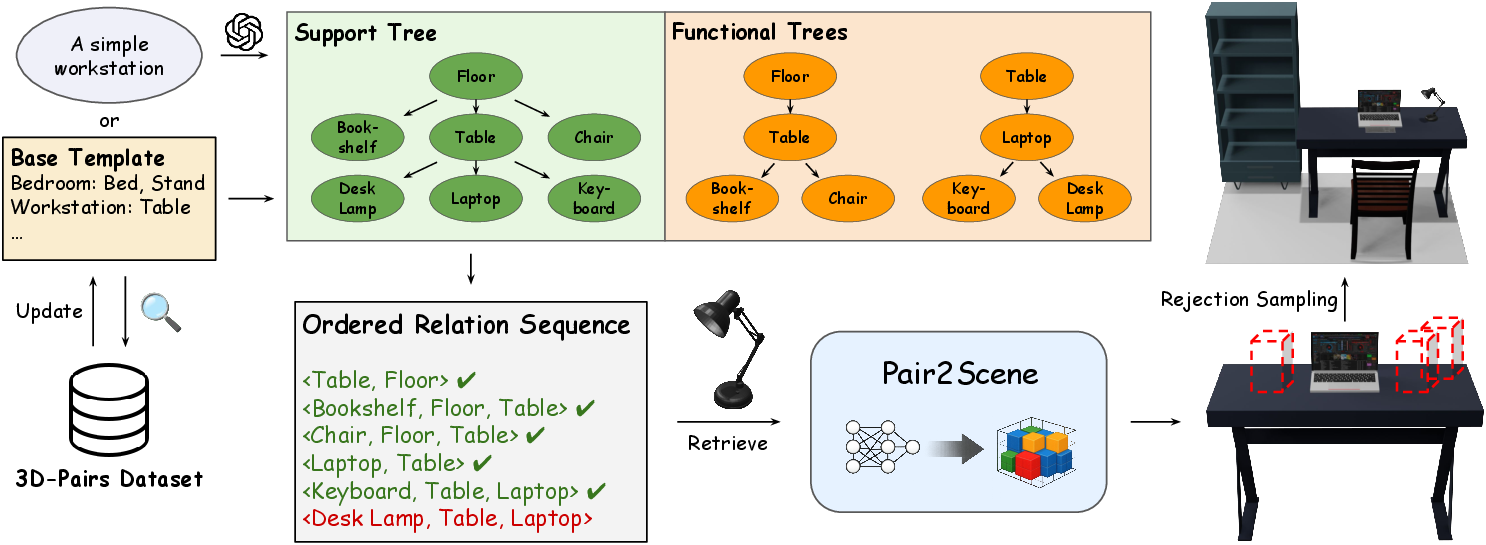
Figure 2: The full pipeline for scene assembly, from input parsing and hierarchy generation to sequential object placement and physical refinement via rejection sampling.
Data Curation and Relations Dataset
A critical foundation is the construction of a large-scale 3D-Pairs dataset. This involves:
- Rigorous physical validation and filtering of unstable/unrealistic objects within diverse 3D scene sources using rigid-body simulation.
- Heuristic support relation extraction via geometric analysis (proximity, enclosure).
- LLM-assisted extraction of functional relationships, further validated by bounding box intersection.
This pipeline (Figure 3) yields ~140,000 high-quality relational tuples, substantially increasing coverage and compositionality relative to previous datasets.
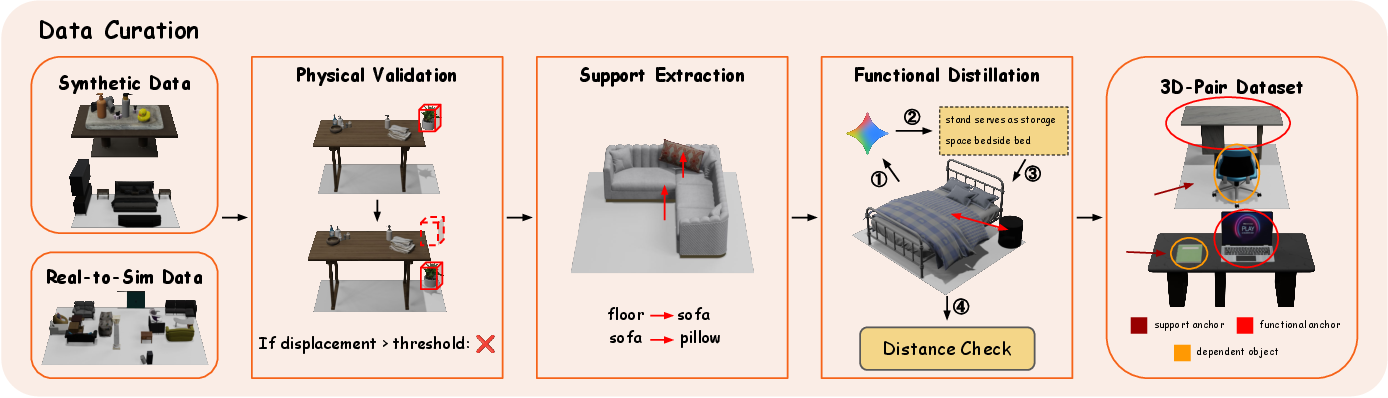
Figure 3: The data curation pipeline, integrating physical validation, support relation heuristics, and LLM-aided functional extraction to produce the 3D-Pairs dataset.
Experimental Results
Evaluation Protocol
Performance is quantified on two axes:
- 3D-Front only: The model's capacity to fit and generalize beyond a single dataset's distribution.
- Multi-source: Generalization to arbitrarily high-complexity scenes using all 3D-Pairs sources.
Metrics include FID and KID (computed over BEV renderings), user study evaluations (semantic alignment, physical plausibility, scene complexity), Mean Quality (MQ), and the Contextual Fidelity Score (CFS).
Quantitative and Qualitative Results
In constrained dataset settings, Pair2Scene (Ours-Fit) achieves the lowest FID/KID and best user study ratings against ATISS, DiffuScene, FactoredScenes, and LayoutVLM (see Table 1 and 2 in the paper). The procedural variant (Ours-Beyond) produces scenes of significantly higher object count and complexity, yet preserves physical and semantic integrity (scoring 5.12 MQ and 4.46 CFS vs. 4.3/2.05 for the best baseline).
Pair2Scene is uniquely capable of extrapolating beyond training distributions, producing rich, functionally dense layouts with minimal physical artifacts such as collisions or floating objects (Figure 4, Figure 5).

Figure 4: Qualitative comparison (3D-Front only), demonstrating the superior scene diversity and spatial logic of Pair2Scene relative to global and LLM/VLM-based baselines.

Figure 5: Qualitative comparison (multi-source), illustrating robust handling of high-density, multi-domain scenarios.
Ablation studies (Table 4 and Figure 6) show that omitting geometry encoding, learned local rules, or collision/gravity post-processing significantly degrades both distributional fit and physical correctness, demonstrating the necessity of each component.
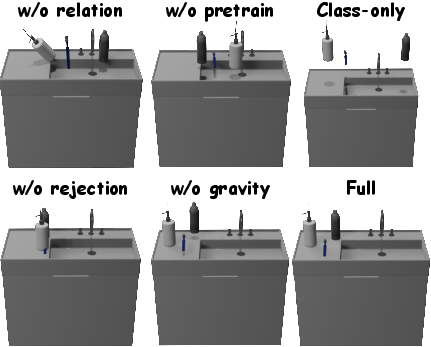
Figure 6: Ablation visualizations under the multi-source setting, highlighting failure modes when geometric priors or rejection/collision handling are removed.
Efficiency and Generalization
Inference analysis shows that Pair2Scene generates complex, high-density scenes orders of magnitude faster than procedural or LLM-only baselines (69s vs. up to 686s for Infinigen-Indoors), due to avoiding expensive global optimization or overly long autoregressive token streams.

Figure 7: Additional visualizations demonstrating generalization to novel scene categories outside original training distributions.
Theoretical and Practical Implications
The primary claim is that most of spatial scene generation can be reduced to a dense set of local rules. This model demonstrates that sampling from such compositional, geometry-aware local distributions, coupled with rigorous physical validation, suffices to generate globally coherent and semantically consistent environments. This breaks the over-reliance on global joint modeling that is intractable in highly populated scenes and allows for efficient generalization to complex, out-of-distribution scenarios. Extensions to the method could readily accommodate more complex relational structures or use additional sensory modalities (e.g., language-guided hierarchies).
Practically, this framework provides a strong foundation for simulation environments in embodied AI and robotics, where the diversity and plausibility of physical 3D world representations are critical for robust agent training.
Conclusion
Pair2Scene introduces a scalable, relational approach to procedural indoor scene generation, leveraging a large curated local-relations dataset, point cloud-based geometric modeling, and hierarchical procedural assembly. The approach yields scenes superior in semantic plausibility, physical validity, and complexity, while remaining computationally efficient and data-efficient. The decomposition into local rules with physical post-processing establishes a new paradigm for large-scale scene generation in simulation, gaming, and embodied intelligence. However, certain limitations remain in stylistic consistency and handling rare multi-anchored or hanging object relationships. Future research could address these by integrating style-aware object retrieval and more sophisticated relational graphs.