- The paper introduces EntCollabBench, a benchmark that evaluates role-specialized LLM systems in enterprise workflows by simulating 11 roles across 6 departments with strict access controls and objective metrics.
- It employs rigorous Workflow and Approval tracks to assess multi-step delegation, parameter validation, and stateful coordination in complex, permissioned environments.
- The benchmark reveals that even with high per-role success rates, end-to-end task accuracy remains low, underscoring the need for improved delegation, memory management, and cost-quality balancing.
Benchmarking Role-Specialized Multi-Agent Collaboration in Enterprise Workflows
Motivation and Positioning
The deployment of LLM-based agents in enterprise environments exposes a set of constraints rarely reflected in existing benchmarking: granular role specialization, access-limited systems, explicit delegation, and complex approval workflows. Existing paradigms largely focus on monolithic "all-in-one" agents with global authority and overbroad tool access, masking the distributed, permissioned, and stateful nature of real organizational work. While there exist benchmarks for single-agent settings in enterprise platforms (such as AgentBench, WorkArena, and EntWorld), and separate efforts focused on generic multi-agent cooperation, these paradigms omit the synthesis of both role constraints and enterprise business semantics (Figure 1).
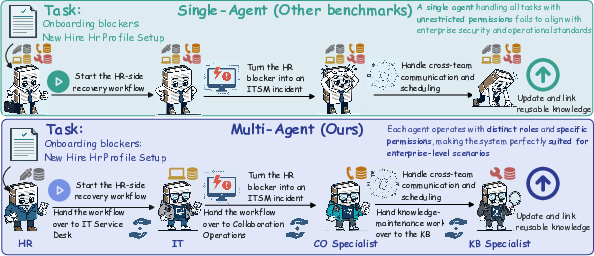
Figure 1: EntCollabBench compared with other enterprise benchmarks, highlighting its unique focus on cross-role specialization and permission-isolated collaboration.
EntCollabBench is introduced as a benchmark that operationalizes this gap by evaluating multi-agent LLM systems instantiated in a simulated 11-role, 6-department enterprise, contrasting with single-agent or communication-in-abstract schemes. It uniquely attaches each agent to specific scopes within realistic business systems, enforces access and identity controls, and evaluates the agents on objective, state-verifiable collaboration, rather than subjective, language-level response metrics.
Benchmark Design and Architecture
Task and Environment Construction
EntCollabBench comprises two primary evaluation tracks—Workflow and Approval—each designed to stress-test different operational and reasoning axes of enterprise work (Figure 2).
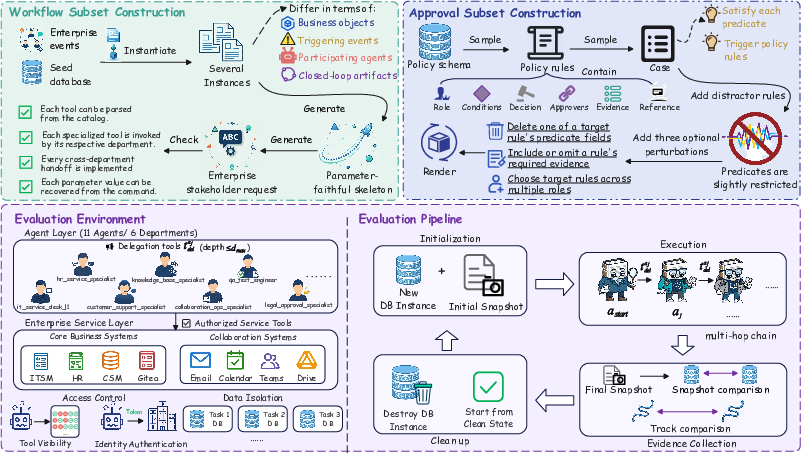
Figure 2: Schematic of EntCollabBench covering task generation, role-specialized agent ecosystem, access-controlled environment, and an objective multi-hop evaluation pipeline.
- Workflow Track: Agents execute complex, multi-step operational procedures (incident creation, HR processing, code review, etc.) across IT, HR, CSM, Engineering, and Shared Services departments. Each subtask is anchored to a stateful change in enterprise databases, evaluated by tracking explicit traces and system state deltas.
- Approval Track: Specialists in finance, legal, and procurement decide on business requests according to a structured, citation-grounded policy schema—decisions are evaluated against a deterministic engine, with granular audits of decision rationales and rule citation consistency.
Both tracks enforce role-specific tool visibility implemented at the protocol (MCP) and authentication level, and simulate enterprise systems with independent, seeded, per-task database snapshots to guarantee strong task isolation and reproducibility. Cross-role actions are only possible via explicit, content-rich delegation steps, requiring agents not just to plan actions but to perform accurate context transfer and downstream role routing.
- Dataset Composition: 300 tasks (160 workflow, 40 multi-task workflow, 80 approval, 20 multi-task approval) with at least two roles per task and, in the multi-step configuration, enforced three or more cross-agent delegations per instance.
Policy Grounding and Reproducibility
Approval tasks are generated from curated corpora (e.g., GitLab Handbook, GDPR articles) processed into a JSON schema with extractive, cross-referenced rule sets—enforcing strong grounding, deterministic evaluation, and cross-domain linkage. All instances are synthesized to include hard negative distractors, evidence document perturbations, and multi-stage cross-role adjudication to emulate real enterprise ambiguity and coordination requirements.
Evaluation Methodology
EntCollabBench's protocol is anchored in deterministic, objective evaluation, avoiding the common pitfalls of subjective human ratings or stochastic "pass/fail" event assignment.
Experimental Results and Analysis
Numerical Outcomes
- Benchmark Difficulty: The strongest open model, DeepSeek-V4-Pro, achieves only 62.00% average task accuracy, with closed-source Claude-Sonnet-4.6 at 52.67%. Most high-profile agents (including Gemini, GPT-5.4, Qwen series) remain below 50% on task-level end-to-end metrics.
- Local vs End-to-End: All models achieve significantly higher per-role pass rates (often over 80%) than end-to-end task success (frequently under 60%), precisely quantifying the systematic failure points in delegation, parameter transmission, and final-stage closure.
- Track-wise Observations:
- Approval tasks are easier in isolation (e.g., DeepSeek-V4-Flash scores 80.00% on single-step approval) but degrade significantly in multi-step settings (top accuracy: 40%), highlighting fragility in multi-role, multi-stage evidence tracking and decision commitment.
- Workflow multi-step tasks expose severe prefix decay—models like Qwen3.5-122B achieve high subtask success but low final-task accomplishment, often failing on ultimate handoff or parameter consistency (cf. Figure 2, case studies).
- Cost Dynamics: Models such as DeepSeek-V4-Pro sometimes achieve high robustness through proportionally extreme token and coordination expenditure (e.g., >8M tokens, hundreds of trace events for one successful task), demonstrating a nontrivial cost-quality trade-off.
Failure Modes and Analysis
Detailed trace studies reveal dominant failure axes:
- Delegation errors: Omission, insufficient context, premature, or poorly sequenced delegation is a primary error source—models repeatedly delegate before preconditions exist, with missing or misbound parameters.
- Tool parameterization errors: Model outputs often contain correct high-level intent but incorrect or default parameter values (wrong enums, status, relationships, assignment semantics), leading to silent propagation of semantic errors in downstream state.
- Chain-position fragility: Downstream agents (e.g., knowledge base specialists) fail disproportionately, owing to compounded upstream error, incomplete handoff, or instruction loss across roles.
- Approval-specific deficiencies: Models demonstrate weak decision commitment, especially open-source ones (e.g., MiMo-V2-Flash in approval settings)—some enter pathological document-reading loops, dramatically increasing context and failing to emit terminal decisions.
- Small model interface weakness: Smaller models (e.g., Qwen3.5-9B) often fail at tool-execution transition, defaulting to schema listing without progressing to action, or emitting pseudo-invocations in place of executable tool calls.
Implications and Future Directions
Practical Impact
The empirical bottlenecks identified by EntCollabBench have concrete ramifications for deploying agentic systems in enterprise:
- Naive "all-in-one" prototypes do not transfer to real multi-role, access-controlled settings. Effective real-world automation demands strong delegation, precise permission handling, and robust context management at both the operational and reasoning interface.
- Inadequacy of surface-level tool invocation benchmarking: The bottleneck lies not in tool exposure, but in multi-hop parameter and responsibility alignment.
- Coordination cost may scale nonlinearly: Robustness can be purchased at prohibitive context and communication cost, raising concerns for both scalability and usability.
Theoretical Significance
EntCollabBench concretizes multi-agent, multi-role planning as a sequential, stateful collaboration challenge, exposing the necessity for advances in:
- Explicit planning and memory management: Models require advances in memory summarization, context compression, and stateful responsibility transfer to scale reliably.
- Explicit protocol schema handling: Tool and delegation interfaces must be treated as first-class citizens, with systematic grounding and enforcement of parameter semantics.
- Adaptive cost-quality control: Balancing correctness and communication overhead will become critical.
Future Prospects
Closing the observed accuracy gap will likely require architectural innovation beyond mere scaling. Potential directions include:
- Hierarchical planning modules with explicit role and delegation reasoning.
- Hybrid neural/symbolic delegation and parameter-validation systems.
- Advanced interface co-design between business system APIs and LLM-action realization modules.
Furthermore, integrating real-time learning from failed execution traces and environment-driven repair/replanning is essential for further improvements.
Conclusion
EntCollabBench marks a significant advance in the empirical study of multi-agent LLM systems under enterprise constraints. By moving beyond single-agent, globally-permissive evaluation paradigms, it enables precise diagnosis of the current limitations in routing, delegation, parameter grounding, and workflow closure present in existing foundation models. Objective, trace-based, and policy-grounded evaluation offers actionable directions for both algorithmic and systems research, laying the groundwork for future robust agentic orchestration in complex organizational environments.