- The paper introduces a novel method that injects latent guidance into selectively chosen KV memory slots to control LLM behavior without visible prompt clutter.
- It demonstrates enhanced personality steering, dialogue update ability, and structured reasoning while achieving significant KV cache reduction, up to 118×.
- Empirical evaluations confirm that the approach reduces control drift and maintains performance across both dense and MoE architectures.
Memory Inception: Latent-Space KV Cache Manipulation for Steering LLMs
Motivation and Context
Persistent, domain-specific guidance for LLMs is critical for applications requiring controlled persona, dialogue tone, and reusable reasoning heuristics. Standard prompting materializes guidance text throughout the input context and cache, making it visible and incurring full-layer KV storage costs. Activation steering techniques, such as CAA, intervene in residual space, offering compactness but only weak control—especially for long or structured guidance.
Memory Inception (MI) introduces a new interface: steering models in latent attention space by targeted, layer-specific injection of text-derived KV-memory banks. This approach avoids visible prompt clutter and the inefficiency of per-layer duplication, while retaining text-faithful and updateable guidance. MI leverages the selective placement principle: guidance resides only where model routing demands, yielding substantial KV-cache compression and strong behavioral control.
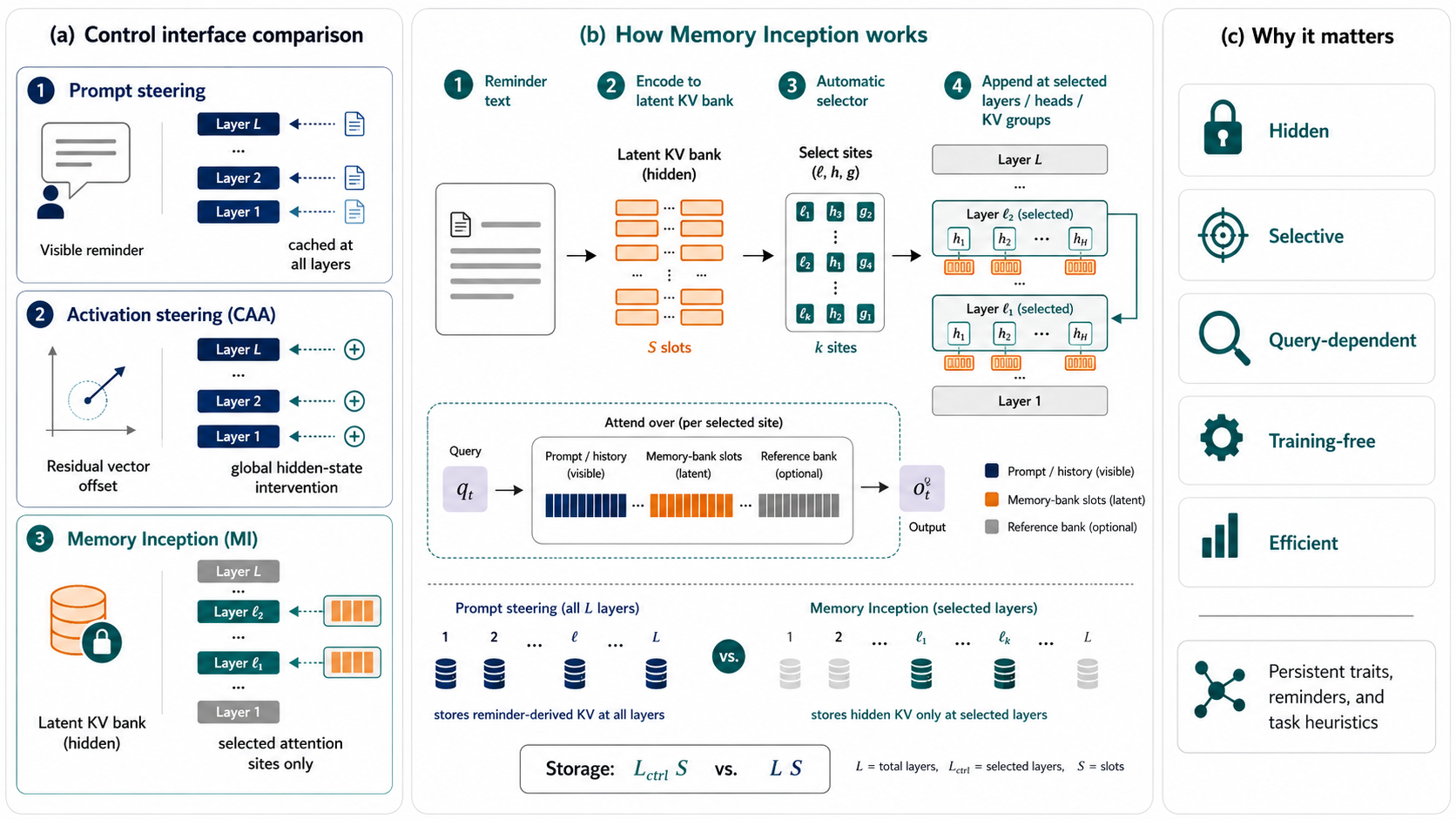
Figure 1: Memory inception—concisely encoded reminders are injected into latent KV memory-bank slots at specifically chosen layers, heads, or KV groups during decoding, remaining hidden from the visible transcript and accessed via query-dependent attention.
Methodology
MI encodes reminders, persona descriptors, and reasoning heuristics as latent KV slots, constructed by projecting base-model hidden states through attention-specific key/value matrices. The guiding principle: attach these memory banks exclusively at a calibrated subset of attention layers and sites, selected automatically via scoring query-key alignment relative to reference banks. This ensures efficient coverage and targetable routing, optimizing both control strength and drift minimization.
Detailed selection utilizes calibration-phase diagnostics, maximizing target-reference alignment while minimizing prompt mass. For dense transformers (Llama3.1), banks are placed per attention head; in MoE architectures (Qwen3), placement is per grouped-query KV group.

Figure 2: Memory-bank attention steering for both dense and MoE decoders, with reminders encoded as latent slots and routing selectivity determined by layer and attention-site selection.
Multiple memory banks—target, reference (opposite), auxiliary—compete for routing via normalized evidence scores (β(b)) to avoid bias from slot count inflation. Rotary position embeddings (RoPE) are handled via canonical pre-RoPE storage, ensuring position-agnostic access and compatibility with extended contexts.
Empirical Evaluation
MI is benchmarked across three axes:
- Personality Steering: Big Five tasks (IPIP-50) and generation, evaluating control–drift tradeoff relative to baseline prompting and CAA. Metrics include questionnaire trait shifts (DAS, GAS) and coherence scores from external LLM judges.
- Updateable Guidance: Dialogue-shift tasks with mid-conversation style updates, testing persistence and adaptation without visible prompt rewriting. Post-shift alignment captures adaptation efficacy under fixed prompt budgets.
- Structured Reasoning: PHYSICS and HARDMath, employing latent heuristic banks to steer reasoning, with partial-credit evaluation emphasizing heuristic-driven solution quality.
MI consistently outperforms or matches prompting on control–drift metrics, exhibiting much stronger alignment and lower non-target drift than CAA, especially on Qwen3. For structured guiding, MI achieves highest post-shift alignment and decisively wins on PHYSICS, outperforming prompt-based approaches in 10/12 cells while reducing KV storage up to 118×.
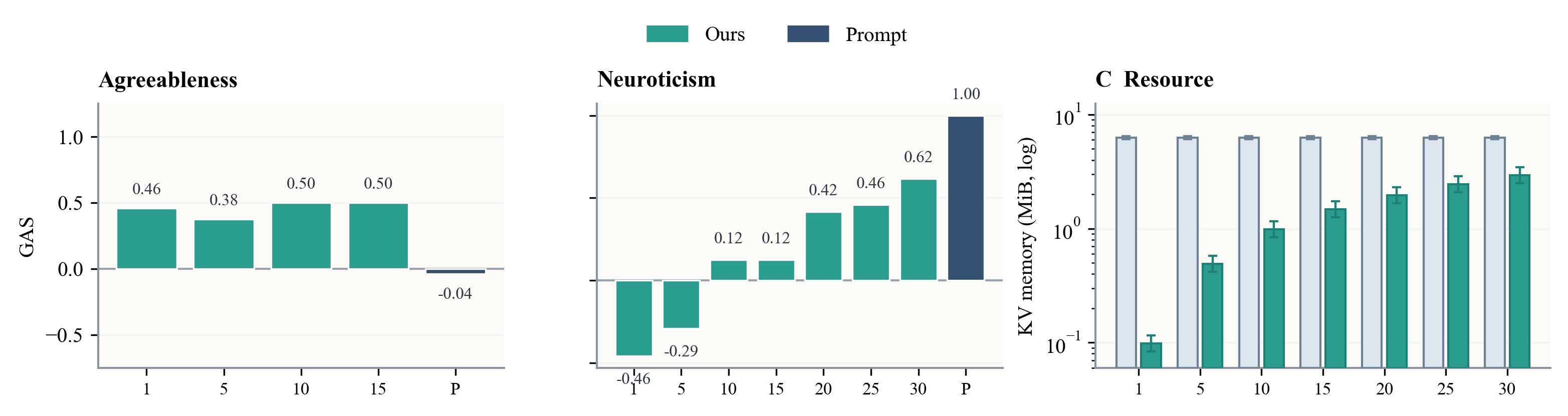
Figure 3: GAS layer-selection ablation—MI achieves efficient control with minimal layers on easy traits; harder traits require broader placement but always with reduced KV footprint compared to prompting.
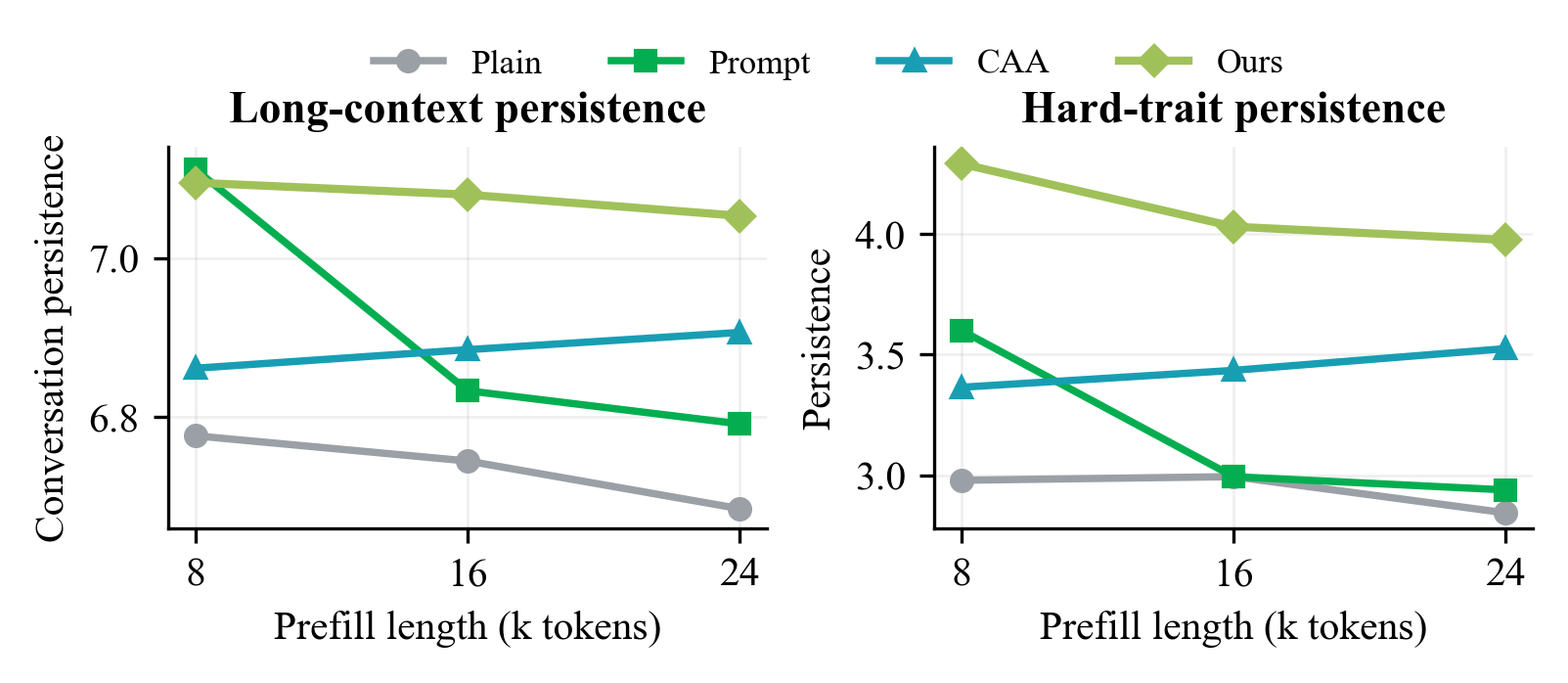
Figure 4: Long-context persistence ablation—MI retains target style under extensive opposite-style prefills, exhibiting superior persistence to both prompt and CAA methods.
Systems Efficiency and KV Cache Reduction
MI’s core systems advantage is compaction: steering guidance is stored as latent slots only at selected layers/sites, drastically reducing KV-cache footprint. Savings scale with guidance length: from 6× for short descriptors to 60–118× for heuristic banks in PHYSICS and HARDMath. Empirical resource panels demonstrate that even hardest control cases never require full-layer materialization, underscoring MI's suitability for persistent or structured guidance regimes.
Analysis and Ablations
Layer-selection ablations validate that easy traits are controllable with minimal coverage; harder traits demand broader allocation but still below prompt baseline. MI’s superiority in long-context persistence confirms that latent guidance is robust against contextual dilution, a key limitation for visible prompt methods.
General capability checks (GSM8K, MMLU) affirm that MI induces no significant capability degradation compared to baseline or prompt steering, ensuring broad applicability without negative transfer.
Implications and Future Directions
MI establishes latent KV steering as a powerful, training-free interface with practical benefits for persistent persona, adaptive dialogue, and structured reasoning, simultaneously achieving competitive or superior control with massive KV-cache reduction. Theoretically, MI exposes novel directions in selective intervention and attention-state memory allocation, providing a blueprint for system-level efficiency constrained by behavioral fidelity.
Potential developments include:
- Enhanced selector calibration for fine-grained, task-adaptive placement.
- Extension to more diverse architectures and inference stacks.
- Integration with retrieval-Augmented and memory-augmented LMs for hierarchical guidance.
- Improved auditability and disclosure mechanisms for latent steering artifacts, as highlighted in deployment safeguards.
Conclusion
Memory Inception (MI) offers a principled, efficient solution for latent-space steering of LLMs—balancing control strength, drift mitigation, and KV-cache economy. Empirical results confirm MI's efficacy across personality, dialogue, and reasoning domains, especially on extended or structured guidance. Limitations necessitate careful selector calibration and bank quality control, with audit protocols vital against covert policy injection. MI thus positions latent KV memory as an essential primitive for next-generation controllable, efficient LLM systems (2605.06225).

