- The paper introduces a novel risk-sensitive aggregation approach that penalizes reward variance to prevent constraint neglect in multi-objective RLHF.
- It employs a soft-min operator to balance mean aggregation with strict minimum enforcement, achieving robust performance across health and tool-calling benchmarks.
- Empirical results demonstrate enhanced bottleneck constraint adherence and training stability, significantly boosting scores and accelerating convergence compared to GRPO and GDPO.
RVPO: Risk-Sensitive Alignment via Variance Regularization
Motivation and Problem Statement
The paper addresses constraint neglect in critic-less RLHF for LLMs performing multi-objective alignment. Existing aggregation schemes (arithmetic mean in GRPO and GDPO) induce loss compensation: the optimizer is blind to bottleneck objective failures when high-magnitude rewards on easier objectives are present. This produces policies that over-optimize unconstrained metrics (e.g., verbosity) at the cost of safety, formatting, or completeness requirements. Robust RLHF for LLMs requires policies to satisfy all constraints, especially the strictest or lowest-performing one, without explicit constraint specification or costly memory overhead from value networks.
RVPO introduces a risk-sensitive reward aggregation mechanism using variance regularization. Standardized rewards Zj across M objectives are aggregated not by their mean, but by a variance-penalized objective:
ARVPO-explicit(g)=μZ(g)−β⋅(σZ(g))2
To avoid instability and excessive penalty in high-dimensional spaces (especially when M is small or heterogeneous), RVPO replaces explicit variance penalization with a LogSumExp (SoftMin) operator:
ARVPO(g)=−k1ln(M1j=1∑Me−kZj(g))
Here, the risk coefficient k interpolates between mean aggregation (k→0) and strict minimum (k→∞). Mathematically, RVPO is a proper generalization of GDPO and allows smooth control over the mean-min tradeoff. Second-order Taylor expansion demonstrates that the SoftMin is a robust proxy for variance penalization (with β=k/2), aligning optimization pressure with the most difficult constraints.
Empirical Evaluation
RVPO is evaluated against GRPO and GDPO across two domains:
- Rubrics-as-Rewards (RaR): LLM-judged multi-axis rubrics (5–17 criteria) for medical and scientific reasoning (HealthBench and GPQA-Diamond benchmarks).
- Tool Calling (RLLA-4k): Two reward signals (execution correctness, format compliance) in rule-based function-calling trajectories.
RVPO is implemented via Verl/TRL on Qwen2.5 models (1.5B–14B), with risk coefficient k annealed during training. The evaluation follows micro-averaged rubric scores for HealthBench and BFCL-v3 metrics for tool calling. All methods are trained and tested under identical compute and data regimes.
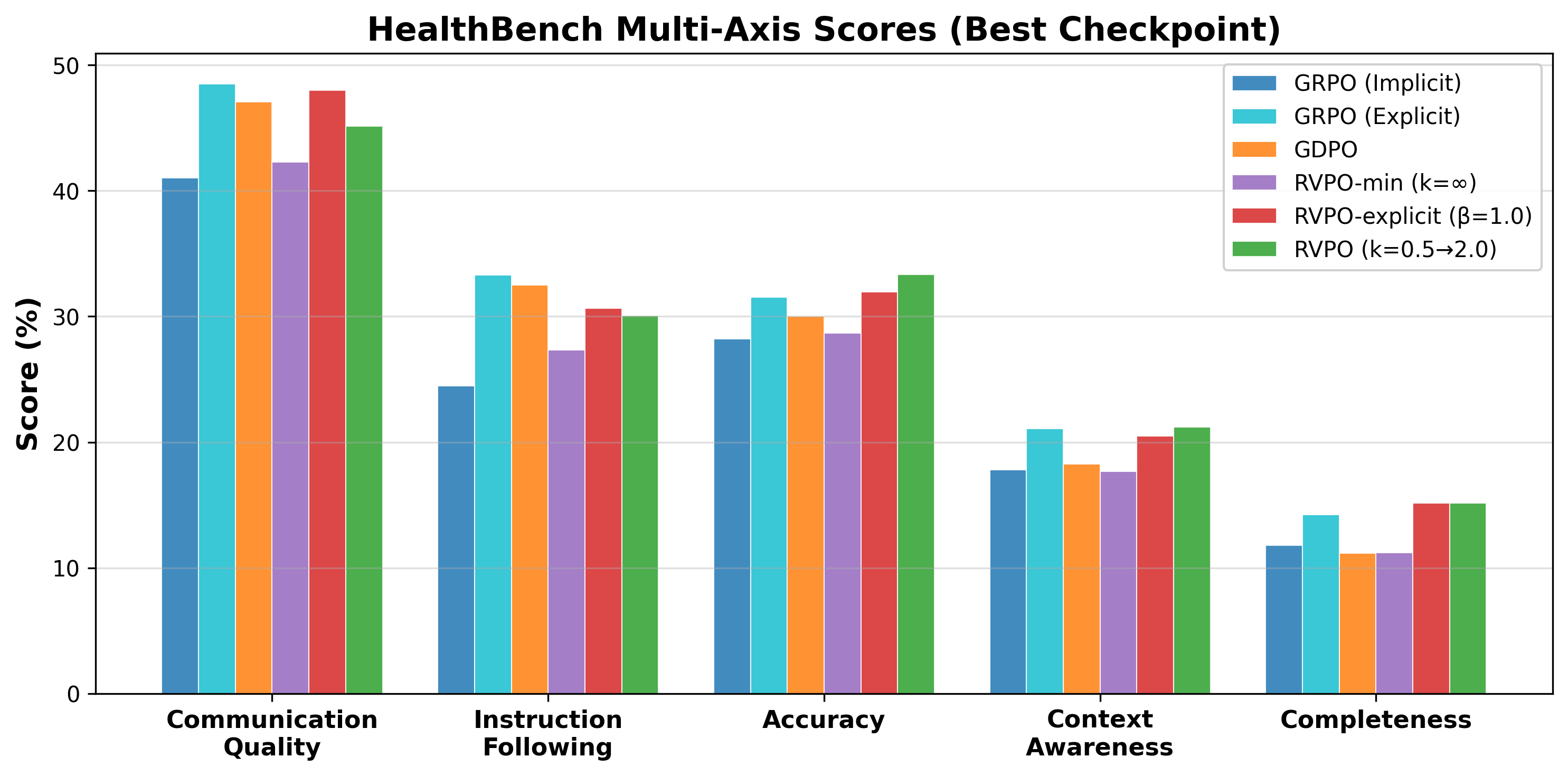
Figure 1: Per-axis performance at the optimal checkpoint on HealthBench (Medicine, Qwen2.5-7B); RVPO redistributes optimization pressure to bottleneck axes and achieves higher overall scores than GDPO.
RVPO consistently improves adherence to bottleneck constraints across model scales. On HealthBench, arithmetic aggregation with GDPO over-optimizes Communication Quality and Instruction Following but neglects Completeness and Context Awareness. RVPO’s variance penalty substantially increases scores on the stricter axes, raising Completeness from 11.1% to 15.2% and Accuracy from 30.0% to 33.3%. The overall score at 14B reaches 0.261 (vs. 0.215 for GDPO, M0). Crucially, RVPO avoids late-stage training collapse observed in GDPO and mean-based baselines, maintaining stability and robust alignment.
Tool-calling experiments further highlight RVPO’s superiority in rapid convergence and constraint satisfaction. With GRPO and GDPO, the format adherence constraint is satisfied only late in training due to loss compensation (Figure 2). RVPO ensures simultaneous improvement in execution correctness and format compliance, reducing inter-run variance and accelerating convergence.
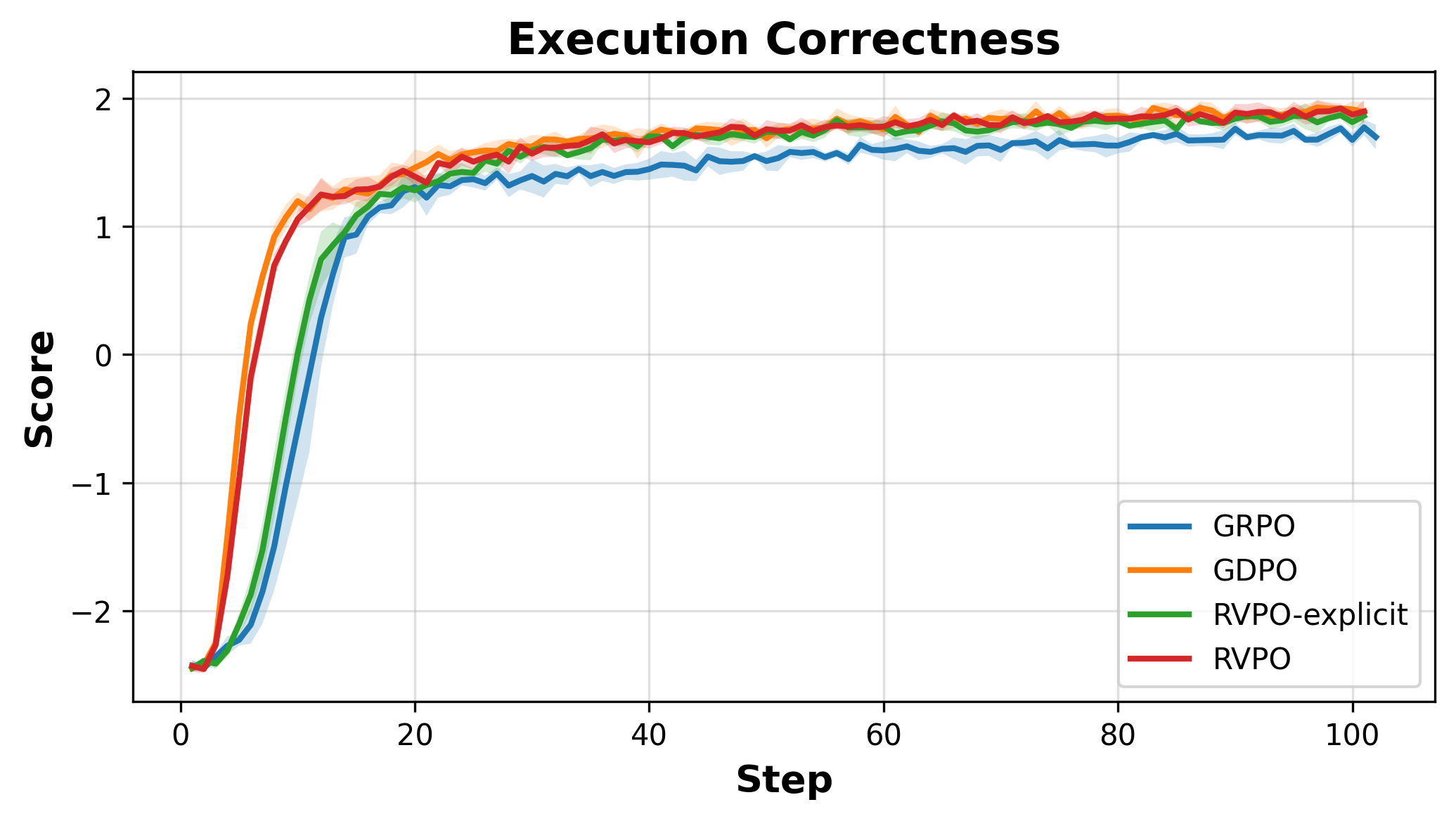
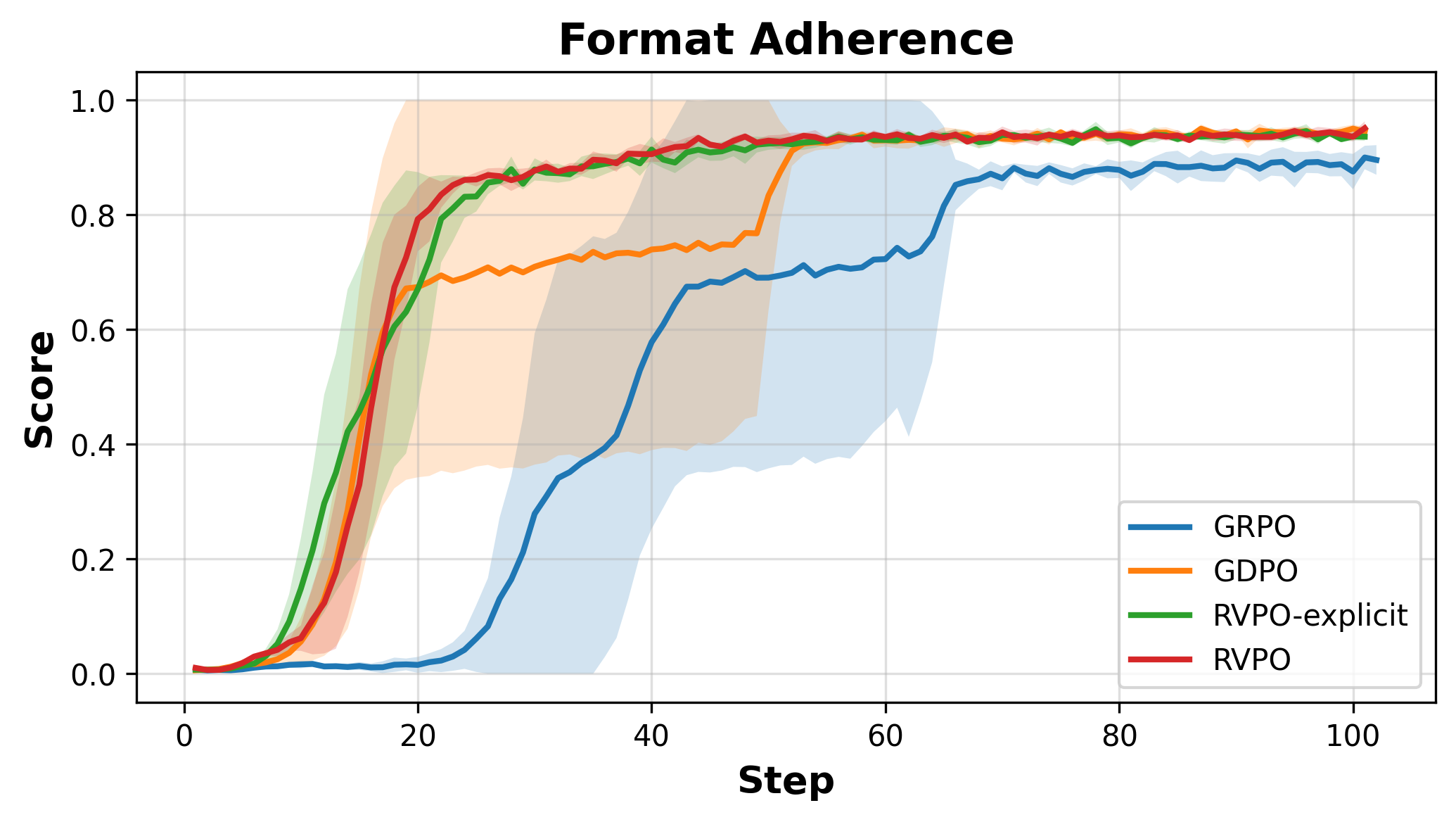
Figure 2: Tool Calling (RLLA) training progression; RVPO outperforms baselines in enforcing formatting constraints alongside execution accuracy.
Hyperparameter Sensitivity
The risk coefficient M1 (inverse temperature in soft-min) is a critical hyperparameter for curriculum robustness. High constant M2 schedules boost peak performance by tightening bottleneck pressure, but induce instability; low M3 schedules are stable but less performant. Annealing M4 from low to moderate values yields optimal stability and peak scores, allowing general capabilities to be established before variance penalization dominates.
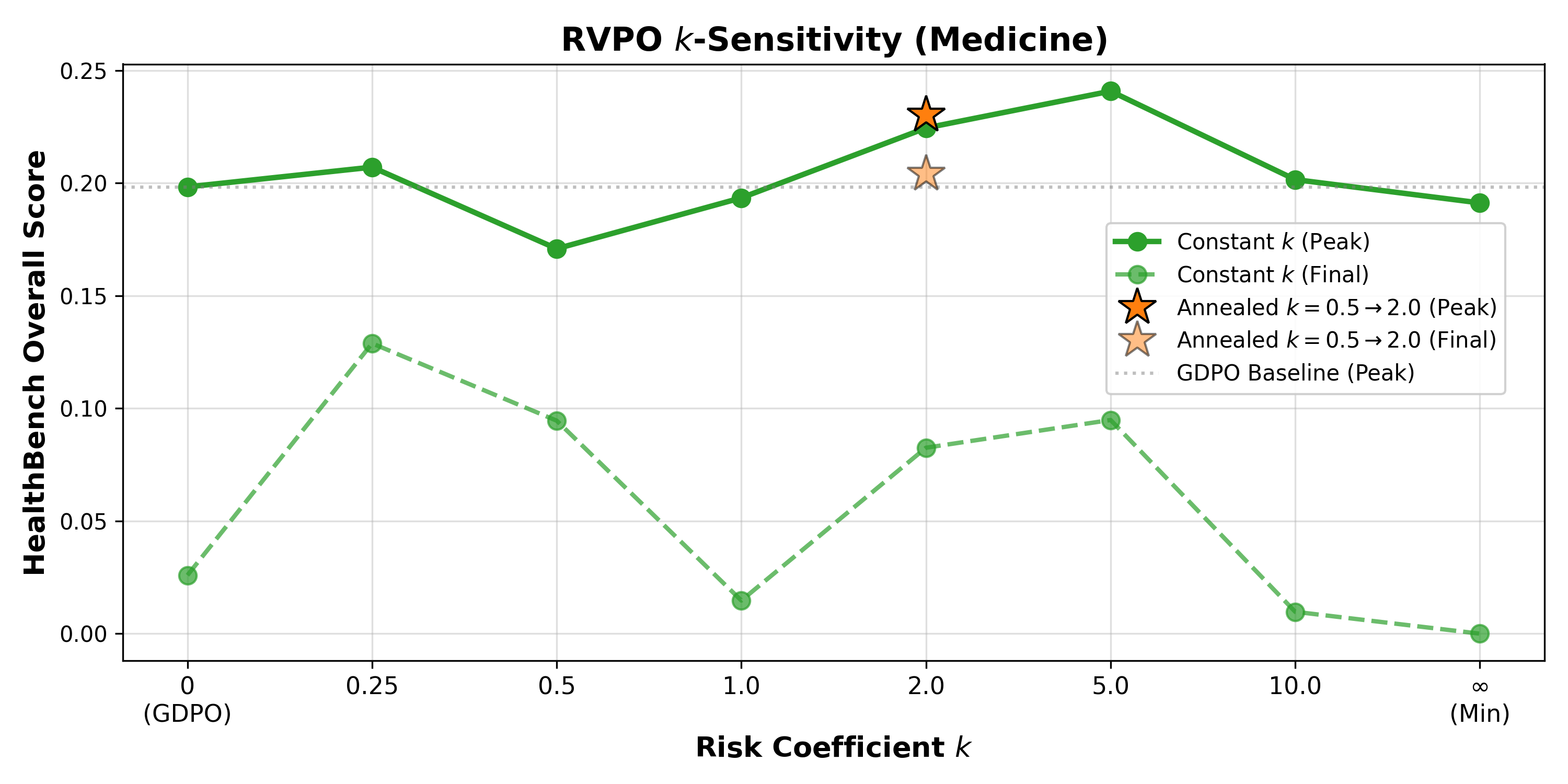
Figure 3: Risk coefficient sweep on HealthBench; annealed M5 schedules best balance peak performance and training stability.
RVPO’s soft-min formulation demonstrates enhanced robustness over explicit variance penalties (M6). Empirical variance with fixed M7 is highly sensitive to reward space dimensionality and produces non-monotonic results, confirming theoretical expectations (Figure 4).
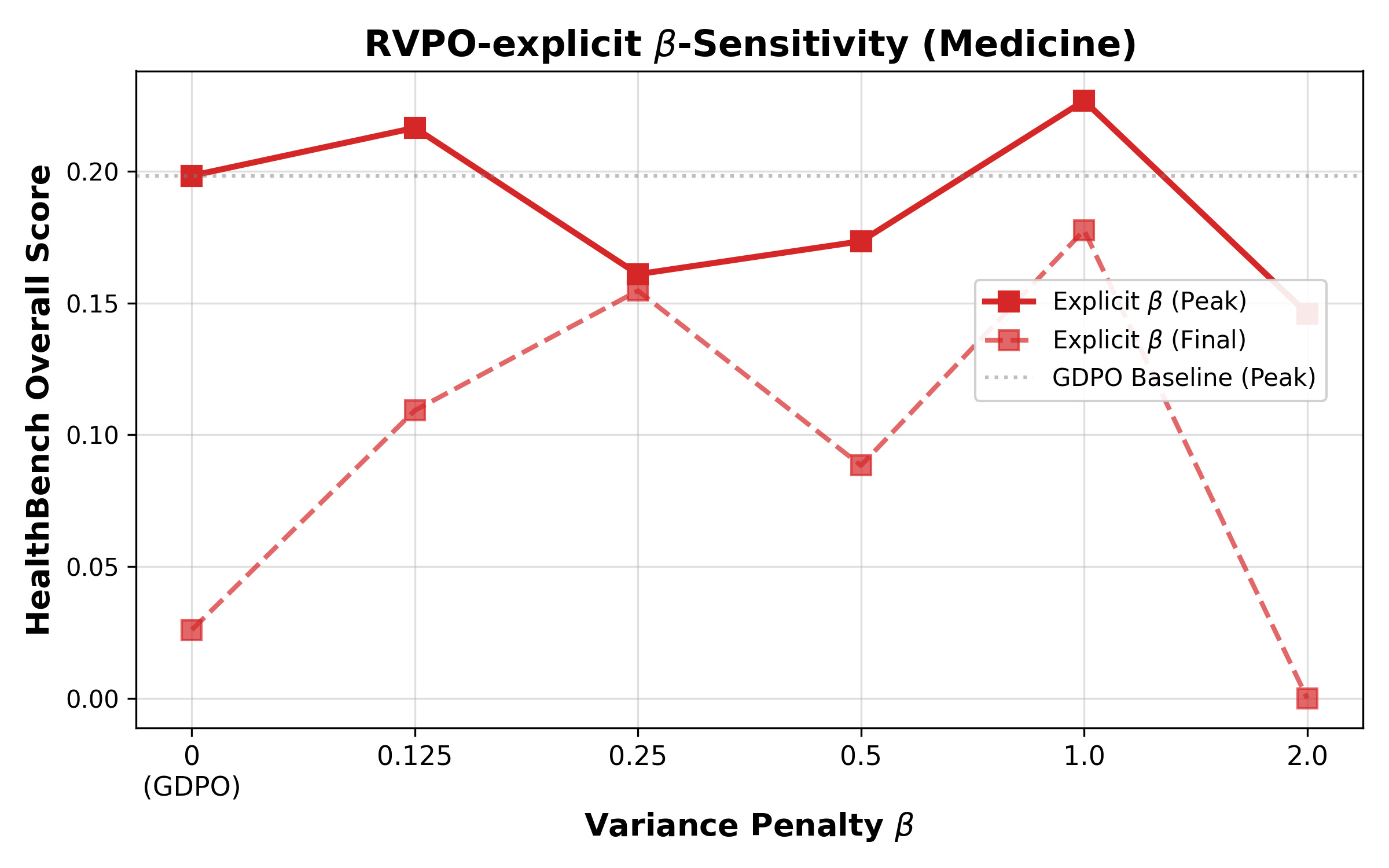
Figure 4: Explicit variance penalty sweep; RVPO’s soft-min achieves greater robustness in optimization stability and sensitivity.
Practical and Theoretical Implications
RVPO generalizes mean aggregation in multi-reward RL by penalizing reward variance, thus robustly addressing constraint neglect without explicit constraint thresholds or multiple policy training. Its curriculum-driven optimization allows for scalable, risk-sensitive alignment across high-dimensional and dynamically varying reward spaces. The absence of value networks reduces memory and compute overhead, facilitating deployment. RVPO’s dynamic prioritization of bottleneck constraints yields policies with strict adherence to safety, formatting, and completeness, necessary for LLMs in practical, real-world settings.
RVPO’s flexible risk coefficient offers explicit control over objective prioritization, supporting advanced curriculum learning and robust multi-objective tuning. Its theoretical foundation in risk-sensitive MDPs and smooth interpolation between mean and min aggregation opens pathways for deeper exploration of difficulty-aware policy optimization, adaptive risk scheduling, and integration with prioritized reward weighting schemes.
Future Directions
Key future avenues include adaptive risk coefficient scheduling, integration with weighted reward systems to reconcile empirical difficulty and declared priorities, and further investigation into noise amplification and reward model reliability in variance-penalized regimes. RVPO’s formulation could enable more interpretable multi-objective policies, robust safety alignment, and Pareto-optimality in large-scale LLMs. It is likely to serve as a foundation for further research into single-run Pareto alignment and scalable, risk-sensitive RLHF.
Conclusion
RVPO introduces a scalable, risk-sensitive aggregation framework that fundamentally mitigates constraint neglect in critic-less RLHF for LLMs. By dynamically penalizing reward variance using the LogSumExp operator, RVPO aligns policies towards consistent, bottleneck-oriented behavior across model scales and domains, improving both peak and final constraint satisfaction. The explicit risk coefficient provides granularity in balancing general vs. strict objectives, with annealed curricula yielding robust training. As the field moves toward decomposed reward models and modular constraints, variance regularization as instantiated by RVPO will remain essential for reliable multi-objective LLM alignment.

