- The paper presents explicit transformer parameterizations that implement batch SARSA and actor-critic policy improvements.
- It rigorously proves local exponential convergence under explicit richness conditions using a teacher-mimicking training regime.
- Empirical validation on random tabular MDPs confirms that the learned transformers achieve near oracle-level control performance.
Transformers as Provable In-Context Policy Improvement Algorithms
Introduction
This study rigorously addresses the ability of transformer architectures to realize in-context reinforcement learning (ICRL) algorithms that perform policy improvement rather than value-only updates. The theoretical characterization answers an outstanding open problem: whether transformers can not only evaluate policies in context (as in previous mechanistic analyses of in-context temporal-difference (TD) learning) but also execute policy improvement procedures such as SARSA and actor-critic. The work provides the first formal convergence guarantee showing that, under explicit richness conditions on the training MDP family, gradient-based training converges (locally and exponentially) to the optimal parameter manifold for these policy improvement algorithms. Empirical results on randomly generated tabular MDPs validate the theoretical predictions, demonstrating the emergence of the constructed weight structure and oracle-level control performance on held-out tasks.
The paper's primary technical contribution is the derivation of explicit parameterizations for single-layer, single-head linear self-attention transformer blocks that provably implement batch semi-gradient SARSA and batch actor-critic updates in context. These constructions extend the mechanistic account beyond previous work focused only on policy evaluation [TCLTD].
Given a trajectory and current parameterization, the designed prompt encodes all necessary trajectory statistics so the transformer block, under constructed (P⋆,V⋆) weights, outputs the parameter update matching the analytical policy improvement algorithm. This construction retains its correctness for any affine parameterization due to scaling invariance. Notably, the block design supports both the critic and actor updates in the actor-critic setting, allowing the model to perform joint policy and value function learning within a single in-context inference.
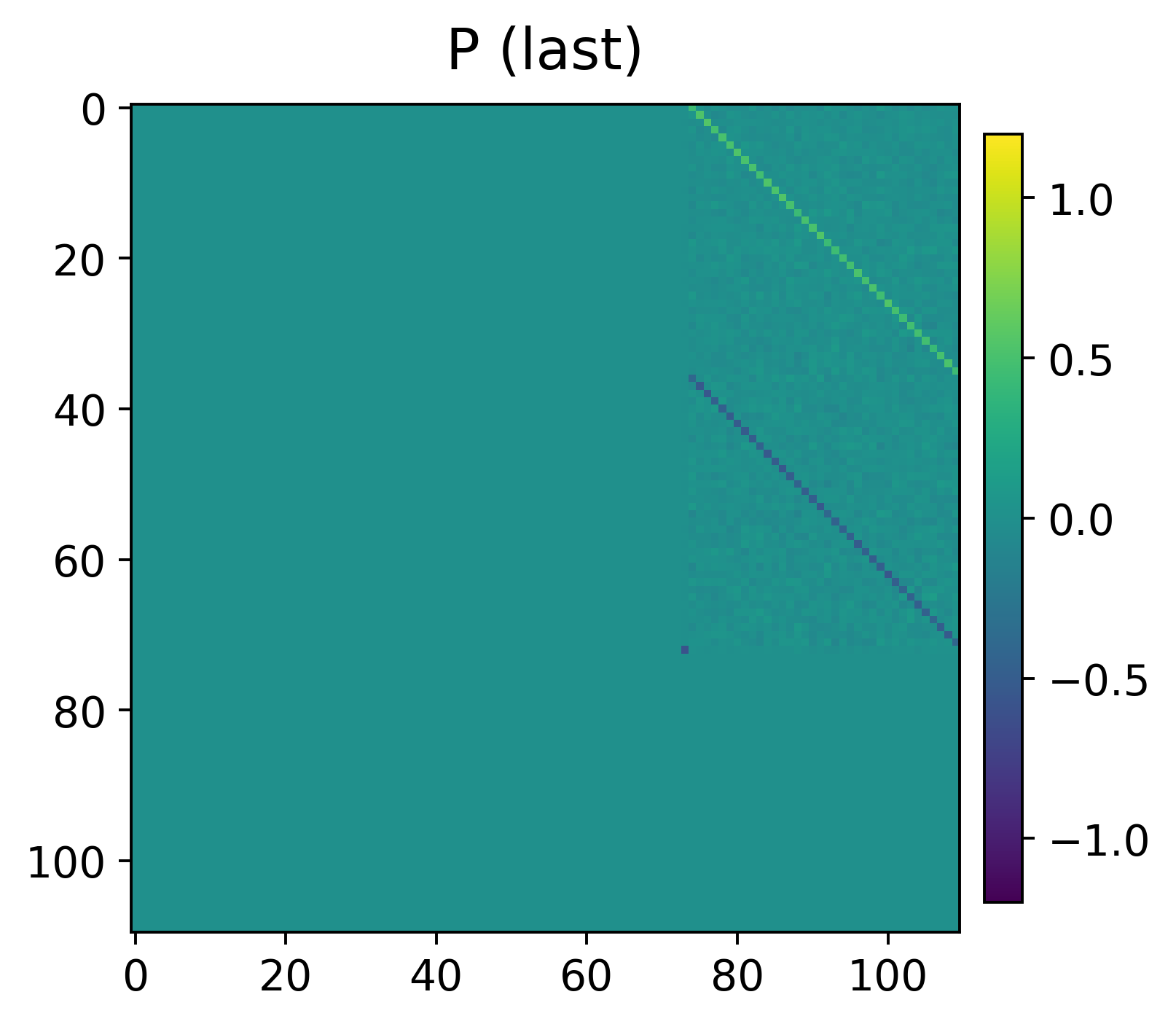
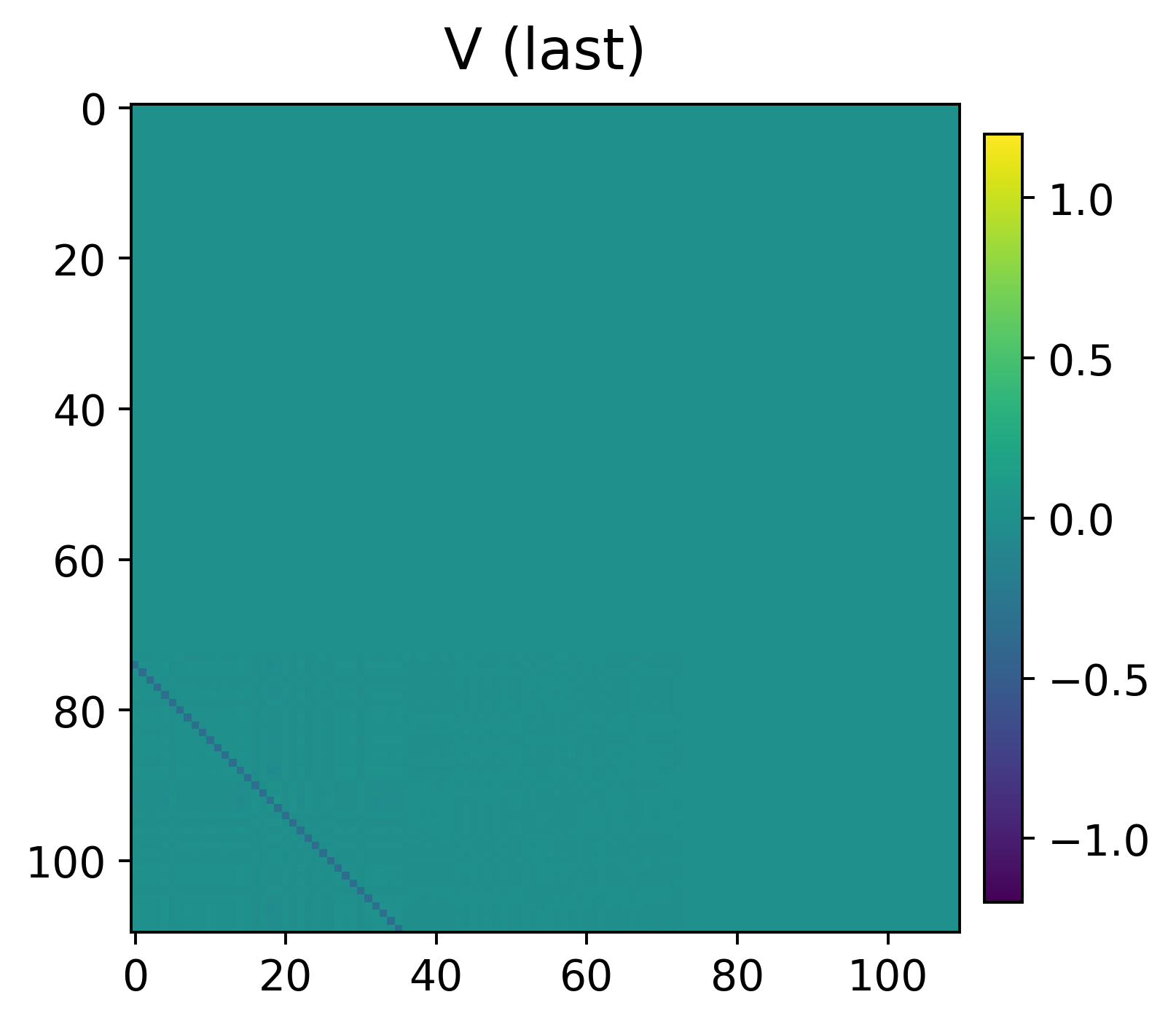
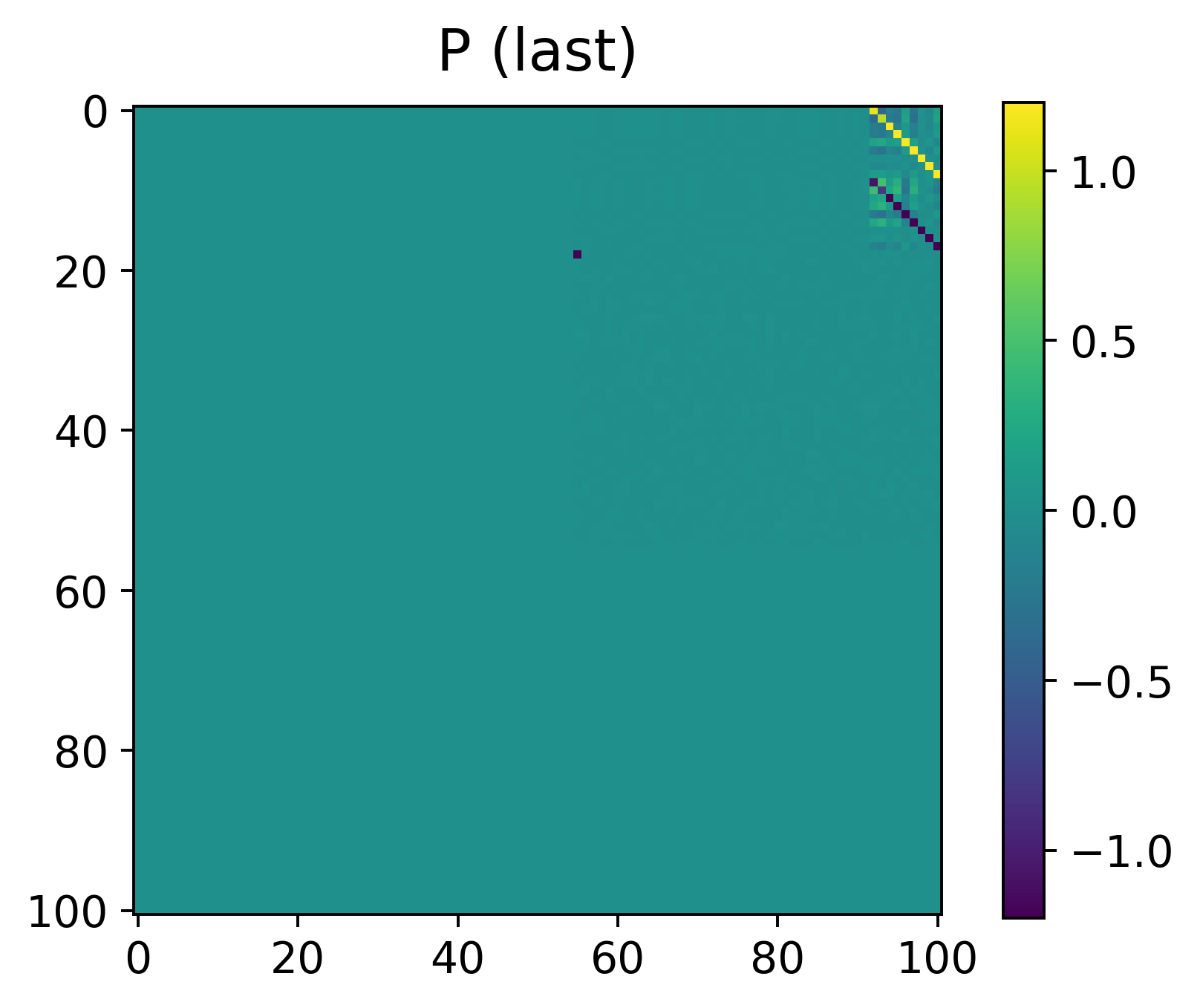
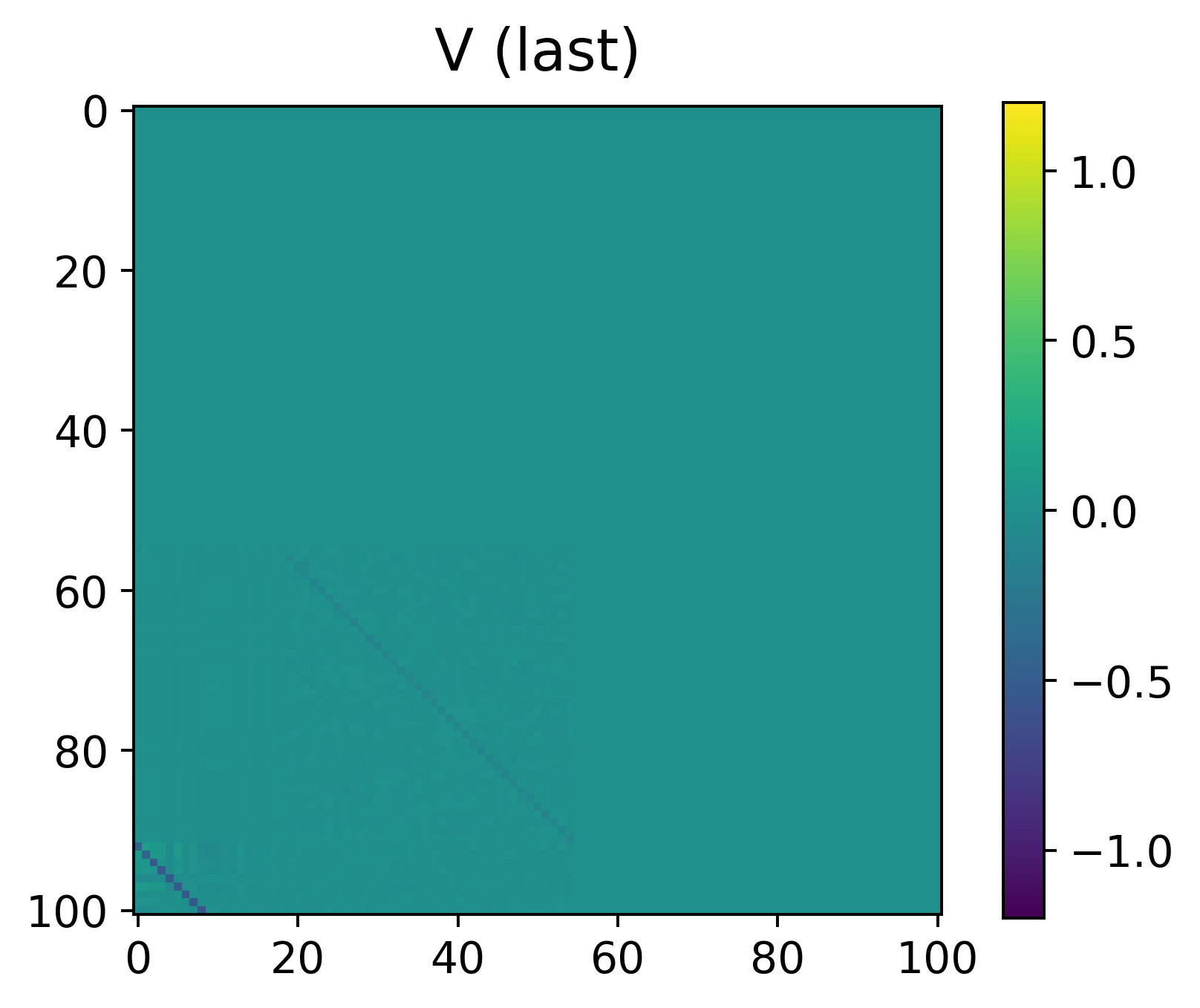
Figure 2: Learned P and V parameter matrices for SARSA after training, showing the explicit structure predicted by the theoretical construction.
Teacher-Mimicking Training and Convergence Properties
A secondary technical contribution is a training regime—teacher-mimicking—that, for each sampled MDP, matches the transformer output to a batch SARSA or actor-critic update computed analytically from the observed trajectory. The gradient flow dynamics for this supervised objective are analyzed via a local Polyak-Łojasiewicz (PL) inequality restricted to a tubular neighborhood around the optimal scaling manifold. The loss exhibits local strong contractivity in all but a scaling direction, leading to exponential decay along normal directions to the manifold.
Under the richness assumption on the MDP distribution (covering feature, reward, and excitation structure), the analysis establishes that gradient flow initialized sufficiently close to the optimal parameter manifold remains within this tube and converges exponentially to the set of optimal points implementing the target RL update. This is, importantly, the first convergence guarantee in the ICRL mechanistic learning literature.
Empirical Validation
Empirically, the transformer is trained using the prescribed procedure on families of random tabular MDPs with diverse state transitions, reward functions, and randomly initialized policy/value parameterizations. Learned parameter blocks for both SARSA and actor-critic exhibit strong accordance with the constructed solution, up to scaling (see Figure 2), supporting claims that the training procedure actualizes the theoretical fixed points.
Closed-loop evaluation on unseen MDPs demonstrates that the trained models perform in-context policy improvement as predicted analytically. Policy returns closely track those of the analytical teacher (batch SARSA or actor-critic) when performing multiple in-context rollouts and updates, eventually attaining returns near the exact policy-iteration oracle within the representational limits of linear parameterizations.
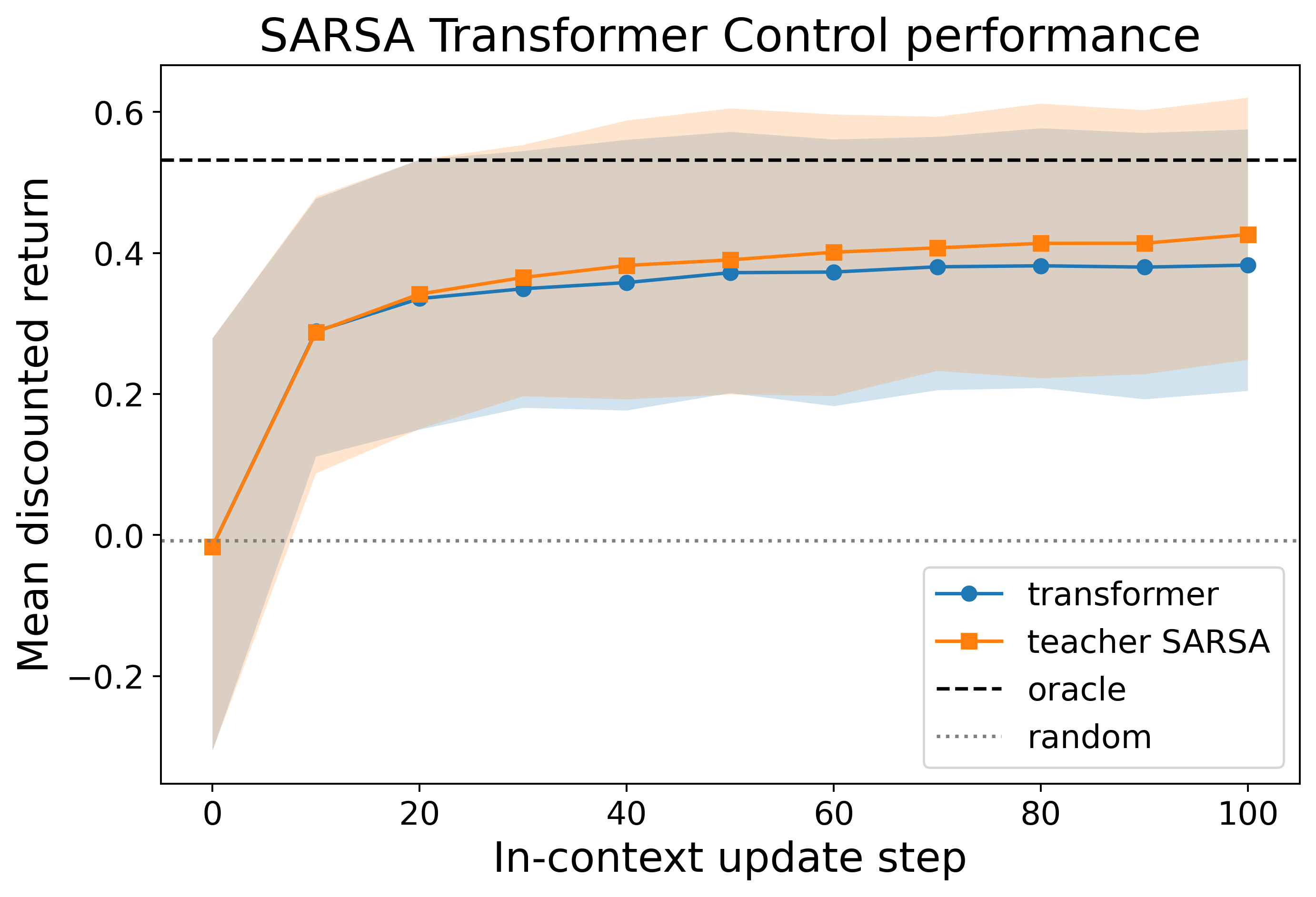
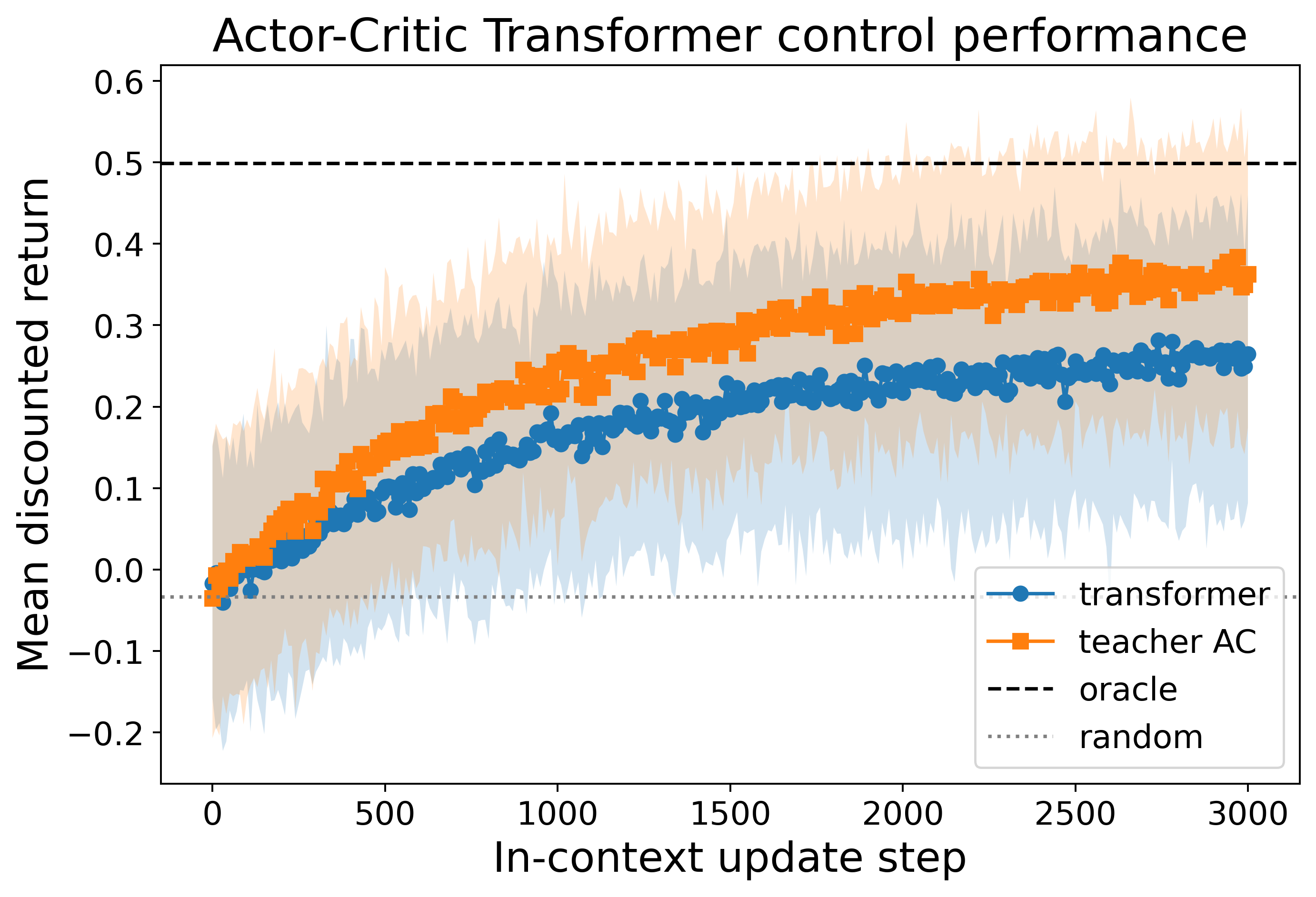
Figure 1: Learned parameter blocks for the SARSA transformer architecture after training, highlighting concentration in theoretical non-zero regions.
Figure 3: Learned parameter blocks for the actor-critic architecture after training, similarly confirming theoretical predictions.
Implications and Future Directions
These results substantively deepen the mechanistic understanding of transformers in reinforcement learning, showing not only existence but also constructive learnability (by gradient-based optimization) of parameterizations that realize core policy improvement procedures fully in context. The findings elucidate why and how transformer-based agents trained with sufficiently rich MDPs and teacher-mimicking objectives internalize classical RL update rules. The paper additionally supports the notion that policy improvement, not just value evaluation, is accessible through in-context learning with standard transformer blocks.
Theoretical implications include the characterization of the optimization geometry around the scaling invariance manifold, which may inform future analysis of more complex architectures (multi-head, nonlinearities) or connections to meta-learning and general algorithm distillation. Practically, this result supports the design and training of unified agents capable of efficient online adaptation to new reward and transition functions via in-context updates—potentially informing scalable generalist RL agents or enhancing diagnostic interpretability of transformer decision-making.
Limitations and Outstanding Challenges
The results hinge on several assumptions: explicit richness conditions on MDP sampling, affine value/policy parameterizations, and a gradient flow (or very small step size) optimization regime. The convergence guarantee is local: the parameterization must begin in a neighborhood of the optimal manifold. Characterizing generalization to stochastic optimization, nonlinear architectures, multi-step updates, or partial observability remains open. Moreover, verifying or constructing adequate MDP distributions for sufficient excitation in high-dimensional environments may be nontrivial in practice.
Conclusion
This work establishes, both analytically and empirically, that transformers can provably learn to perform in-context RL with policy improvement, including both SARSA and actor-critic updates, and provides the first convergence result for such mechanistic ICRL. The study bridges the gap between mechanistic theory and practical optimization, and points toward principled development of in-context agents that perform sequential decision-making with robust policy improvement dynamics (2605.05755).

