- The paper introduces PSMTrack, which employs sparsity-aware expert modeling and dynamic pondering to adaptively fuse multi-sparsity event representations.
- It integrates a hierarchical Vision Transformer backbone that progressively combines sparse, medium, and dense event frames to enhance tracking efficiency.
- Empirical results on benchmark datasets show improved accuracy and speed, setting a new state-of-the-art in event stream-based visual tracking.
Introduction
Event cameras have emerged as a compelling alternative to standard RGB sensors by asynchronously detecting pixel-wise brightness changes, enabling high temporal resolution, high dynamic range, and low latency. While event-driven sensing is inherently robust to adverse conditions such as motion blur and poor illumination, existing event-based trackers often fall short in computational efficiency and accuracy—primarily due to their insensitivity to event sparsity and reliance on rigid temporal aggregation strategies. The authors address these deficiencies by introducing a unified framework, PSMTrack, centered on explicit event sparsity modeling, adaptive dynamic inference, and expert specialization via a transformer-based Mixture-of-Experts architecture.
Multi-Sparsity Event Representation and Progressive Token Integration
Event streams are naturally characterized by spatial sparsity and variable temporal density. Exploiting this, PSMTrack constructs three event frame representations (sparse, medium-density, dense) from different temporal window lengths. These representations offer complementary information: short windows yield sharp contours, while long windows provide aggregated motion cues.
Rather than simultaneously feeding all representations into a deep backbone—leading to quadratic complexity—PSMTrack adopts a three-stage Vision Transformer (ViT) backbone. Each stage assimilates a new sparsity level, allowing progressive feature fusion and cost-effective hierarchical learning.
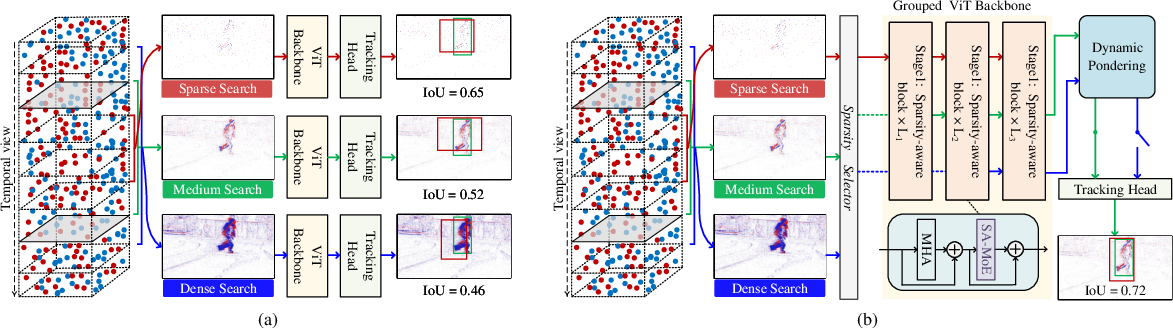
Figure 1: (a) Variable temporal windows yield distinct event densities and tracking scenarios, (b) overview of the dynamic pondering sparsity-aware mixture-of-experts transformer framework.
The network crops, embeds, and partitions event frames, successively integrating dense, medium-density, and sparse search regions via a feature transformation and concatenation mechanism at each stage. This stratified design ensures computational tractability while maximizing cross-scale feature interaction.
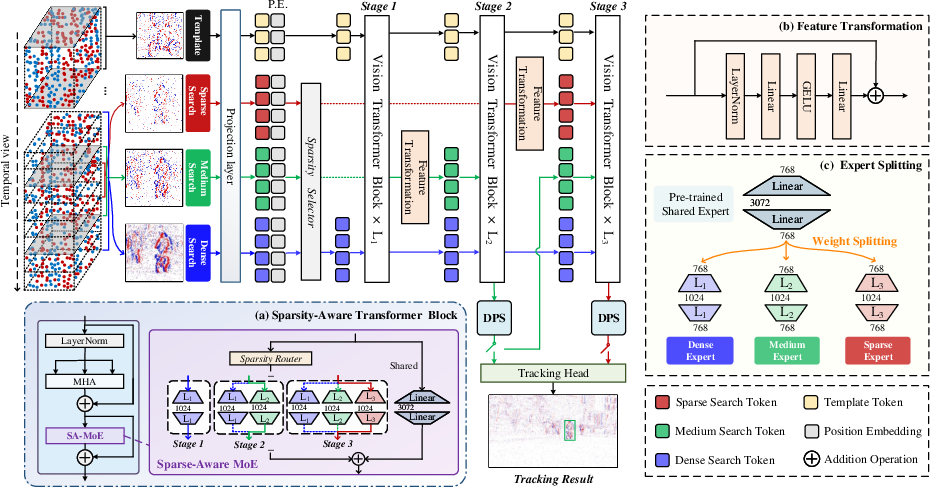
Figure 2: Hierarchical backbone with multi-sparsity token integration, sparsity-aware MoE, and dynamic pondering for adaptive inference depth.
Sparsity-aware Mixture-of-Experts Architecture
Standard feed-forward networks (FFN) in transformers apply homogeneously to all token types, limiting their capacity to model the heterogeneity present in event data. PSMTrack mitigates this by introducing a Sparsity-Aware Mixture-of-Experts (SA-MoE) module in the first block of each stage. This module decomposes the FFN into three sub-experts—each specializing in a particular event sparsity level (dense, medium, sparse)—plus a shared global expert. An MLP-based routing network, utilizing global pooled representations and Gumbel-Softmax selection, dynamically dispatches tokens to appropriate experts, whose outputs are combined with the shared output. This targeted specialization results in enhanced discrimination of sparsity-dependent cues without incurring excessive computational cost.
Dynamic Pondering for Adaptive Inference
To further optimize computation-accuracy tradeoffs, especially in trivially separable scenarios, PSMTrack integrates a Dynamic Pondering Strategy (DPS) modeled after adaptive computation time paradigms. Starting after sufficient early-layer processing, DPS employs a scalar halting predictor at each transformer block to evaluate if further inference is warranted. The prediction is based on global average-pooled features; halting occurs once the cumulative probability crosses a prescribed threshold. This mechanism dynamically adjusts the depth of executed layers per input, penalized during training to favor early exit when possible.
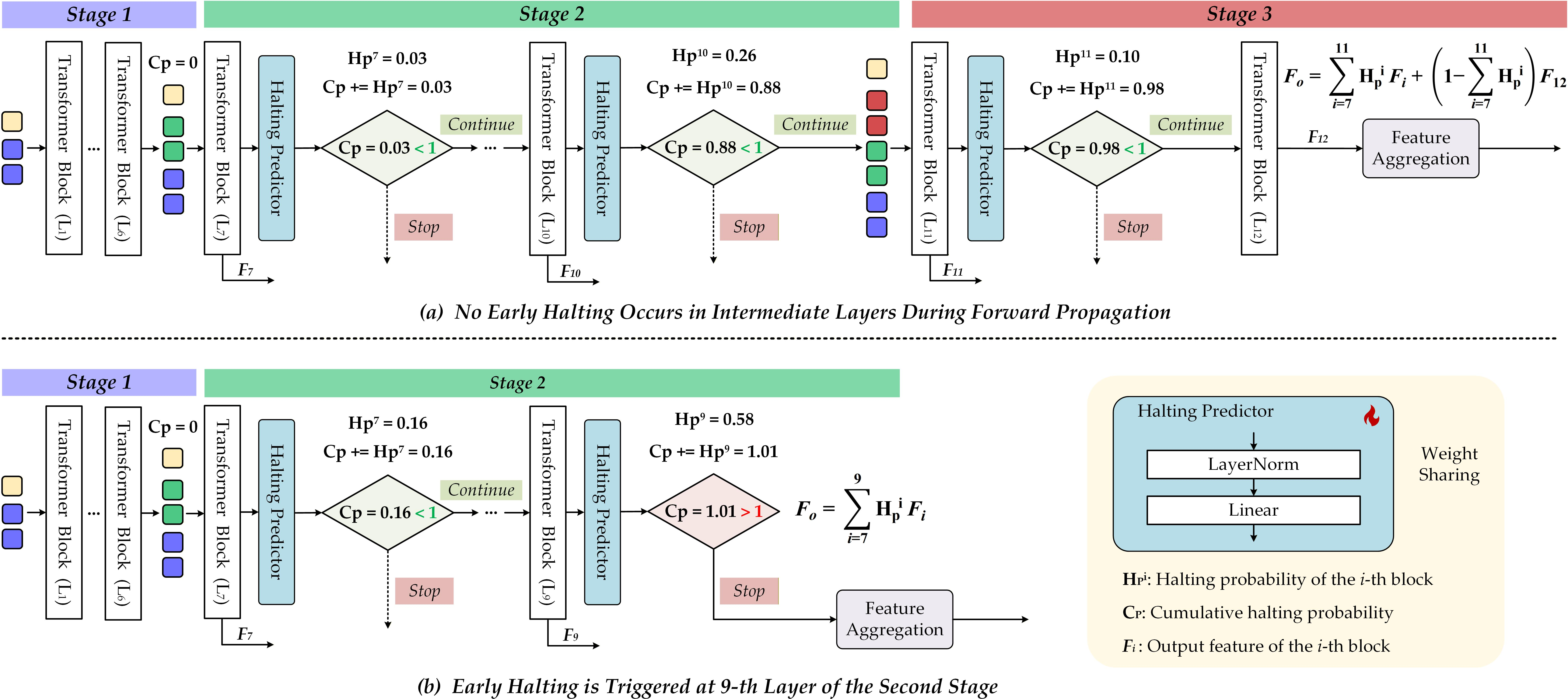
Figure 3: DPS pipeline; model continues to the final layer for challenging sequences or halts early for simpler cases.
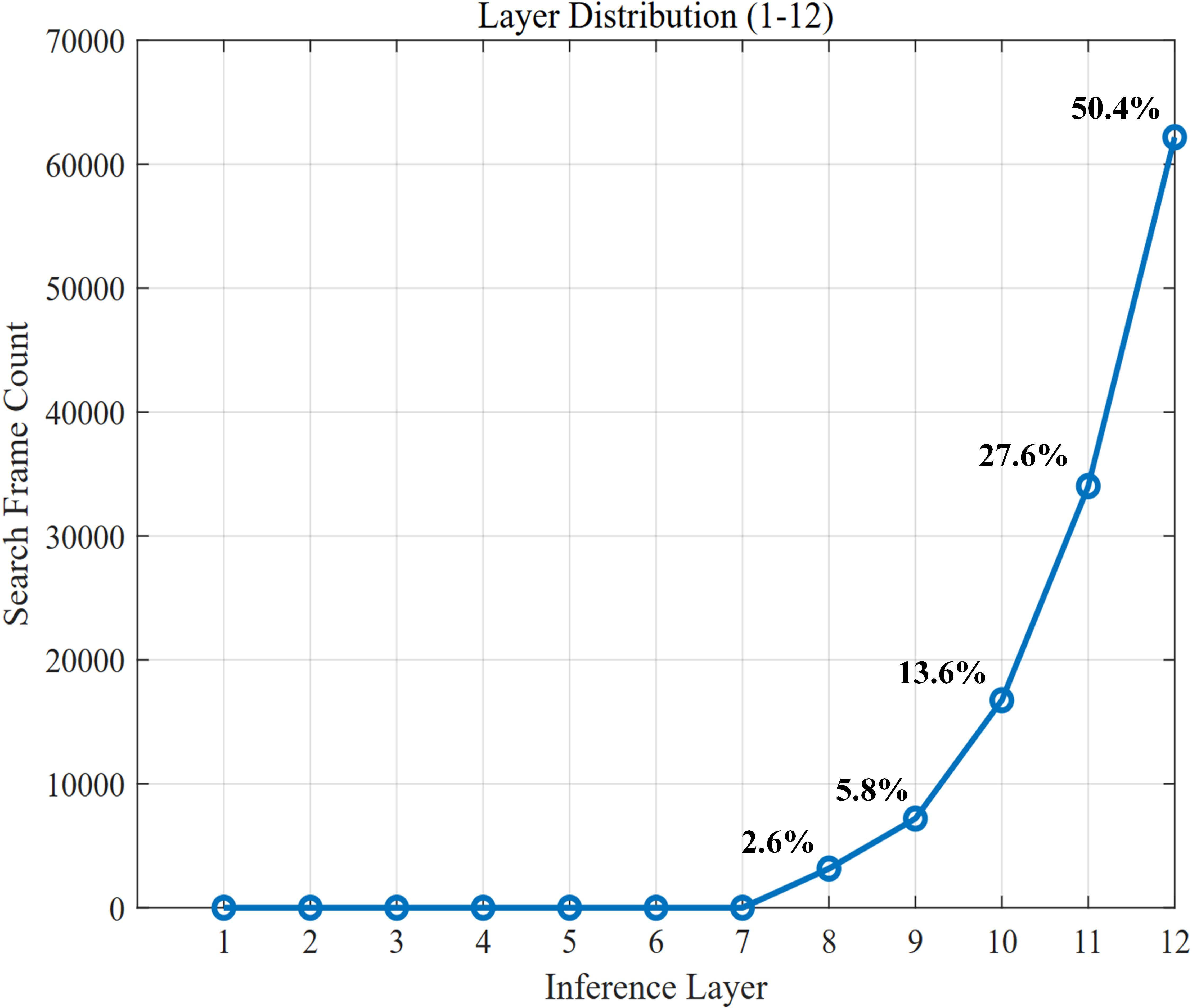
Figure 4: Distribution statistics of inference layer termination on EventVOT, showing early exit in approximately half the sequences.
Empirical Results and Comparative Analysis
The authors conduct rigorous evaluation on three prominent event tracking benchmarks: FE240hz, COESOT, and EventVOT datasets. PSMTrack consistently achieves leading performance, exhibiting better accuracy vs. FPS tradeoffs than competing approaches, owing to its multi-sparsity modeling and adaptive computation.
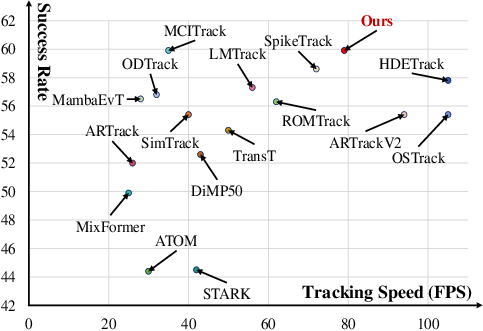
Figure 5: SR–FPS analysis; PSMTrack attains superior tracking accuracy and efficiency trade-offs compared to SOTA methods.
Notably, on the EventVOT benchmark, PSMTrack with DPS (Ours-II) achieves an SR of 59.9%, PR of 66.2%, NPR of 75.4% at 79 FPS, outperforming all listed event-based and frame-based SOTA trackers in both accuracy and inference speed. The ablation analysis demonstrates that dynamic pondering increases FPS by 41% while incurring only a 0.3% drop in success rate. The hierarchical, progressive token fusion and expert specialization via MoE confer further measurable gains over strong baselines.
Qualitative Insights
Visualization of event representations, attention distributions, and output response maps affirms the model's ability to adapt its processing according to input sparsity and context complexity.

Figure 6: Dense, medium, and sparse event representations highlight complementarity across temporal windows.
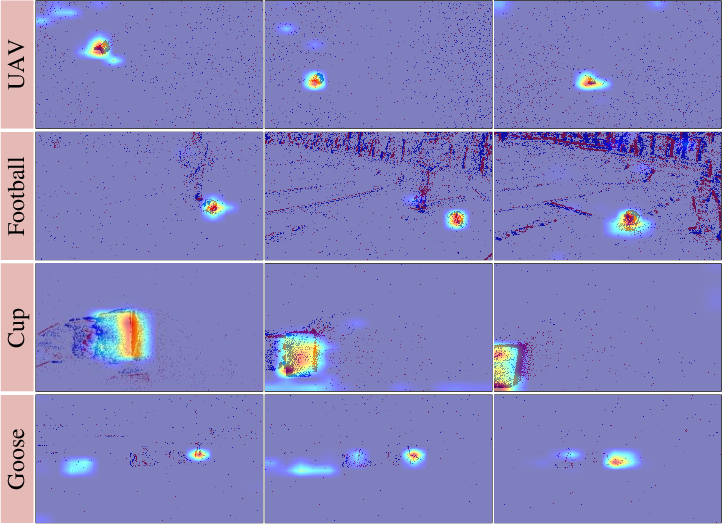
Figure 7: The attention maps from PSMTrack show consistent focus on targets even in cluttered or occluded scenes.
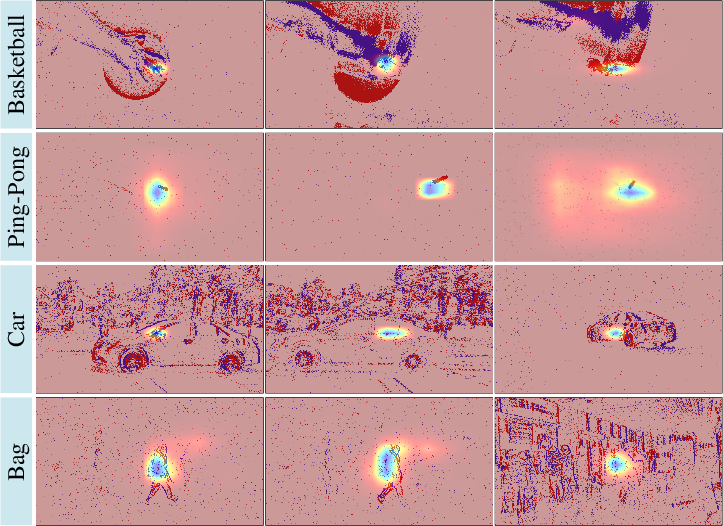
Figure 8: Response maps demonstrate tight and concentrated peaks over the tracked objects, reflecting robust localization.
Qualitative comparison against SOTA trackers on challenging visual sequences further demonstrates better alignment with ground truth and resilience to distractors and occlusions.

Figure 9: Example qualitative tracking results versus competitive methods; PSMTrack exhibits superior robustness under complex conditions.
Attribute-wise Robustness and Component Contributions
Attribute-wise breakdowns reveal PSMTrack's notable gains under scenarios characterized by similar interfering objects, background clutter, full occlusion, and static backgrounds—underscoring the benefit of multi-sparsity context modeling.
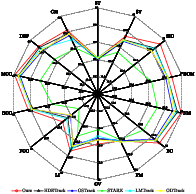
Figure 10: Performance per challenge attribute—strongest improvements under SIO, BC, NM, and FOC conditions.
Component-wise ablations validate that progressive multi-sparsity integration, MoE specialization, and dynamic pondering each yield tangible quantitative improvements. The combination is essential for attaining the best efficiency–accuracy balance.
Limitations and Directions for Future Work
Despite significant gains, the framework does not currently exploit semantic linguistic priors or contextual cues from multimodal foundation models. Incorporating language-guided initialization, human-in-the-loop description, or vision-language representation learning could further enhance robustness under ambiguous or under-constrained scenarios. There is also potential in adapting the dynamic inference paradigm to multimodal and continual learning regimes, as well as linking event-based representations to broader temporal reasoning models.
Conclusion
PSMTrack establishes a new paradigm for event stream-based object tracking by uniting hierarchical multi-sparsity token integration, sparsity-adaptive expert specialization, and dynamic computation allocation within a transformer framework. Its carefully engineered pipeline results in both superior tracking accuracy and efficient inference. This work implies that sparsity-aware mixture modeling and adaptive inference are vital ingredients for the next generation of event-driven perception systems and opens up new research directions for context-adaptive, resource-efficient visual learning in both unimodal and multimodal domains.