- The paper rigorously establishes Flux Matching as a new generative modeling paradigm that generalizes score matching by learning any distribution-preserving vector field.
- Empirical results show accelerated sampling, improved image generation, and enhanced interpretability, with applications ranging from RNA velocity to high-dimensional image tasks.
- Flux Matching enables the integration of causal mechanisms and structural priors into generative models while maintaining competitive performance.
Generative Modeling with Flux Matching
Overview
The paper "Generative Modeling with Flux Matching" (2605.07319) rigorously establishes Flux Matching as a new foundational paradigm for generative modeling. This approach generalizes score-based generative modeling by learning any vector field whose associated diffusion process admits the data distribution as a stationary distribution. Rather than constraining generative models to strictly match the score function, Flux Matching introduces a nullspace involving divergence-free perturbations, enabling explicit control over generative process properties while preserving the target distribution. The framework admits scalable training objectives, covers the score-matching setting as a special case, and extends naturally to modern diffusion models with noise annealing. Empirical results demonstrate that the increase in flexibility yields practical gains in accelerated sampling, interpretable generative dynamics, and rapid incorporation of structural priors, all with competitive generative modeling performance.
Theory and Objective
Background: Score Matching vs. Distribution-Preserving Vector Fields
In the conventional generative paradigm, the vector field fθ is trained to estimate the score ∇logp of the data distribution p; thus, all subsequent sampling dynamics and generative properties are inherited from this specific conservative field. However, the Fokker-Planck equation shows that any vector field fθ=∇logp+v, where ∇⋅(pv)=0, leads to the same stationary distribution. This exposes a rich family of generative vector fields with the same marginals, but potentially distinct and useful process properties.
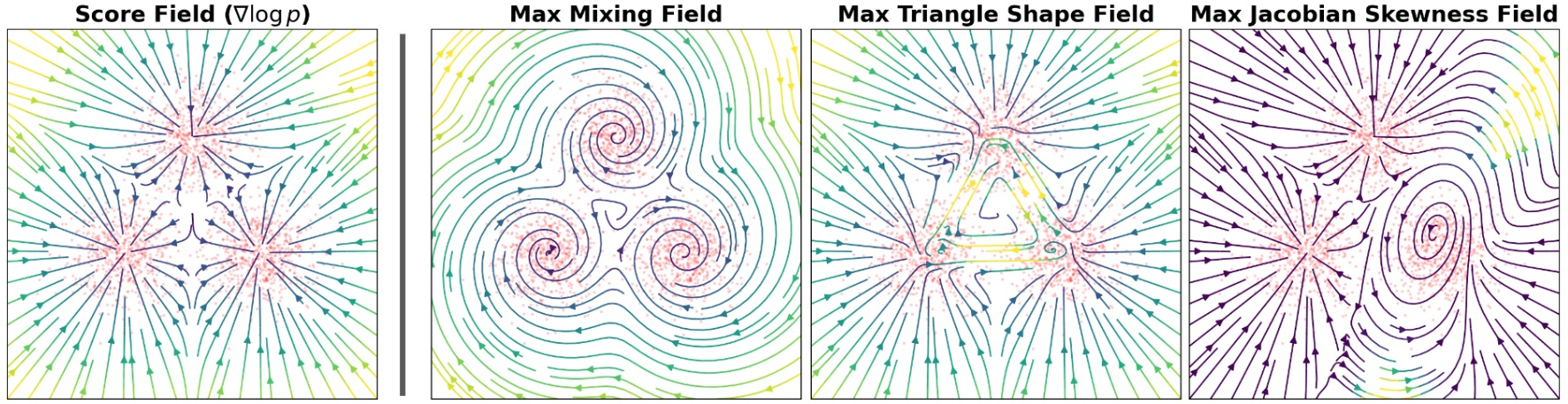
Figure 1: Schematic illustration of the space of vector fields; score matching learns only a single field while Flux Matching admits multiples lying within a generative subspace.
Flux Matching Loss Function
The core innovation is the Flux Matching objective, which only requires matching the divergence of the probability flux rather than the score directly:
Lflux(θ)=−Et,x0,xt[q(t)1uθ(x0)⊤sg(∂x0∂xt⊤∇xtrθ(xt))]
uθ=fθ−∇logp, rθ is a Stein operator capturing flux divergence, and the loss propagates divergence auto-correlations along the score-based diffusion trajectory. The result is an objective that is zero on the entire family of distribution-preserving vector fields.
The associated projected Fisher divergence defines an L2(p) geometry on flux divergence, maximally preserving Fisher information structure.
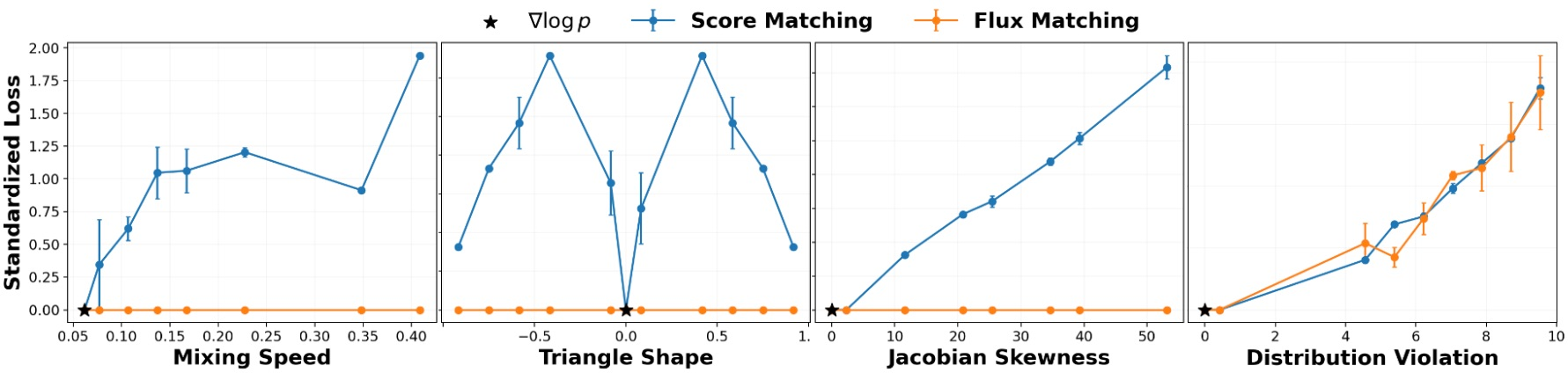
Figure 2: Normalized losses for Score Matching and Flux Matching as various vector field attributes are tuned for a Gaussian mixture; only Flux Matching remains flat (zero) on the entire set of distribution-preserving fields.
Practical Implementation
Scalable Training
A core challenge is to efficiently evaluate the intractable gradient and divergence terms. The authors employ minibatch-based KDE approximations for the score, stochastic horizon truncation to reduce MCMC cost, variance-reduced minibatch averaging for surrogate derivatives, and focus on gradient-friendly architectures for tractability.
The framework generalizes to the noise annealed setting essential for modern diffusion models, allowing separate vector field estimation for each noise level.
Empirical Analysis
Controlled Controllability
On a toy Gaussian mixture, tuning vector field attributes such as mixing speed, circulation, and Jacobian skewness (while holding the stationary distribution fixed) dramatically increases the score matching loss but is entirely neutral under Flux Matching.
Figure 2: Confirmed in empirical experiments; large changes in field attributes are penalized by Score Matching but not by Flux Matching, unless the perturbed field leaves the set of distribution-preserving fields.
Biological Interpretability: RNA Velocity
The framework enables direct training of structured, interpretable vector fields. For RNA velocity in single-cell genomics, where the generative field is dictated by biophysical ODEs, Flux Matching is used to fit interpretable parameters such as transcription and splicing rates directly from data. The method outperforms maximum likelihood EM-style fitting (scVelo) on standard metrics (CBC accuracy, velocity consistency), holding inductive bias constant and changing only the loss function.
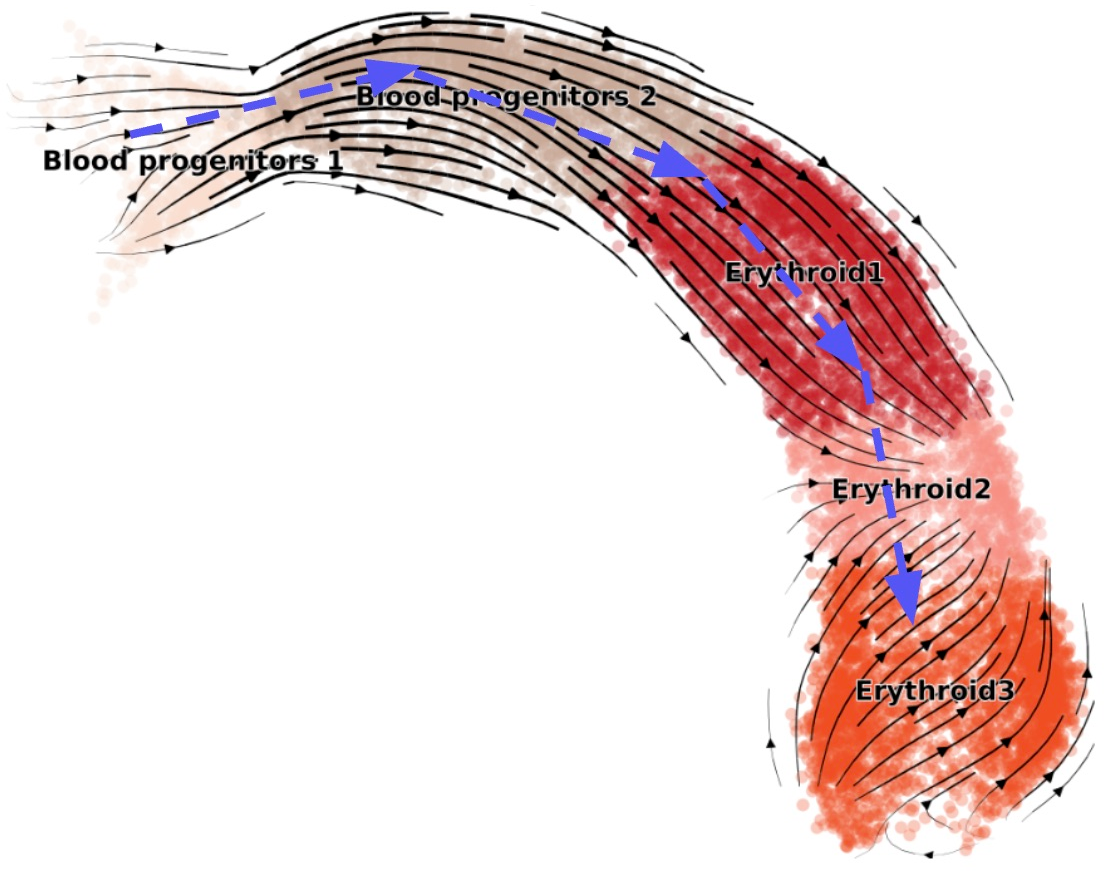
Figure 3: (Left) RNA velocity vector field learned via Flux Matching aligns with true progression; (Right) improved consistency/CBC vs. scVelo benchmarks.
High-Dimensional Image Generation
Using standard UNet backbones, the Flux Matching objective yields generative models achieving strong FID and NLL scores on CIFAR-10 and CelebA, validating scalability. Runtime and memory overhead, compared to DSM, is significant during training but absent at sampling time.

Figure 4: Uncurated samples from Flux Matching (left) and DSM (right) on CIFAR-10.

Figure 5: CelebA samples, demonstrating learning of rich image distributions with Flux Matching.
Accelerated Sampling and Fast Mixing
By augmenting the objective with explicit mixing-optimizing regularization, the learned vector fields achieve lower FID in fewer diffusion steps than vanilla DSM or unregularized Flux Matching, reflecting an increased mixing rate of the resulting generative dynamics.
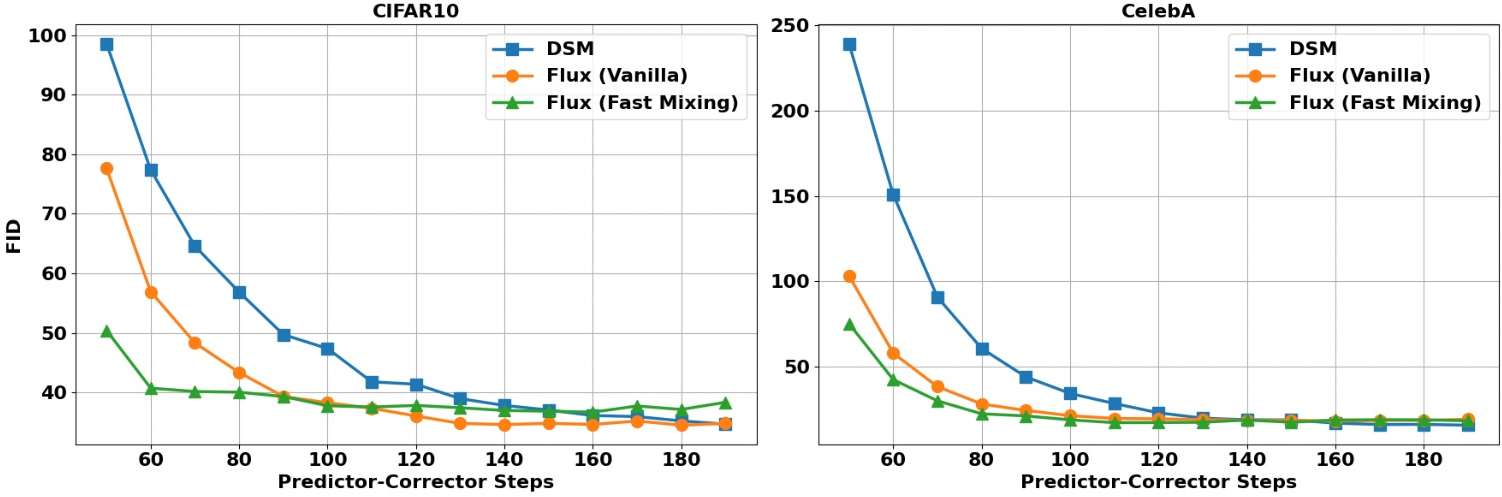
Figure 6: FID as a function of sampling steps for Flux Matching (with/without mixing regularization) and DSM. Flux Matching with fast mixing regularizer achieves target FID with up to 3× fewer steps.
Structural Priors: Directed and Autoregressive Dependencies
Flux Matching can accommodate nonconservative vector fields with asymmetric Jacobians and explicit structure, such as temporal causality. In a nonlinear-oscillator benchmark, causal attention masking delivers improved sample quality under Flux Matching, but degrades performance for DSM, which is architecturally incompatible with directionality due to gradient symmetry constraints.
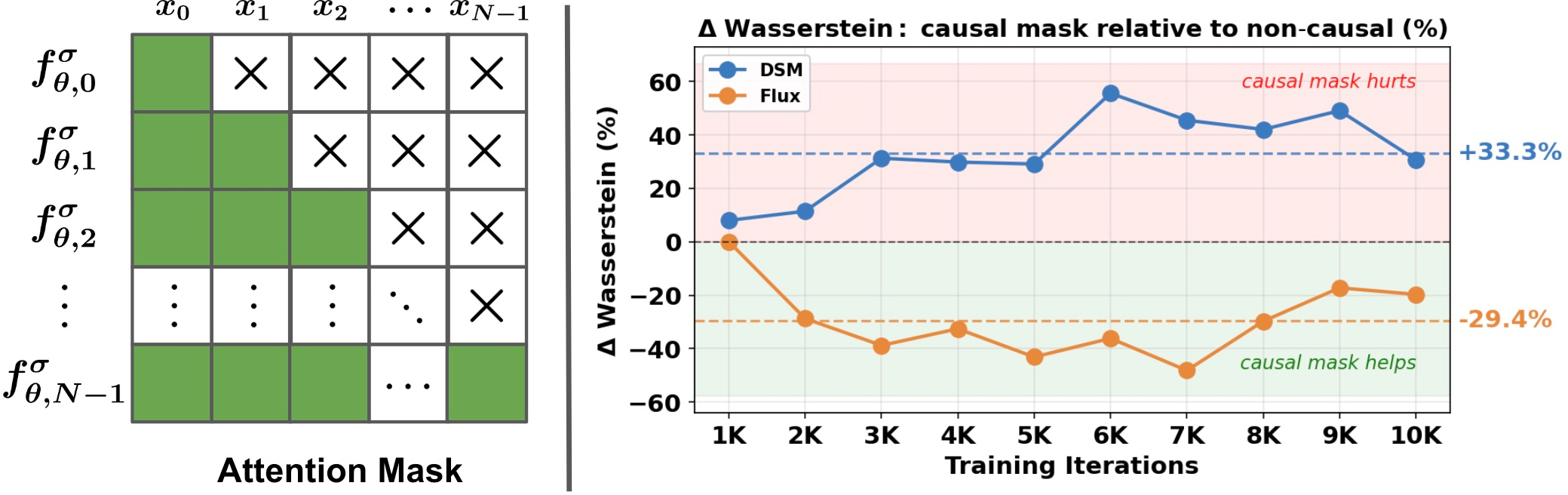
Figure 7: (Left) Causal attention mask for imposing autoregressive structure over time; (Right) Wasserstein distance improvement using causal structure under Flux Matching, but not DSM.
Implications and Theoretical Significance
Theoretical Expansion: Flux Matching strictly subsumes score-based modeling, covering all generative vector fields that share a stationary distribution and introducing a new axis of freedom previously ignored in generative modeling theory.
Practical Impact: Modelers can now deliberately select or regularize for mixing, mechanistic interpretability, or directed process structure, and can distill such properties directly into ∇logp0 via the loss or architecture, without compromising generative performance with respect to the stationary distribution.
Sampling Decoupling: Since sampling depends only on the divergence of the drift-augmented process, models trained under Flux Matching can be plugged directly into existing diffusion-based samplers with no algorithmic changes.
Causal and Mechanistic Inference: The approach opens scalable avenues to learn causal SDEs and ODEs at data scales surpassing previous methods, with immediate application in high-dimensional biology and physics.
Future Directions: Open questions include reducing the training-time cost, automating application-driven regularizer design, and exploring architecture spaces where the nullspace of divergence-free perturbations can be maximally exploited.
Conclusion
This work defines, analyzes, and operationalizes Flux Matching—a generative modeling objective and paradigm that opens the space of admissible vector fields yielding a given stationary distribution. Flux Matching enables practitioners to inject, optimize, and leverage application-specific inductive bias directly into the vector field, controlling both statistical and dynamical model properties. The empirical evidence demonstrates that this additional freedom is not merely theoretical but can be concretely harnessed for accelerated sampling, interpretability, and encoding explicit structure. The approach reconfigures the landscape of continuous generative modeling and expands the principled toolkit available for building powerful, structured, and interpretable generative models.