- The paper introduces a framework that distills a multi-step optimal transport flow matching teacher into a single-step consistency model for rapid high-fidelity reconstruction.
- It employs a three-stage pipeline—unconditional teacher training, consistency distillation via TrigFlow, and inference through trajectory initialization—to ensure precise reconstruction.
- Experimental results across 2D fluid benchmarks show competitive pointwise and spectral fidelity with a 12× reduction in inference time and fewer parameters.
Improved Consistency-Distilled Flow Matching for Physical Fidelity Reconstruction in Dynamical Systems
Reconstruction of high-fidelity flow fields from low-resolution observations is a central task in scientific machine learning, driven by the need to replace computationally intensive direct numerical simulations (DNS) for turbulent flows and multiscale physical systems. Existing generative approaches—especially denoising diffusion models (DDMs) and flow matching (FM) models—show high fidelity but necessitate multiple iterative steps at inference, imposing substantial latency constraints for ensemble forecasting, real-time visualization, or operational simulation workflows. The paper proposes a distillation framework that compresses a multi-step optimal transport flow-matching (OT-FM) “teacher” into a single-pass TrigFlow consistency model (sCM) “student”, exploiting the OT path structure to inject low-resolution observations at inference via noise initialization.
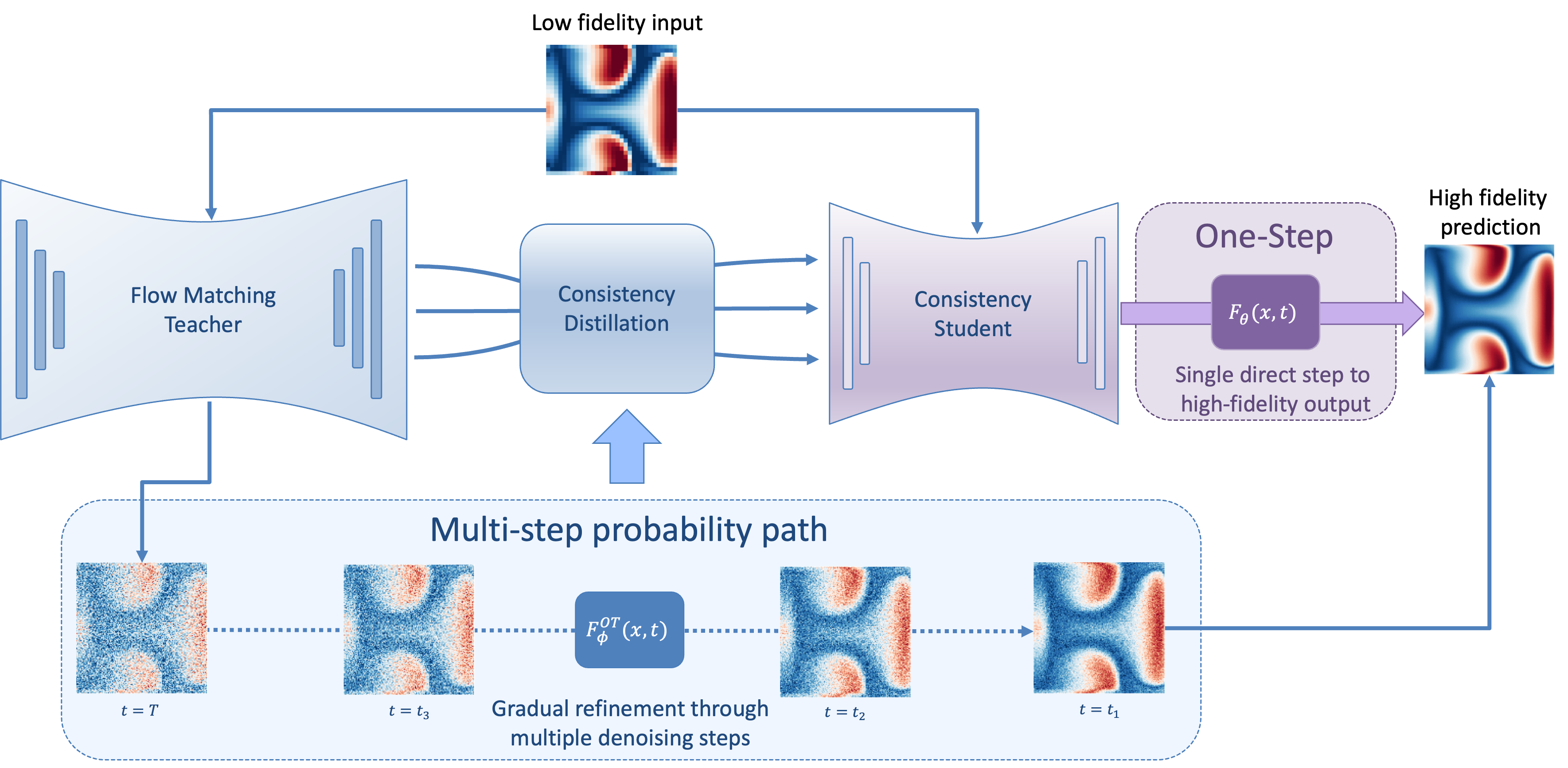
Figure 1: A schematic overview of the pipeline: multi-step OT-FM teacher distilled into single-step TrigFlow sCM student; LR conditioning incorporated at inference by trajectory initialization.
Methodology
The central pipeline consists of three stages:
- Unconditional Training of OT-FM Teacher: The teacher is trained fully unconditionally on high-resolution data, leveraging the OT schedule to produce straight-line latent interpolations between Gaussian noise and data samples. The teacher operates as a continuous-time velocity field, minimizing flow-matching loss under the conditional coupling.
- Consistency Distillation (sCM/TrigFlow Student): Distillation follows the simplified continuous-time consistency distillation (sCD) framework, parameterizing trajectories via TrigFlow and regressing the student’s velocity onto a tangent constructed via a Jacobian-vector product (JVP) using teacher supervision. OT-FM and TrigFlow are losslessly equivalent, allowing consistent teacher-to-student supervision without retraining.
- Inference via Trajectory Initialization: At inference, the low-resolution field is nearest-neighbor upsampled and mixed with Gaussian noise at a chosen intermediate OT-path time τ, forming the initialization. The sCM student maps this initialization directly to the high-fidelity endpoint, requiring only a single forward evaluation. The τ parameter effectively trades LR fidelity for fine-scale realism.
Experimental Evaluation
Benchmarks and Baselines
Three canonical 2D fluid benchmarks were used for evaluation:
- Smoke Buoyancy (32→128): Buoyancy-driven transport, high resolution 1282, large dataset (173,824 frames).
- Turbulent Channel Flow (64→192): Anisotropic wall turbulence, medium resolution 1922 (38,080 frames).
- Kolmogorov Flow (64→256): High-resolution 2D turbulence, periodic boundaries (12,800 frames).
Baselines include nearest-neighbor LR upsampling, multi-step OT-FM teacher (Euler, Heun, RK5), standard DDPM/DDIM and DPM-Solver++ diffusion, and from-scratch sCM (no teacher supervision).
Numerical Results
Across all benchmarks, the sCM-distilled student achieves competitive pointwise (RL2) and spectral (PSDD) metrics, matching or exceeding the teacher’s fidelity, while requiring roughly half the parameters and a 12× reduction in inference cost. Notably:
- On Smoke Buoyancy, the distilled sCM outperforms the multi-step RK5 teacher in RL2, SSIM, and PSDD; from-scratch sCM is substantially inferior, isolating distillation as the key factor.
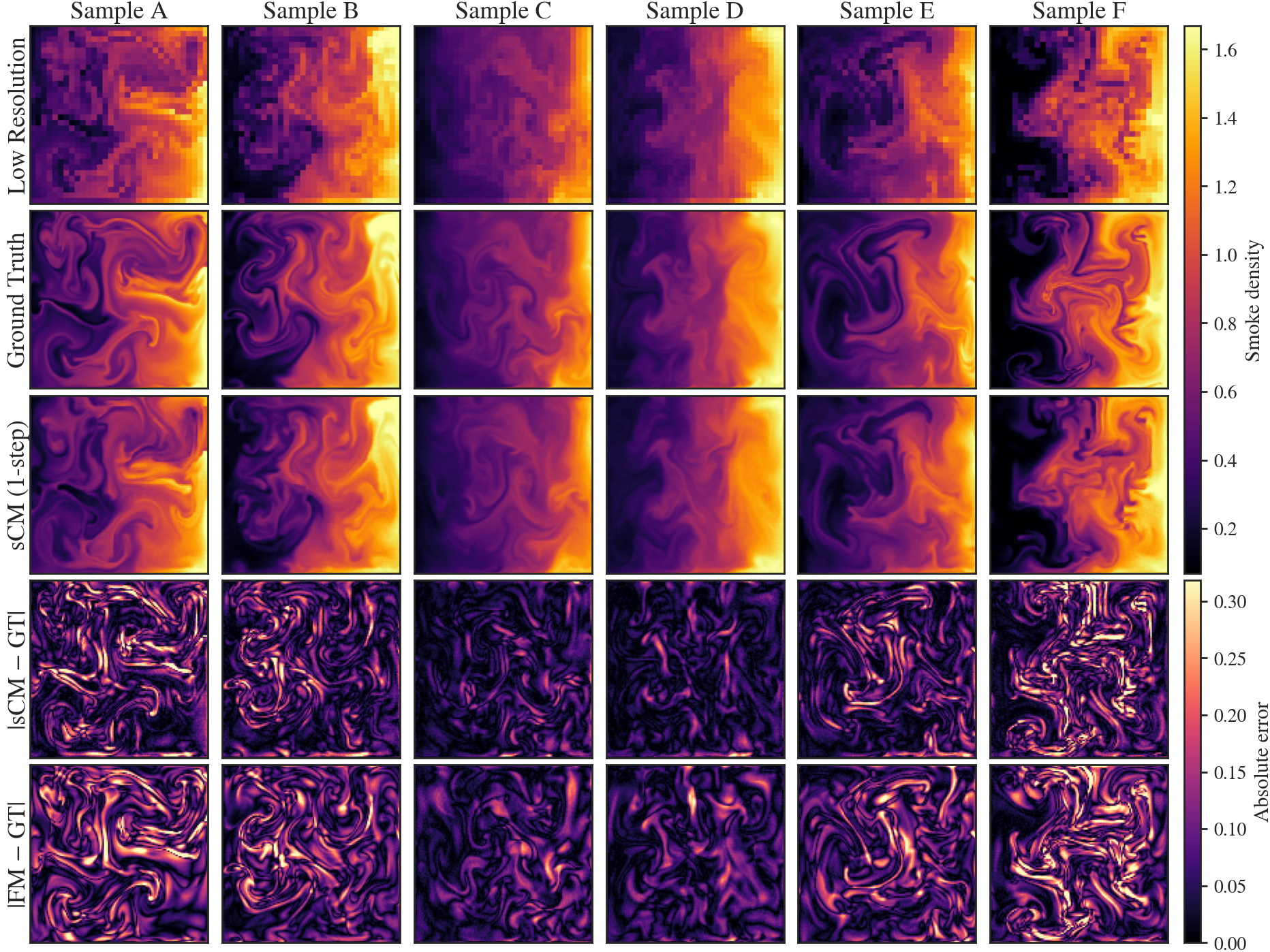
Figure 2: Visually, sCM student reconstructions preserve fine-scale vortical features and yield error maps comparable to or lower than the teacher—confirming metric superiority.
- On Kolmogorov Flow, the one-step student matches or exceeds teacher fidelity across all metrics, with a τ0 reduction in PSDD, indicating superior preservation of turbulent spectral characteristics.
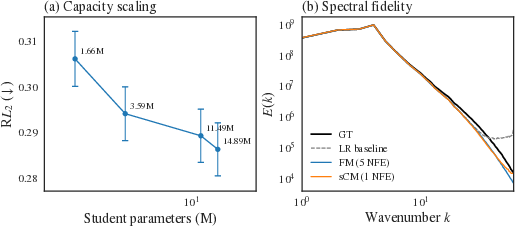
Figure 3: Scaling and spectral fidelity for Kolmogorov Flow: student achieves optimal spectral match above modest capacity, with spectra tightly tracking ground truth.
- On Turbulent Channel Flow, the student is marginally behind the teacher in spectral fidelity but remains superior to diffusion baselines, with qualitative error concentrated in near-wall streaks.
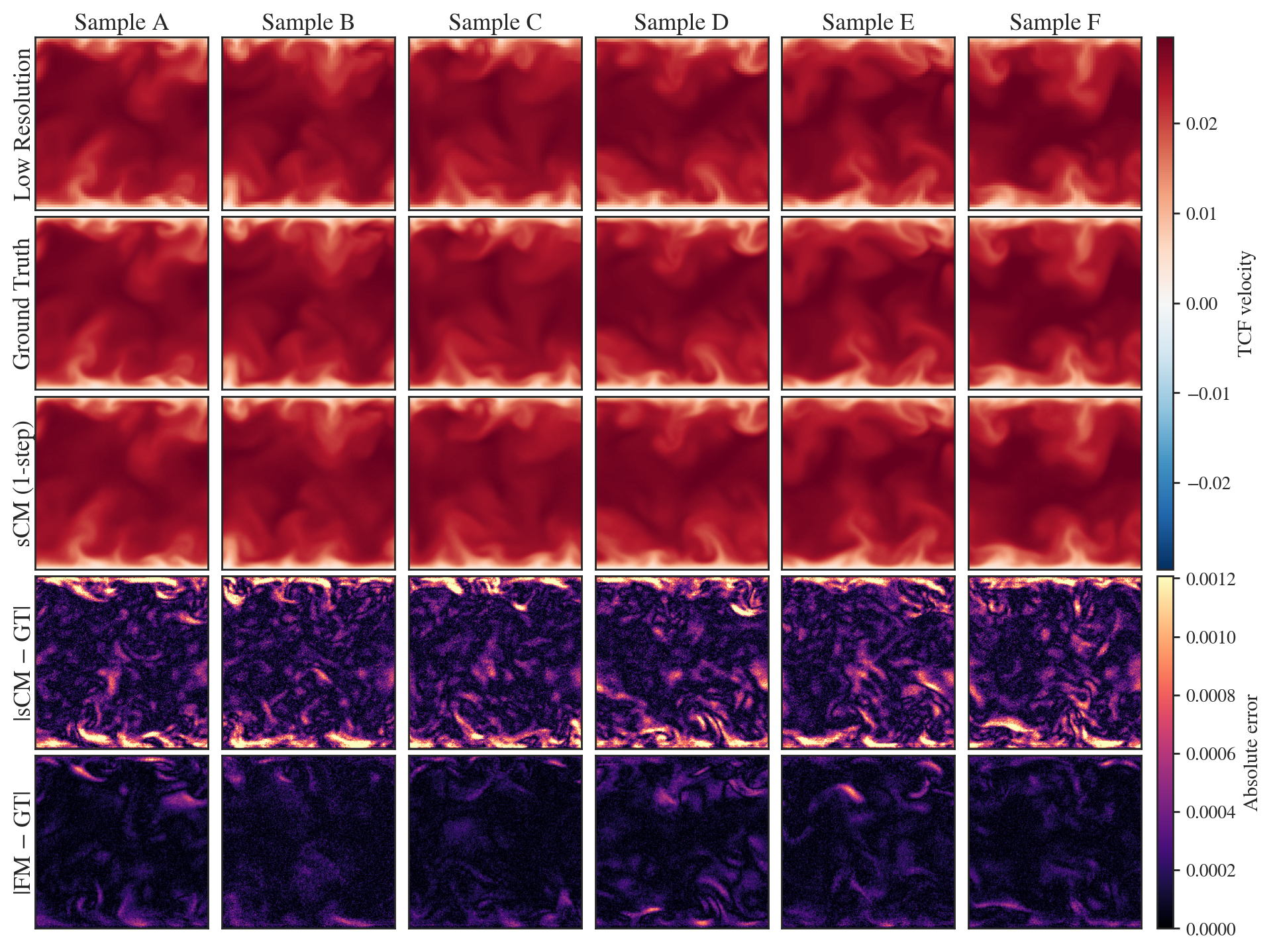
Figure 4: Qualitative comparison—student and teacher recover anisotropic near-wall structures, with error localized to regions of high fluctuation.
Spectral Analysis Across Benchmarks
Student models retain high performance on radially-averaged power spectra, matching ground truth across the inertial range for Smoke Buoyancy and Kolmogorov (Figure 5), with minor gaps at high wavenumber in Turbulent Channel Flow. The spectral metrics confirm the capacity of the distilled model to achieve multi-scale fidelity in turbulent flows.
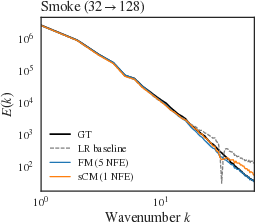
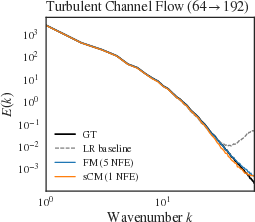
Figure 5: Radially-averaged power spectra show sCM student maintaining target spectra, outperforming baseline LR and diffusion models.
Noise Strength and Inference Sensitivity
A sweep over noise injection parameter τ1 demonstrates a broad plateau in RMSE, validating robustness of the inference mechanism. Model sensitivity to random noise at inference remains low for pointwise metrics, with larger fluctuations only in spectral error, consistent with stochastic generation properties.
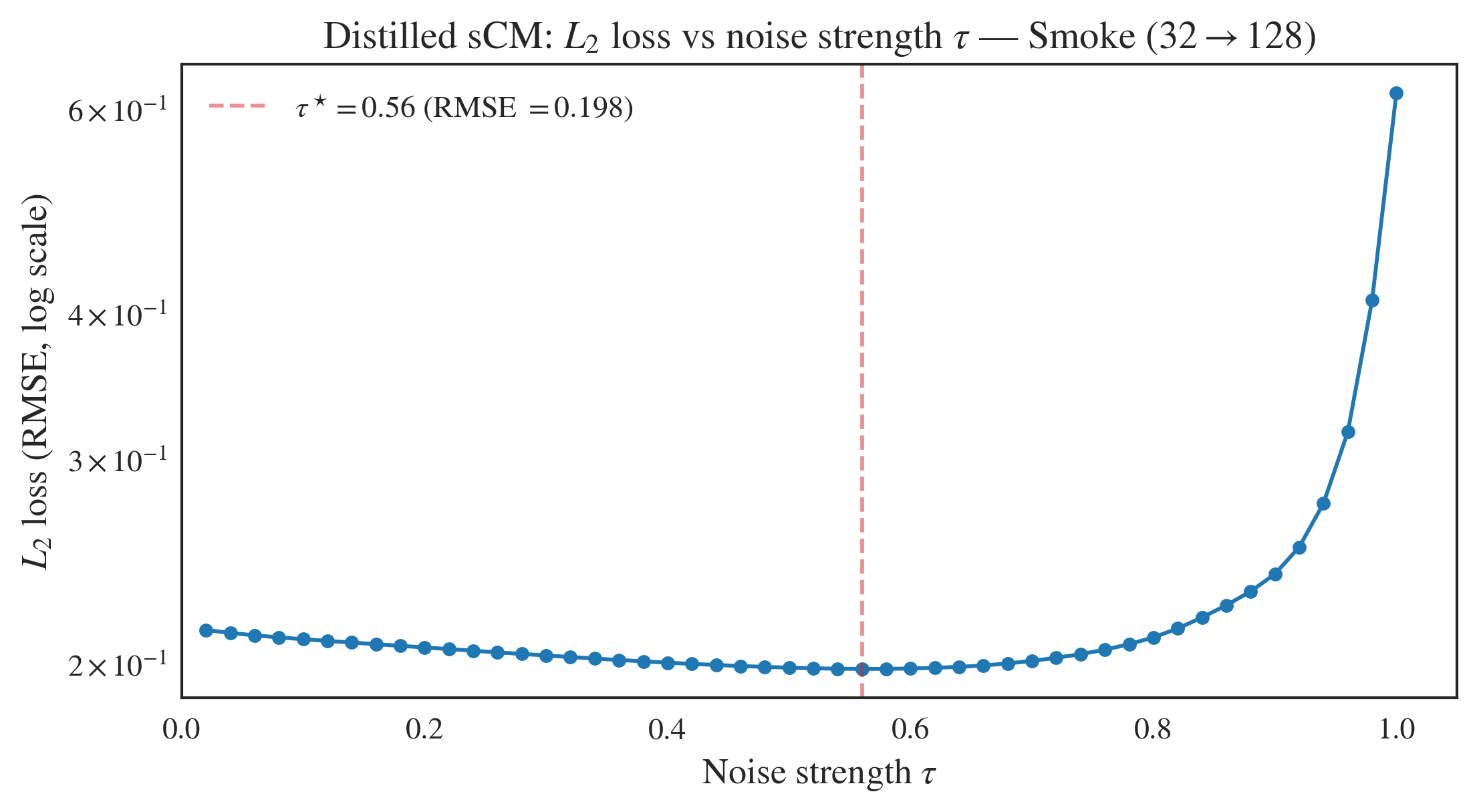
Figure 6: RMSE is robust to τ2 over a wide range, confirming stability and flexibility for practical deployment.
Inference Efficiency
Distilled sCM reduces practical inference time per frame by τ3 compared to multi-step OT-FM teacher at all resolutions, with the wall-clock speedup constant across spatial scales.
Implications and Future Directions
The results provide empirical confirmation that consistency distillation delivers substantial acceleration—without retraining the teacher—for scientific generative modeling tasks requiring physical fidelity. The approach is particularly well-suited for ensemble and real-time settings, enabling pointwise and spectral fidelity reconstruction at reduced hardware and latency costs.
The methodology is currently limited to 2D, stationary fields and relies on the assumption that upsampled LR is sufficiently close to an OT-path state. Extension to 3D flows, boundary dynamics, sparse conditioning, and application to weather or combustion domains requires further research. Adaptive or content-dependent τ4 schedules could reduce the residual spectral gap. Parameter-matched comparisons against diffusion baselines remain future work.
As scientific generative modeling expands to higher resolution and capacity, the combination of OT-path structure, consistency distillation, and single-pass inference forms a robust blueprint for deployment at scale. The framework is generalizable to other dynamical systems and opens possibilities for compressing large scientific generative models into compact, efficient reconstructions without modifying teacher architectures or requiring task-specific conditioning machinery.
Conclusion
The paper establishes a principled and empirically validated recipe for fast, high-fidelity scientific flow reconstruction via improved consistency-distilled flow matching. The distilled sCM student achieves competitive—or superior—metrics with a dramatic reduction in parameter count and inference cost. The approach is transferable across fluid benchmarks and scalable to high resolutions, underscoring its practical utility for modern computational workflows in scientific machine learning (2605.05975).