Deterministic Fully-Static Whole-Binary Translation without Heuristics
Abstract: We present Elevator, the first binary translator that statically translates entire x86-64 executables to AArch64 without debug information, source code, or assumptions about code layout. Unlike existing systems, which rely on heuristics or runtime fallbacks to handle code-versus-data decoding errors, Elevator considers all possible interpretations of every byte and produces a separate translation for each feasible one ahead of time. Any byte may be interpreted as data, an opcode, or an opcode argument; we generate separate control flow paths for all interpretations, pruning only those leading to abnormal termination. Translations are built by composing code "tiles" automatically derived from a high-level description of the source ISA, yielding a nimble translation framework. The approach is deterministic and produces complete, self-contained binaries with no runtime component in the trusted code base. The principal cost is substantial code size expansion. The key benefit is that the output is the actual code that will run, enabling testing, validation, certification, and cryptographic signing prior to deployment, reducing risk compared to emulators or JIT compilers. We evaluate Elevator on a diverse corpus of real-world binaries, including the entire SPECint 2006 suite, demonstrating that static full-program binary translation can be both reliable and practical. Elevator achieves performance on par with or better than QEMU's user-mode JIT emulation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Elevator, a tool that can take a program made for one kind of computer chip (x86-64, common in many PCs) and turn it into a program that runs on a different kind of chip (AArch64, used in many phones and newer laptops) — without needing the original source code, without guessing, and without any extra helper software when it runs. The key idea is to prepare every possible valid way the old program could be read and then translate all of those possibilities ahead of time. The result is a single, self-contained program you can test, trust, and even digitally sign before deployment.
What questions are the authors trying to answer?
The paper focuses on simple but tough questions:
- Can we reliably convert a full program from one chip’s “language” to another, using only the finished executable (not the source code)?
- Can we do this without “guessing” where the code is and where the data is, which usually causes errors?
- Can we make the translation fully static (no just-in-time tricks, no emulators) so the final program is exactly what will run?
- Can this be fast enough and robust enough for real-world software?
How did they do it? (Methods in everyday terms)
Think of a program’s file like a long string of bytes. Some bytes are instructions (code), and some are just numbers or letters (data). On x86-64, instructions can start at many places and have different lengths. It’s like a sentence with no spaces: if you start reading at different positions, you can get different words. Most tools guess where the words start. Elevator doesn’t guess.
Here’s the core approach explained with simple analogies:
- The big problem: separating code from data
- In many old programs, code and data are mixed, and instructions have variable length. Deciding “this byte is code, that one is data” perfectly is like solving a famous impossible puzzle (related to the Halting Problem). Heuristics (educated guesses) sometimes work but can silently fail.
- Their idea: translate all reasonable paths (no guessing)
- Imagine a maze where you’re not sure which paths are real. Elevator draws every path that could be valid and prepares translations for all of them. It removes only the paths that clearly lead to a dead end (like an immediate crash). This technique is called “superset disassembly”: include every feasible way of reading the bytes as code.
- Building with Lego-like pieces (“tiles”)
- Instead of hand-writing translations for every instruction, the authors describe what each x86-64 instruction does using tiny C functions. Then they use the LLVM compiler to pre-build a “tile bank” — a big box of ready-made AArch64 snippets, each snippet being the translation of one specific instruction form (like “add this register to that register”).
- When Elevator translates a program, it picks the right tiles and snaps them together to form the new executable. This keeps the process clean, consistent, and easier to maintain.
- Keeping the program’s “state” 1-to-1
- Each x86-64 register (the CPU’s small fast storage) is mapped to a specific AArch64 register. Think of it like keeping everyone’s name tags when switching classrooms, so you always know who’s who. This allows each instruction to be translated independently, because the expected inputs and outputs are always in the same places.
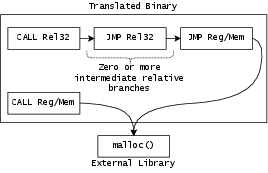
- Handling jumps and function calls (even the tricky ones)
- Programs jump around: sometimes to a known address (“go to line 100”), sometimes to a computed one (“go to the place in this table”). Elevator builds a lookup table that maps old addresses to new addresses, so even when a jump target is decided at runtime, it can quickly find the right place in the translated program.
- When the program calls into outside libraries (like standard C libraries), the two worlds have different rules for how to pass arguments and return values (called the ABI). Elevator includes small “border control” steps that rearrange the arguments and return values correctly when crossing from translated code (pretending to be x86-64) to real AArch64 libraries, and back again.
- Packaging the final program
- The output is a normal AArch64 executable with:
- The translated code (built from tiles).
- A copy of the original x86-64 binary as read-only data (not executable).
- The address lookup table (old → new addresses).
- A tiny driver that sets memory protections and handles special cases (like catching attempts to run the old code and redirecting to the right translated spot).
What did they find, and why is it important?
Here are the main takeaways from their tests on real-world software, including the full SPECint 2006 suite:
- It works on entire, complex programs
- Elevator can handle full programs, not just small examples, and does not rely on lucky guesses. This is a big step because many earlier static tools struggled to process large real programs reliably.
- It’s fully static and deterministic
- The exact same input always produces the exact same output. No just-in-time steps, no hidden runtime translators. That means the final program can be tested, validated, certified, and even cryptographically signed before it’s deployed, which lowers risk.
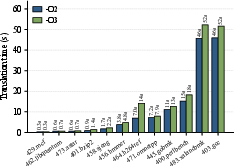
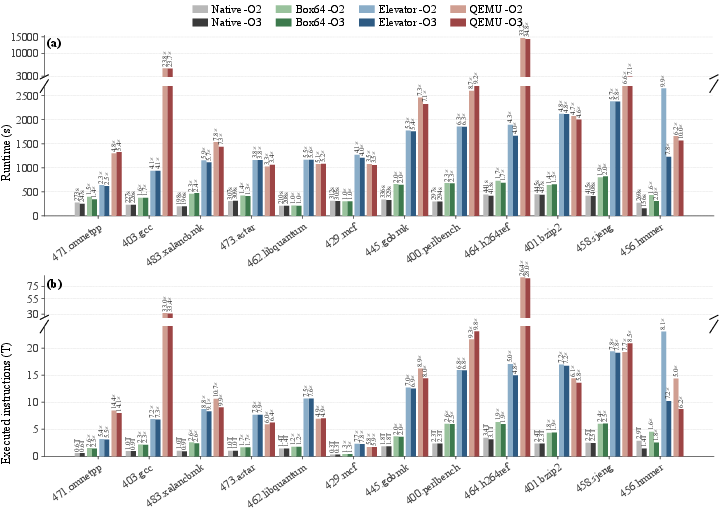
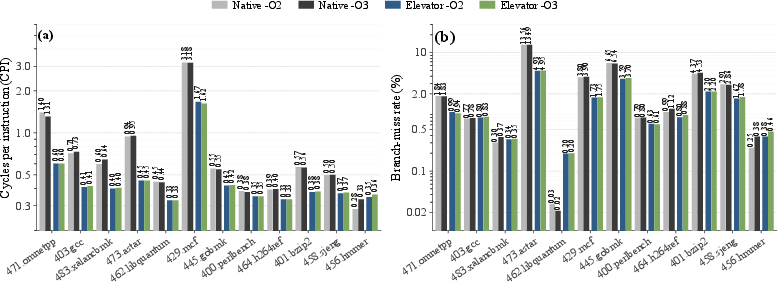
- Performance is competitive
- The translated programs run about as fast as, or sometimes faster than, QEMU’s user-mode emulation with JIT. That’s impressive for a fully static approach.
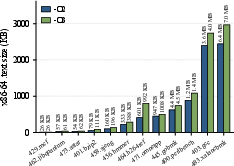
- The trade-off: bigger code size
- Because Elevator keeps many possible paths to avoid guessing, the output program can be noticeably larger. In many safety- or reliability-focused settings, that’s an acceptable cost.
This is important because organizations often need to keep old, trusted software running on new hardware. Sometimes the original source code is lost, or the exact build tools no longer exist, or the binary has been manually patched. Elevator lets you move that exact binary to a new architecture safely.
What’s the potential impact?
- Safer migration across chip architectures
- If a company needs to move from x86-64 machines to AArch64 machines (for speed, power, supply-chain, or policy reasons), Elevator can help them bring their existing, officially approved binaries along without rebuilding from source.
- Better testing and certification
- Since the translated program is exactly what will run, you can test it thoroughly ahead of time. That’s less risky than using emulators or just-in-time translators that might behave slightly differently depending on timing or inputs.
- A new tool in the toolbox
- Elevator doesn’t replace all methods; it offers a different balance: more static reliability in exchange for a larger output. In cases where safety, predictability, and certification matter most, that’s a powerful option.
In short, this paper shows that fully static, no-guess, whole-program translation from x86-64 to AArch64 is not only possible but practical at scale. It opens a safer path to keep trusted software alive on modern hardware.
Knowledge Gaps
Below is a single, actionable list of knowledge gaps, limitations, and open questions left unresolved by the paper. Each item identifies a concrete area for future work or clarification.
- Memory addressing semantics: precisely define how arbitrary x64 memory accesses (including absolute addresses, RIP-relative operands, and pointers embedded in data structures) are mapped to the embedded x64 image; explain handling under ASLR/PIE and pointer provenance across the translated/native boundary.
- Statically linked binaries and direct syscalls: add support (or document the limitation) for statically linked executables and binaries that invoke SYSCALL directly, including syscall number translation and architecture-dependent struct/ioctl layouts.
- ISA coverage completeness: extend beyond “full x86-64 integer ISA and the SSE subset exercised by SPECint” to include x87 FPU, SSE4.x, AVX/AVX2/AVX-512, BMI/BitOps, XSAVE/XRSTOR/XGETBV, RDTSC/RDTSCP, string instructions with REP/segment overrides, BCD, and other special cases; deliver verified tiles for LOCK-prefixed atomics and MFENCE/LFENCE/SFENCE.
- Memory model correctness: specify and implement a faithful mapping from x86 TSO to AArch64’s weaker memory model for multi-threaded programs (barriers, atomic RMW semantics), and validate on concurrency litmus tests and stress benchmarks.
- TLS and segments: provide a complete treatment of FS/GS-based thread-local storage on x64 and its translation to AArch64 TLS; verify with pthreads and libraries that rely on TLS or segment-relative addressing.
- Signals and exceptions: detail how synchronous exceptions and signals raised inside translated code map to x64 semantics (signal numbers, siginfo/ucontext), and how this interacts with the NX-based signal handler used for callback detection to avoid conflating genuine faults with interception.
- C++ exceptions and unwinding: support exception propagation and stack unwinding across translated/native frames, including generation of unwind metadata, preservation of CFA rules, and correct cross-ABI interaction with libunwind and language runtimes.
- setjmp/longjmp and stack probing: clarify support and correctness for non-local control flow and stack probing in the presence of SP alignment adjustments and tile spill behavior.
- Multi-threading and reentrancy: analyze and test thread-safety of the runtime driver, signal handler, lookup-table usage, and ABI gadgets under concurrent execution, signals, and callbacks from multiple threads.
- Code-size expansion: quantify worst-case and average expansion (codesize, I/D-cache/TLB impact, veneer insertion rates) and explore systematic mitigations (tile deduplication, outlining, profile-guided pruning that preserves determinism).
- Superset disassembly scalability: provide algorithmic complexity, memory usage, termination guarantees, and formal criteria for “pruning paths that lead to exceptional termination”; offer proofs or invariants for completeness vs over-approximation.
- Emulated RIP handling: document how RIP is represented and advanced inside tiles, especially for instructions that read/write RIP (e.g., call/pop idioms, LEA) and RIP-relative memory operands; include tests that cover overlapping/nested decodes with RIP-relative addressing.
- Tile semantics and flags verification: supply formal/mechanized validation (e.g., SMT, differential testing vs a reference x86 emulator) of arithmetic/logic semantics and flag updates (carry/overflow, shifts/rotates-through-carry, condition codes).
- Vector register mapping: specify the exact reservation and callee-save behavior of AArch64 NEON registers for emulated XMM/YMM state and how LLVM is constrained to avoid unintended clobbering or spills.
- Tile-bank footprint and build-time: report the number of specialized tiles, total bank size, compilation time, and storage; investigate compression or on-demand tile synthesis to limit offline costs.
- ABI translation coverage: go beyond varargs (vsprintf/vsprintf_chk) to systematically catalog and translate architecture-dependent interfaces (ioctl families, stat*/time types, getcontext/swapcontext, epoll/futex, long double differences), and address the hard limit on maximum call arguments (n).
- Indirect branch/callback overheads: measure and optimize overheads of lookup-table resolution and NX-based external callback interception (caching, branch predictor behavior, contention under heavy callback use).
- Function pointer representation: clarify how exported symbols and function pointers handed to external libraries are represented (original x64 address vs translated tile address) and ensure correctness with dlsym/bind-time relocation, PLT/GOT, and symbol visibility.
- Self-modifying code and JITs: document limitations and potential support strategies for binaries that modify/execute code regions (packers, JITs), given the embedded original is marked non-executable.
- Architecture-dependent data layouts: expand coverage beyond va_arg for differences such as long double format/size, packed/bitfield structs, atomic types, and ABI-specific alignments; validate marshaling at the boundary.
- ASLR/PIE and dlopen: explain how PIE/ASLR are handled for the embedded image and lookup table, and how addresses and relocations remain correct when shared objects are dlopen’ed at runtime.
- REP string ops and fault semantics: describe precise handling of REP-prefixed instructions, including fault restart semantics and signal interactions (e.g., page faults mid-stream) consistent with x86 behavior.
- Broader evaluation: assess correctness and performance on diverse workloads beyond SPECint 2006 (e.g., SPEC CPU 2017, FP/vector-heavy apps, servers, GUI), including binaries that exercise advanced vector and floating-point features.
- Cross-ISA/OS portability: map required changes to support other source/target ISA pairs (e.g., x86-64→RISC-V, ARM→x86-64) and other ABIs/OSes (Windows x64, macOS), identifying ISA/ABI features that impact TileGen and the runtime.
- Determinism across toolchains: document controls for reproducible builds and deterministic output across LLVM/LLD versions and environments (hash seeds, pass ordering, linker behavior), and provide artifacts/tests.
- Security considerations: analyze whether superset-translation increases gadget availability or attack surface, and evaluate the robustness/hardening of the signal-handler interception mechanism under adversarial inputs.
- Red zone and stack conventions: clarify handling of the x86-64 SysV red-zone vs AArch64 conventions, and whether tiles or ABI gadgets rely on or disable the red zone.
- CFG layout heuristics: quantify the impact of greedy tile merging and placement heuristics on performance/locality and explore more principled, deterministic layout strategies (e.g., graph partitioning) to improve cache behavior.
Practical Applications
Immediate Applications
The following applications can be deployed now, drawing directly from the paper’s deterministic, fully static x86-64 → AArch64 translation and superset-disassembly approach. Each item notes relevant sectors, possible tools/workflows, and feasibility assumptions.
- Port legacy x86-64 Linux software to ARM servers without source
- Sectors: software, cloud, enterprise IT
- Use case: Move proprietary or abandoned x86-64 applications and services to AArch64 infrastructure (e.g., AWS Graviton, Azure Ampere) when source is missing or not reproducible; replace ad‑hoc QEMU user-mode emulation with stand-alone binaries that can be tested and signed.
- Tools/workflows: CI/CD step to run Elevator on x86-64 artifacts; automated test suites; artifact signing; deployment to ARM fleets.
- Assumptions/dependencies: Input must be a dynamically linked Linux x86-64 binary; currently covers full integer ISA and SSE subset (as exercised by SPECint); external libraries must be available on AArch64; expect code-size expansion and performance roughly on par with QEMU user-mode.
- Maintain “authoritative binary” behavior under certification constraints
- Sectors: healthcare, aerospace, automotive, industrial control
- Use case: Preserve certified x86-64 binary semantics after an ARM hardware refresh; test and certify the exact AArch64 code that will run, reducing runtime TCB vs. JIT/emulators.
- Tools/workflows: Translation pipeline + regression/acceptance suites; cryptographic signing and audit trail linking original → translated binary; compliance documentation (e.g., IEC 62304, DO-178C).
- Assumptions/dependencies: Regulators may require evidence of equivalence; dynamic linking requirement; memory footprint increase; careful review of ABI interception stubs (e.g., varargs) in the certification package.
- Supply-chain and geopolitical risk mitigation for CPU availability
- Sectors: government, critical infrastructure, finance, energy, telecom
- Use case: Rapidly retarget mission-critical x86-64 applications to ARM when x86 hardware becomes constrained or prohibited; pre-translate and stage signed binaries for continuity plans.
- Tools/workflows: Business continuity playbooks; pre-translation catalog for critical services; periodic drills to validate translated images.
- Assumptions/dependencies: Availability of equivalent AArch64 OS and libraries; legal/IP permissions to translate binaries.
- Reduce trusted computing base and attack surface versus dynamic translation
- Sectors: cybersecurity, defense, regulated IT
- Use case: Replace large runtime emulators/JITs with statically translated binaries that can be audited; enforce non-executable embedded x86-64 segments; sign outputs.
- Tools/workflows: Security review of translation driver and signal handler; SBOMs for translated artifacts; vulnerability scanning and SAST/DAST run on the AArch64 output.
- Assumptions/dependencies: Deterministic output enables reproducible builds; code-size growth may increase audit effort; ABI shims (e.g., va_arg rewrites) must be scrutinized.
- Cloud/container modernization without emulation in production
- Sectors: cloud/SaaS, DevOps
- Use case: Translate x86-64 binaries inside container images for ARM-native deployments; improve cold-start and reduce unpredictable emulation paths; provide multi-arch images with genuine ARM executables.
- Tools/workflows: Build-time translation in Docker/OCI pipelines; image validation tests; multi-arch registries.
- Assumptions/dependencies: Dynamic libs must exist in ARM base image; syscalls go through libc; limitations for AVX-heavy workloads.
- Software preservation and digital archaeology
- Sectors: archives, museums, academia
- Use case: Keep historical x86-64 applications runnable on ARM hardware for exhibitions and studies; store both original and translated binaries with provenance.
- Tools/workflows: Artifact repositories with metadata linking original ↔ translated; reproducibility records; checksum/signature registries.
- Assumptions/dependencies: Dynamic linking; practical for CLI/utility software; complex multimedia apps may depend on unsupported SIMD.
- Robust platform for teaching and research in binary translation and program analysis
- Sectors: academia, R&D labs
- Use case: Use Elevator’s tile-bank design and superset CFG to teach cross-ISA semantics, lifting, and rewriting; run experiments without heuristics confounding results.
- Tools/workflows: Course labs, reproducible research baselines; extending tiles for instruction coverage studies.
- Assumptions/dependencies: Current scope (Linux x86-64 → AArch64; SSE subset) is adequate for many curricula; not yet suitable for Windows or AVX-centric courses.
- Resilient handling of obfuscated control flow for binary analysis
- Sectors: security research, reverse engineering
- Use case: Analyze binaries with overlapping instructions or computed branches (e.g., ROP-like or obfuscated code) on ARM hosts; superset disassembly ensures valid landing points exist at translation.
- Tools/workflows: Static/dynamic analysis of translated code; CFG exploration; test harnesses to surface rare paths.
- Assumptions/dependencies: Best fit for dynamically linked samples; statically linked malware often uses arch-specific instructions (needs future support); legal constraints for malware handling.
Long-Term Applications
These applications require additional instruction coverage, OS/ABI support, scaling, or formal assurance beyond the current prototype.
- Full SIMD/FPU and modern vector ISA coverage
- Sectors: HPC, media, gaming, scientific computing
- Use case: Translate AVX/AVX2/AVX-512/FMA-heavy x86-64 applications to ARM NEON/SVE equivalents with competitive performance.
- Tools/workflows: Expanded tile bank for advanced SIMD; auto-vectorization mapping; performance benchmarking suites.
- Assumptions/dependencies: Significant engineering for correctness and performance; mapping semantics across different vector widths/flags.
- Support for statically linked binaries and direct syscall/CPUID handling
- Sectors: embedded, security research, forensics
- Use case: Translate self-contained x86-64 executables (common in malware and appliances) and correctly emulate/translate CPU-specific instructions.
- Tools/workflows: Syscall translation layer; CPUID emulation/patching; static relocation handling.
- Assumptions/dependencies: Larger runtime driver; OS-specific behaviors; increased TCB unless minimized.
- Cross-OS/ABI and multi-ISA generalization (e.g., Windows x64 → ARM64, Linux x86-64 → RISC-V)
- Sectors: desktop, enterprise IT, cross-platform products
- Use case: Portable, static cross-ISA translation across operating systems and targets (Windows, macOS, Linux; ARM, RISC-V).
- Tools/workflows: Additional ABI shims (SEH/PE for Windows, Mach-O for macOS); expanded LLVM backends; tile templates per ISA pair.
- Assumptions/dependencies: Legal/IP considerations; OS loader/relocation paradigms; wide matrix of library/ABI behaviors.
- Package-manager and app-store integration (“translate-on-install”)
- Sectors: Linux distributions, enterprise IT, device app stores
- Use case: Auto-translate x86-64 packages during installation on ARM devices; deliver signed ARM-native binaries instead of bundling emulators.
- Tools/workflows: Distro build hooks (apt/yum/pacman); translation caching; failure fallbacks to emulation; policy controls.
- Assumptions/dependencies: Scale-out build infrastructure; quality gates and test coverage; license compliance for translation.
- Formal verification and proof-carrying translation
- Sectors: safety-critical systems, high-assurance computing
- Use case: Machine-checked proofs that tiles preserve x86-64 semantics; certification artifacts for regulators.
- Tools/workflows: Formal specs for x86-64/AArch64 instructions; verified compilers/solvers; proof artifacts bundled with binaries.
- Assumptions/dependencies: High engineering and verification costs; acceptance by certification authorities.
- Performance-focused variants with superset-graph pruning and PGO
- Sectors: cloud, performance-sensitive services
- Use case: Reduce code size and improve hot-path performance by pruning unreachable superset paths based on profiling; optimize flag tiles and register allocation.
- Tools/workflows: Profile-guided translation; multi-stage builds (conservative → pruned); differential testing for equivalence.
- Assumptions/dependencies: Must maintain determinism guarantees for certified builds; robust path-coverage strategies.
- Security instrumentation and CFI in the translated output
- Sectors: cybersecurity, critical infrastructure
- Use case: Insert defenses (CFI, shadow stacks, bounds checking) during translation, producing hardened ARM binaries with reduced gadget surfaces.
- Tools/workflows: Instrumentation passes on tiles; policy-driven hardening profiles; red-team validation.
- Assumptions/dependencies: Overheads from instrumentation; correctness of inserted checks; coordination with ABI stubs.
- Enterprise “Binary Portability Platform” productization
- Sectors: enterprise IT, managed services
- Use case: A managed service that translates, tests, signs, and distributes ARM-native binaries from x86-64 artifacts at scale; dashboards for compliance and performance.
- Tools/workflows: Multi-tenant builders; automated test and verification pipelines; artifact registries and SBOMs.
- Assumptions/dependencies: Operational maturity, SLAs, and governance; cross-license rights for translation; customer data protections.
- Mobile and consumer device compatibility for legacy desktop apps
- Sectors: consumer software, education
- Use case: Offer static ARM-native builds of legacy x86-64 Linux apps on ARM laptops/tablets/phones without runtime emulators.
- Tools/workflows: App-store pipelines with translation and validation; sandboxing; UX telemetry for compatibility reporting.
- Assumptions/dependencies: Broader instruction support; GUI/multimedia stack availability on ARM; licensing constraints.
- Hardware/OS integration for faster indirect target resolution
- Sectors: CPU vendors, OS platforms
- Use case: OS or hardware assist for address-lookup tables and signal-based callback detection to lower overheads of superset translation.
- Tools/workflows: Kernel support for execute-only segments and fast signal paths; optional ISA extensions for translation tables.
- Assumptions/dependencies: Vendor and kernel collaboration; long lead times; cross-platform standardization.
- Training data and benchmarks for reverse engineering and obfuscation studies
- Sectors: academia, security R&D
- Use case: Use superset-CFG artifacts to benchmark code-versus-data ambiguity handling and evaluate de-obfuscation tools.
- Tools/workflows: Curated datasets from translated binaries; metrics for path coverage and correctness; shared research corpora.
- Assumptions/dependencies: Community governance; licensing of sample binaries; reproducibility frameworks.
Common Dependencies and Assumptions Across Applications
- Current scope: Linux x86-64 user-mode, dynamically linked binaries; AArch64 target; integer ISA + SSE subset used by SPECint; not yet AVX/AVX2/AVX-512.
- ABI transitions rely on available AArch64 versions of external libraries; syscall behavior goes through libc.
- Output binaries grow substantially in size due to superset disassembly; ensure sufficient memory/storage.
- Signal-based callback detection assumes OS support (e.g., POSIX signals) and non-executable embedded x86-64 segments.
- Legal/IP: Translating third-party binaries may be restricted by license/EULA; compliance review is required.
- Acceptance: Safety/regulated sectors may require additional evidence (tests, proofs) of semantic equivalence.
Glossary
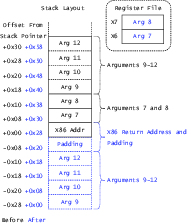
- AAPCS64: The AArch64 Procedure Call Standard defining the calling convention, register usage, and ABI details for 64-bit ARM. Example: "An x64 register that is callee-saved under System~V maps to an AArch64 register callee-saved under AAPCS64, and symmetrically for caller-saved registers, so that calls into AAPCS64 libraries preserve emulated x64 state across the boundary."
- AArch64: The 64-bit ARM instruction set architecture used as the translation target. Example: "We present Elevator, the first binary translator capable of statically translating entire x86-64 binary executables to AArch64 without using debug information..."
- ABI: Application Binary Interface; the low-level interface between two binary program modules (e.g., a program and the OS or libraries), encompassing calling conventions, data types, and register usage. Example: "Rather than analyzing the application binary interface (ABI) of the input x64 binary, Elevator performs ABI translation only when execution transitions to and from external code;"
- Address-lookup table: A mapping from original code addresses to translated code addresses, used to resolve indirect control transfers. Example: "the address-lookup table that the runtime uses to resolve computed indirect branches,"
- BAP IL: The intermediate language of the Binary Analysis Platform (BAP), designed for binary analysis and lifting. Example: "Binary Analysis Platformâs (BAP) IL~\cite{brumley2011bap}"
- Binary lifting: Translating machine code to an intermediate representation to enable analysis or recompilation. Example: "binary lifting with cross-compilation"
- Binary rewriting: Modifying binaries without source code to instrument, optimize, or transform them. Example: "binary rewriting and aims to enable the application of various program transformations to a programâs binary form."
- Callee-saved register: A register that a called function must preserve across calls under a given calling convention. Example: "An x64 register that is callee-saved under System~V maps to an AArch64 register callee-saved under AAPCS64,"
- Caller-saved register: A register that a calling function must assume may be overwritten by the callee and thus save if needed. Example: "and symmetrically for caller-saved registers,"
- Calling convention: Rules that define how functions receive parameters, return values, and use registers. Example: "hand-written C tiles compiled through LLVM with a custom calling convention,"
- Computed indirect branch: A branch whose target address is computed at runtime rather than encoded directly. Example: "Listing~\ref{lst:weird-branch} illustrates a computed indirect branch:"
- Control-flow graph (CFG): A graph representation of all paths that might be traversed through a program during its execution. Example: "represent the input as a superset control-flow graph (CFG), derived byte by byte from the original binary,"
- CPUID: An x86/x64 instruction that queries processor capabilities. Example: "architecture-specific instructions such as CPUID,"
- Direct branch: A control transfer with a statically encoded target address in the instruction. Example: "Direct branches encode their target as an immediate offset relative to RIP, so the target is known at translation time."
- Dynamic binary translation: Translating code during execution rather than ahead of time, often with caching and profiling. Example: "a hybrid dynamic binary translation approach that performs some instruction translation ahead-of-time while translating others dynamically upon first discovery"
- ELF: Executable and Linkable Format, the standard binary format on Unix-like systems. Example: "into a stand-alone ELF executable."
- Gadget: A small code sequence used here as a stub for ABI transitions (distinct from ROP gadgets). Example: "we install the address of a reverse ABI-translation gadget in X30"
- Global Offset Table (GOT): A table used by position-independent code to resolve addresses of global symbols at runtime. Example: "resolving external library symbols and populating GOT entries."
- Intermediate representation (IR): A machine-independent code form used internally by compilers and analysis tools. Example: "Full-translation techniques, on the other hand, usually translate programs to specialized intermediate representations (IRs) and eventually reassemble a new binary."
- Just-in-time (JIT) compiler: A runtime compiler that translates code during execution for performance or portability. Example: "emulators or just-in-time (JIT) compilers."
- LLD: LLVM’s linker, used to place symbols and perform relocations. Example: "The symbols are passed to the linker (LLD), which places them into the final executable and adds relocations to the x64-offset-to-tile lookup table with the final tile positions."
- Linker veneer: A small stub the linker inserts to extend branch reach when the target is out of range. Example: "and inserts a veneer if the 26-bit range is exceeded."
- Procedure Linkage Table (PLT): A mechanism used by dynamically linked ELF binaries to resolve external symbol addresses lazily at runtime. Example: "processing PLT relocations,"
- Register allocator: The compiler component that assigns program variables to physical registers. Example: "as callee-saved inside the register allocator,"
- REIL: Reverse Engineering Intermediate Language, an IR designed for analyzing binary code. Example: "and REIL~\cite{dullien2009reil}."
- Return-oriented programming (ROP): An exploit technique that chains short instruction sequences ending in returns to perform arbitrary computation. Example: "``return-oriented programmingââ (ROP) attacks~\cite{schacham07geometry}"
- RFLAGS: The x86/x64 flags register holding condition codes like Zero, Sign, Carry, and Overflow. Example: "The x64 ADD Reg8, Reg8 instruction also affects the RFLAGS register,"
- Shadow state: Additional reserved registers or storage used to hold emulated or auxiliary architectural state. Example: "we keep the surplus free for future shadow state without perturbing the existing mapping."
- Signal handler: A function invoked in response to a hardware or OS signal, used here to intercept illegal execution attempts and perform ABI transitions. Example: "Elevator solves this by installing signal handlers that catch attempts to execute code within the embedded original x64 binary,"
- Superset disassembly: Disassembling every byte offset as a potential instruction start to avoid committing to code-versus-data decisions. Example: "This is an application of the concept of superset disassembly"
- System V x64 ABI: The calling convention and ABI standard for 64-bit Unix-like systems on x86-64. Example: "The System V x64 ABI (used by x64 Linux) designates six registers, RDI, RSI, RDX, RCX, R8, and R9, as argument registers,"
- Tail call: An optimized function call that reuses the caller’s stack frame, often compiled as a jump. Example: "the latter typically arises when a call to an external library at the end of a function is optimized into a tail call,"
- Tile bank: A library of precompiled code snippets (“tiles”) representing instruction semantics, reused across translations. Example: "constructs a reusable tile bank: a set of precompiled AArch64 byte sequences, one for every concrete combination of an x64 instruction and its operand registers."
- Trampoline: A small code snippet used to redirect control flow or transition between contexts. Example: "Direct and minimally-invasive schemes target specific tasks such as diverting control flow, inserting trampolines, or performing instruction-level modifications."
- User-mode emulation: Emulating a foreign ISA at the user process level (not full-system), often with dynamic translation. Example: "QEMU's user-mode emulation with JIT acceleration."
- va_arg: The C/C++ mechanism and layout for accessing variadic function arguments, which is ABI-specific. Example: "The most prevalent is va\_arg, whose layout reflects the ABI's argument-register count (six for System~V, eight for AAPCS64)."
- VEX IR: The intermediate representation used by Valgrind’s VEX engine for dynamic binary translation and analysis. Example: "Examples include VEX IR~\cite{vex-valgrind}, Binary Analysis Platformâs (BAP) IL~\cite{brumley2011bap}, and REIL~\cite{dullien2009reil}."
- XMM register file: The SSE vector registers on x86/x64 used for floating-point and SIMD operations. Example: "x64's RFLAGS bits and XMM register file are held in dedicated AArch64 registers under the same one-to-one discipline,"
Collections
Sign up for free to add this paper to one or more collections.

