ReActor: Reinforcement Learning for Physics-Aware Motion Retargeting
Abstract: Retargeting human kinematic reference motion onto a robot's morphology remains a formidable challenge. Existing methods often produce physical inconsistencies, such as foot sliding, self-collisions, or dynamically infeasible motions, which hinder downstream imitation learning. We propose a bilevel optimization framework that jointly adapts reference motions to a robot's morphology while training a tracking policy using reinforcement learning. To make the optimization tractable, we derive an approximate gradient for the upper-level loss. Our framework requires only a sparse set of semantic rigid-body correspondences and eliminates the need for manual tuning by identifying optimal values for a parameterization expressive enough to preserve characteristic motion across different embodiments. Moreover, by integrating retargeting directly with physics simulation, we produce physically plausible motions that facilitate robust imitation learning. We validate our method in simulation and on hardware, demonstrating challenging motions for morphologies that differ significantly from a human, including retargeting onto a quadruped.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces ReActor, a way to take a person’s movement (like a dance or a jump captured by motion-capture) and make a robot with a very different body perform it in a believable, physics-correct way. The goal is to avoid common glitches—like feet sliding across the floor, parts of the body passing through each other, or moves that a real robot couldn’t do—so the result looks realistic and can be used to train robot controllers.
What questions did the researchers ask?
- How can we convert human motions into robot motions when the robot has a very different shape and set of joints (for example, a small humanoid or even a four-legged robot)?
- Can we make these retargeted motions physically believable (no foot sliding, no self-collisions, no impossible moves)?
- Can we do this with minimal human setup—just telling the system which robot part corresponds to which human body part—without lots of manual tuning?
- Will better, physics-aware retargeted motions help train robots (with reinforcement learning) to follow these motions more reliably?
How did they do it?
Think of their method as a two-player team working together:
- The “Coach” (top level) tweaks how the human motion is adapted to fit the robot’s body (for example, slight shifts, rotations, and scaling).
- The “Athlete” (bottom level) learns, through trial and error in a physics simulator, how to move the robot’s joints to follow that adapted motion.
These two parts learn together in a loop: while the Athlete practices, the Coach keeps adjusting the motion to better match what the robot can realistically do.
Two-layer learning (bilevel optimization)
- Top layer (“Coach”): Chooses parameters that reshape the human motion to fit the robot (like aligning limbs, scaling height, and nudging positions/orientations).
- Bottom layer (“Athlete”): A reinforcement learning (RL) policy that controls the robot in a physics simulation to track the adapted motion. RL here means the robot learns by trying moves, getting rewards for matching the target motion, and avoiding penalties (like applying too much force).
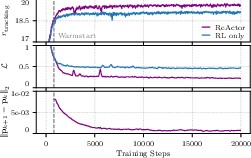
Instead of stopping training to wait for perfect learning each time, they update both layers continuously. To keep this efficient, they use a simple, practical shortcut to estimate how to adjust the motion parameters while the policy is still learning.
Simple setup from the user
- The user only marks a few “correspondences” like “this robot link ≈ this human body part” (e.g., robot left hand ↔ human left hand). They don’t need to label every joint or define when feet contact the ground.
- The system automatically figures out the rest: global scale (height differences), how to align body frames, and small per-motion adjustments (like a tiny vertical shift) to account for noise in the source data.
Physics keeps it honest
- Everything runs inside a physics simulator (like a very accurate video game world), which respects gravity, contacts, and collisions.
- This prevents non-physical artifacts such as foot sliding, ground penetration, or body parts going through each other.
- The controller uses joint targets plus a small “helper” push/torque on the robot’s main body (called a residual wrench). This makes it easier to learn tough moves across many different motions. They penalize using this helper so the final motions stay as realistic as possible.
Practical training tricks
- A short “phase-in” at the start of each episode lets the robot settle into the correct starting pose before tracking begins.
- The training sampler focuses more on hard motion clips where the robot fails, so learning time is used efficiently.
What did they find, and why is it important?
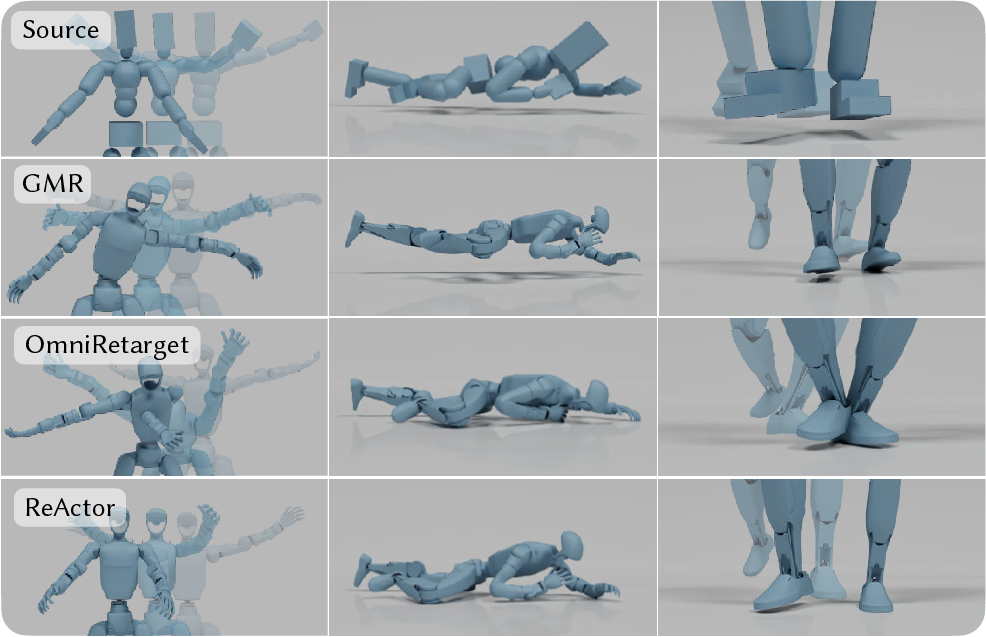
- Fewer artifacts: Compared to strong baselines (GMR and OmniRetarget), ReActor produced motions with virtually no ground penetration or self-collisions, and much less foot sliding/floating. That means movements look and feel more real.
- Works across very different robots: They successfully retargeted human motions to two different humanoids (including one tested on real hardware) and even to a quadruped, despite big differences in shape, size, and joint types.
- Better training data for robots: When they trained separate tracking controllers on the resulting motions (the “downstream” task), the controllers succeeded more often and tracked more accurately with ReActor’s data than with the baselines’ data. In short: better inputs lead to better robots.
- Less manual tuning: With only a sparse set of body-part correspondences as input, ReActor automatically found good parameter values, saving time and expertise.
- Efficient and scalable: Training on a large motion dataset finished in a practical amount of time on a single GPU and generalized well to new motions.
These results matter because high-quality, physics-aware motion retargeting makes it much easier to create reliable robot behaviors from human examples—useful in animation, games, and real-world robotics.
What does this mean going forward?
ReActor shows a promising way to quickly adapt human movement to many robot bodies in a realistic, physics-safe way. This can:
- Speed up building lifelike characters in films and games.
- Help robots learn complex skills from human motion libraries with fewer glitches.
- Reduce the need for hand-tuned settings and contact schedules, making the process more accessible and scalable.
- Enable retargeting across very different morphologies (including legged robots), broadening where human motion data can be applied.
While the method allows small helper forces during retargeting (penalized to keep things realistic) and doesn’t force exact contact matching, it already delivers large improvements. Future work can further reduce helper forces, refine contact handling, and expand to more robot types and tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains uncertain or unexplored, and where further research could concretely advance the work.
- Convergence guarantees for the single-loop bilevel optimization: The method uses a simplified gradient estimate with TTSA-style updates, but provides no theoretical convergence analysis or conditions under which the algorithm converges (or fails), especially given stochastic RL and the αI sensitivity assumption.
- Sensitivity to the α parameter in the gradient approximation: The choice of α ∈ 0,1 is not specified or validated; systematic sensitivity analysis, learning α, or deriving α from rollout statistics remains open.
- Variance reduction and stability of upper-level gradient estimates: The paper does not evaluate the variance of the stochastic gradient estimate for retargeting parameters nor propose variance-reduction techniques (e.g., baselines, control variates, trajectory weighting).
- Scope and limits of the parameterization: The mapping relies on a single global scale s (root-height ratio) and bounded local offsets; the effect of more expressive parameterizations (e.g., per-limb nonuniform scaling, learnable joint-space embeddings, time-warping) on morphology extremes and task fidelity is not studied.
- Automatic discovery of semantic correspondences: Correspondences are manually specified; methods to automatically infer or refine source-target rigid-body pairings (e.g., from kinematic topology, contact patterns, or learned shape/function priors) are not explored.
- Robustness to incorrect or sparse correspondences: Beyond anecdotal tests, there is no systematic evaluation of how correspondence errors affect retargeting quality, nor mechanisms to detect, correct, or robustify against misaligned mappings.
- Contact semantics and task-level constraints: The method intentionally avoids enforcing contact patterns, but applications that require contact fidelity (e.g., footfall timing, hand placements, tool interactions) lack mechanisms to preserve or adapt contact semantics with guarantees.
- Handling of complex environmental interactions: The dataset is filtered to remove human-object interaction; retargeting motions involving external contacts (hands, props, walls), frictional variability, or terrain irregularities is not addressed.
- Initialization strategy evaluation: The learned phase-based initialization replaces RSI/IK, but the trade-offs (speed to “trackable” state, stability, failure modes) and comparisons to IK-based warm-starts across morphologies are not quantified.
- Reward and loss weight auto-tuning: Despite claims of reducing manual tuning, key weights (e.g., tracking terms, residual wrench penalty) are hand-set and sensitive; meta-optimization or bilevel reward learning for automatic weight selection is not investigated.
- Constraints δpos, δori, δz selection: The bounds defining the convex parameter set are fixed; there is no study on their sensitivity, motion-specific adaptation, or principled methods to set them for large embodiment gaps.
- Physical feasibility beyond artifact metrics: Evaluation emphasizes foot sliding/floating and penetrations; analyses of energy/torque feasibility, actuator saturation, stability margins, and tracking effort (e.g., torque/energy cost) are missing.
- Long-horizon and temporal coherence: Episodes are short (≈5 s) and training curves are reported over 20k iterations; the method’s stability over long sequences, transitions between motions, and temporal style preservation is not quantified.
- Style and perceptual fidelity: Beyond rigid-body pose/velocity errors, there is no evaluation of style similarity (e.g., motion signatures, kinematic synergies) or human perceptual studies, which are critical for animation and character control.
- Generalization across morphologies and tasks: Experiments use two humanoids and one quadruped (primarily simulated); broader testing on diverse non-humanoid morphologies (hexapods, manipulators) and task sets (locomotion vs. manipulation) is absent.
- Quadruped evaluation depth: The quadruped results are showcased but lack comprehensive metrics (contact timing, gait quality, stability, energy usage) and downstream RL tracking without residual forces.
- Hardware validation scope: Real-world evaluation appears limited to a single humanoid platform; systematic sim-to-real analysis (latency, safety, contact quality, wear, controller robustness) across multiple robots is not provided.
- Residual root wrench reliance: Retargeting uses residual root forces/torques to broaden coverage; the boundary between motions that remain feasible without residuals and those that do not, and strategies to eliminate or minimize residuals while retaining coverage, need quantification.
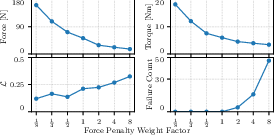
- Force penalty tuning and trade-offs: The residual force penalty is “most sensitive,” but there is no principled method for setting it or characterizing the Pareto frontier between physical realism and motion coverage; adaptive or motion-specific penalty schedules are unexplored.
- Partial orientation tracking (twist/swing) selection: Ignoring unactuated axes is pragmatic, but criteria for axis selection, effects on tracking fidelity, and learning which components to prioritize per joint/motion remain open.
- Robust handling of noisy source motions: The approach adds nominal and learnable vertical offsets; more comprehensive contact/noise correction (e.g., learned contact inference, motion denoising, physics-consistent re-timing) is not explored.
- Computational efficiency and online use: Training takes ≈6–6.5 hours on a high-end GPU; strategies for few-shot adaptation to new motions/morphologies, online retargeting, or incremental updates with limited compute are not discussed.
- Fairness and breadth of baseline comparisons: Baseline hyperparameters are “provided” or nominal; a thorough study with tuned baselines, broader methods (including differentiable simulation or trajectory optimization variants), and cross-metric comparisons would strengthen claims.
- Collision-aware upper-level objectives: While simulation prevents self-penetration, collision avoidance is not explicitly encoded in the upper-level loss; integrating contact-aware loss terms or constraints could improve controllability and guarantees.
- Dataset diversity and benchmarks: The reliance on filtered AMASS and limited cross-dataset tests (100STYLE subset with pseudo-ground truth) leaves open the question of performance on richer, noisier, and interaction-heavy datasets; standardized benchmarks for physics-aware retargeting are needed.
Practical Applications
Immediate Applications
Below are applications that can be deployed now or with modest engineering effort, leveraging the paper’s physics-aware, bilevel RL retargeting with sparse semantic correspondences.
- Physics-consistent motion retargeting for animation and games
- Sector: Media/Entertainment (VFX, games, virtual production), Software
- Tools/Products/Workflows: Offline “ReActor Retargeter” plugin for DCC tools (e.g., Blender, Maya) or game engines (Unreal/Unity via Isaac Sim or equivalent); batch-convert human mocap (e.g., AMASS) to diverse characters (non-uniform scale, different DoF), then bake to kinematic animation tracks without foot sliding/self-penetration.
- Assumptions/Dependencies: Accurate physics simulation; sparse body-part correspondences; GPU resources for training; licensing for mocap datasets; acceptable offline latency (hours-scale training).
- Robot policy pretraining using artifact-free references
- Sector: Robotics (humanoids, quadrupeds), Software
- Tools/Products/Workflows: Use ReActor to generate physically plausible reference trajectories; train downstream tracking policies (e.g., PPO) without residual forces; integrate into existing imitation-learning stacks (DeepMimic-like, PHC-style pipelines).
- Assumptions/Dependencies: Robot URDF/physics model fidelity (contacts, friction); tuned PD gains; sim-to-real gap management (system ID, friction tuning).
- Sim-to-real motion library generation for humanoids and quadrupeds
- Sector: Robotics (R&D labs, OEMs), Theme parks/Animatronics
- Tools/Products/Workflows: Generate gait and whole-body motion libraries (walks, turns, gestures, crouches, crawls) tailored to specific robot morphologies; export as reference trajectories controllable by low-level controllers on hardware.
- Assumptions/Dependencies: Accurate joint limits and contact modeling; remove or tightly penalize residual root wrench before hardware deployment; validation on target hardware.
- Rapid motion exploration for novel morphologies
- Sector: Robotics, Character design
- Tools/Products/Workflows: Designers specify sparse mappings once; the system auto-optimizes offsets and produces viable motions across characters with very different proportions/DoF; useful for early-stage morphology evaluation.
- Assumptions/Dependencies: Coarse nominal alignment; correct choice of root body; stable twist–swing selection for reduced-DoF joints.
- Teleoperation and VR user studies in simulation
- Sector: Telepresence/Industrial robotics, HRI research
- Tools/Products/Workflows: Map human operator (mocap/VR rig) to robots of different morphologies inside a physics sim; run usability and safety studies before hardware trials.
- Assumptions/Dependencies: Not real-time hard constraints; acceptable latency for studies; interface to VR suits; clean contact simulation.
- Automated mocap “cleaning” with physics-aware constraints
- Sector: Media/Entertainment, Software
- Tools/Products/Workflows: Ingest noisy/floating mocap, pass through physics-aware retargeter (to the same or proxy skeleton), then reproject to source skeleton to remove sliding and penetrations.
- Assumptions/Dependencies: A consistent mapping between source and proxy skeletons; re-projection step quality.
- Retargeting quality assurance and metrics in content pipelines
- Sector: Media/Entertainment, QA tooling
- Tools/Products/Workflows: Use paper’s metrics (ground penetration, self-penetration, foot sliding/floating) as automated checks; gate content before publishing or before training downstream controllers.
- Assumptions/Dependencies: Thresholds tuned per project; reproducible simulation settings.
- Dataset creation for academic benchmarking
- Sector: Academia
- Tools/Products/Workflows: Release physics-consistent, retargeted motion datasets (humanoid/quadruped variants) for evaluating imitation controllers and retargeting algorithms.
- Assumptions/Dependencies: Data licensing; standardized correspondences; documented hyperparameters for reproducibility.
- Interactive authoring for animatronics and live shows
- Sector: Theme parks/Animatronics
- Tools/Products/Workflows: Creative teams specify target poses via sparse mappings; system optimizes physically feasible motions that respect hardware constraints, reducing manual tuning.
- Assumptions/Dependencies: Accurate motor limits/torque envelopes; conservative removal/penalization of residual forces; on-site validation.
- Robotics education and curriculum modules
- Sector: Education
- Tools/Products/Workflows: Course labs demonstrating bilevel optimization and RL for motion retargeting; students modify correspondences/weights and observe effects on tracking and artifacts.
- Assumptions/Dependencies: Access to Isaac Sim (or equivalent), GPU time, curated motion subsets.
- Quadruped behavior ideation from human mocap
- Sector: Robotics, Media/Entertainment
- Tools/Products/Workflows: Map crawl/parkour-like human motions to quadrupeds for novel gait discovery and stylized animations.
- Assumptions/Dependencies: Thoughtful body-part mappings; swing–twist loss selection for reduced DoF hips/shoulders.
- Minimal-setup mapping wizard
- Sector: Software tooling
- Tools/Products/Workflows: A lightweight UI to define sparse semantic correspondences and root selection, then run the nominal alignment and optimization with sensible defaults.
- Assumptions/Dependencies: Reasonable defaults for weights; users can identify semantically matching parts.
Long-Term Applications
Below are applications that are promising but will likely require further research, scaling, or productization (e.g., real-time performance, broader task coverage, standardization, safety certification).
- Real-time teleoperation retargeting on hardware
- Sector: Manufacturing, Field robotics, Healthcare
- Tools/Products/Workflows: Low-latency controller that maps human motions onto robots on-device, satisfying contacts/limits on the fly; fallback safety layers and predictive models.
- Assumptions/Dependencies: Faster simulators or learned dynamics models; robust online optimization; safety certification and fail-safes; network QoS.
- In-home robot “puppeteering” to teach tasks
- Sector: Consumer robotics
- Tools/Products/Workflows: End-users demonstrate behaviors; system retargets and learns task policies despite morphology mismatch (grippers vs hands) and varied environments.
- Assumptions/Dependencies: Extension from whole-body motion to contact-rich manipulation; perception and environment modeling; robust generalization.
- Cross-embodiment generalist policies (foundation models for robot motion)
- Sector: Robotics, AI
- Tools/Products/Workflows: Large-scale training of policies using retargeted datasets spanning many bodies/morphologies; standardized correspondence schemas; shared latent spaces.
- Assumptions/Dependencies: Massive compute; data diversity; stable optimization beyond locomotion; standardized evaluation suites.
- Assistive devices: exoskeleton/prosthetic motion mapping
- Sector: Healthcare
- Tools/Products/Workflows: Physics-aware mapping of human intent to devices with fewer/different DoF; safer gait and posture assistance under real constraints.
- Assumptions/Dependencies: Medical-grade safety; individualized calibration; comfort and energy use constraints; regulatory approval.
- Policy and safety standards for public-facing robots
- Sector: Policy/Regulation
- Tools/Products/Workflows: Certification guidelines that require physics-aware validation (penetration/sliding thresholds, contact consistency) before deployment in public spaces (e.g., malls, parks).
- Assumptions/Dependencies: Consensus on metrics and test protocols; standardized simulators and reporting.
- Adaptive, on-device physics-aware retargeting for AR/VR avatars
- Sector: AR/VR, Social platforms
- Tools/Products/Workflows: Real-time avatar motion with fewer artifacts across device form factors (full-body to partial-body input) by integrating lightweight physics constraints.
- Assumptions/Dependencies: Highly optimized mobile inference/simulation; power and latency budgets; partial observation robustness.
- Co-design of robot morphology with retargetability objectives
- Sector: Robot design/Manufacturing
- Tools/Products/Workflows: Use bilevel optimization to search morphologies that best accommodate human motion libraries (reduced energy, fewer artifacts).
- Assumptions/Dependencies: CAD–simulation integration; multi-objective optimization (cost, manufacturability, control).
- Consumer-grade “retarget to any character” cloud service
- Sector: Media/Entertainment, Prosumer tools
- Tools/Products/Workflows: Drag-and-drop mocap/video; select character; cloud performs physics-aware retargeting and returns animations; optional stylization.
- Assumptions/Dependencies: Scalable cloud GPU; streamlined licensing; easy correspondence presets per character library.
- Physics-based mocap cleanup and inversion services
- Sector: Media/Entertainment
- Tools/Products/Workflows: Service that fixes sliding/penetration via physics-aware retargeting and maps corrected motion back to the original skeleton or mesh.
- Assumptions/Dependencies: Reliable inverse mapping and skinning; controllable latency/cost; artist-friendly controls.
- Safety-aware motion libraries for cobots and logistics
- Sector: Industrial robotics
- Tools/Products/Workflows: Retargeted, collision-aware motion sets validated under constrained environments (shelf spacing, human proximity); integrated with perception to adjust references online.
- Assumptions/Dependencies: Accurate environment modeling; online constraint handling; standards compliance (e.g., ISO/TS 15066).
- Automatic correspondence learning and semantics transfer
- Sector: Robotics/AI research
- Tools/Products/Workflows: Learn semantic body-part correspondences from data to remove manual mapping; integrate with video-to-motion pipelines.
- Assumptions/Dependencies: Labeled datasets; robust cross-domain features; interpretable mapping for safety/auditability.
- Integration with differentiable or hybrid simulators
- Sector: Robotics/Simulation
- Tools/Products/Workflows: Replace/augment approximate gradient with differentiable physics to refine upper-level updates; better sample efficiency and stability.
- Assumptions/Dependencies: Scalable differentiable contact models; numerical stability; engineering effort to bridge with RL.
- Standardized retargeting configuration specs
- Sector: Software standards
- Tools/Products/Workflows: Open schema for semantic correspondences, root/body definitions, twist–swing axes, constraints; interoperable across engines and studios.
- Assumptions/Dependencies: Community buy-in; versioning and validation tools.
Notes on Key Assumptions and Dependencies
- Simulation fidelity: Contact/ friction modeling, joint limits, and mass/inertial properties must reflect the target robot/character to ensure transferability and artifact suppression.
- Sparse semantic correspondences: Correct pairing and root selection are critical; errors degrade outcomes but the method is robust enough to handle sparsity and some mismatches.
- Compute and time: Training typically needs a modern GPU and hours of wall time; real-time variants will need new optimizations or model reductions.
- Residual forces: Useful during retargeting but must be penalized or removed for hardware deployment; downstream controllers trained without RFC showed improved realism.
- Approximate upper-level gradient: The “alpha I” sensitivity assumption makes optimization tractable; extreme dynamics or highly non-smooth losses may require refinements.
- Data quality and licensing: Curated mocap (e.g., PHC-filtered AMASS) improves robustness; ensure rights for commercial use.
- Safety and regulation: Hardware deployment (especially public/assistive use) requires safety envelopes, monitoring, and formal validation beyond simulation metrics.
Glossary
- AMASS: A large human motion capture dataset aggregated from multiple sources, used for training and evaluation of motion models; "Unless stated otherwise, we use the AMASS dataset~\cite{mahmood_amass_2019}."
- Bilevel optimization: An optimization paradigm with an upper-level problem whose objective depends on the solution of a nested lower-level problem; "We propose a bilevel optimization framework that jointly adapts reference motions to a robotâs morphology while training a tracking policy using reinforcement learning."
- Contact dynamics: The physical interactions involving contact forces and discontinuities (e.g., impacts and friction) during motion; "Our approach inherently respects physical limitations, accounts for discontinuous contact dynamics, and allows the use of non-differentiable objectives."
- Contact pattern: The temporal sequence of contacts (e.g., foot-ground) assumed during motion; "However, these methods often require a predefined contact pattern, are prone to local minima, and require substantial manual tuning to scale across diverse motion datasets."
- Convex set: A set in which any line segment between two points lies entirely within the set, often used to enforce bounded parameter constraints; "where is a convex set to which the parameters are constrained, is the upper-level loss function, and is the lower-level reward function."
- Deadband: A range around zero in which an input command produces no output, used here to encourage exactly zero residual forces when not needed; "Additionally, we apply a continuous deadband to the wrench action"
- Degrees of Freedom (DoF): Independent parameters that define the configuration of a system, such as joints in a robot; "with varying degrees of freedom and vastly different shapes, sizes, and proportions."
- Differentiable simulation: Simulation whose dynamics are differentiable with respect to states and parameters, enabling gradient-based optimization through physics; "Additionally, differentiable simulation can be used to optimize for additional effects such as vibration suppression~\cite{hoshyari_vibration-minimizing_2019}."
- Domain randomization: A training technique that randomizes environment parameters to improve robustness and sim-to-real transfer; "Unlike motion imitation, we relax strict dynamic requirements by omitting domain randomization and allowing residual force control (RFC)~\cite{yuan_residual_2020} to act on the root"
- Euclidean projection: The closest-point projection of a vector onto a set under the Euclidean norm, used to keep parameters within bounds; "where $P_{\mathcal{P} \left(\cdot\right)$ is the Euclidean projection onto the convex set "
- Exponential map: A mapping from a rotation vector in the Lie algebra to a rotation matrix on the Lie group (SO(3)); "and is the exponential map, mapping the 3D rotation vector ${p}^b_{\text{ori}$ to a rotation matrix~\cite{sola_micro_2018}."
- Foot floating: An artifact where a foot is above the ground when it should be in contact; "However, these objectives may conflict, leading to foot floating, as seen in~#1{tab:retargeting_eval}."
- Foot sliding: An artifact where a foot moves tangentially while it should be stationary in contact; "Additionally, both approaches can produce physically-implausible motions with artifacts like foot sliding, self-penetration, and abrupt joint movements."
- GAE (Generalized Advantage Estimation): A variance-reducing estimator for policy gradient methods that balances bias and variance via a discount factor; "GAE discount factor & $0.95$"
- Geodesic difference: The shortest-path angular difference between two rotations on the rotation manifold; "With the rotation term, we penalize the geodesic difference between the two rotations"
- Ground penetration: An artifact where a body part passes below the ground plane; "As a result, it exhibits both ground penetration and floating (#1{fig:kinematic_artifacts}, second row)."
- Implicit function theorem: A mathematical result used to differentiate through optimality conditions by relating changes in solutions to parameter changes; "First, as is standard in bilevel optimization \cite{zhang_introduction_2024}, the implicit function theorem is used to derive an expression for $\text{d}_{p}{\mathcal{L}$ based on the optimality conditions of the lower level."
- Inverse Hessian: The matrix inverse of the Hessian (second-derivative) matrix, often appearing in implicit differentiation of optimization problems; "which requires computing the inverse Hessian of the lower-level problem"
- Isaac Sim: NVIDIA’s physics-based simulator for robotics and synthetic data generation; "All simulations are performed using Isaac Sim, running $4,096$ environment instances in parallel on a single RTX $5090$ GPU."
- Kinematic chain: A series of links connected by joints, forming a chain-like structure in a robot or character; "Collisions within same kinematic chain ignored, to remove false positives."
- Kinematic singularities: Configurations where small joint changes cause large or undefined end-effector motions, often leading to solver instability; "The most severe failures of the optimization-based baselines occur when the solver converges to local minima, typically near kinematic singularities and joint limits."
- KL-divergence: Kullback–Leibler divergence, a measure of difference between probability distributions, often constrained in PPO; "Desired KL-divergence & $0.009$"
- Latent space: A compressed representation space learned by models to capture essential structure across domains; "often using shared latent spaces~\cite{yan_imitationnet_2023,aberman_skeleton-aware_2020}"
- Log map: The inverse of the exponential map that maps a rotation matrix to a rotation vector; "where maps a rotation matrix to a 3D rotation vector~\cite{sola_micro_2018}."
- Multi-layer perceptron (MLP): A feedforward neural network with multiple fully connected layers and nonlinear activations; "Both the policy and value function are modeled using multi-layer perceptron (MLP) networks with ELU activations"
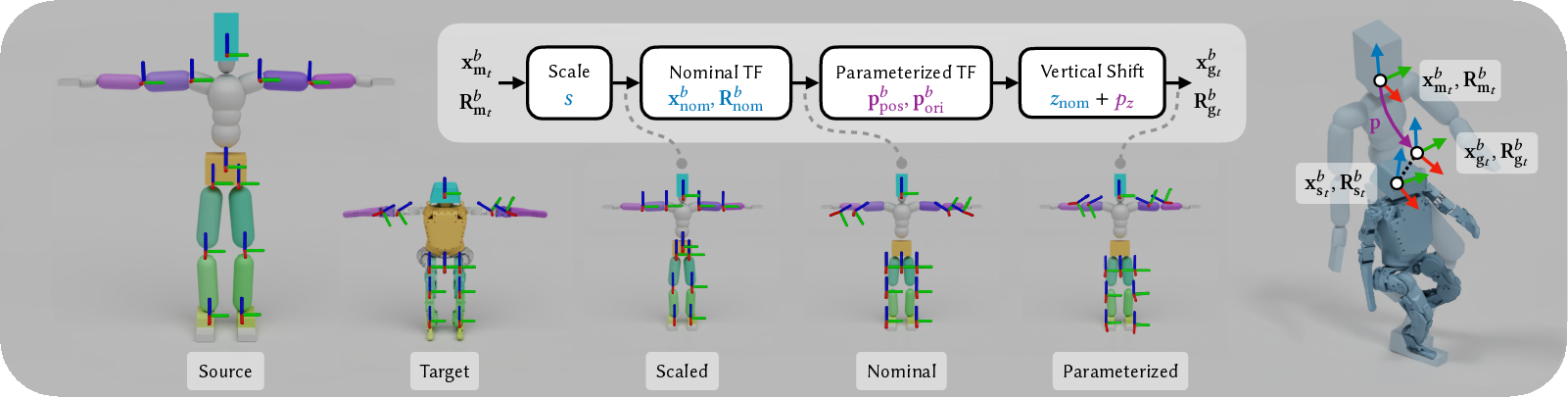
- Nominal configuration: A standard or reference pose used for alignment and parameter extraction (e.g., T-pose); "the user provides the source and target morphologies in a nominal configuration (e.g., a T-pose)"
- PD controller (Proportional–Derivative controller): A feedback controller that applies a control signal proportional to error and its derivative; "The policy outputs joint position setpoints for Proportional-Derivative (PD) controllers"
- Proprioceptive state: Internal sensing of a robot’s own body configuration and motion (e.g., joint angles, velocities); "The character's proprioceptive state"
- Proximal Policy Optimization (PPO): A policy gradient RL algorithm that stabilizes training via clipped objective and KL constraints; "We train our policies using PPO~\cite{schulman_proximal_2017} with an adaptive learning rate~\cite{rudin_learning_2022}."
- Reference State Initialization (RSI): An initialization technique that starts episodes from states sampled from the reference motion; "State-of-the-art motion tracking methods typically rely on Reference State Initialization (RSI)~\cite{peng_deepmimic_2018}"
- Residual Force Control (RFC): A technique that augments control with additional forces/torques to improve tracking and robustness; "allowing residual force control (RFC)~\cite{yuan_residual_2020} to act on the root"
- Semantic correspondences: Human-specified mappings between meaningful parts (rigid bodies) of source and target morphologies; "Our framework requires only a sparse set of semantic rigid-body correspondences"
- Self-collision: Interpenetration between parts of the same articulated body due to poor kinematic or dynamic constraints; "Existing methods often produce physical inconsistencies, such as foot sliding, self-collisions, or dynamically infeasible motions"
- Self-penetration: Geometric interpenetration of a character’s own bodies during motion; "Additionally, both approaches can produce physically-implausible motions with artifacts like foot sliding, self-penetration, and abrupt joint movements."
- Sim-to-real transfer: The process of deploying policies trained in simulation to real hardware; "streamline sim-to-real transfer, they remain largely kinematic and struggle with temporal coherence."
- Stochastic bilevel optimization: Bilevel optimization where objectives/gradients are estimated from stochastic samples; "However, we are unaware of the use of stochastic bilevel optimization for retargeting."
- Swing–twist decomposition: A decomposition of a rotation into a twist about an axis and a swing (the remaining rotation), useful when some axes are unactuated; "We can achieve this by decomposing orientation error into
swing'' andtwist'' components, where ``twist'' is the rotation about a user-specified local axis" - Two-Timescale Approximation (TTSA): A bilevel optimization approach that updates upper-level variables more slowly than lower-level ones within a single loop; "Specifically, we follow the Two-Timescale Approximation (TTSA)~\cite{mingyi_hong_two-timescale_2023}, and update the upper-level decision variables at each iteration of the RL algorithm"
- Wrench: A 6D force–torque vector applied to a rigid body; "The policy outputs joint position setpoints ... and auxiliary wrenches ${w}^{\text{rt}_t$, consisting of forces ${f}^{\text{rt}_t$ and torques $\bm{\tau}^{\text{rt}_t$"
Collections
Sign up for free to add this paper to one or more collections.